- Content Creators: Expand your audience by localizing videos into multiple languages.
- Educators & Trainers: Deliver training materials in various languages to reach a broader audience.
- Marketing Teams: Create region-specific campaigns with localized video content.
- Enterprises: Standardize global communications with consistent, localized videos.
- Agencies: Offer multilingual video services to clients without additional resources.
- Influencers & Vloggers: Engage international followers with content in their native languages.
How to Use Perso.ai?
- Sign Up & Log In: Create an account to access the platform's features.
- Upload Video: Import your video file (supports MP4, MOV, WEBM, MP3, WAV formats, up to 2GB).
- Select Language & Voice: Choose from over 6,000 multilingual voices and select the desired language.
- Edit Script: Modify the script in real-time to ensure accurate translation and tone.
- Generate Dubbing: Let Perso.ai automatically dub the video with synchronized lip movements.
- Download & Share: Export the localized video in up to 4K quality and share it across platforms.
- Over 6,000 Multilingual Voices: Access a vast library of voices capable of emotional expression.
- AI Lip-Sync Technology: Achieve natural lip movements, even with glasses, masks, or hands covering the face.
- Real-Time Script Editing: Make instant adjustments to translations and technical terms.
- Multi-Speaker Detection: Automatically detect and dub multiple speakers in interviews or podcasts.
- High-Quality Exports: Produce videos in up to 4K resolution without watermarking.
- User-Friendly Interface: No need for professional equipment or voice actors.
- Extensive voice library supporting numerous languages.
- Advanced lip-sync technology ensuring realistic dubbing.
- Quick and easy video localization process.
- High-quality video output suitable for professional use.
- No need for additional resources like voice actors or recording equipment.
- Affordable pricing plans catering to various needs.
- Limited customization options for voice selection.
- Some languages may have fewer voice options.
- Real-time script editing may require manual adjustments for complex content.
- No mobile application for on-the-go video creation.
- Limited integration with other video editing tools.
- May require a stable internet connection for optimal performance.
Free
$ 0.00
Up to 1 min video creation
Booster Concurrent Processing: Up to 1
Booster Queue: Up to 1
Normal video processing
Voice Cloning in 32 languages
Multi-Speaker Support
Creator
$ 39.00
Up to 15 min video creation
Booster Concurrent Processing: Up to 1
Booster Queue: Up to 2
Standard video processing
Voice Cloning in 32 languages
Multi-Speaker Support
AI Lip-Sync
Script Editing: Grammar & translation refinement
Custom Glossary
PRO (x3)
$ 99.00
Up to 30 min video creation
Booster Concurrent Processing: Up to 3
Booster Queue: Up to 6
Fast video processing
Voice Cloning in 32 languages
Multi-Speaker Support
AI Lip-Sync
Script Editing: Grammar & translation refinement
Custom Glossary
Enterprise
custom
Up to 60 min video creation
Booster Concurrent Processing: Up to 4 per 2 seats (Custom Booster available)
Booster Queue: Up to 10 per 2 seats
Uses dedicated resources
Voice Cloning in 32 languages
Multi-Speaker Support
AI Lip-Sync
Script Editing: Grammar & translation refinement
SRT File Upload
Custom Glossary
Proud of the love you're getting? Show off your AI Toolbook reviews—then invite more fans to share the love and build your credibility.
Add an AI Toolbook badge to your site—an easy way to drive followers, showcase updates, and collect reviews. It's like a mini 24/7 billboard for your AI.
Reviews
Rating Distribution
Average score
Popular Mention
FAQs
Similar AI Tools
Veo3 AI Video
UseVoe is an AI-powered voice cloning and speech synthesis platform that enables users to create realistic voiceovers using customized synthetic voices. Designed for content creators, marketers, educators, and developers, UseVoe offers a fast and efficient way to generate human-like speech from text without needing professional voice actors or recording studios. The platform supports multiple languages and voice styles, allowing users to select or train voices that match their brand or project tone. Its intuitive interface allows easy input of text scripts, adjustment of speech parameters such as speed and pitch, and immediate generation of audio outputs. Additionally, UseVoe provides API access for seamless integration into applications, games, or multimedia projects. It is useful for producing podcasts, audiobooks, instructional content, advertisements, and more.
