Its intuitive interface allows easy input of text scripts, adjustment of speech parameters such as speed and pitch, and immediate generation of audio outputs. Additionally, UseVoe provides API access for seamless integration into applications, games, or multimedia projects. It is useful for producing podcasts, audiobooks, instructional content, advertisements, and more.
- Content Creators and Podcasters: Generate voiceovers quickly without recording.
- Marketers and Advertisers: Produce audio ads and promotional materials.
- Educators and Trainers: Create narrated e-learning and instructional content.
- Developers and Game Designers: Integrate custom voices into apps and games.
- Businesses: Use for IVR systems, announcements, and customer engagement.
How to Use It?
- Sign Up or Log In: Create an account on the UseVoe platform.
- Input Text Script: Paste or type the text to be converted to speech.
- Choose Voice: Select a pre-built voice or upload data to train a custom voice.
- Adjust Settings: Modify pitch, speed, and tone as needed.
- Generate Audio: Create the voiceover and preview the output.
- Download or Integrate: Export audio files or use API for embedding in projects.
- Custom Voice Cloning: Ability to create personalized voices from user data.
- Multi-Language Support: Includes many languages and accents.
- API Access: Facilitates easy integration into other software.
- High-Quality Realistic Speech: Natural intonation and clarity.
- User Privacy and Security: Safeguards voice data and personal information.
- Flexible Plans: Includes free trials and scalable pricing options.
- Produces natural-sounding, high-quality voiceovers.
- Easy-to-use interface for non-experts.
- Supports voice customization and training.
- Wide range of languages and accents.
- Suitable for many industries and use cases.
