
- Students: Listen to textbooks, articles, notes, and online courses to absorb information faster and improve retention, especially beneficial for auditory learners or those with reading disabilities like dyslexia and ADHD.
- Professionals: Multitask by listening to emails, documents, reports, and industry news while commuting, exercising, or performing other activities, boosting productivity.
- Content Creators (Podcasters, YouTubers, Video Creators): Generate high-quality AI voiceovers, dub videos into multiple languages, clone voices, and create audio content efficiently without the need for traditional voice artists.
- Individuals with Reading Disabilities or Visual Impairments: Access written content more easily by converting it into spoken words with human-like voices.
- Language Learners: Improve listening skills and pronunciation in new languages by listening to text read aloud and practicing.
- Anyone Seeking Enhanced Productivity: Get through more reading material in less time by listening at faster speeds, optimizing content consumption.
How to Use Speechify.com?
- Install the App/Extension: Begin by downloading the Speechify app on your iPhone, iPad, Android, or Mac device, or install the convenient Chrome/Edge browser extension.
- Import Text: You can import text in several ways: upload PDFs, Word documents, or other compatible files; copy and paste text directly into the editor; or paste a web link to have an entire webpage read aloud. For physical content, use the mobile app to scan pages with your device's camera (OCR).
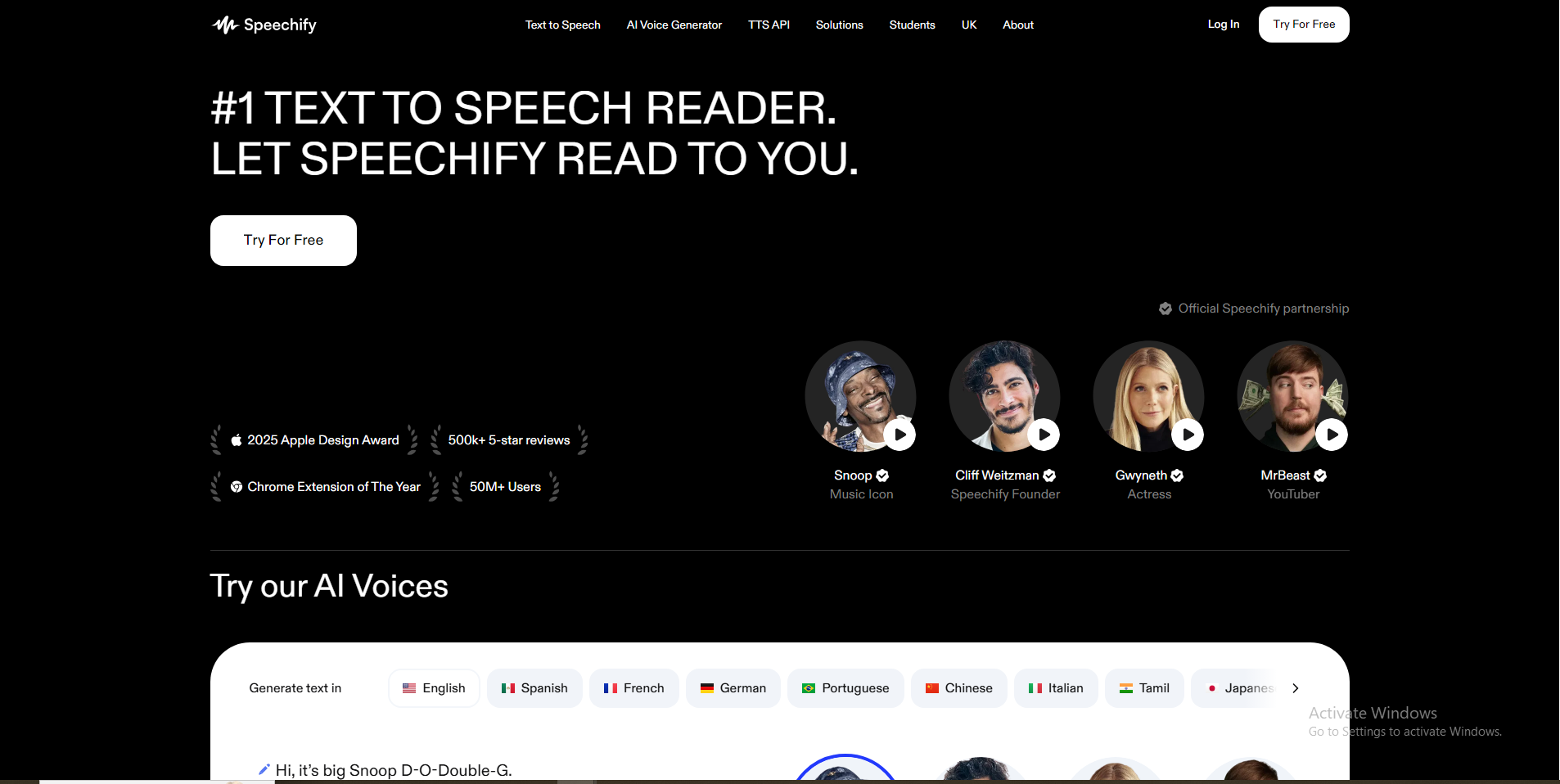
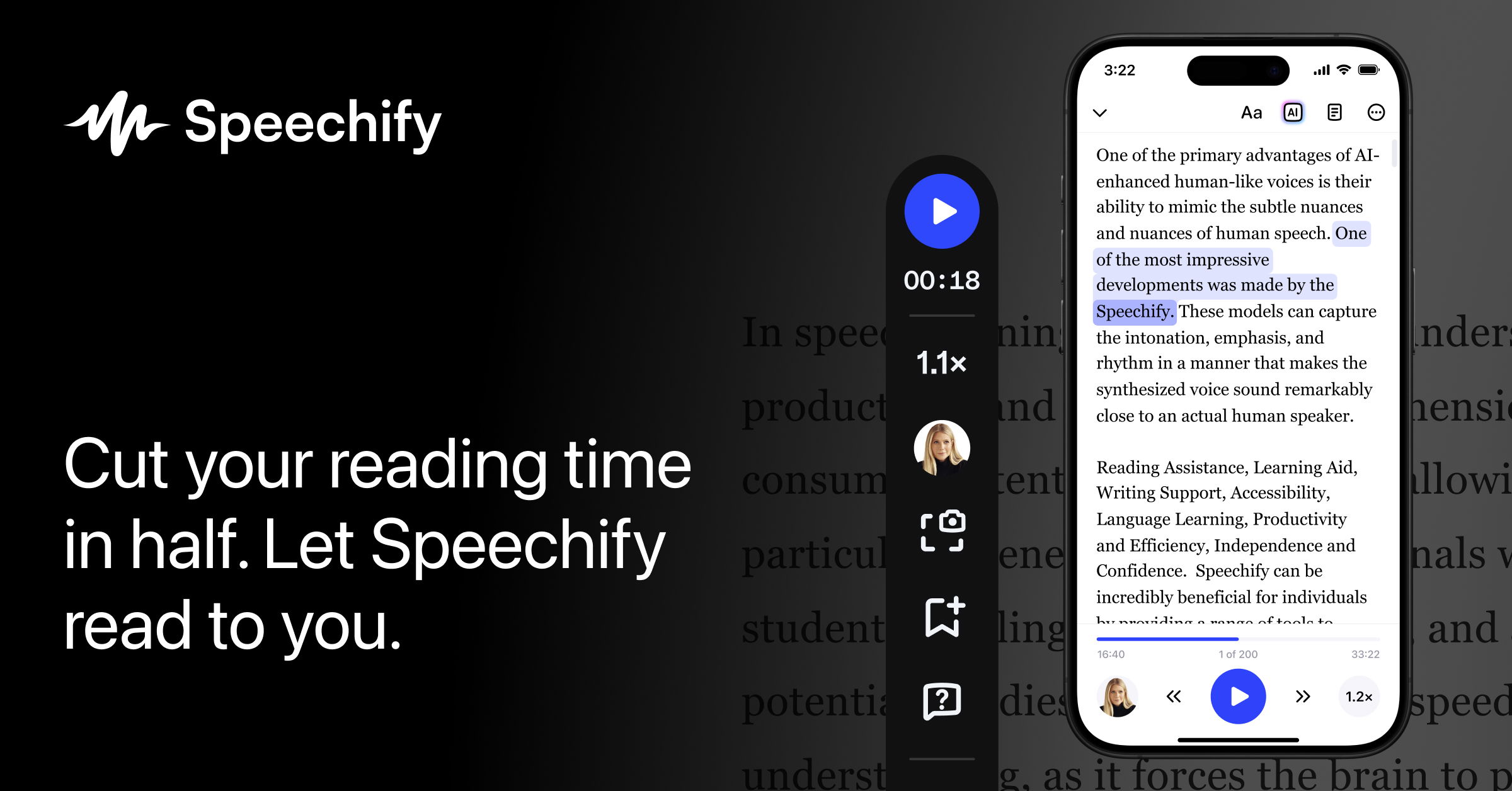
- Choose a Voice & Speed: Select from an extensive library of over 200 natural, lifelike AI voices available in 60+ languages, which may include licensed celebrity voices. Customize your listening experience by adjusting the reading speed.
- Human-Like AI Voices: Offers an extensive library of over 200 high-quality, natural-sounding AI voices across 60+ languages. These voices are often described as indistinguishable from human speech and include licensed celebrity voices, enhancing the listening experience.
- Multifaceted Platform: Available across almost all major platforms and devices (iOS, Android, Mac, Web, Chrome Extension, Edge Add-on), ensuring seamless content consumption and accessibility for users anywhere, anytime.
- Productivity-Focused Reading: Specifically designed to help users consume content 2-3x faster by leveraging auditory processing, enabling efficient multitasking and accelerated information absorption for busy individuals.
- Comprehensive AI Suite for Creators: Goes beyond basic text-to-speech, offering advanced tools for professional content creation such as AI voice generation from scripts, personal voice cloning, and AI dubbing for videos.
