
- Software Developers & Engineers: Benefit from advanced reasoning, front-end code generation, and a new agentic coding tool.
- Data Analysts & Scientists: Handle complex math, physics, chart interpretation, and data extraction tasks.
- Automation & Productivity Teams: Use “extended thinking” for multi-step planning and task execution; ideal for agentic workflows.
- Enterprises & API Users: Integrate via Anthropic API, Amazon Bedrock, Google Vertex AI, Databricks, or other platforms.
- Students & Academics: Tap into strong math, science, and multi-step problem-solving capabilities.
- Content Creators & Planners: Generate in-depth strategy, planning, and creative content with reliable traceability.
How to Use Claude 3.7 Sonnet?
- Access & Enable: Available via Claude.ai (Free, Pro, Team, Enterprise), Anthropic API, AWS Bedrock, Google Vertex AI, Snowflake Cortex AI, and Databricks.
- Choose Thinking Mode: Use standard mode for instant answers or extended thinking mode for step-by-step reasoning.
- Set Reasoning Budget in API: Control how much it “thinks” (up to 128K tokens), balancing cost and depth.
- Use Claude Code: Run agentic coding directly from the terminal via command-line interface (research preview).
- Generate & Refine: Interact through the Claude UI with visualized chain-of-thought (“Artifacts” window), prompt for code, math, or complex reasoning.
- Hybrid Reasoning in One Model: Combines instant responses with extended chain-of-thought in a single model—no need to swap models.
- Visible Chain-of-Thought: Users can observe the model’s reasoning steps when extended thinking mode is enabled.
- Top-Tier Coding & Agentic Tools: Leads benchmarks on SWE-bench, TAU-bench; includes Claude Code for CLI workflows.
- Extended Context Windows: Supports outputs up to 128K tokens—ideal for large reasoning or code generation tasks.