Veo3 AI Video
UseVoe is an AI-powered voice cloning and speech synthesis platform that enables users to create realistic voiceovers using customized synthetic voices. Designed for content creators, marketers, educators, and developers, UseVoe offers a fast and efficient way to generate human-like speech from text without needing professional voice actors or recording studios. The platform supports multiple languages and voice styles, allowing users to select or train voices that match their brand or project tone. Its intuitive interface allows easy input of text scripts, adjustment of speech parameters such as speed and pitch, and immediate generation of audio outputs. Additionally, UseVoe provides API access for seamless integration into applications, games, or multimedia projects. It is useful for producing podcasts, audiobooks, instructional content, advertisements, and more.
Veo3 AI Video
UseVoe is an AI-powered voice cloning and speech synthesis platform that enables users to create realistic voiceovers using customized synthetic voices. Designed for content creators, marketers, educators, and developers, UseVoe offers a fast and efficient way to generate human-like speech from text without needing professional voice actors or recording studios. The platform supports multiple languages and voice styles, allowing users to select or train voices that match their brand or project tone. Its intuitive interface allows easy input of text scripts, adjustment of speech parameters such as speed and pitch, and immediate generation of audio outputs. Additionally, UseVoe provides API access for seamless integration into applications, games, or multimedia projects. It is useful for producing podcasts, audiobooks, instructional content, advertisements, and more.

AiLuvio
AiLuvio is an AI-powered video communication platform that enables real-time dubbing during video calls in over 30 languages. It breaks down language barriers by translating speech in live conversations and offering features like automatic chat translation, voice cloning, and secure communication.
AiLuvio
AiLuvio is an AI-powered video communication platform that enables real-time dubbing during video calls in over 30 languages. It breaks down language barriers by translating speech in live conversations and offering features like automatic chat translation, voice cloning, and secure communication.
AiLuvio
AiLuvio is an AI-powered video communication platform that enables real-time dubbing during video calls in over 30 languages. It breaks down language barriers by translating speech in live conversations and offering features like automatic chat translation, voice cloning, and secure communication.

vo3ai.ai
Veo3 AI is Google's advanced generative video and audio platform that transforms text prompts or images into cinematic videos with synchronized sound, dialogue, and effects. Leveraging the latest Veo 3 technology, users can go from concept to animated, sound-rich video in minutes—whether starting from words or static images. With deep learning-driven audio, accurate lip-sync, and fast tracking for realistic animation, Veo3 AI enables both casual creators and professionals to produce engaging content easily and efficiently.
vo3ai.ai
Veo3 AI is Google's advanced generative video and audio platform that transforms text prompts or images into cinematic videos with synchronized sound, dialogue, and effects. Leveraging the latest Veo 3 technology, users can go from concept to animated, sound-rich video in minutes—whether starting from words or static images. With deep learning-driven audio, accurate lip-sync, and fast tracking for realistic animation, Veo3 AI enables both casual creators and professionals to produce engaging content easily and efficiently.
vo3ai.ai
Veo3 AI is Google's advanced generative video and audio platform that transforms text prompts or images into cinematic videos with synchronized sound, dialogue, and effects. Leveraging the latest Veo 3 technology, users can go from concept to animated, sound-rich video in minutes—whether starting from words or static images. With deep learning-driven audio, accurate lip-sync, and fast tracking for realistic animation, Veo3 AI enables both casual creators and professionals to produce engaging content easily and efficiently.
AI Voice Generator – Voice Cloning is a cutting-edge platform that leverages Higgs Audio's advanced neural networks to create realistic voice replicas from just a short audio sample. This tool allows users to clone voices with minimal reference audio, offering professional-grade results in under 100 milliseconds. Ideal for content creators, voice actors, and developers, it provides an open-source framework for customizable voice models.
AI Voice Generator – Voice Cloning is a cutting-edge platform that leverages Higgs Audio's advanced neural networks to create realistic voice replicas from just a short audio sample. This tool allows users to clone voices with minimal reference audio, offering professional-grade results in under 100 milliseconds. Ideal for content creators, voice actors, and developers, it provides an open-source framework for customizable voice models.
