
- Developers & Engineers: Gain robust reasoning for analysis and polished code output in one tool.
- Teams & Enterprises: Use dual-model workflows securely, on-premises or managed, with end-to-end encryption.
- Open-Source Enthusiasts: Customize the fully open-source Rust codebase (MIT license) for coding assistants, chatbots, or RAG systems.
- Researchers & Analysts: Compare reasoning vs creativity through side-by-side model outputs.
- Educators & Students: Learn how multimodal reasoning pipelines work in practice.
How to Use DeepClaude?
- Load the Platform: Clone the GitHub repo or use self-hosted options; manage keys for DeepSeek and Anthropic Claude.
- Install Dependencies: Requires Rust 1.75+, plus your own DeepSeek API key and Claude key.
- Run Locally or Deploy: `cargo build --release` → configure `config.toml` → launch Rust streaming API.
- Use Chat API: Send requests to `https://api.deepclaude.com/v1` with headers `X-DeepSeek-API-Token` and `X-Anthropic-API-Token`.
- Deploy to Vercel/Cloudflare or integrate via your framework of choice.
- Dual-Stage Reasoning Pipeline: R1 provides detailed CoT analysis, then Claude refines and generates final output—"combine both models to provide… R1's exceptional reasoning… Claude's superior code generation and creativity."
- Zero-Latency Streaming API: Built in Rust, it streams model outputs seamlessly without delay.
- BYOK & Security: End-to-end encryption and local API key management ensure privacy.
- Highly Configurable & Open-Source: Community forks (e.g., Erlich’s OpenAI-compatible variant) expand deployment and integration scenarios.
- Proven Performance: Benchmarks cite MMLU score of 90.8%, 81% bug detection in code reviews, and cost efficiency (~11.7x cheaper than alternatives).
- Seamless integration of reasoning and polish in one pipeline
- Rust-based runtime offers low latency and high performance
- Full BYOK support and open-source freedom
- Community-driven extensions and diverse deployment options
- Requires DeepSeek and Claude API keys—no standalone offline model
- Complexity of managing two API services may deter casual users
- Some reports indicate Claude may get “confused by the chain of reasoning” in longer contexts
Paid
custom
Proud of the love you're getting? Show off your AI Toolbook reviews—then invite more fans to share the love and build your credibility.
Add an AI Toolbook badge to your site—an easy way to drive followers, showcase updates, and collect reviews. It's like a mini 24/7 billboard for your AI.
Reviews
Rating Distribution
Average score
Popular Mention
FAQs
Similar AI Tools
OpenAI ChatGPT
ChatGPT is an advanced AI chatbot developed by OpenAI that can generate human-like text, answer questions, assist with creative writing, and engage in natural conversations. Powered by OpenAI’s GPT models, it is widely used for customer support, content creation, tutoring, and even casual chat. ChatGPT is available as a web app, API, and mobile app, making it accessible for personal and business use.
OpenAI ChatGPT
ChatGPT is an advanced AI chatbot developed by OpenAI that can generate human-like text, answer questions, assist with creative writing, and engage in natural conversations. Powered by OpenAI’s GPT models, it is widely used for customer support, content creation, tutoring, and even casual chat. ChatGPT is available as a web app, API, and mobile app, making it accessible for personal and business use.
OpenAI ChatGPT
ChatGPT is an advanced AI chatbot developed by OpenAI that can generate human-like text, answer questions, assist with creative writing, and engage in natural conversations. Powered by OpenAI’s GPT models, it is widely used for customer support, content creation, tutoring, and even casual chat. ChatGPT is available as a web app, API, and mobile app, making it accessible for personal and business use.