- Broad Platform Availability: Accessible across Claude web/app, API, Bedrock, Vertex AI, Cortex AI, Databricks.
- Cost-Effective Performance: Fast runtime with cost-efficiency—same pricing as Claude 3.5 while doubling output capabilities.
- Hybrid agility: seamless switch between quick answers and deep reasoning.
- Transparent thought: extended mode shows working logic.
- Frontier-tier coding: excels in real-world programming benchmarks.
- Flexible deployment: accessible across API and major cloud platforms.
- Token-controlled depth: trade off speed, cost, and detail via thinking budget.
- Extended thinking still experimental: confined to paid tiers and may overthink.
- Potential latency: deeper reasoning increases response time.
- Cost/benefit judgement: users must manage thinking token budgets to control cost.
Free
$ 0.00
- Chat on web, iOS, and Android
- Generate code and visualize data
- Write, edit, and create content
- Analyze text and images
- Ability to search the web
Pro
$20/month
Connect Google Workspace: email, calendar, and docs
Connect any context or tool through Integrations with remote MCP
Extended thinking for complex work
Ability to use more Claude models
Max
$100/month
- Choose 5x or 20x more usage than Pro
- Higher output limits for all tasks
- Early access to advanced Claude features
- Priority access at high traffic times
API Usage
$3/$15 per 1M tokens
- $3 per million input tokens & $15 per million output tokens
- Prompt caching write - $3.75 / MTok
- Prompt caching read - $0.30 / MTok
Proud of the love you're getting? Show off your AI Toolbook reviews—then invite more fans to share the love and build your credibility.
Add an AI Toolbook badge to your site—an easy way to drive followers, showcase updates, and collect reviews. It's like a mini 24/7 billboard for your AI.
Reviews
Rating Distribution
Average score
Popular Mention
FAQs
Similar AI Tools
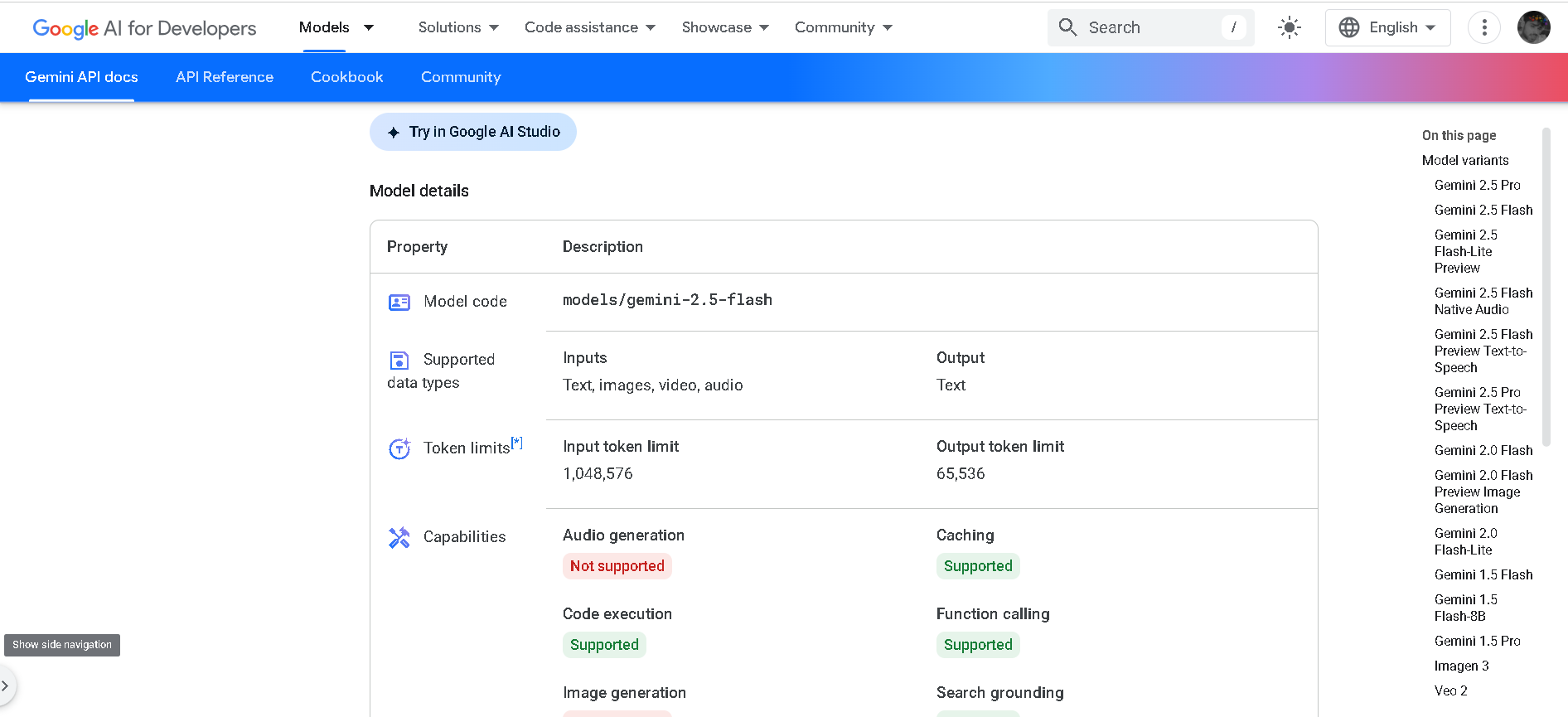

