- Content Creators & Streamers: Produce voice bits for memes, shorts, and livestream soundboards.
- YouTubers & Editors: Add character TTS and parody narration to videos.
- Game Modders & Roleplayers: Generate in-character lines for machinima and mods.
- Marketing & Social Teams: Create eye-catching promos and quirky audio hooks.
- Educators & Hobbyists: Demonstrate TTS concepts and prototype voice ideas quickly.
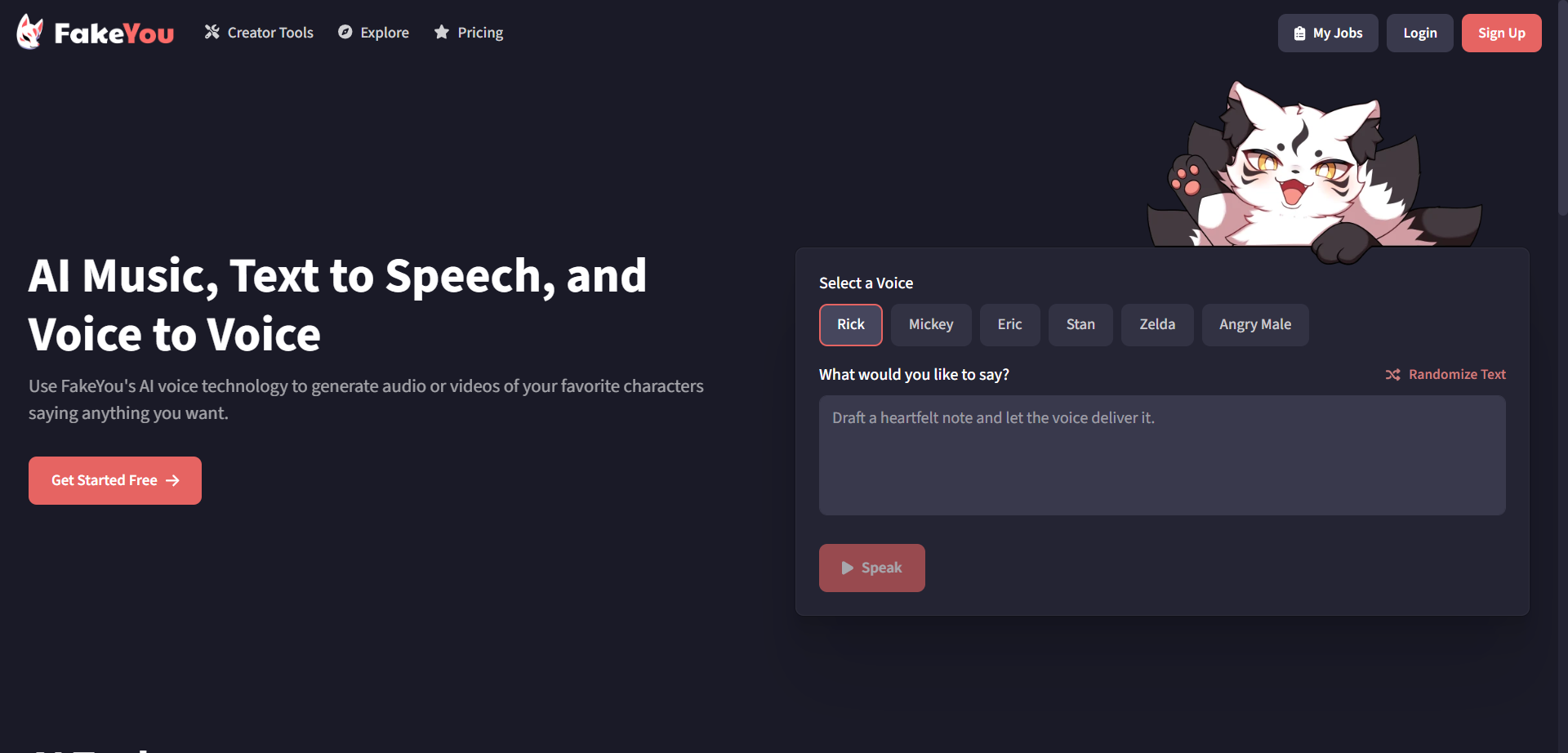
How to Use FakeYou?
- Pick a Voice: Browse voice categories or search for a specific character or style.
- Enter Text: Paste the script and set length and emphasis as needed.
- Generate & Review: Create the audio, then adjust pacing or try alternate takes.
- Download & Share: Export the clip for videos, streams, or social platforms.
- Huge Voice Library: Thousands of character and creator voices for rapid experimentation.
- Community Models: Constantly updated catalog with niche and trending voices.
- Quick Memes to Long Reads: Handles short clips and longer narration reliably.
- Accessible Workflow: Simple interface for fast, repeatable TTS generation.
- Fun-first Creativity: Built for playful voice cosplay, parodies, and social content.
- Vast selection of recognizable and niche voices.
- Fast generation workflow ideal for social content.
- Simple controls that lower the barrier to entry.
- Active community with frequent new voice models.
- Quality varies across community-created voices.
- Licensing for public/commercial use may require extra review.