- Custom voice training may require additional data and time.
- Free tier has limited usage and features.
- No offline functionality; requires internet connection.
- Pricing may be high for extensive commercial use.
- Some voices may sound less natural depending on input quality.
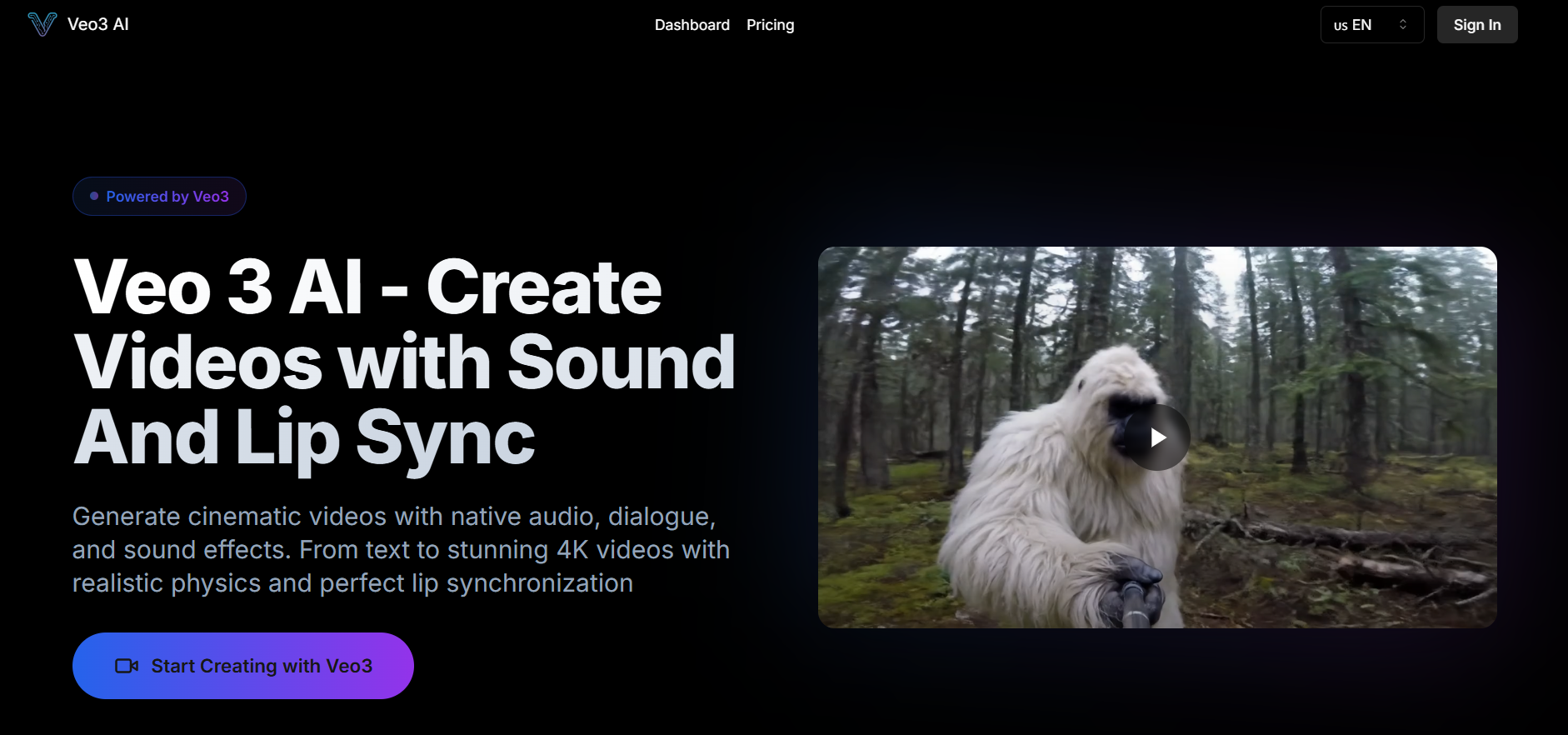
Basic
$ 29.90
- 1500 Credits/month
- No watermark
- Up to 5s video length
- 720p video quality
- Faster generation
- Image generator(Schnell, Dev, Pro Model)
- 2 concurrent generation tasks
- Private video creation
- Commercial use
- Email Notification
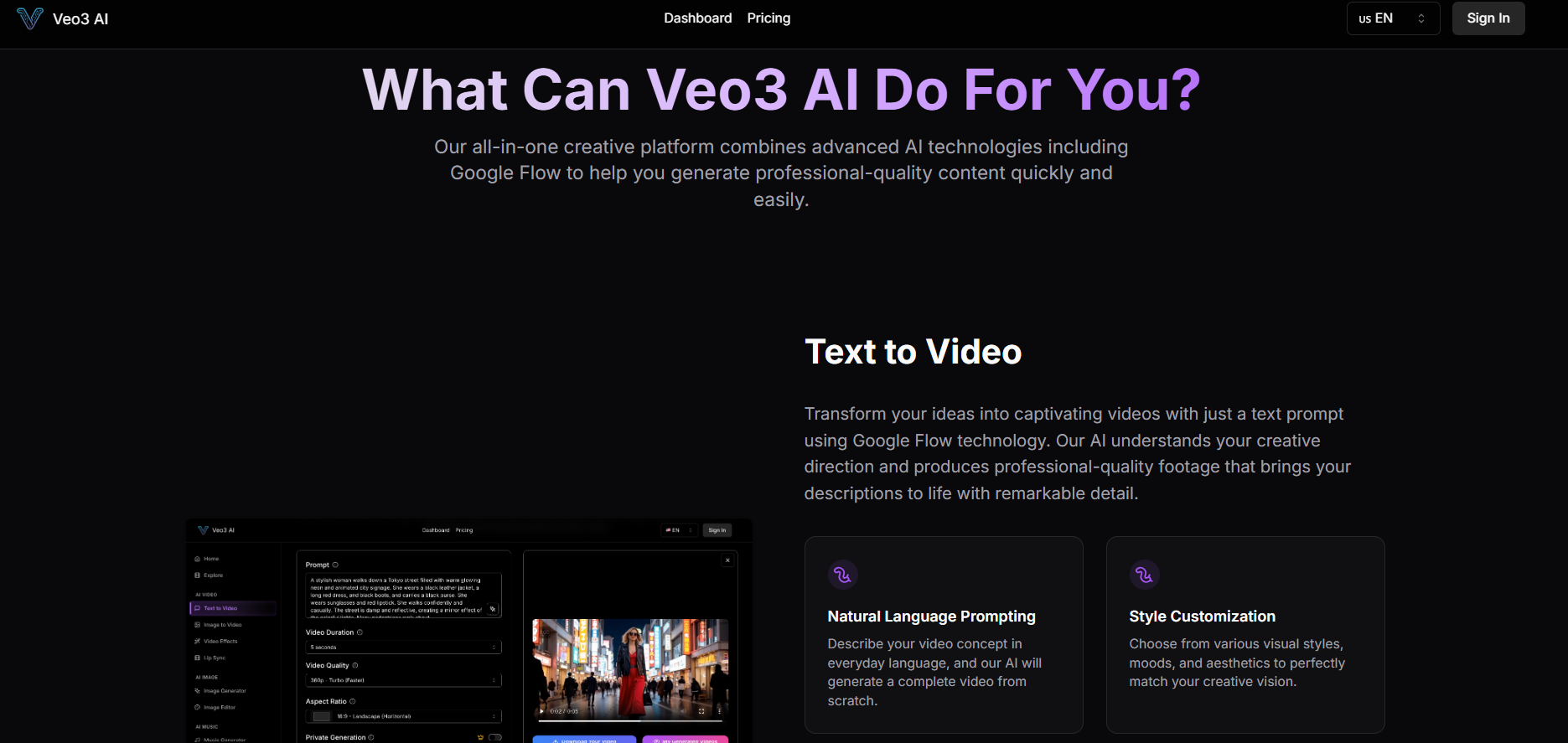
Standard
$ 49.90
- 4000 Credits/month
- No watermark
- Up to 8s video length
- 720p video quality
- Faster generation
- Image generator(Schnell, Dev, Pro Model)
- 4 concurrent generation tasks
- Private video creation
- Commercial use
- Email Notification
Pro
$ 99.90
- 10000 Credits/month
- No watermark
- Faster generation
- Up to 8s video length
- 720p video quality
- Image generator(Schnell, Dev, Pro Model)
- 8 concurrent generation tasks
- Private video creation
- Commercial use
- Email Notification
Proud of the love you're getting? Show off your AI Toolbook reviews—then invite more fans to share the love and build your credibility.
Add an AI Toolbook badge to your site—an easy way to drive followers, showcase updates, and collect reviews. It's like a mini 24/7 billboard for your AI.
Reviews
Rating Distribution
Average score
Popular Mention
FAQs
Similar AI Tools

XSAudio
XSAudio is a powerful AI audio platform offering text-to-speech, voice cloning, and sound effect generation. With realistic voice libraries, custom cloning, and multilingual support, it’s perfect for creators, developers, and businesses needing high-quality audio fast. Use it for videos, podcasts, games, and more—with daily free credits and API access.
XSAudio