AI Voice Generator – Voice Cloning is a cutting-edge platform that leverages Higgs Audio's advanced neural networks to create realistic voice replicas from just a short audio sample. This tool allows users to clone voices with minimal reference audio, offering professional-grade results in under 100 milliseconds. Ideal for content creators, voice actors, and developers, it provides an open-source framework for customizable voice models.
Voiceslab
Voiceslab is an AI voice cloning and synthesis platform that enables users to create digital replicas of their voice from a short audio sample. By uploading or recording about 10–60 seconds of speech, the system analyzes tone, speech patterns, and style to generate a custom voice model. After that, users can input text to produce natural-sounding speech in their cloned voice across multiple languages. The tool is suited for content creators, marketers, podcasters, and businesses wanting to scale voice content without repeated recording.
Voiceslab
Voiceslab is an AI voice cloning and synthesis platform that enables users to create digital replicas of their voice from a short audio sample. By uploading or recording about 10–60 seconds of speech, the system analyzes tone, speech patterns, and style to generate a custom voice model. After that, users can input text to produce natural-sounding speech in their cloned voice across multiple languages. The tool is suited for content creators, marketers, podcasters, and businesses wanting to scale voice content without repeated recording.
Voiceslab
Voiceslab is an AI voice cloning and synthesis platform that enables users to create digital replicas of their voice from a short audio sample. By uploading or recording about 10–60 seconds of speech, the system analyzes tone, speech patterns, and style to generate a custom voice model. After that, users can input text to produce natural-sounding speech in their cloned voice across multiple languages. The tool is suited for content creators, marketers, podcasters, and businesses wanting to scale voice content without repeated recording.

Humva
Humva is an AI video creation platform that turns a single sentence or full script into a complete, auto-edited video in one click. It combines realistic talking avatars with automatic A‑roll and B‑roll generation, basic editing, and support for 30+ languages to deliver explainer, marketing, and training videos fast. Users can pick from thousands of diverse avatars or create a custom avatar from a single photo, set aspect ratios for social or widescreen, and generate multiple clips that Humva stitches together. Videos are capped at three minutes, making it ideal for short-form content and rapid iteration without complex tools or manual editing.
Humva
Humva is an AI video creation platform that turns a single sentence or full script into a complete, auto-edited video in one click. It combines realistic talking avatars with automatic A‑roll and B‑roll generation, basic editing, and support for 30+ languages to deliver explainer, marketing, and training videos fast. Users can pick from thousands of diverse avatars or create a custom avatar from a single photo, set aspect ratios for social or widescreen, and generate multiple clips that Humva stitches together. Videos are capped at three minutes, making it ideal for short-form content and rapid iteration without complex tools or manual editing.
Humva
Humva is an AI video creation platform that turns a single sentence or full script into a complete, auto-edited video in one click. It combines realistic talking avatars with automatic A‑roll and B‑roll generation, basic editing, and support for 30+ languages to deliver explainer, marketing, and training videos fast. Users can pick from thousands of diverse avatars or create a custom avatar from a single photo, set aspect ratios for social or widescreen, and generate multiple clips that Humva stitches together. Videos are capped at three minutes, making it ideal for short-form content and rapid iteration without complex tools or manual editing.
PlayAI
Play.ht is an AI voice generator and text-to-speech platform for creating humanlike voiceovers in minutes. It offers a large, growing library of natural voices across 30+ languages and accents, with controls for pitch, pace, emphasis, pauses, and SSML. Dialog-enabled generation supports multi-speaker, multi-turn conversations in a single file, ideal for podcasts and character-driven audio. Teams can define and reuse pronunciations for brand terms, preview segments, and fine-tune emotion and speaking styles. Voice cloning and custom voice creation enable consistent brand sound, while ultra-low-latency streaming suits live apps. Use cases span videos, audiobooks, training, assistants, games, IVR, and localization.
PlayAI
Play.ht is an AI voice generator and text-to-speech platform for creating humanlike voiceovers in minutes. It offers a large, growing library of natural voices across 30+ languages and accents, with controls for pitch, pace, emphasis, pauses, and SSML. Dialog-enabled generation supports multi-speaker, multi-turn conversations in a single file, ideal for podcasts and character-driven audio. Teams can define and reuse pronunciations for brand terms, preview segments, and fine-tune emotion and speaking styles. Voice cloning and custom voice creation enable consistent brand sound, while ultra-low-latency streaming suits live apps. Use cases span videos, audiobooks, training, assistants, games, IVR, and localization.