- Pronunciation control can be limited for complex scripts.
- Occasional queues or delays during high demand.
Plus
$ 12.00
Normal
Text to Speech:
Unlimited generation
Up to 30 seconds audio
Voice to Voice:
Up to 4 minutes of audio
Pro
$ 25.00
Faster
Text to Speech:
Unlimited generation
Up to 1 minute audio
Upload private models
Voice to Voice:
Up to 5 minutes of audio
Upload private models
Elite
$ 40.00
Fastest
Text to Speech:
Unlimited generation
Up to 2 minutes audio
Upload private models
Share private models
Voice to Voice:
Unlimited audio
Upload private models
Share private models
Proud of the love you're getting? Show off your AI Toolbook reviews—then invite more fans to share the love and build your credibility.
Add an AI Toolbook badge to your site—an easy way to drive followers, showcase updates, and collect reviews. It's like a mini 24/7 billboard for your AI.
Reviews
Rating Distribution
Average score
Popular Mention
FAQs
Similar AI Tools
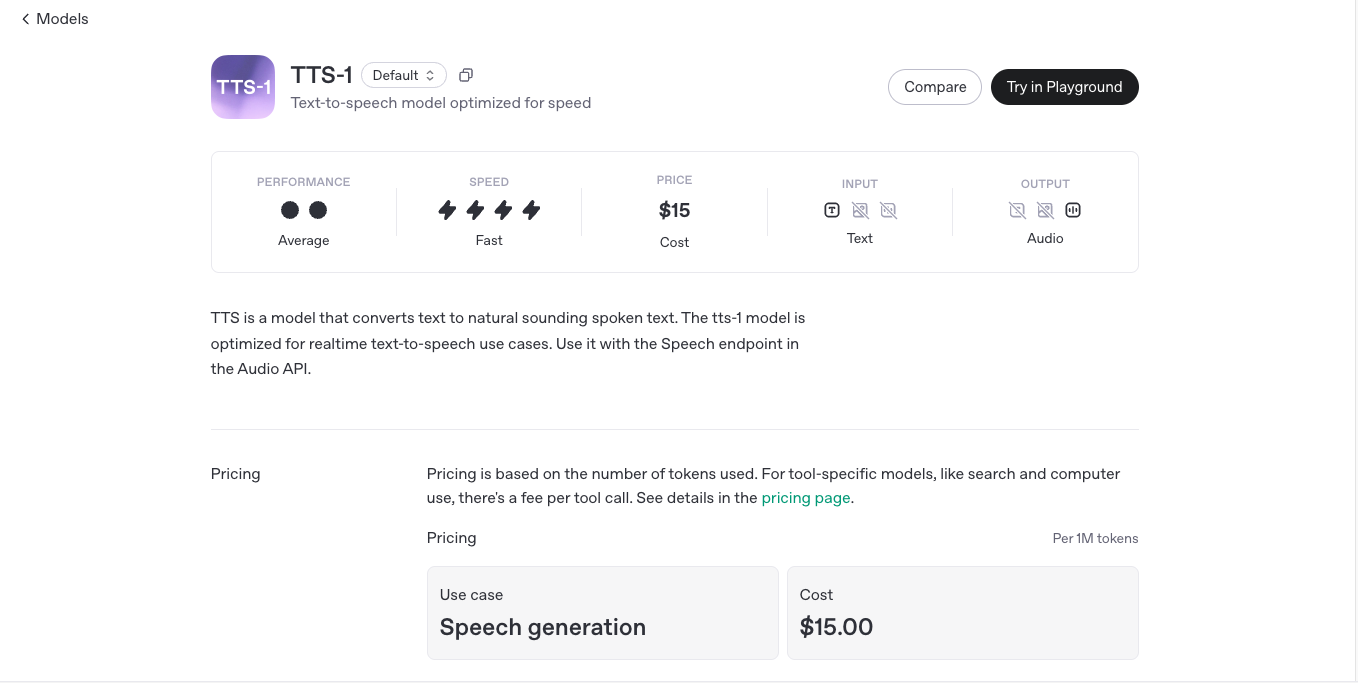
OpenAI TTS1
OpenAI's TTS-1 (Text-to-Speech) is a cutting-edge generative voice model that converts written text into natural-sounding speech with astonishing clarity, pacing, and emotional nuance. TTS-1 is designed to power real-time voice applications—like assistants, narrators, or conversational agents—with near-human vocal quality and minimal latency. Available through OpenAI’s API, this model makes it easy for developers to give their applications a voice that actually sounds human—not robotic. With multiple voices, languages, and low-latency streaming, TTS-1 redefines the synthetic voice experience.
OpenAI TTS1
OpenAI's TTS-1 (Text-to-Speech) is a cutting-edge generative voice model that converts written text into natural-sounding speech with astonishing clarity, pacing, and emotional nuance. TTS-1 is designed to power real-time voice applications—like assistants, narrators, or conversational agents—with near-human vocal quality and minimal latency. Available through OpenAI’s API, this model makes it easy for developers to give their applications a voice that actually sounds human—not robotic. With multiple voices, languages, and low-latency streaming, TTS-1 redefines the synthetic voice experience.