- Exceptional Voice Quality: Offers incredibly natural and human-like AI voices that enhance the listening experience.
- Broad Accessibility: Available across numerous devices and platforms, making it highly versatile.
- Significant Productivity Boost: Enables users to consume content much faster, facilitating multitasking.
- Rich Feature Set for Learning: Supports speed control, text highlighting, offline listening, and AI summaries/quizzes, making it an excellent study tool.
- Powerful Tools for Content Creation: Provides advanced AI voice generation, cloning, and dubbing capabilities for professionals.
- Addresses Accessibility Needs: A valuable resource for individuals with reading and visual impairments.
- User-Friendly Interface: Generally intuitive and easy to use across its various applications.
- Premium Pricing: While a free tier exists, full features and unlimited usage require a relatively expensive premium subscription.
- Internet Dependency (for some features): Some advanced features and real-time processing require a stable internet connection.
- Occasional Glitches (reported by some users): Some reviews mention occasional skipping of words or unpredictable pauses, though this might be related to earlier versions.
- Learning Curve for Advanced Features: While basic TTS is simple, utilizing the full suite of content creation tools may require some initial learning.

Free
$ 0.00
Listen anywhere
Monthly
$ 29.00
60+ different languages
Offline MP3 download
Listen at 5x faster speeds
Advanced skipping and importing
AI Summaries & Chats
Annual
$ 11.58
60+ different languages
Offline MP3 download
Listen at 5x faster speeds
Advanced skipping and importing
AI Summaries & Chats
Proud of the love you're getting? Show off your AI Toolbook reviews—then invite more fans to share the love and build your credibility.
Add an AI Toolbook badge to your site—an easy way to drive followers, showcase updates, and collect reviews. It's like a mini 24/7 billboard for your AI.
Reviews
Rating Distribution
Average score
Popular Mention
FAQs
Similar AI Tools
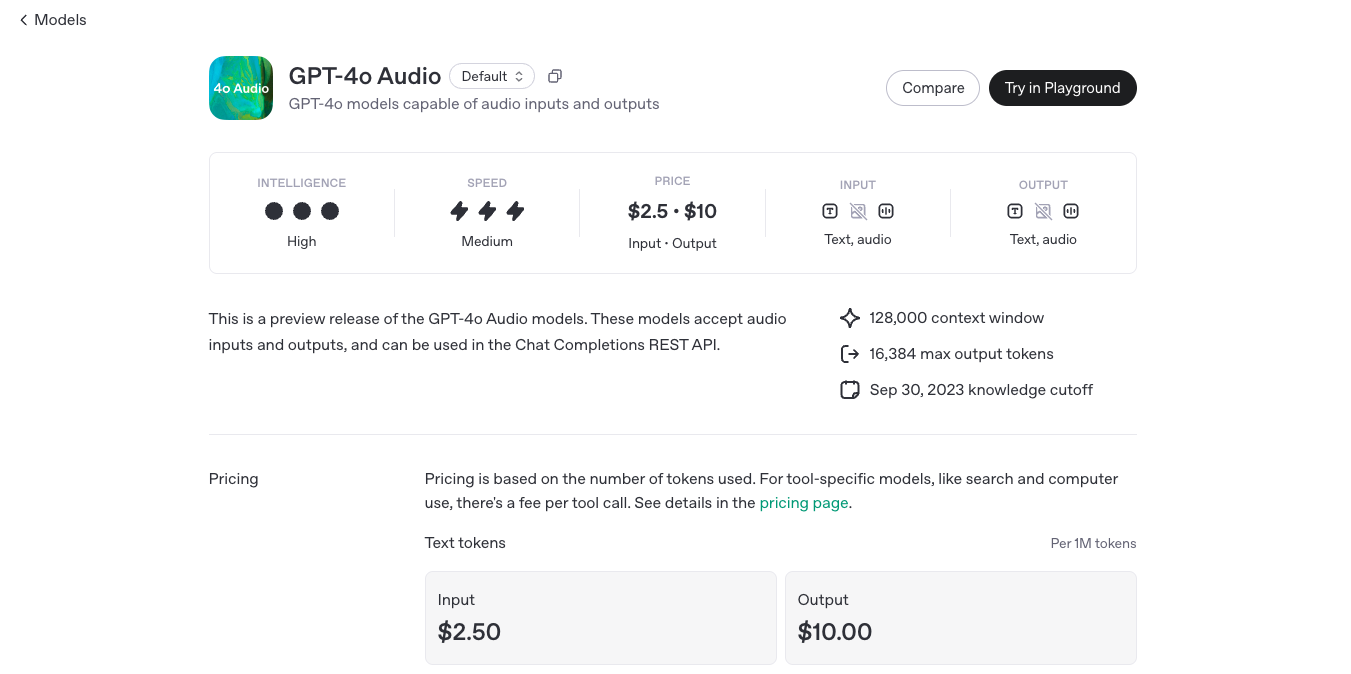
OpenAI GPT-4o Audio is an advanced real-time AI-powered voice assistant that enables instant, natural, and expressive conversations with AI. Unlike previous AI voice models, GPT-4o Audio can listen, understand, and respond within milliseconds, making interactions feel fluid and human-like. This model is designed to process and generate speech with emotion, tone, and contextual awareness, making it suitable for applications such as AI assistants, voice interactions, real-time translations, and accessibility tools.