XSAudio is a powerful AI audio platform offering text-to-speech, voice cloning, and sound effect generation. With realistic voice libraries, custom cloning, and multilingual support, it’s perfect for creators, developers, and businesses needing high-quality audio fast. Use it for videos, podcasts, games, and more—with daily free credits and API access.
XSAudio
XSAudio is a powerful AI audio platform offering text-to-speech, voice cloning, and sound effect generation. With realistic voice libraries, custom cloning, and multilingual support, it’s perfect for creators, developers, and businesses needing high-quality audio fast. Use it for videos, podcasts, games, and more—with daily free credits and API access.

Parrot Talk
Parrot Talk, often referred to as Parrot AI, is an AI-powered voice cloner, generator, and video creation tool. It allows users to clone their own voices from a simple recording, as well as generate realistic audio and videos using a vast library of 100+ celebrity-style AI voices. The platform enables users to create engaging content by converting text to speech, generating AI music from YouTube URLs, and creating short videos with lip-syncing and facial expressions. It's primarily designed for creating funny, entertaining, and creative audio and video clips.
Parrot Talk
Parrot Talk, often referred to as Parrot AI, is an AI-powered voice cloner, generator, and video creation tool. It allows users to clone their own voices from a simple recording, as well as generate realistic audio and videos using a vast library of 100+ celebrity-style AI voices. The platform enables users to create engaging content by converting text to speech, generating AI music from YouTube URLs, and creating short videos with lip-syncing and facial expressions. It's primarily designed for creating funny, entertaining, and creative audio and video clips.