OpenAI TTS1
OpenAI's TTS-1 (Text-to-Speech) is a cutting-edge generative voice model that converts written text into natural-sounding speech with astonishing clarity, pacing, and emotional nuance. TTS-1 is designed to power real-time voice applications—like assistants, narrators, or conversational agents—with near-human vocal quality and minimal latency. Available through OpenAI’s API, this model makes it easy for developers to give their applications a voice that actually sounds human—not robotic. With multiple voices, languages, and low-latency streaming, TTS-1 redefines the synthetic voice experience.
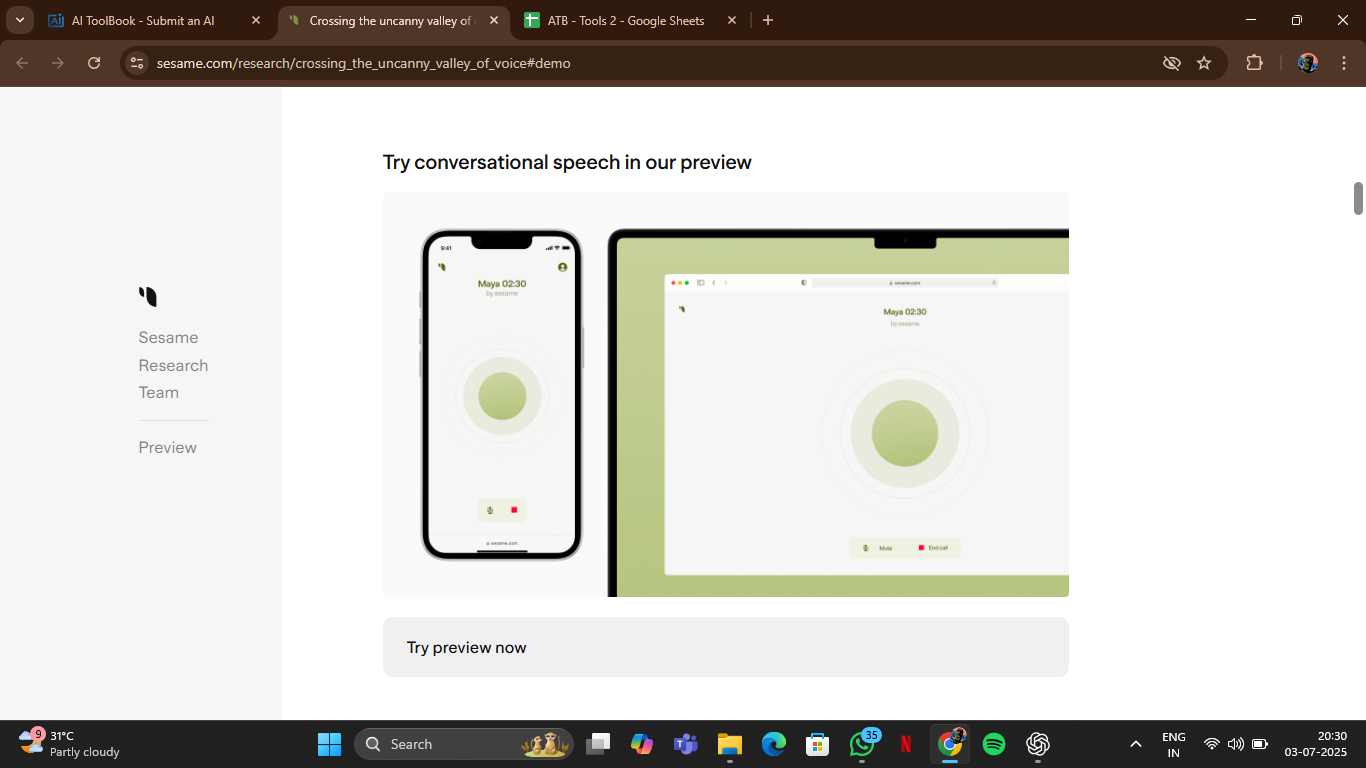
Sesame AI
Sesame Voice AI is a cutting-edge voice synthesis platform that specializes in generating highly realistic and emotionally expressive synthetic voices. Developed by Sesame Labs, this tool bridges the gap between robotic-sounding voice models and human-like speech by incorporating nuanced emotion, context-awareness, and personality into generated audio. Whether it's for games, virtual assistants, films, or branded audio experiences, Sesame aims to "cross the uncanny valley" of voice, producing voices that sound indistinguishably human. It leverages deep learning, large-scale neural networks, and novel techniques in voice conditioning to bring personality-rich, expressive voice capabilities to creators and developers—without needing a real voice actor every time.
Sesame AI
Sesame Voice AI is a cutting-edge voice synthesis platform that specializes in generating highly realistic and emotionally expressive synthetic voices. Developed by Sesame Labs, this tool bridges the gap between robotic-sounding voice models and human-like speech by incorporating nuanced emotion, context-awareness, and personality into generated audio. Whether it's for games, virtual assistants, films, or branded audio experiences, Sesame aims to "cross the uncanny valley" of voice, producing voices that sound indistinguishably human. It leverages deep learning, large-scale neural networks, and novel techniques in voice conditioning to bring personality-rich, expressive voice capabilities to creators and developers—without needing a real voice actor every time.