Gemini 2.5 Flash
Gemini 2.5 Flash is Google DeepMind’s cost-efficient, low-latency hybrid-reasoning model. Designed for large-scale, real-time tasks that require thinking—like classification, translation, conversational AI, and agent behaviors—it supports text, image, audio, and video input, and offers developer control over its reasoning depth. It balances high speed with strong multimodal intelligence.
Gemini 2.5 Flash
Gemini 2.5 Flash is Google DeepMind’s cost-efficient, low-latency hybrid-reasoning model. Designed for large-scale, real-time tasks that require thinking—like classification, translation, conversational AI, and agent behaviors—it supports text, image, audio, and video input, and offers developer control over its reasoning depth. It balances high speed with strong multimodal intelligence.
Gemini 2.5 Flash
Gemini 2.5 Flash is Google DeepMind’s cost-efficient, low-latency hybrid-reasoning model. Designed for large-scale, real-time tasks that require thinking—like classification, translation, conversational AI, and agent behaviors—it supports text, image, audio, and video input, and offers developer control over its reasoning depth. It balances high speed with strong multimodal intelligence.

DeepSeek-V3
DeepSeek V3 is the latest flagship Mixture‑of‑Experts (MoE) open‑source AI model from DeepSeek. It features 671 billion total parameters (with ~37 billion activated per token), supports up to 128K context length, and excels across reasoning, code generation, language, and multimodal tasks. On standard benchmarks, it rivals or exceeds proprietary models—including GPT‑4o and Claude 3.5—as a high-performance, cost-efficient alternative.
DeepSeek-V3
DeepSeek V3 is the latest flagship Mixture‑of‑Experts (MoE) open‑source AI model from DeepSeek. It features 671 billion total parameters (with ~37 billion activated per token), supports up to 128K context length, and excels across reasoning, code generation, language, and multimodal tasks. On standard benchmarks, it rivals or exceeds proprietary models—including GPT‑4o and Claude 3.5—as a high-performance, cost-efficient alternative.
DeepSeek-V3
DeepSeek V3 is the latest flagship Mixture‑of‑Experts (MoE) open‑source AI model from DeepSeek. It features 671 billion total parameters (with ~37 billion activated per token), supports up to 128K context length, and excels across reasoning, code generation, language, and multimodal tasks. On standard benchmarks, it rivals or exceeds proprietary models—including GPT‑4o and Claude 3.5—as a high-performance, cost-efficient alternative.


Grok 3 Latest
Grok 3 is xAI’s newest flagship AI chatbot, released on February 17, 2025, running on the massive Colossus supercluster (~200,000 GPUs). It offers elite-level reasoning, chain-of-thought transparency (“Think” mode), advanced “Big Brain” deeper reasoning, multimodal support (text, images), and integrated real-time DeepSearch—positioning it as a top-tier competitor to GPT‑4o, Gemini, Claude, and DeepSeek V3 on benchmarks.
Grok 3 Latest
Grok 3 is xAI’s newest flagship AI chatbot, released on February 17, 2025, running on the massive Colossus supercluster (~200,000 GPUs). It offers elite-level reasoning, chain-of-thought transparency (“Think” mode), advanced “Big Brain” deeper reasoning, multimodal support (text, images), and integrated real-time DeepSearch—positioning it as a top-tier competitor to GPT‑4o, Gemini, Claude, and DeepSeek V3 on benchmarks.
Grok 3 Latest
Grok 3 is xAI’s newest flagship AI chatbot, released on February 17, 2025, running on the massive Colossus supercluster (~200,000 GPUs). It offers elite-level reasoning, chain-of-thought transparency (“Think” mode), advanced “Big Brain” deeper reasoning, multimodal support (text, images), and integrated real-time DeepSearch—positioning it as a top-tier competitor to GPT‑4o, Gemini, Claude, and DeepSeek V3 on benchmarks.

grok-3-fast-latest
Grok 3 Fast is xAI’s speed-optimized variant of their flagship Grok 3 model, offering identical output quality with lower latency. It leverages the same underlying architecture—including multimodal input, chain-of-thought reasoning, and large context—but serves through optimized infrastructure for real-time responsiveness. It supports up to 131,072 tokens of context.
grok-3-fast-latest
Grok 3 Fast is xAI’s speed-optimized variant of their flagship Grok 3 model, offering identical output quality with lower latency. It leverages the same underlying architecture—including multimodal input, chain-of-thought reasoning, and large context—but serves through optimized infrastructure for real-time responsiveness. It supports up to 131,072 tokens of context.
grok-3-fast-latest
Grok 3 Fast is xAI’s speed-optimized variant of their flagship Grok 3 model, offering identical output quality with lower latency. It leverages the same underlying architecture—including multimodal input, chain-of-thought reasoning, and large context—but serves through optimized infrastructure for real-time responsiveness. It supports up to 131,072 tokens of context.