Parrot Talk
Parrot Talk, often referred to as Parrot AI, is an AI-powered voice cloner, generator, and video creation tool. It allows users to clone their own voices from a simple recording, as well as generate realistic audio and videos using a vast library of 100+ celebrity-style AI voices. The platform enables users to create engaging content by converting text to speech, generating AI music from YouTube URLs, and creating short videos with lip-syncing and facial expressions. It's primarily designed for creating funny, entertaining, and creative audio and video clips.
a2e.ai
A2E.ai is an AI video platform that generates lifelike avatar videos with precise lip-sync, voice cloning, and image-to-video synthesis, all in the browser and via API access. It offers a complete avatar toolset—including streaming avatars, talking photos, and face swap—designed for rapid, scalable content creation without cameras or studios. With ElevenLabs-powered voice clone, 50+ language support, and cross-language translation, A2E.ai delivers persuasive, multilingual videos for marketing, e-learning, and internal communications. Developers can integrate features through an MCP-ready API, while teams benefit from ultra-fast generation, beginner-friendly workflows, and cost-effectiveness.
a2e.ai
A2E.ai is an AI video platform that generates lifelike avatar videos with precise lip-sync, voice cloning, and image-to-video synthesis, all in the browser and via API access. It offers a complete avatar toolset—including streaming avatars, talking photos, and face swap—designed for rapid, scalable content creation without cameras or studios. With ElevenLabs-powered voice clone, 50+ language support, and cross-language translation, A2E.ai delivers persuasive, multilingual videos for marketing, e-learning, and internal communications. Developers can integrate features through an MCP-ready API, while teams benefit from ultra-fast generation, beginner-friendly workflows, and cost-effectiveness.
a2e.ai
A2E.ai is an AI video platform that generates lifelike avatar videos with precise lip-sync, voice cloning, and image-to-video synthesis, all in the browser and via API access. It offers a complete avatar toolset—including streaming avatars, talking photos, and face swap—designed for rapid, scalable content creation without cameras or studios. With ElevenLabs-powered voice clone, 50+ language support, and cross-language translation, A2E.ai delivers persuasive, multilingual videos for marketing, e-learning, and internal communications. Developers can integrate features through an MCP-ready API, while teams benefit from ultra-fast generation, beginner-friendly workflows, and cost-effectiveness.
PERSO.ai
Perso.ai is an AI-powered video localization platform that enables creators, educators, and businesses to produce high-quality, multilingual videos effortlessly. It offers features like voice cloning, lip-sync dubbing, and real-time script editing, making global content creation accessible to everyone.
PERSO.ai
Perso.ai is an AI-powered video localization platform that enables creators, educators, and businesses to produce high-quality, multilingual videos effortlessly. It offers features like voice cloning, lip-sync dubbing, and real-time script editing, making global content creation accessible to everyone.
PERSO.ai
Perso.ai is an AI-powered video localization platform that enables creators, educators, and businesses to produce high-quality, multilingual videos effortlessly. It offers features like voice cloning, lip-sync dubbing, and real-time script editing, making global content creation accessible to everyone.

Wondera
Wondera is an AI music co-creator and visualizer platform that helps musicians and creators generate, edit, and publish original music and synced music videos from simple prompts or uploaded references. It blends an AI music generator, stem editor, voice conversion, and effect controls with a free music video generator that aligns visuals to rhythm and mood. Users can refine melodies, swap instruments, change genres, and craft artist personas, then publish or download tracks for use in videos, podcasts, and social media. With mobile apps and web tools, Wondera streamlines end‑to‑end music production, from idea to mastered audio and dynamic visuals.
Wondera
Wondera is an AI music co-creator and visualizer platform that helps musicians and creators generate, edit, and publish original music and synced music videos from simple prompts or uploaded references. It blends an AI music generator, stem editor, voice conversion, and effect controls with a free music video generator that aligns visuals to rhythm and mood. Users can refine melodies, swap instruments, change genres, and craft artist personas, then publish or download tracks for use in videos, podcasts, and social media. With mobile apps and web tools, Wondera streamlines end‑to‑end music production, from idea to mastered audio and dynamic visuals.
Wondera
Wondera is an AI music co-creator and visualizer platform that helps musicians and creators generate, edit, and publish original music and synced music videos from simple prompts or uploaded references. It blends an AI music generator, stem editor, voice conversion, and effect controls with a free music video generator that aligns visuals to rhythm and mood. Users can refine melodies, swap instruments, change genres, and craft artist personas, then publish or download tracks for use in videos, podcasts, and social media. With mobile apps and web tools, Wondera streamlines end‑to‑end music production, from idea to mastered audio and dynamic visuals.