Sesame AI
Sesame Voice AI is a cutting-edge voice synthesis platform that specializes in generating highly realistic and emotionally expressive synthetic voices. Developed by Sesame Labs, this tool bridges the gap between robotic-sounding voice models and human-like speech by incorporating nuanced emotion, context-awareness, and personality into generated audio. Whether it's for games, virtual assistants, films, or branded audio experiences, Sesame aims to "cross the uncanny valley" of voice, producing voices that sound indistinguishably human. It leverages deep learning, large-scale neural networks, and novel techniques in voice conditioning to bring personality-rich, expressive voice capabilities to creators and developers—without needing a real voice actor every time.
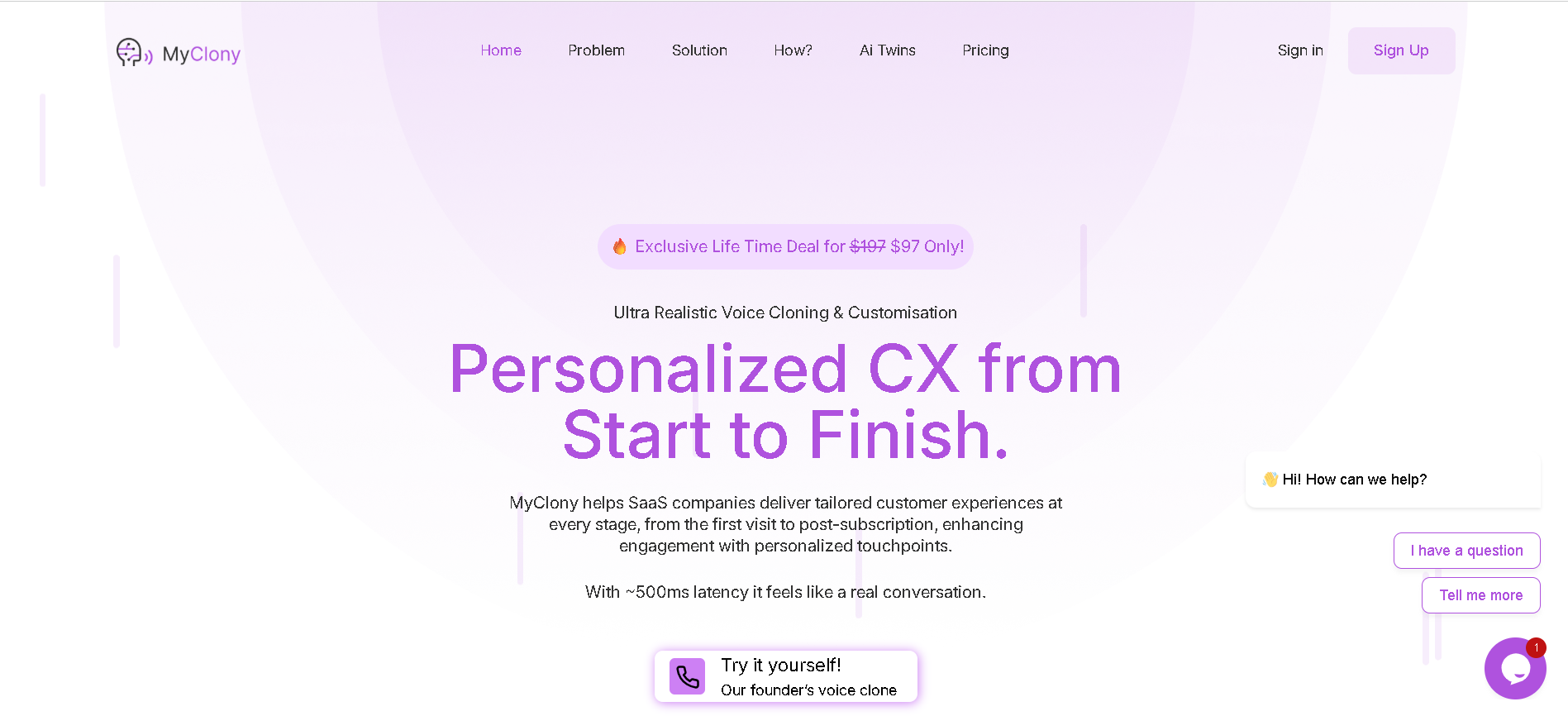
MyClony
Myclony is an AI-powered interactive voice cloning platform designed to enhance customer experience for SaaS companies. It creates personalized "Voice Twins" that provide real-time, human-like assistance, helping businesses to automate customer support and sales processes while fostering deeper emotional connections and trust.
MyClony
Myclony is an AI-powered interactive voice cloning platform designed to enhance customer experience for SaaS companies. It creates personalized "Voice Twins" that provide real-time, human-like assistance, helping businesses to automate customer support and sales processes while fostering deeper emotional connections and trust.
MyClony
Myclony is an AI-powered interactive voice cloning platform designed to enhance customer experience for SaaS companies. It creates personalized "Voice Twins" that provide real-time, human-like assistance, helping businesses to automate customer support and sales processes while fostering deeper emotional connections and trust.