grok-2-latest
Grok 2 is xAI’s second-generation chatbot model, launched in August 2024 as a substantial upgrade over Grok 1.5. It delivers frontier-level performance in chat, coding, reasoning, vision tasks, and image generation via the FLUX.1 system. On leaderboards, it outscored Claude 3.5 Sonnet and GPT‑4 Turbo, with strong results in GPQA (56%), MMLU (87.5%), MATH (76.1%), HumanEval (88.4%), MathVista, and DocVQA benchmarks.
grok-2-latest
Grok 2 is xAI’s second-generation chatbot model, launched in August 2024 as a substantial upgrade over Grok 1.5. It delivers frontier-level performance in chat, coding, reasoning, vision tasks, and image generation via the FLUX.1 system. On leaderboards, it outscored Claude 3.5 Sonnet and GPT‑4 Turbo, with strong results in GPQA (56%), MMLU (87.5%), MATH (76.1%), HumanEval (88.4%), MathVista, and DocVQA benchmarks.
grok-2-latest
Grok 2 is xAI’s second-generation chatbot model, launched in August 2024 as a substantial upgrade over Grok 1.5. It delivers frontier-level performance in chat, coding, reasoning, vision tasks, and image generation via the FLUX.1 system. On leaderboards, it outscored Claude 3.5 Sonnet and GPT‑4 Turbo, with strong results in GPQA (56%), MMLU (87.5%), MATH (76.1%), HumanEval (88.4%), MathVista, and DocVQA benchmarks.

Meta Llama 3.3
Llama 3.3 is Meta’s instruction-tuned, text-only large language model released on December 6, 2024, available in a 70B-parameter size. It matches the performance of much larger models using significantly fewer parameters, is multilingual across eight key languages, and supports a massive 128,000-token context window—ideal for handling long-form documents, codebases, and detailed reasoning tasks.
Meta Llama 3.3
Llama 3.3 is Meta’s instruction-tuned, text-only large language model released on December 6, 2024, available in a 70B-parameter size. It matches the performance of much larger models using significantly fewer parameters, is multilingual across eight key languages, and supports a massive 128,000-token context window—ideal for handling long-form documents, codebases, and detailed reasoning tasks.
Meta Llama 3.3
Llama 3.3 is Meta’s instruction-tuned, text-only large language model released on December 6, 2024, available in a 70B-parameter size. It matches the performance of much larger models using significantly fewer parameters, is multilingual across eight key languages, and supports a massive 128,000-token context window—ideal for handling long-form documents, codebases, and detailed reasoning tasks.

DeepSeek R1 0528 – Qwen3 ‑ 8B is an 8 B-parameter dense model distilled from DeepSeek‑R1‑0528 using Qwen3‑8B as its base. Released in May 2025, it transfers high-depth chain-of-thought reasoning into a compact architecture while achieving benchmark-leading results close to much larger models.
DeepSeek R1 0528 – Qwen3 ‑ 8B is an 8 B-parameter dense model distilled from DeepSeek‑R1‑0528 using Qwen3‑8B as its base. Released in May 2025, it transfers high-depth chain-of-thought reasoning into a compact architecture while achieving benchmark-leading results close to much larger models.
DeepSeek R1 0528 – Qwen3 ‑ 8B is an 8 B-parameter dense model distilled from DeepSeek‑R1‑0528 using Qwen3‑8B as its base. Released in May 2025, it transfers high-depth chain-of-thought reasoning into a compact architecture while achieving benchmark-leading results close to much larger models.

Perplexity AI
Perplexity AI is a powerful AI‑powered answer engine and search assistant launched in December 2022. It combines real‑time web search with large language models (like GPT‑4.1, Claude 4, Sonar), delivering direct answers with in‑text citations and multi‑turn conversational context.
Perplexity AI
Perplexity AI is a powerful AI‑powered answer engine and search assistant launched in December 2022. It combines real‑time web search with large language models (like GPT‑4.1, Claude 4, Sonar), delivering direct answers with in‑text citations and multi‑turn conversational context.
Perplexity AI
Perplexity AI is a powerful AI‑powered answer engine and search assistant launched in December 2022. It combines real‑time web search with large language models (like GPT‑4.1, Claude 4, Sonar), delivering direct answers with in‑text citations and multi‑turn conversational context.