PlayAI
Play.ht is an AI voice generator and text-to-speech platform for creating humanlike voiceovers in minutes. It offers a large, growing library of natural voices across 30+ languages and accents, with controls for pitch, pace, emphasis, pauses, and SSML. Dialog-enabled generation supports multi-speaker, multi-turn conversations in a single file, ideal for podcasts and character-driven audio. Teams can define and reuse pronunciations for brand terms, preview segments, and fine-tune emotion and speaking styles. Voice cloning and custom voice creation enable consistent brand sound, while ultra-low-latency streaming suits live apps. Use cases span videos, audiobooks, training, assistants, games, IVR, and localization.

Resemble.AI
Resemble AI is an enterprise-focused Voice AI platform built on trust, offering realistic voice generation, voice cloning, and multi-modal deepfake detection across audio, image, and video. It provides real-time text-to-speech and speech-to-speech backed by advanced models like Chatterbox, plus watermarking for provenance and intelligence features for language, dialect, and anomaly detection. Teams can create branded, controllable voices, edit audio by typing, and deploy voice agents with developer-ready tooling. The platform also enables on-premises or private deployment for stricter compliance. With integrated security awareness training and automated monitoring, Resemble helps organizations scale voice experiences while defending against synthetic media risks.
Resemble.AI
Resemble AI is an enterprise-focused Voice AI platform built on trust, offering realistic voice generation, voice cloning, and multi-modal deepfake detection across audio, image, and video. It provides real-time text-to-speech and speech-to-speech backed by advanced models like Chatterbox, plus watermarking for provenance and intelligence features for language, dialect, and anomaly detection. Teams can create branded, controllable voices, edit audio by typing, and deploy voice agents with developer-ready tooling. The platform also enables on-premises or private deployment for stricter compliance. With integrated security awareness training and automated monitoring, Resemble helps organizations scale voice experiences while defending against synthetic media risks.
Resemble.AI
Resemble AI is an enterprise-focused Voice AI platform built on trust, offering realistic voice generation, voice cloning, and multi-modal deepfake detection across audio, image, and video. It provides real-time text-to-speech and speech-to-speech backed by advanced models like Chatterbox, plus watermarking for provenance and intelligence features for language, dialect, and anomaly detection. Teams can create branded, controllable voices, edit audio by typing, and deploy voice agents with developer-ready tooling. The platform also enables on-premises or private deployment for stricter compliance. With integrated security awareness training and automated monitoring, Resemble helps organizations scale voice experiences while defending against synthetic media risks.

Voice.ai
Voice.ai is an AI voice platform that delivers realistic voice agents, studio-quality text-to-speech, rapid voice cloning, and a free real-time voice changer all in one system. Businesses can deploy human-like AI phone agents for 24/7 inbound and outbound calls, lead qualification, appointment booking, and customer conversations that integrate seamlessly with CRM tools like Salesforce and HubSpot. It generates lifelike TTS audio in 15+ languages with accent localization, clones voices from just 10 seconds of sample audio, and offers a free voice changer for gamers and streamers to switch voices live. With enterprise compliance including GDPR, SOC 2, and HIPAA plus cloud or on-premise deployment options.
Voice.ai
Voice.ai is an AI voice platform that delivers realistic voice agents, studio-quality text-to-speech, rapid voice cloning, and a free real-time voice changer all in one system. Businesses can deploy human-like AI phone agents for 24/7 inbound and outbound calls, lead qualification, appointment booking, and customer conversations that integrate seamlessly with CRM tools like Salesforce and HubSpot. It generates lifelike TTS audio in 15+ languages with accent localization, clones voices from just 10 seconds of sample audio, and offers a free voice changer for gamers and streamers to switch voices live. With enterprise compliance including GDPR, SOC 2, and HIPAA plus cloud or on-premise deployment options.