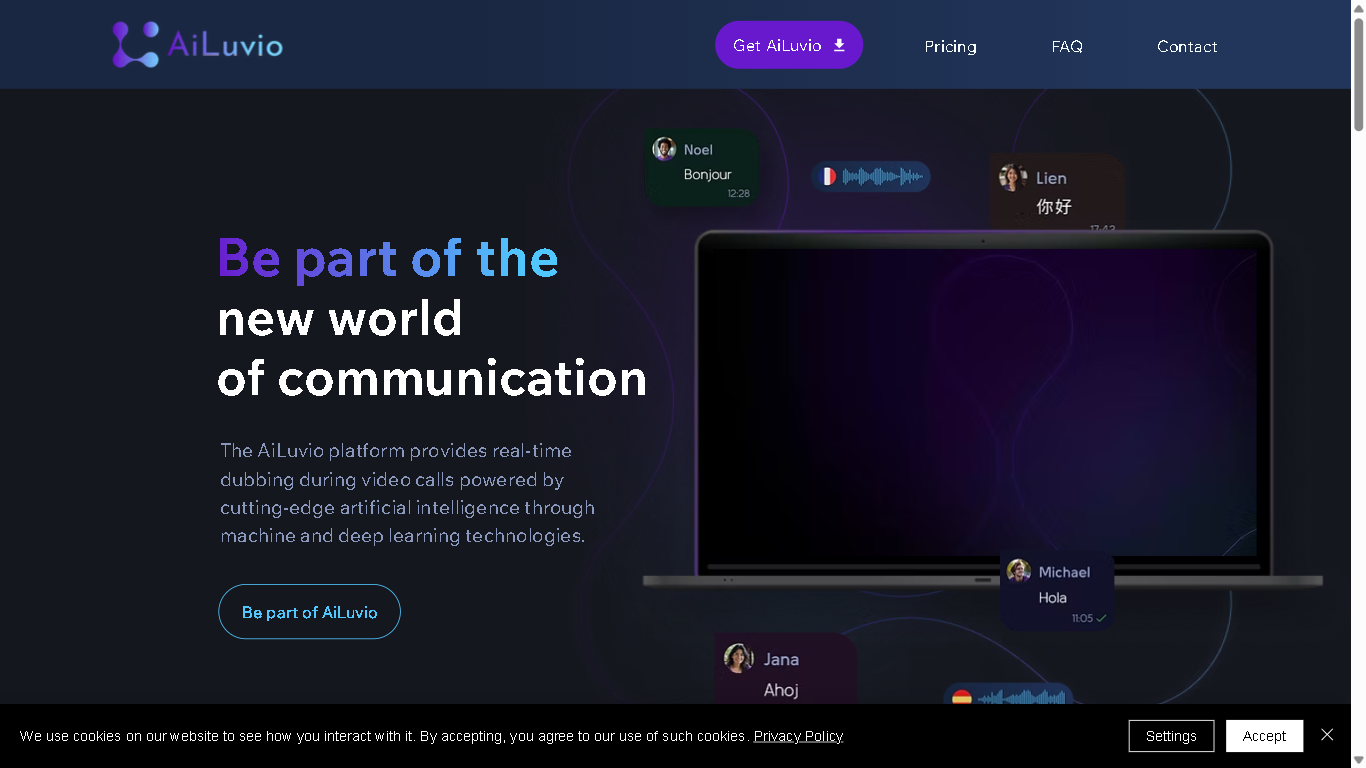

AiLuvio
AiLuvio is an AI-powered video communication platform that enables real-time dubbing during video calls in over 30 languages. It breaks down language barriers by translating speech in live conversations and offering features like automatic chat translation, voice cloning, and secure communication.
AiLuvio
AiLuvio is an AI-powered video communication platform that enables real-time dubbing during video calls in over 30 languages. It breaks down language barriers by translating speech in live conversations and offering features like automatic chat translation, voice cloning, and secure communication.
AiLuvio
AiLuvio is an AI-powered video communication platform that enables real-time dubbing during video calls in over 30 languages. It breaks down language barriers by translating speech in live conversations and offering features like automatic chat translation, voice cloning, and secure communication.