OpenAI GPT-4o Audio is an advanced real-time AI-powered voice assistant that enables instant, natural, and expressive conversations with AI. Unlike previous AI voice models, GPT-4o Audio can listen, understand, and respond within milliseconds, making interactions feel fluid and human-like. This model is designed to process and generate speech with emotion, tone, and contextual awareness, making it suitable for applications such as AI assistants, voice interactions, real-time translations, and accessibility tools.
OpenAI GPT-4o Audio is an advanced real-time AI-powered voice assistant that enables instant, natural, and expressive conversations with AI. Unlike previous AI voice models, GPT-4o Audio can listen, understand, and respond within milliseconds, making interactions feel fluid and human-like. This model is designed to process and generate speech with emotion, tone, and contextual awareness, making it suitable for applications such as AI assistants, voice interactions, real-time translations, and accessibility tools.

GPT-4o-mini-tts is OpenAI's lightweight, high-speed text-to-speech (TTS) model designed for fast, real-time voice synthesis using the GPT-4o-mini architecture. It's built to deliver natural, expressive, and low-latency speech output—ideal for developers building interactive applications that require instant voice responses, such as AI assistants, voice agents, or educational tools. Unlike larger TTS models, GPT-4o-mini-tts balances performance and efficiency, enabling responsive, engaging voice output even in environments with limited compute resources.
GPT-4o-mini-tts is OpenAI's lightweight, high-speed text-to-speech (TTS) model designed for fast, real-time voice synthesis using the GPT-4o-mini architecture. It's built to deliver natural, expressive, and low-latency speech output—ideal for developers building interactive applications that require instant voice responses, such as AI assistants, voice agents, or educational tools. Unlike larger TTS models, GPT-4o-mini-tts balances performance and efficiency, enabling responsive, engaging voice output even in environments with limited compute resources.
GPT-4o-mini-tts is OpenAI's lightweight, high-speed text-to-speech (TTS) model designed for fast, real-time voice synthesis using the GPT-4o-mini architecture. It's built to deliver natural, expressive, and low-latency speech output—ideal for developers building interactive applications that require instant voice responses, such as AI assistants, voice agents, or educational tools. Unlike larger TTS models, GPT-4o-mini-tts balances performance and efficiency, enabling responsive, engaging voice output even in environments with limited compute resources.
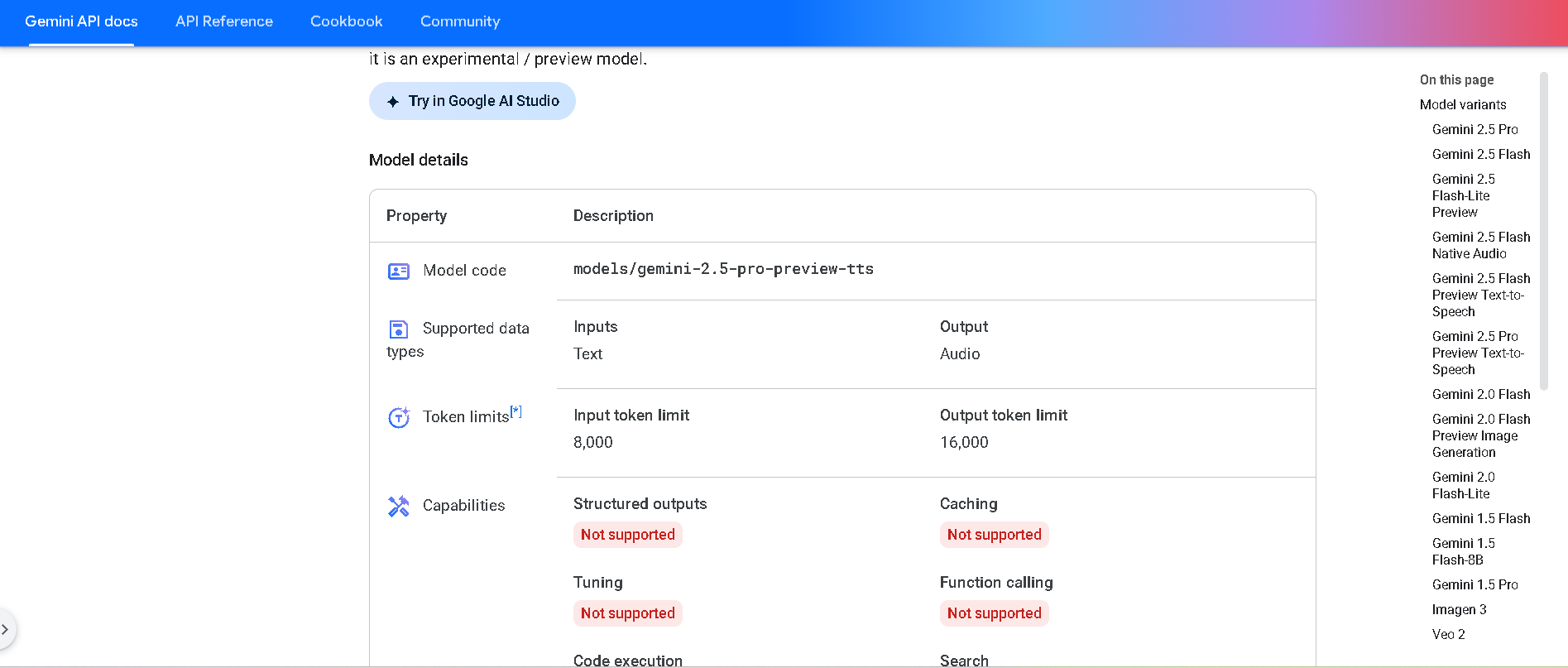
Gemini 2.5 Pro Preview TTS is Google DeepMind’s most powerful text-to-speech model in the Gemini 2.5 series, available in preview. It generates natural-sounding audio—from single-speaker readings to multi-speaker dialogue—while offering fine-grained control over voice style, emotion, pacing, and cadence. Designed for high-fidelity podcasts, audiobooks, and professional voice workflows.