Voiceslab
Voiceslab is an AI voice cloning and synthesis platform that enables users to create digital replicas of their voice from a short audio sample. By uploading or recording about 10–60 seconds of speech, the system analyzes tone, speech patterns, and style to generate a custom voice model. After that, users can input text to produce natural-sounding speech in their cloned voice across multiple languages. The tool is suited for content creators, marketers, podcasters, and businesses wanting to scale voice content without repeated recording.
Voiceslab
Voiceslab is an AI voice cloning and synthesis platform that enables users to create digital replicas of their voice from a short audio sample. By uploading or recording about 10–60 seconds of speech, the system analyzes tone, speech patterns, and style to generate a custom voice model. After that, users can input text to produce natural-sounding speech in their cloned voice across multiple languages. The tool is suited for content creators, marketers, podcasters, and businesses wanting to scale voice content without repeated recording.
Voiceslab
Voiceslab is an AI voice cloning and synthesis platform that enables users to create digital replicas of their voice from a short audio sample. By uploading or recording about 10–60 seconds of speech, the system analyzes tone, speech patterns, and style to generate a custom voice model. After that, users can input text to produce natural-sounding speech in their cloned voice across multiple languages. The tool is suited for content creators, marketers, podcasters, and businesses wanting to scale voice content without repeated recording.
PlayAI
Play.ht is an AI voice generator and text-to-speech platform for creating humanlike voiceovers in minutes. It offers a large, growing library of natural voices across 30+ languages and accents, with controls for pitch, pace, emphasis, pauses, and SSML. Dialog-enabled generation supports multi-speaker, multi-turn conversations in a single file, ideal for podcasts and character-driven audio. Teams can define and reuse pronunciations for brand terms, preview segments, and fine-tune emotion and speaking styles. Voice cloning and custom voice creation enable consistent brand sound, while ultra-low-latency streaming suits live apps. Use cases span videos, audiobooks, training, assistants, games, IVR, and localization.
PlayAI
Play.ht is an AI voice generator and text-to-speech platform for creating humanlike voiceovers in minutes. It offers a large, growing library of natural voices across 30+ languages and accents, with controls for pitch, pace, emphasis, pauses, and SSML. Dialog-enabled generation supports multi-speaker, multi-turn conversations in a single file, ideal for podcasts and character-driven audio. Teams can define and reuse pronunciations for brand terms, preview segments, and fine-tune emotion and speaking styles. Voice cloning and custom voice creation enable consistent brand sound, while ultra-low-latency streaming suits live apps. Use cases span videos, audiobooks, training, assistants, games, IVR, and localization.
PlayAI
Play.ht is an AI voice generator and text-to-speech platform for creating humanlike voiceovers in minutes. It offers a large, growing library of natural voices across 30+ languages and accents, with controls for pitch, pace, emphasis, pauses, and SSML. Dialog-enabled generation supports multi-speaker, multi-turn conversations in a single file, ideal for podcasts and character-driven audio. Teams can define and reuse pronunciations for brand terms, preview segments, and fine-tune emotion and speaking styles. Voice cloning and custom voice creation enable consistent brand sound, while ultra-low-latency streaming suits live apps. Use cases span videos, audiobooks, training, assistants, games, IVR, and localization.
FakeYou
FakeYou is a community-driven AI voice platform that converts text into speech using a large catalog of celebrity, character, and creator-trained voices. It emphasizes ease of use for quick meme audio, voiceovers, and creative projects, while also supporting longer scripts with stable generation. Users select from many fan-made and studio-quality voice models, then fine-tune outputs with controls like pace and emphasis for better delivery. The platform focuses on fun, experimentation, and shareability, letting creators generate clips for videos, streams, and social posts. With a lively community and frequent new voices, FakeYou makes voice cloning and character TTS accessible for everyday content creation.