Voice.ai
Voice.ai is an AI voice platform that delivers realistic voice agents, studio-quality text-to-speech, rapid voice cloning, and a free real-time voice changer all in one system. Businesses can deploy human-like AI phone agents for 24/7 inbound and outbound calls, lead qualification, appointment booking, and customer conversations that integrate seamlessly with CRM tools like Salesforce and HubSpot. It generates lifelike TTS audio in 15+ languages with accent localization, clones voices from just 10 seconds of sample audio, and offers a free voice changer for gamers and streamers to switch voices live. With enterprise compliance including GDPR, SOC 2, and HIPAA plus cloud or on-premise deployment options.
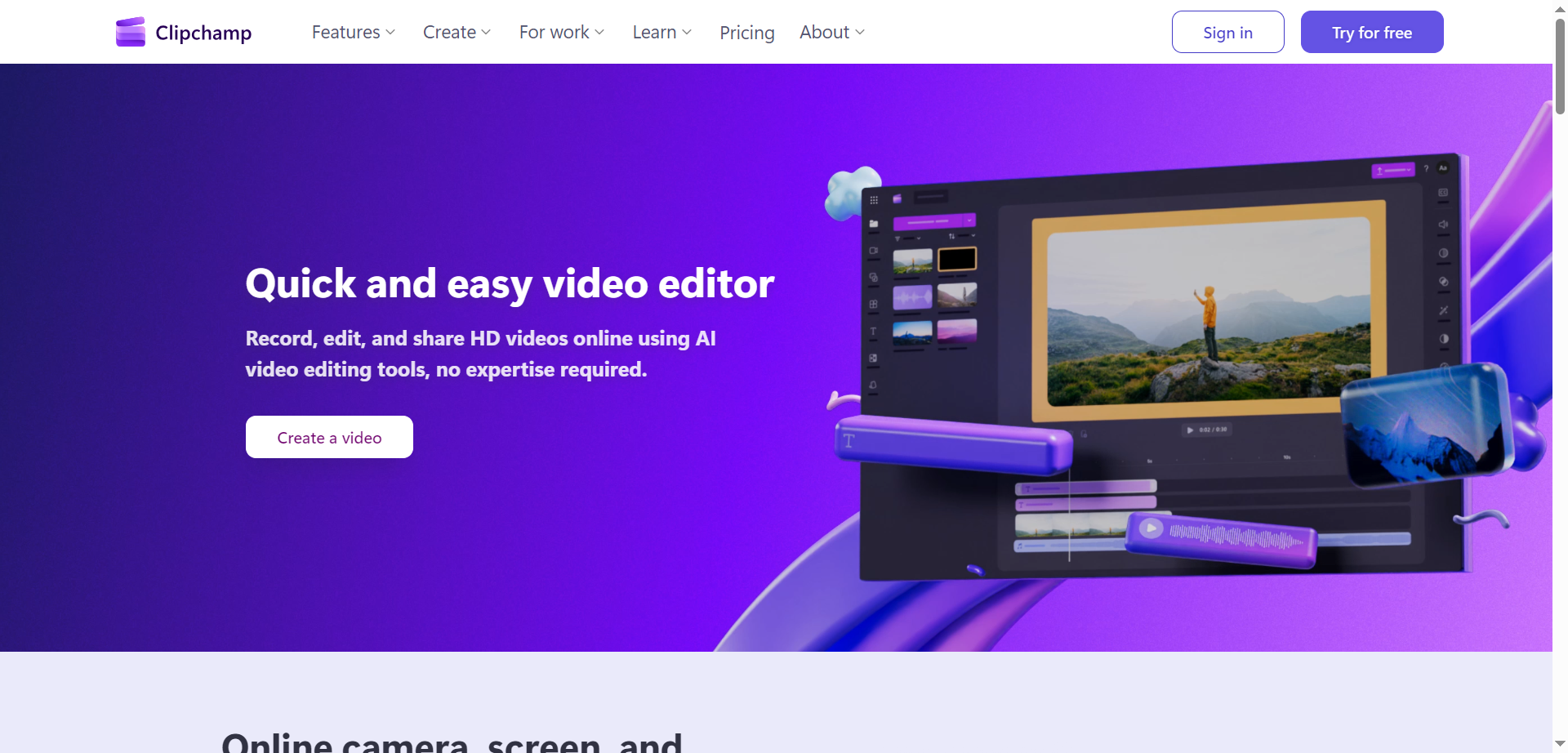

Clipchamp
Clipchamp is a user-friendly, AI-powered video editing platform by Microsoft that makes professional video creation accessible to everyone, no expertise required. It offers seamless recording of screen, webcam, and voice, plus smart AI tools like subtitle generators in over 80 languages, natural voiceovers from text, and audio enhancers that remove noise, pauses, and filler words. Users can access royalty-free stock videos, images, music, stickers, and effects, with easy trimming, cropping, green screen, and exports in HD without watermarks—all via browser, Windows app, or iOS.