Gemini 2.5 Pro Preview TTS is Google DeepMind’s most powerful text-to-speech model in the Gemini 2.5 series, available in preview. It generates natural-sounding audio—from single-speaker readings to multi-speaker dialogue—while offering fine-grained control over voice style, emotion, pacing, and cadence. Designed for high-fidelity podcasts, audiobooks, and professional voice workflows.
Gemini 2.5 Pro Preview TTS is Google DeepMind’s most powerful text-to-speech model in the Gemini 2.5 series, available in preview. It generates natural-sounding audio—from single-speaker readings to multi-speaker dialogue—while offering fine-grained control over voice style, emotion, pacing, and cadence. Designed for high-fidelity podcasts, audiobooks, and professional voice workflows.
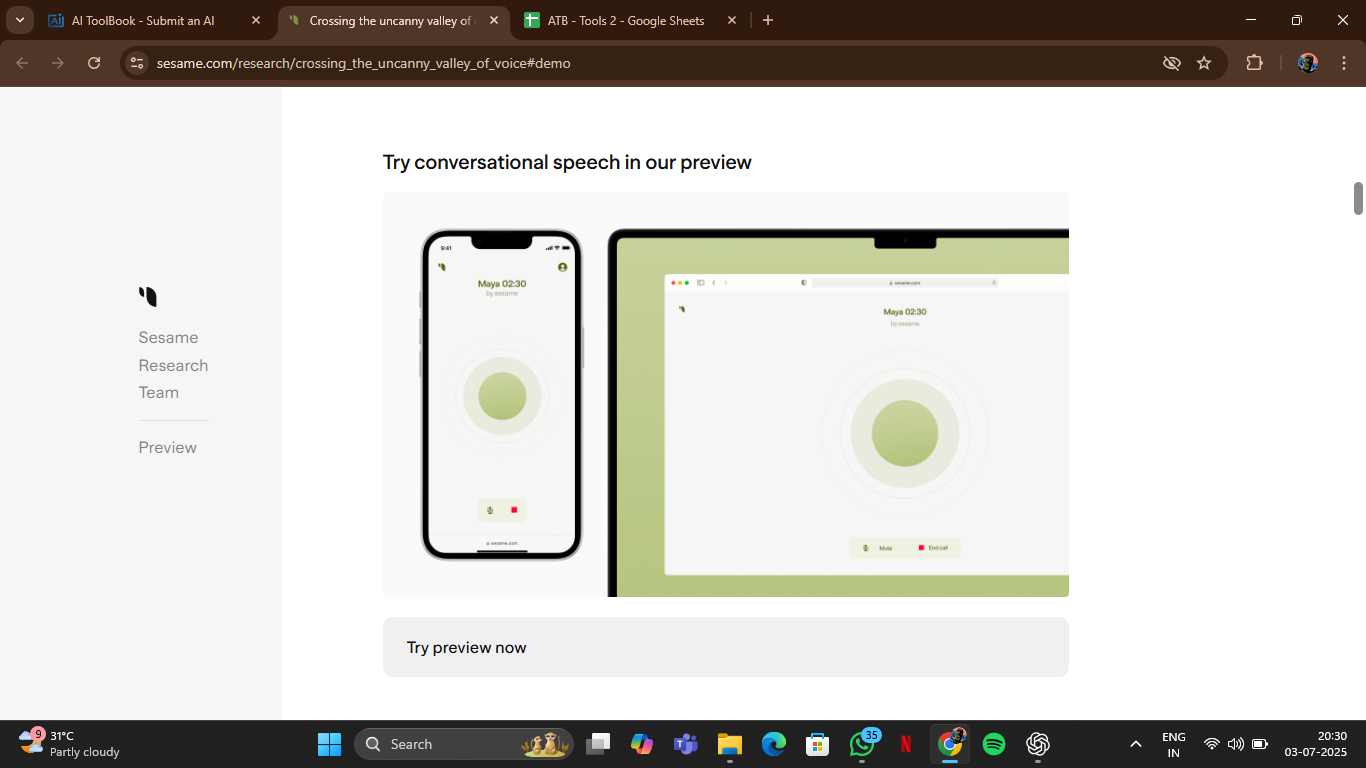
Sesame AI
Sesame Voice AI is a cutting-edge voice synthesis platform that specializes in generating highly realistic and emotionally expressive synthetic voices. Developed by Sesame Labs, this tool bridges the gap between robotic-sounding voice models and human-like speech by incorporating nuanced emotion, context-awareness, and personality into generated audio. Whether it's for games, virtual assistants, films, or branded audio experiences, Sesame aims to "cross the uncanny valley" of voice, producing voices that sound indistinguishably human. It leverages deep learning, large-scale neural networks, and novel techniques in voice conditioning to bring personality-rich, expressive voice capabilities to creators and developers—without needing a real voice actor every time.