FakeYou
FakeYou is a community-driven AI voice platform that converts text into speech using a large catalog of celebrity, character, and creator-trained voices. It emphasizes ease of use for quick meme audio, voiceovers, and creative projects, while also supporting longer scripts with stable generation. Users select from many fan-made and studio-quality voice models, then fine-tune outputs with controls like pace and emphasis for better delivery. The platform focuses on fun, experimentation, and shareability, letting creators generate clips for videos, streams, and social posts. With a lively community and frequent new voices, FakeYou makes voice cloning and character TTS accessible for everyday content creation.
FakeYou
FakeYou is a community-driven AI voice platform that converts text into speech using a large catalog of celebrity, character, and creator-trained voices. It emphasizes ease of use for quick meme audio, voiceovers, and creative projects, while also supporting longer scripts with stable generation. Users select from many fan-made and studio-quality voice models, then fine-tune outputs with controls like pace and emphasis for better delivery. The platform focuses on fun, experimentation, and shareability, letting creators generate clips for videos, streams, and social posts. With a lively community and frequent new voices, FakeYou makes voice cloning and character TTS accessible for everyday content creation.
AI Awaaz
Ai Awaaz is a text-to-speech (TTS) and voice-generation platform developed in India and marketed as India’s first emotion-based TTS AI engine. It enables users to convert text into natural-sounding voiceovers in 20+ Indian languages and 140+ voices, with selectable emotions (e.g., cheerful, sad, whispering) and export formats suitable for videos, podcasts, audiobooks and e-learning modules. The platform emphasises speed and scalability, claiming that a voiceover can be created in just minutes, compared to traditional voice-actor turnaround times. It is positioned for marketers, educators, content creators and agencies needing multi-language voice production with minimal friction.
AI Awaaz
Ai Awaaz is a text-to-speech (TTS) and voice-generation platform developed in India and marketed as India’s first emotion-based TTS AI engine. It enables users to convert text into natural-sounding voiceovers in 20+ Indian languages and 140+ voices, with selectable emotions (e.g., cheerful, sad, whispering) and export formats suitable for videos, podcasts, audiobooks and e-learning modules. The platform emphasises speed and scalability, claiming that a voiceover can be created in just minutes, compared to traditional voice-actor turnaround times. It is positioned for marketers, educators, content creators and agencies needing multi-language voice production with minimal friction.
AI Awaaz
Ai Awaaz is a text-to-speech (TTS) and voice-generation platform developed in India and marketed as India’s first emotion-based TTS AI engine. It enables users to convert text into natural-sounding voiceovers in 20+ Indian languages and 140+ voices, with selectable emotions (e.g., cheerful, sad, whispering) and export formats suitable for videos, podcasts, audiobooks and e-learning modules. The platform emphasises speed and scalability, claiming that a voiceover can be created in just minutes, compared to traditional voice-actor turnaround times. It is positioned for marketers, educators, content creators and agencies needing multi-language voice production with minimal friction.

Voice.ai
Voice.ai is an AI voice platform that delivers realistic voice agents, studio-quality text-to-speech, rapid voice cloning, and a free real-time voice changer all in one system. Businesses can deploy human-like AI phone agents for 24/7 inbound and outbound calls, lead qualification, appointment booking, and customer conversations that integrate seamlessly with CRM tools like Salesforce and HubSpot. It generates lifelike TTS audio in 15+ languages with accent localization, clones voices from just 10 seconds of sample audio, and offers a free voice changer for gamers and streamers to switch voices live. With enterprise compliance including GDPR, SOC 2, and HIPAA plus cloud or on-premise deployment options.
Voice.ai
Voice.ai is an AI voice platform that delivers realistic voice agents, studio-quality text-to-speech, rapid voice cloning, and a free real-time voice changer all in one system. Businesses can deploy human-like AI phone agents for 24/7 inbound and outbound calls, lead qualification, appointment booking, and customer conversations that integrate seamlessly with CRM tools like Salesforce and HubSpot. It generates lifelike TTS audio in 15+ languages with accent localization, clones voices from just 10 seconds of sample audio, and offers a free voice changer for gamers and streamers to switch voices live. With enterprise compliance including GDPR, SOC 2, and HIPAA plus cloud or on-premise deployment options.