Mistral Large 2
Mistral Large 2 is the second-generation flagship model from Mistral AI, released in July 2024. Also referenced as mistral-large-2407, it’s a 123 B-parameter dense LLM with a 128 K-token context window, supporting dozens of languages and 80+ coding languages. It excels in reasoning, code generation, mathematics, instruction-following, and function calling—designed for high throughput on single-node setups.
Mistral Large 2
Mistral Large 2 is the second-generation flagship model from Mistral AI, released in July 2024. Also referenced as mistral-large-2407, it’s a 123 B-parameter dense LLM with a 128 K-token context window, supporting dozens of languages and 80+ coding languages. It excels in reasoning, code generation, mathematics, instruction-following, and function calling—designed for high throughput on single-node setups.
Mistral Large 2
Mistral Large 2 is the second-generation flagship model from Mistral AI, released in July 2024. Also referenced as mistral-large-2407, it’s a 123 B-parameter dense LLM with a 128 K-token context window, supporting dozens of languages and 80+ coding languages. It excels in reasoning, code generation, mathematics, instruction-following, and function calling—designed for high throughput on single-node setups.
Mistral Medium 3
Mistral Medium 3 is Mistral AI’s new frontier-class multimodal dense model, released May 7, 2025, designed for enterprise use. It delivers state-of-the-art performance—matching or exceeding 90 % of models like Claude Sonnet 3.7—while costing 8× less and offering simplified deployment for coding, STEM reasoning, vision understanding, and long-context workflows up to 128 K tokens.
Mistral Medium 3
Mistral Medium 3 is Mistral AI’s new frontier-class multimodal dense model, released May 7, 2025, designed for enterprise use. It delivers state-of-the-art performance—matching or exceeding 90 % of models like Claude Sonnet 3.7—while costing 8× less and offering simplified deployment for coding, STEM reasoning, vision understanding, and long-context workflows up to 128 K tokens.
Mistral Medium 3
Mistral Medium 3 is Mistral AI’s new frontier-class multimodal dense model, released May 7, 2025, designed for enterprise use. It delivers state-of-the-art performance—matching or exceeding 90 % of models like Claude Sonnet 3.7—while costing 8× less and offering simplified deployment for coding, STEM reasoning, vision understanding, and long-context workflows up to 128 K tokens.

Mistral Small 3.1
Mistral Small 3.1 is the March 17, 2025 update to Mistral AI's open-source 24B-parameter small model. It offers instruction-following, multimodal vision understanding, and an expanded 128K-token context window, delivering performance on par with or better than GPT‑4o Mini, Gemma 3, and Claude 3.5 Haiku—all while maintaining fast inference speeds (~150 tokens/sec) and running on devices like an RTX 4090 or a 32 GB Mac.
Mistral Small 3.1
Mistral Small 3.1 is the March 17, 2025 update to Mistral AI's open-source 24B-parameter small model. It offers instruction-following, multimodal vision understanding, and an expanded 128K-token context window, delivering performance on par with or better than GPT‑4o Mini, Gemma 3, and Claude 3.5 Haiku—all while maintaining fast inference speeds (~150 tokens/sec) and running on devices like an RTX 4090 or a 32 GB Mac.
Mistral Small 3.1
Mistral Small 3.1 is the March 17, 2025 update to Mistral AI's open-source 24B-parameter small model. It offers instruction-following, multimodal vision understanding, and an expanded 128K-token context window, delivering performance on par with or better than GPT‑4o Mini, Gemma 3, and Claude 3.5 Haiku—all while maintaining fast inference speeds (~150 tokens/sec) and running on devices like an RTX 4090 or a 32 GB Mac.

DeepClaude
DeepClaude is a high-performance, open-source platform that combines DeepSeek R1’s chain-of-thought reasoning with Claude 3.5 Sonnet’s creative and code-generation capabilities. It offers zero-latency streaming responses via a Rust-based API and supports self-hosted or managed deployment.
DeepClaude
DeepClaude is a high-performance, open-source platform that combines DeepSeek R1’s chain-of-thought reasoning with Claude 3.5 Sonnet’s creative and code-generation capabilities. It offers zero-latency streaming responses via a Rust-based API and supports self-hosted or managed deployment.
DeepClaude
DeepClaude is a high-performance, open-source platform that combines DeepSeek R1’s chain-of-thought reasoning with Claude 3.5 Sonnet’s creative and code-generation capabilities. It offers zero-latency streaming responses via a Rust-based API and supports self-hosted or managed deployment.
Editorial Note
This page was researched and written by the ATB Editorial Team. Our team researches each AI tool by reviewing its official website, testing features, exploring real use cases, and considering user feedback. Every page is fact-checked and regularly updated to ensure the information stays accurate, neutral, and useful for our readers.
If you have any suggestions or questions, email us at hello@aitoolbook.ai