Clipchamp
Clipchamp is a user-friendly, AI-powered video editing platform by Microsoft that makes professional video creation accessible to everyone, no expertise required. It offers seamless recording of screen, webcam, and voice, plus smart AI tools like subtitle generators in over 80 languages, natural voiceovers from text, and audio enhancers that remove noise, pauses, and filler words. Users can access royalty-free stock videos, images, music, stickers, and effects, with easy trimming, cropping, green screen, and exports in HD without watermarks—all via browser, Windows app, or iOS.
Clipchamp
Clipchamp is a user-friendly, AI-powered video editing platform by Microsoft that makes professional video creation accessible to everyone, no expertise required. It offers seamless recording of screen, webcam, and voice, plus smart AI tools like subtitle generators in over 80 languages, natural voiceovers from text, and audio enhancers that remove noise, pauses, and filler words. Users can access royalty-free stock videos, images, music, stickers, and effects, with easy trimming, cropping, green screen, and exports in HD without watermarks—all via browser, Windows app, or iOS.
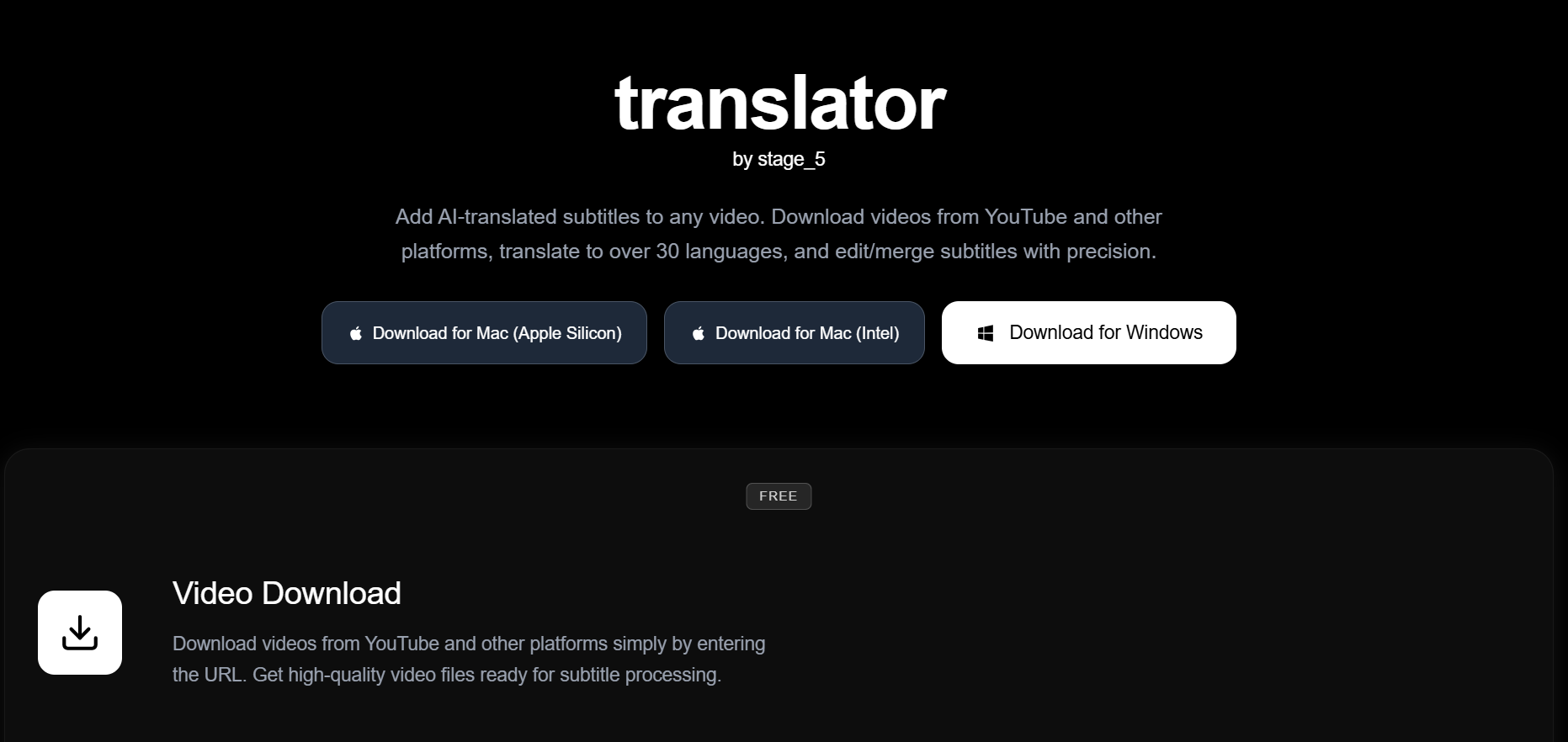
translator.tools
Translator.tools is an AI-powered subtitle translation platform that enables users to add multilingual subtitles to videos with precision. It allows downloading videos from platforms such as YouTube, translating subtitles into more than 30 languages, and editing or merging subtitle files accurately. Designed for content creators, educators, and media professionals, the tool simplifies the process of making videos accessible to global audiences. Its focus on subtitle accuracy and control ensures translations remain aligned with timing and context.
translator.tools