Sesame AI
Sesame Voice AI is a cutting-edge voice synthesis platform that specializes in generating highly realistic and emotionally expressive synthetic voices. Developed by Sesame Labs, this tool bridges the gap between robotic-sounding voice models and human-like speech by incorporating nuanced emotion, context-awareness, and personality into generated audio. Whether it's for games, virtual assistants, films, or branded audio experiences, Sesame aims to "cross the uncanny valley" of voice, producing voices that sound indistinguishably human. It leverages deep learning, large-scale neural networks, and novel techniques in voice conditioning to bring personality-rich, expressive voice capabilities to creators and developers—without needing a real voice actor every time.
Sesame AI
Sesame Voice AI is a cutting-edge voice synthesis platform that specializes in generating highly realistic and emotionally expressive synthetic voices. Developed by Sesame Labs, this tool bridges the gap between robotic-sounding voice models and human-like speech by incorporating nuanced emotion, context-awareness, and personality into generated audio. Whether it's for games, virtual assistants, films, or branded audio experiences, Sesame aims to "cross the uncanny valley" of voice, producing voices that sound indistinguishably human. It leverages deep learning, large-scale neural networks, and novel techniques in voice conditioning to bring personality-rich, expressive voice capabilities to creators and developers—without needing a real voice actor every time.
Reader by Audeus
Audeus.com is a text-to-speech (TTS) application designed to help users efficiently consume various types of written content, such as PDFs, Word documents, and web articles. Its primary purpose is to convert written text into spoken audio, allowing users to listen while reading along. This aims to save time, boost productivity, and potentially enhance comprehension and retention by engaging both visual and auditory senses.
Reader by Audeus
Audeus.com is a text-to-speech (TTS) application designed to help users efficiently consume various types of written content, such as PDFs, Word documents, and web articles. Its primary purpose is to convert written text into spoken audio, allowing users to listen while reading along. This aims to save time, boost productivity, and potentially enhance comprehension and retention by engaging both visual and auditory senses.
Reader by Audeus
Audeus.com is a text-to-speech (TTS) application designed to help users efficiently consume various types of written content, such as PDFs, Word documents, and web articles. Its primary purpose is to convert written text into spoken audio, allowing users to listen while reading along. This aims to save time, boost productivity, and potentially enhance comprehension and retention by engaging both visual and auditory senses.

VoiceClone-AI
VoiceClone AI is a cutting-edge voice synthesis platform powered by advanced AI that recreates a speaker’s voice from just 30–60 seconds of sample audio. By capturing tone, accent, inflection, and emotion, it enables users to generate realistic voice content without the need for re-recording. VoiceClone supports multi-language output and provides fine-grained control over emotional cues, pacing, and expressiveness—delivering high-quality MP3/WAV files and seamless API integration.
VoiceClone-AI
VoiceClone AI is a cutting-edge voice synthesis platform powered by advanced AI that recreates a speaker’s voice from just 30–60 seconds of sample audio. By capturing tone, accent, inflection, and emotion, it enables users to generate realistic voice content without the need for re-recording. VoiceClone supports multi-language output and provides fine-grained control over emotional cues, pacing, and expressiveness—delivering high-quality MP3/WAV files and seamless API integration.
VoiceClone-AI
VoiceClone AI is a cutting-edge voice synthesis platform powered by advanced AI that recreates a speaker’s voice from just 30–60 seconds of sample audio. By capturing tone, accent, inflection, and emotion, it enables users to generate realistic voice content without the need for re-recording. VoiceClone supports multi-language output and provides fine-grained control over emotional cues, pacing, and expressiveness—delivering high-quality MP3/WAV files and seamless API integration.

VoiceAIWrapper
VoiceAIWrapper is a versatile AI-powered platform designed to streamline the process of creating and managing voice-based applications. It offers a user-friendly interface for building various voice applications, from simple voice assistants to complex conversational AI systems, without requiring extensive coding expertise. VoiceAIWrapper simplifies integration with popular AI models and provides tools for managing voice data and enhancing the overall user experience.