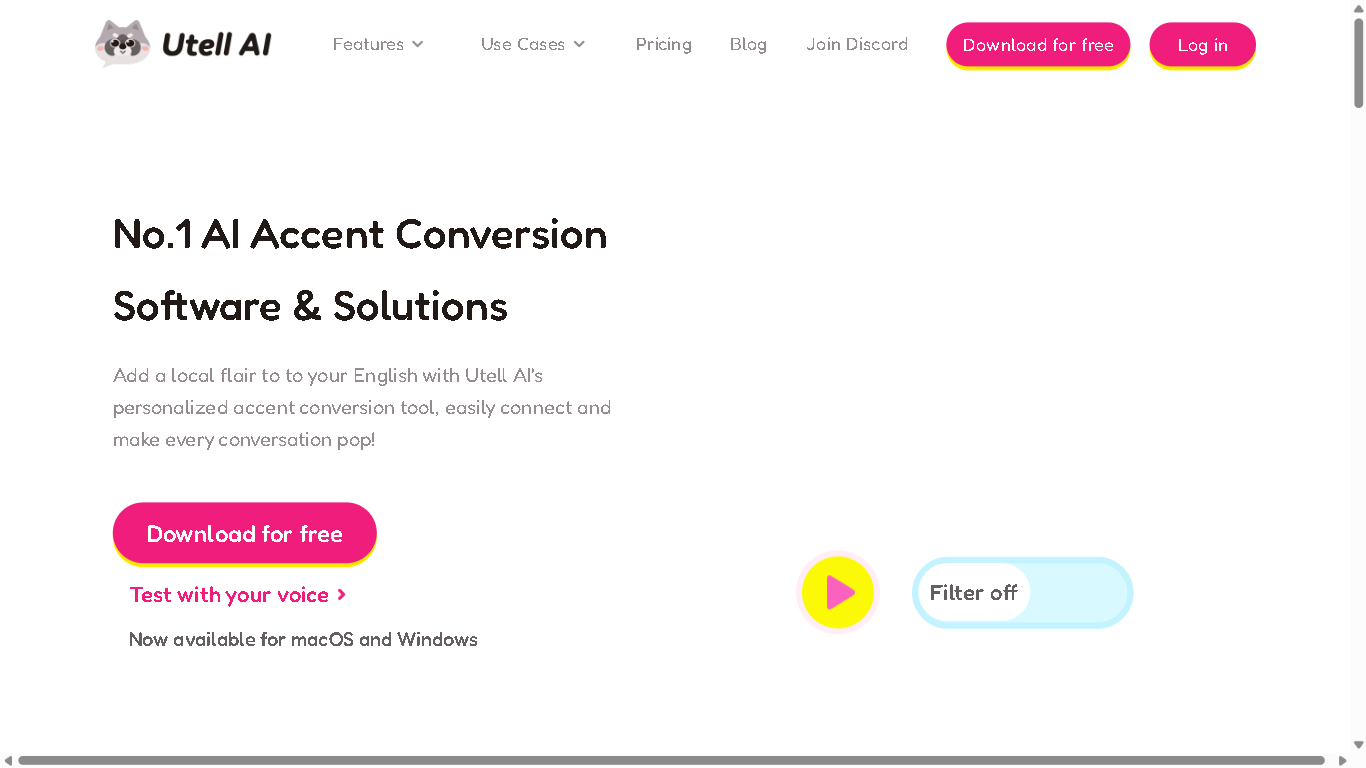
Utell AI
Utell AI is an advanced AI-powered accent conversion platform that helps individuals and businesses improve communication by refining non-native English accents in real-time. It provides a seamless experience for enhancing clarity, preserving natural voice characteristics, and facilitating smooth interactions across meetings, calls, gaming, and online streaming.
Utell AI
Utell AI is an advanced AI-powered accent conversion platform that helps individuals and businesses improve communication by refining non-native English accents in real-time. It provides a seamless experience for enhancing clarity, preserving natural voice characteristics, and facilitating smooth interactions across meetings, calls, gaming, and online streaming.
Utell AI
Utell AI is an advanced AI-powered accent conversion platform that helps individuals and businesses improve communication by refining non-native English accents in real-time. It provides a seamless experience for enhancing clarity, preserving natural voice characteristics, and facilitating smooth interactions across meetings, calls, gaming, and online streaming.
PERSO.ai
Perso.ai is an AI-powered video localization platform that enables creators, educators, and businesses to produce high-quality, multilingual videos effortlessly. It offers features like voice cloning, lip-sync dubbing, and real-time script editing, making global content creation accessible to everyone.
PERSO.ai
Perso.ai is an AI-powered video localization platform that enables creators, educators, and businesses to produce high-quality, multilingual videos effortlessly. It offers features like voice cloning, lip-sync dubbing, and real-time script editing, making global content creation accessible to everyone.
PERSO.ai
Perso.ai is an AI-powered video localization platform that enables creators, educators, and businesses to produce high-quality, multilingual videos effortlessly. It offers features like voice cloning, lip-sync dubbing, and real-time script editing, making global content creation accessible to everyone.

Murf.ai
Murf.ai is an AI voice generator and text-to-speech platform that delivers ultra-realistic voiceovers for creators, teams, and developers. It offers 200+ multilingual voices, 10+ speaking styles, and fine-grained controls over pitch, speed, tone, prosody, and pronunciation. A low-latency TTS model powers conversational agents with sub-200 ms response, while APIs enable voice cloning, voice changing, streaming TTS, and translation/dubbing in 30+ languages. A studio workspace supports scripting, timing, and rapid iteration for ads, training, audiobooks, podcasts, and product audio. Pronunciation libraries, team workspaces, and tool integrations help standardize brand voice at scale without complex audio engineering.
Murf.ai
Murf.ai is an AI voice generator and text-to-speech platform that delivers ultra-realistic voiceovers for creators, teams, and developers. It offers 200+ multilingual voices, 10+ speaking styles, and fine-grained controls over pitch, speed, tone, prosody, and pronunciation. A low-latency TTS model powers conversational agents with sub-200 ms response, while APIs enable voice cloning, voice changing, streaming TTS, and translation/dubbing in 30+ languages. A studio workspace supports scripting, timing, and rapid iteration for ads, training, audiobooks, podcasts, and product audio. Pronunciation libraries, team workspaces, and tool integrations help standardize brand voice at scale without complex audio engineering.