Translator.tools is an AI-powered subtitle translation platform that enables users to add multilingual subtitles to videos with precision. It allows downloading videos from platforms such as YouTube, translating subtitles into more than 30 languages, and editing or merging subtitle files accurately. Designed for content creators, educators, and media professionals, the tool simplifies the process of making videos accessible to global audiences. Its focus on subtitle accuracy and control ensures translations remain aligned with timing and context.
translator.tools
Translator.tools is an AI-powered subtitle translation platform that enables users to add multilingual subtitles to videos with precision. It allows downloading videos from platforms such as YouTube, translating subtitles into more than 30 languages, and editing or merging subtitle files accurately. Designed for content creators, educators, and media professionals, the tool simplifies the process of making videos accessible to global audiences. Its focus on subtitle accuracy and control ensures translations remain aligned with timing and context.
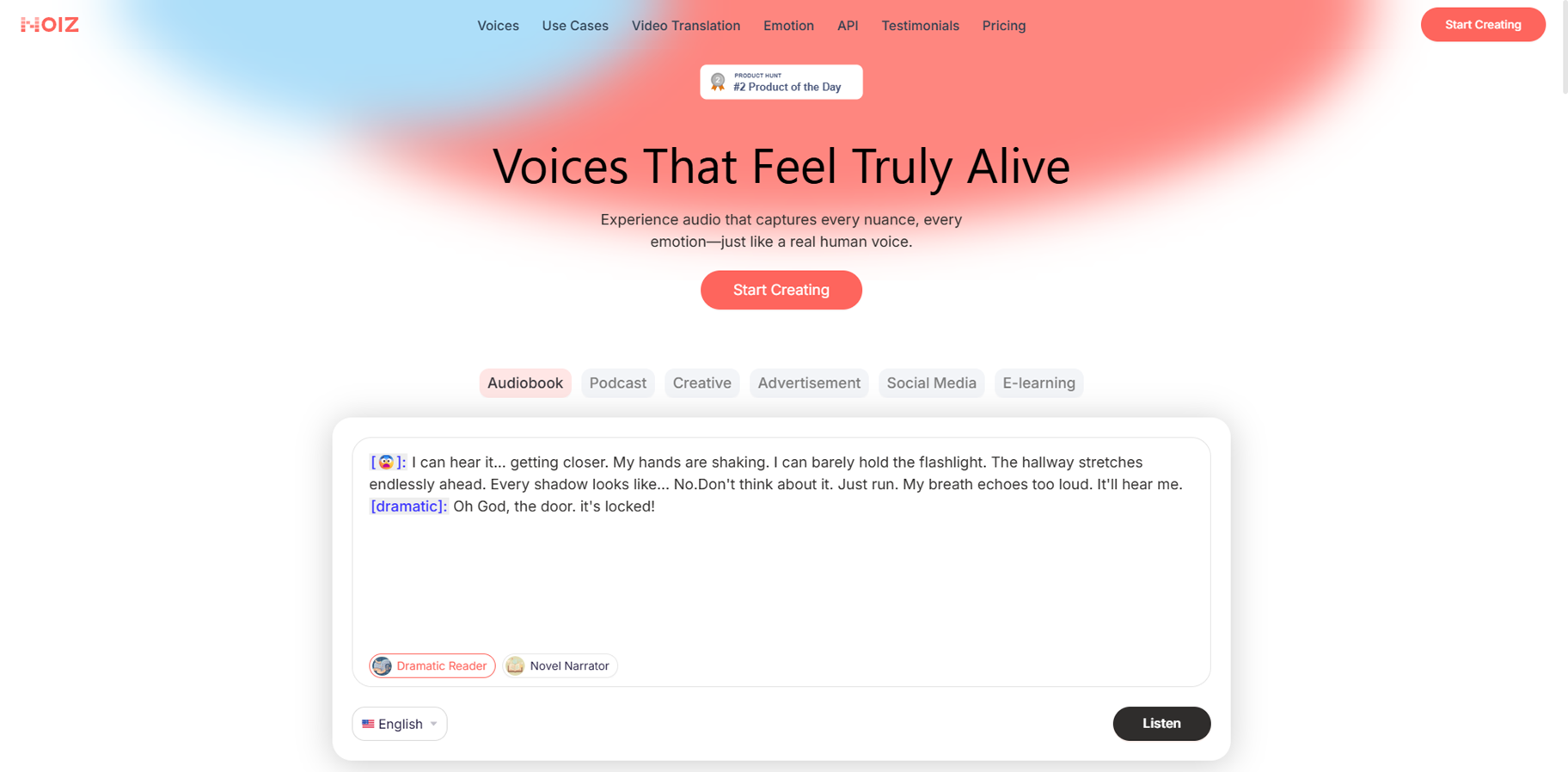

Noiz
Noiz is a leading AI platform for advanced speech synthesis and audio generation, specializing in highly expressive, lifelike voices with emotional control and customization. It offers text-to-speech , voice cloning, multilingual dubbing, AI singing voice generation, and developer APIs for seamless integration into apps. Users can create realistic vocals with nuance, vibrato, and dynamics from simple prompts, supporting video translation, audio editing, and music production. The tool excels in cost-efficiency, handling everything from podcast mastering to viral song covers, with features like noise removal, auto-leveling, and scene-based soundscapes. Ideal for creators seeking professional audio without studios.
Noiz