VoiceAIWrapper
VoiceAIWrapper is a versatile AI-powered platform designed to streamline the process of creating and managing voice-based applications. It offers a user-friendly interface for building various voice applications, from simple voice assistants to complex conversational AI systems, without requiring extensive coding expertise. VoiceAIWrapper simplifies integration with popular AI models and provides tools for managing voice data and enhancing the overall user experience.
VoiceAIWrapper
VoiceAIWrapper is a versatile AI-powered platform designed to streamline the process of creating and managing voice-based applications. It offers a user-friendly interface for building various voice applications, from simple voice assistants to complex conversational AI systems, without requiring extensive coding expertise. VoiceAIWrapper simplifies integration with popular AI models and provides tools for managing voice data and enhancing the overall user experience.

Murf.ai
Murf.ai is an AI voice generator and text-to-speech platform that delivers ultra-realistic voiceovers for creators, teams, and developers. It offers 200+ multilingual voices, 10+ speaking styles, and fine-grained controls over pitch, speed, tone, prosody, and pronunciation. A low-latency TTS model powers conversational agents with sub-200 ms response, while APIs enable voice cloning, voice changing, streaming TTS, and translation/dubbing in 30+ languages. A studio workspace supports scripting, timing, and rapid iteration for ads, training, audiobooks, podcasts, and product audio. Pronunciation libraries, team workspaces, and tool integrations help standardize brand voice at scale without complex audio engineering.
Murf.ai
Murf.ai is an AI voice generator and text-to-speech platform that delivers ultra-realistic voiceovers for creators, teams, and developers. It offers 200+ multilingual voices, 10+ speaking styles, and fine-grained controls over pitch, speed, tone, prosody, and pronunciation. A low-latency TTS model powers conversational agents with sub-200 ms response, while APIs enable voice cloning, voice changing, streaming TTS, and translation/dubbing in 30+ languages. A studio workspace supports scripting, timing, and rapid iteration for ads, training, audiobooks, podcasts, and product audio. Pronunciation libraries, team workspaces, and tool integrations help standardize brand voice at scale without complex audio engineering.
Murf.ai
Murf.ai is an AI voice generator and text-to-speech platform that delivers ultra-realistic voiceovers for creators, teams, and developers. It offers 200+ multilingual voices, 10+ speaking styles, and fine-grained controls over pitch, speed, tone, prosody, and pronunciation. A low-latency TTS model powers conversational agents with sub-200 ms response, while APIs enable voice cloning, voice changing, streaming TTS, and translation/dubbing in 30+ languages. A studio workspace supports scripting, timing, and rapid iteration for ads, training, audiobooks, podcasts, and product audio. Pronunciation libraries, team workspaces, and tool integrations help standardize brand voice at scale without complex audio engineering.
AI Awaaz
Ai Awaaz is a text-to-speech (TTS) and voice-generation platform developed in India and marketed as India’s first emotion-based TTS AI engine. It enables users to convert text into natural-sounding voiceovers in 20+ Indian languages and 140+ voices, with selectable emotions (e.g., cheerful, sad, whispering) and export formats suitable for videos, podcasts, audiobooks and e-learning modules. The platform emphasises speed and scalability, claiming that a voiceover can be created in just minutes, compared to traditional voice-actor turnaround times. It is positioned for marketers, educators, content creators and agencies needing multi-language voice production with minimal friction.
AI Awaaz
Ai Awaaz is a text-to-speech (TTS) and voice-generation platform developed in India and marketed as India’s first emotion-based TTS AI engine. It enables users to convert text into natural-sounding voiceovers in 20+ Indian languages and 140+ voices, with selectable emotions (e.g., cheerful, sad, whispering) and export formats suitable for videos, podcasts, audiobooks and e-learning modules. The platform emphasises speed and scalability, claiming that a voiceover can be created in just minutes, compared to traditional voice-actor turnaround times. It is positioned for marketers, educators, content creators and agencies needing multi-language voice production with minimal friction.
AI Awaaz
Ai Awaaz is a text-to-speech (TTS) and voice-generation platform developed in India and marketed as India’s first emotion-based TTS AI engine. It enables users to convert text into natural-sounding voiceovers in 20+ Indian languages and 140+ voices, with selectable emotions (e.g., cheerful, sad, whispering) and export formats suitable for videos, podcasts, audiobooks and e-learning modules. The platform emphasises speed and scalability, claiming that a voiceover can be created in just minutes, compared to traditional voice-actor turnaround times. It is positioned for marketers, educators, content creators and agencies needing multi-language voice production with minimal friction.

Parrot Talk
Parrottalk.ai is a cutting-edge voice cloning platform that lets users replicate any voice using just a single short audio recording. Upload a 10-second sample, and the AI generates realistic speech clones for podcasts, videos, audiobooks, or creative projects. It delivers high-fidelity results with natural intonation, accents, and timbre, making it ideal for content creators needing custom voices without expensive studios. The tool emphasizes ease-of-use with a simple web interface, quick processing times, and options for fine-tuning clones. Privacy-focused and accessible to beginners or pros, Parrottalk.ai transforms voiceovers, enabling personalized audio content at scale.