Voice.ai
Voice.ai is an AI voice platform that delivers realistic voice agents, studio-quality text-to-speech, rapid voice cloning, and a free real-time voice changer all in one system. Businesses can deploy human-like AI phone agents for 24/7 inbound and outbound calls, lead qualification, appointment booking, and customer conversations that integrate seamlessly with CRM tools like Salesforce and HubSpot. It generates lifelike TTS audio in 15+ languages with accent localization, clones voices from just 10 seconds of sample audio, and offers a free voice changer for gamers and streamers to switch voices live. With enterprise compliance including GDPR, SOC 2, and HIPAA plus cloud or on-premise deployment options.

Noiz
Noiz is a leading AI platform for advanced speech synthesis and audio generation, specializing in highly expressive, lifelike voices with emotional control and customization. It offers text-to-speech , voice cloning, multilingual dubbing, AI singing voice generation, and developer APIs for seamless integration into apps. Users can create realistic vocals with nuance, vibrato, and dynamics from simple prompts, supporting video translation, audio editing, and music production. The tool excels in cost-efficiency, handling everything from podcast mastering to viral song covers, with features like noise removal, auto-leveling, and scene-based soundscapes. Ideal for creators seeking professional audio without studios.
Noiz
Noiz is a leading AI platform for advanced speech synthesis and audio generation, specializing in highly expressive, lifelike voices with emotional control and customization. It offers text-to-speech , voice cloning, multilingual dubbing, AI singing voice generation, and developer APIs for seamless integration into apps. Users can create realistic vocals with nuance, vibrato, and dynamics from simple prompts, supporting video translation, audio editing, and music production. The tool excels in cost-efficiency, handling everything from podcast mastering to viral song covers, with features like noise removal, auto-leveling, and scene-based soundscapes. Ideal for creators seeking professional audio without studios.
Noiz
Noiz is a leading AI platform for advanced speech synthesis and audio generation, specializing in highly expressive, lifelike voices with emotional control and customization. It offers text-to-speech , voice cloning, multilingual dubbing, AI singing voice generation, and developer APIs for seamless integration into apps. Users can create realistic vocals with nuance, vibrato, and dynamics from simple prompts, supporting video translation, audio editing, and music production. The tool excels in cost-efficiency, handling everything from podcast mastering to viral song covers, with features like noise removal, auto-leveling, and scene-based soundscapes. Ideal for creators seeking professional audio without studios.