Murf.ai
Murf.ai is an AI voice generator and text-to-speech platform that delivers ultra-realistic voiceovers for creators, teams, and developers. It offers 200+ multilingual voices, 10+ speaking styles, and fine-grained controls over pitch, speed, tone, prosody, and pronunciation. A low-latency TTS model powers conversational agents with sub-200 ms response, while APIs enable voice cloning, voice changing, streaming TTS, and translation/dubbing in 30+ languages. A studio workspace supports scripting, timing, and rapid iteration for ads, training, audiobooks, podcasts, and product audio. Pronunciation libraries, team workspaces, and tool integrations help standardize brand voice at scale without complex audio engineering.


Narakeet
Narakeet is a text-to-speech and video automation platform that turns scripts, slides, and subtitle files into narrated videos and voiceovers at scale. It offers 100 languages and 800 realistic voices, letting teams update narration by simply editing text instead of re-recording audio. Users can convert PowerPoint, Google Slides, or Keynote into full HD videos with captions, or turn SRT/WebVTT subtitles into synchronized dubbing tracks. Markdown scripting and templates streamline creating social clips, tutorials, and product demos. With API and CLI support, Narakeet automates multi-language, multi-resolution outputs, accelerating production for training, marketing, and documentation content.
Narakeet
Narakeet is a text-to-speech and video automation platform that turns scripts, slides, and subtitle files into narrated videos and voiceovers at scale. It offers 100 languages and 800 realistic voices, letting teams update narration by simply editing text instead of re-recording audio. Users can convert PowerPoint, Google Slides, or Keynote into full HD videos with captions, or turn SRT/WebVTT subtitles into synchronized dubbing tracks. Markdown scripting and templates streamline creating social clips, tutorials, and product demos. With API and CLI support, Narakeet automates multi-language, multi-resolution outputs, accelerating production for training, marketing, and documentation content.
Narakeet
Narakeet is a text-to-speech and video automation platform that turns scripts, slides, and subtitle files into narrated videos and voiceovers at scale. It offers 100 languages and 800 realistic voices, letting teams update narration by simply editing text instead of re-recording audio. Users can convert PowerPoint, Google Slides, or Keynote into full HD videos with captions, or turn SRT/WebVTT subtitles into synchronized dubbing tracks. Markdown scripting and templates streamline creating social clips, tutorials, and product demos. With API and CLI support, Narakeet automates multi-language, multi-resolution outputs, accelerating production for training, marketing, and documentation content.


Top Medi AI
TopMediai is an all-in-one AI platform built to supercharge content creation across voice, music, and media. It offers advanced tools for text-to-speech, voice cloning, song generation, music covers, and more—allowing creators to generate realistic voiceovers, custom music tracks, and full audio productions in minutes. With thousands of AI voices, support for hundreds of languages and accents, and smart music-generation from prompts, lyrics or images, you get a creative engine built for speed and scale. Whether you're crafting podcasts, videos, games, songs or dubbing, TopMediai packs studio-grade power into a browser-based workflow. The platform also offers API access so developers and creative teams can integrate voice and music generation into their apps and systems.
Top Medi AI
TopMediai is an all-in-one AI platform built to supercharge content creation across voice, music, and media. It offers advanced tools for text-to-speech, voice cloning, song generation, music covers, and more—allowing creators to generate realistic voiceovers, custom music tracks, and full audio productions in minutes. With thousands of AI voices, support for hundreds of languages and accents, and smart music-generation from prompts, lyrics or images, you get a creative engine built for speed and scale. Whether you're crafting podcasts, videos, games, songs or dubbing, TopMediai packs studio-grade power into a browser-based workflow. The platform also offers API access so developers and creative teams can integrate voice and music generation into their apps and systems.
Top Medi AI
TopMediai is an all-in-one AI platform built to supercharge content creation across voice, music, and media. It offers advanced tools for text-to-speech, voice cloning, song generation, music covers, and more—allowing creators to generate realistic voiceovers, custom music tracks, and full audio productions in minutes. With thousands of AI voices, support for hundreds of languages and accents, and smart music-generation from prompts, lyrics or images, you get a creative engine built for speed and scale. Whether you're crafting podcasts, videos, games, songs or dubbing, TopMediai packs studio-grade power into a browser-based workflow. The platform also offers API access so developers and creative teams can integrate voice and music generation into their apps and systems.
Voiset
Voiset is an AI-driven voice automation and conversational intelligence platform designed to enhance business communication, sales, and customer service. It allows teams to build intelligent voice agents that handle inbound and outbound calls, transcribe conversations, and provide real-time analytics. With advanced natural language processing, Voiset enables companies to automate communication tasks, reduce call handling time, and maintain personalized customer interactions. It integrates seamlessly with CRM tools and supports multiple languages, making it ideal for global teams and enterprises looking to scale voice operations.