Noiz is a leading AI platform for advanced speech synthesis and audio generation, specializing in highly expressive, lifelike voices with emotional control and customization. It offers text-to-speech , voice cloning, multilingual dubbing, AI singing voice generation, and developer APIs for seamless integration into apps. Users can create realistic vocals with nuance, vibrato, and dynamics from simple prompts, supporting video translation, audio editing, and music production. The tool excels in cost-efficiency, handling everything from podcast mastering to viral song covers, with features like noise removal, auto-leveling, and scene-based soundscapes. Ideal for creators seeking professional audio without studios.
Noiz
Noiz is a leading AI platform for advanced speech synthesis and audio generation, specializing in highly expressive, lifelike voices with emotional control and customization. It offers text-to-speech , voice cloning, multilingual dubbing, AI singing voice generation, and developer APIs for seamless integration into apps. Users can create realistic vocals with nuance, vibrato, and dynamics from simple prompts, supporting video translation, audio editing, and music production. The tool excels in cost-efficiency, handling everything from podcast mastering to viral song covers, with features like noise removal, auto-leveling, and scene-based soundscapes. Ideal for creators seeking professional audio without studios.
Editorial Note
This page was researched and written by the ATB Editorial Team. Our team researches each AI tool by reviewing its official website, testing features, exploring real use cases, and considering user feedback. Every page is fact-checked and regularly updated to ensure the information stays accurate, neutral, and useful for our readers.
If you have any suggestions or questions, email us at hello@aitoolbook.ai