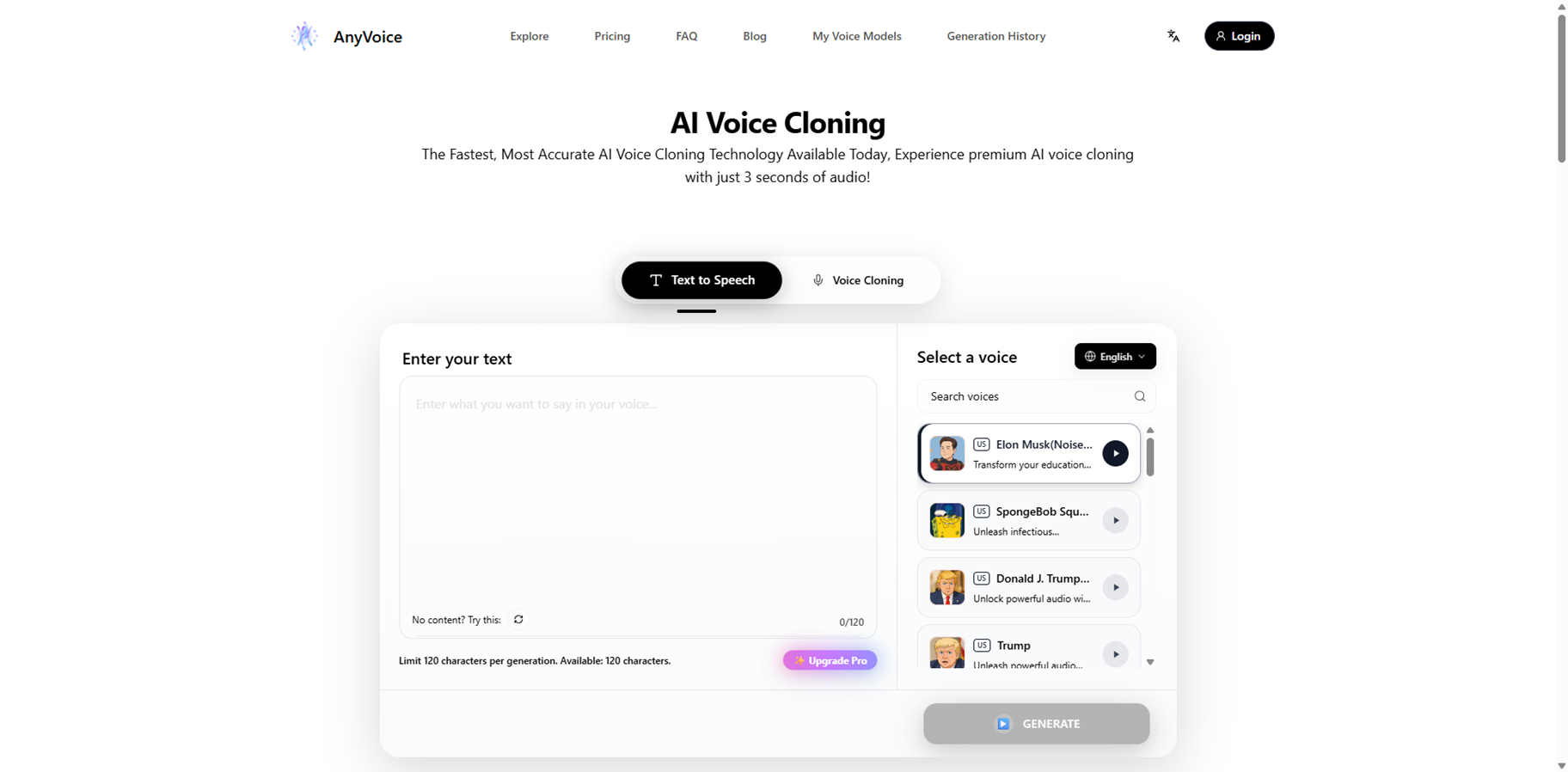

AnyVoice
AnyVoice brings the world's fastest AI voice cloning, turning just 3 seconds of audio into hyper-realistic speech that nails every nuance and emotion. Pick from English, Chinese Mandarin, Japanese, or Korean, enter your text, select the cloned voice, and get instant lifelike output—no long recordings or tech skills needed. Perfect for quick voiceovers, prototyping, or dynamic content, it delivers indistinguishable-from-human results securely with user privacy front and center. Free tier offers 900 seconds monthly and 5 clones; Pro unlocks unlimited everything and commercial rights. Streamlined interface makes pro-level cloning accessible to anyone, speeding up creation like never before.
AnyVoice
AnyVoice brings the world's fastest AI voice cloning, turning just 3 seconds of audio into hyper-realistic speech that nails every nuance and emotion. Pick from English, Chinese Mandarin, Japanese, or Korean, enter your text, select the cloned voice, and get instant lifelike output—no long recordings or tech skills needed. Perfect for quick voiceovers, prototyping, or dynamic content, it delivers indistinguishable-from-human results securely with user privacy front and center. Free tier offers 900 seconds monthly and 5 clones; Pro unlocks unlimited everything and commercial rights. Streamlined interface makes pro-level cloning accessible to anyone, speeding up creation like never before.
AnyVoice
AnyVoice brings the world's fastest AI voice cloning, turning just 3 seconds of audio into hyper-realistic speech that nails every nuance and emotion. Pick from English, Chinese Mandarin, Japanese, or Korean, enter your text, select the cloned voice, and get instant lifelike output—no long recordings or tech skills needed. Perfect for quick voiceovers, prototyping, or dynamic content, it delivers indistinguishable-from-human results securely with user privacy front and center. Free tier offers 900 seconds monthly and 5 clones; Pro unlocks unlimited everything and commercial rights. Streamlined interface makes pro-level cloning accessible to anyone, speeding up creation like never before.
Editorial Note
This page was researched and written by the ATB Editorial Team. Our team researches each AI tool by reviewing its official website, testing features, exploring real use cases, and considering user feedback. Every page is fact-checked and regularly updated to ensure the information stays accurate, neutral, and useful for our readers.
If you have any suggestions or questions, email us at hello@aitoolbook.ai