Voiset
Voiset is an AI-driven voice automation and conversational intelligence platform designed to enhance business communication, sales, and customer service. It allows teams to build intelligent voice agents that handle inbound and outbound calls, transcribe conversations, and provide real-time analytics. With advanced natural language processing, Voiset enables companies to automate communication tasks, reduce call handling time, and maintain personalized customer interactions. It integrates seamlessly with CRM tools and supports multiple languages, making it ideal for global teams and enterprises looking to scale voice operations.
Voiset
Voiset is an AI-driven voice automation and conversational intelligence platform designed to enhance business communication, sales, and customer service. It allows teams to build intelligent voice agents that handle inbound and outbound calls, transcribe conversations, and provide real-time analytics. With advanced natural language processing, Voiset enables companies to automate communication tasks, reduce call handling time, and maintain personalized customer interactions. It integrates seamlessly with CRM tools and supports multiple languages, making it ideal for global teams and enterprises looking to scale voice operations.
Infinite Talk AI
InfiniteTalk AI is a real-time voice AI platform designed to generate natural, expressive, human-like speech for conversations, character performances, dubbing, and instant voice replacement across creative and professional workflows. Unlike traditional text‑to‑speech tools, InfiniteTalk AI focuses on true conversational dynamics intonation, pacing, emotion, interruptions, reactions, and personality-driven delivery. Users can choose from a large library of AI voices or create custom voices that maintain identity, tone consistency, emotional variation, and accent accuracy. Built for streamers, filmmakers, game developers, virtual creators, and businesses, InfiniteTalk AI enables fully interactive AI voice agents, real-time dialogue, multilingual dubbing, and rapid voiceover generation for any context.
Infinite Talk AI
InfiniteTalk AI is a real-time voice AI platform designed to generate natural, expressive, human-like speech for conversations, character performances, dubbing, and instant voice replacement across creative and professional workflows. Unlike traditional text‑to‑speech tools, InfiniteTalk AI focuses on true conversational dynamics intonation, pacing, emotion, interruptions, reactions, and personality-driven delivery. Users can choose from a large library of AI voices or create custom voices that maintain identity, tone consistency, emotional variation, and accent accuracy. Built for streamers, filmmakers, game developers, virtual creators, and businesses, InfiniteTalk AI enables fully interactive AI voice agents, real-time dialogue, multilingual dubbing, and rapid voiceover generation for any context.
Infinite Talk AI
InfiniteTalk AI is a real-time voice AI platform designed to generate natural, expressive, human-like speech for conversations, character performances, dubbing, and instant voice replacement across creative and professional workflows. Unlike traditional text‑to‑speech tools, InfiniteTalk AI focuses on true conversational dynamics intonation, pacing, emotion, interruptions, reactions, and personality-driven delivery. Users can choose from a large library of AI voices or create custom voices that maintain identity, tone consistency, emotional variation, and accent accuracy. Built for streamers, filmmakers, game developers, virtual creators, and businesses, InfiniteTalk AI enables fully interactive AI voice agents, real-time dialogue, multilingual dubbing, and rapid voiceover generation for any context.

RecCloud AI
RecCloud is an AI-powered audio and video platform that simplifies media creation and editing with an integrated toolkit for speech-to-text, subtitles, text-to-speech, summarization, and video generation. It transforms spoken audio into accurate, polished transcripts, automatically generates and translates subtitles, and converts text into natural-sounding voices in multiple languages. Users can summarize long lectures, YouTube videos, and presentations into concise highlights, or turn text prompts directly into complete videos. Designed for students, educators, creators, and marketers, RecCloud focuses on boosting efficiency, accessibility, and creativity while keeping everything easy to use and free to start.
RecCloud AI
RecCloud is an AI-powered audio and video platform that simplifies media creation and editing with an integrated toolkit for speech-to-text, subtitles, text-to-speech, summarization, and video generation. It transforms spoken audio into accurate, polished transcripts, automatically generates and translates subtitles, and converts text into natural-sounding voices in multiple languages. Users can summarize long lectures, YouTube videos, and presentations into concise highlights, or turn text prompts directly into complete videos. Designed for students, educators, creators, and marketers, RecCloud focuses on boosting efficiency, accessibility, and creativity while keeping everything easy to use and free to start.
RecCloud AI
RecCloud is an AI-powered audio and video platform that simplifies media creation and editing with an integrated toolkit for speech-to-text, subtitles, text-to-speech, summarization, and video generation. It transforms spoken audio into accurate, polished transcripts, automatically generates and translates subtitles, and converts text into natural-sounding voices in multiple languages. Users can summarize long lectures, YouTube videos, and presentations into concise highlights, or turn text prompts directly into complete videos. Designed for students, educators, creators, and marketers, RecCloud focuses on boosting efficiency, accessibility, and creativity while keeping everything easy to use and free to start.
Editorial Note
This page was researched and written by the ATB Editorial Team. Our team researches each AI tool by reviewing its official website, testing features, exploring real use cases, and considering user feedback. Every page is fact-checked and regularly updated to ensure the information stays accurate, neutral, and useful for our readers.
If you have any suggestions or questions, email us at hello@aitoolbook.ai