Parrot Talk
Parrottalk.ai is a cutting-edge voice cloning platform that lets users replicate any voice using just a single short audio recording. Upload a 10-second sample, and the AI generates realistic speech clones for podcasts, videos, audiobooks, or creative projects. It delivers high-fidelity results with natural intonation, accents, and timbre, making it ideal for content creators needing custom voices without expensive studios. The tool emphasizes ease-of-use with a simple web interface, quick processing times, and options for fine-tuning clones. Privacy-focused and accessible to beginners or pros, Parrottalk.ai transforms voiceovers, enabling personalized audio content at scale.
Parrot Talk
Parrottalk.ai is a cutting-edge voice cloning platform that lets users replicate any voice using just a single short audio recording. Upload a 10-second sample, and the AI generates realistic speech clones for podcasts, videos, audiobooks, or creative projects. It delivers high-fidelity results with natural intonation, accents, and timbre, making it ideal for content creators needing custom voices without expensive studios. The tool emphasizes ease-of-use with a simple web interface, quick processing times, and options for fine-tuning clones. Privacy-focused and accessible to beginners or pros, Parrottalk.ai transforms voiceovers, enabling personalized audio content at scale.

Noiz
Noiz is a leading AI platform for advanced speech synthesis and audio generation, specializing in highly expressive, lifelike voices with emotional control and customization. It offers text-to-speech , voice cloning, multilingual dubbing, AI singing voice generation, and developer APIs for seamless integration into apps. Users can create realistic vocals with nuance, vibrato, and dynamics from simple prompts, supporting video translation, audio editing, and music production. The tool excels in cost-efficiency, handling everything from podcast mastering to viral song covers, with features like noise removal, auto-leveling, and scene-based soundscapes. Ideal for creators seeking professional audio without studios.
Noiz
Noiz is a leading AI platform for advanced speech synthesis and audio generation, specializing in highly expressive, lifelike voices with emotional control and customization. It offers text-to-speech , voice cloning, multilingual dubbing, AI singing voice generation, and developer APIs for seamless integration into apps. Users can create realistic vocals with nuance, vibrato, and dynamics from simple prompts, supporting video translation, audio editing, and music production. The tool excels in cost-efficiency, handling everything from podcast mastering to viral song covers, with features like noise removal, auto-leveling, and scene-based soundscapes. Ideal for creators seeking professional audio without studios.
Noiz
Noiz is a leading AI platform for advanced speech synthesis and audio generation, specializing in highly expressive, lifelike voices with emotional control and customization. It offers text-to-speech , voice cloning, multilingual dubbing, AI singing voice generation, and developer APIs for seamless integration into apps. Users can create realistic vocals with nuance, vibrato, and dynamics from simple prompts, supporting video translation, audio editing, and music production. The tool excels in cost-efficiency, handling everything from podcast mastering to viral song covers, with features like noise removal, auto-leveling, and scene-based soundscapes. Ideal for creators seeking professional audio without studios.

AnyVoice
AnyVoice brings the world's fastest AI voice cloning, turning just 3 seconds of audio into hyper-realistic speech that nails every nuance and emotion. Pick from English, Chinese Mandarin, Japanese, or Korean, enter your text, select the cloned voice, and get instant lifelike output—no long recordings or tech skills needed. Perfect for quick voiceovers, prototyping, or dynamic content, it delivers indistinguishable-from-human results securely with user privacy front and center. Free tier offers 900 seconds monthly and 5 clones; Pro unlocks unlimited everything and commercial rights. Streamlined interface makes pro-level cloning accessible to anyone, speeding up creation like never before.
AnyVoice
AnyVoice brings the world's fastest AI voice cloning, turning just 3 seconds of audio into hyper-realistic speech that nails every nuance and emotion. Pick from English, Chinese Mandarin, Japanese, or Korean, enter your text, select the cloned voice, and get instant lifelike output—no long recordings or tech skills needed. Perfect for quick voiceovers, prototyping, or dynamic content, it delivers indistinguishable-from-human results securely with user privacy front and center. Free tier offers 900 seconds monthly and 5 clones; Pro unlocks unlimited everything and commercial rights. Streamlined interface makes pro-level cloning accessible to anyone, speeding up creation like never before.
AnyVoice
AnyVoice brings the world's fastest AI voice cloning, turning just 3 seconds of audio into hyper-realistic speech that nails every nuance and emotion. Pick from English, Chinese Mandarin, Japanese, or Korean, enter your text, select the cloned voice, and get instant lifelike output—no long recordings or tech skills needed. Perfect for quick voiceovers, prototyping, or dynamic content, it delivers indistinguishable-from-human results securely with user privacy front and center. Free tier offers 900 seconds monthly and 5 clones; Pro unlocks unlimited everything and commercial rights. Streamlined interface makes pro-level cloning accessible to anyone, speeding up creation like never before.
Editorial Note
This page was researched and written by the ATB Editorial Team. Our team researches each AI tool by reviewing its official website, testing features, exploring real use cases, and considering user feedback. Every page is fact-checked and regularly updated to ensure the information stays accurate, neutral, and useful for our readers.
If you have any suggestions or questions, email us at hello@aitoolbook.ai