Oyeeah
Oyeeah is a versatile platform offering a comprehensive suite of AI tools designed to enhance productivity and drive innovation. It provides cutting-edge solutions for automation, data analysis, content creation, and more, all integrated into a single platform. Whether you're looking to automate tasks, analyze data, or create compelling content, Oyeeah offers the tools to streamline your workflow and achieve your goals efficiently.
Oyeeah
Oyeeah is a versatile platform offering a comprehensive suite of AI tools designed to enhance productivity and drive innovation. It provides cutting-edge solutions for automation, data analysis, content creation, and more, all integrated into a single platform. Whether you're looking to automate tasks, analyze data, or create compelling content, Oyeeah offers the tools to streamline your workflow and achieve your goals efficiently.
Oyeeah
Oyeeah is a versatile platform offering a comprehensive suite of AI tools designed to enhance productivity and drive innovation. It provides cutting-edge solutions for automation, data analysis, content creation, and more, all integrated into a single platform. Whether you're looking to automate tasks, analyze data, or create compelling content, Oyeeah offers the tools to streamline your workflow and achieve your goals efficiently.

DeepSeek-R1
DeepSeek‑R1 is the flagship reasoning-oriented AI model from Chinese startup DeepSeek. It’s an open-source, mixture-of-experts (MoE) model combining model weights clarity and chain-of-thought reasoning trained primarily through reinforcement learning. R1 delivers top-tier benchmark performance—on par with or surpassing OpenAI o1 in math, coding, and reasoning—while being significantly more cost-efficient.
DeepSeek-R1
DeepSeek‑R1 is the flagship reasoning-oriented AI model from Chinese startup DeepSeek. It’s an open-source, mixture-of-experts (MoE) model combining model weights clarity and chain-of-thought reasoning trained primarily through reinforcement learning. R1 delivers top-tier benchmark performance—on par with or surpassing OpenAI o1 in math, coding, and reasoning—while being significantly more cost-efficient.
DeepSeek-R1
DeepSeek‑R1 is the flagship reasoning-oriented AI model from Chinese startup DeepSeek. It’s an open-source, mixture-of-experts (MoE) model combining model weights clarity and chain-of-thought reasoning trained primarily through reinforcement learning. R1 delivers top-tier benchmark performance—on par with or surpassing OpenAI o1 in math, coding, and reasoning—while being significantly more cost-efficient.

DeepSeek-V3
DeepSeek V3 is the latest flagship Mixture‑of‑Experts (MoE) open‑source AI model from DeepSeek. It features 671 billion total parameters (with ~37 billion activated per token), supports up to 128K context length, and excels across reasoning, code generation, language, and multimodal tasks. On standard benchmarks, it rivals or exceeds proprietary models—including GPT‑4o and Claude 3.5—as a high-performance, cost-efficient alternative.
DeepSeek-V3
DeepSeek V3 is the latest flagship Mixture‑of‑Experts (MoE) open‑source AI model from DeepSeek. It features 671 billion total parameters (with ~37 billion activated per token), supports up to 128K context length, and excels across reasoning, code generation, language, and multimodal tasks. On standard benchmarks, it rivals or exceeds proprietary models—including GPT‑4o and Claude 3.5—as a high-performance, cost-efficient alternative.
DeepSeek-V3
DeepSeek V3 is the latest flagship Mixture‑of‑Experts (MoE) open‑source AI model from DeepSeek. It features 671 billion total parameters (with ~37 billion activated per token), supports up to 128K context length, and excels across reasoning, code generation, language, and multimodal tasks. On standard benchmarks, it rivals or exceeds proprietary models—including GPT‑4o and Claude 3.5—as a high-performance, cost-efficient alternative.

DeepSeek VL
DeepSeek VL is DeepSeek’s open-source vision-language model designed for real-world multimodal understanding. It employs a hybrid vision encoder (SigLIP‑L + SAM), processes high-resolution images (up to 1024×1024), and supports both base and chat variants across two sizes: 1.3B and 7B parameters. It excels on tasks like OCR, diagram reasoning, webpage parsing, and visual Q&A—while preserving strong language ability.
DeepSeek VL
DeepSeek VL is DeepSeek’s open-source vision-language model designed for real-world multimodal understanding. It employs a hybrid vision encoder (SigLIP‑L + SAM), processes high-resolution images (up to 1024×1024), and supports both base and chat variants across two sizes: 1.3B and 7B parameters. It excels on tasks like OCR, diagram reasoning, webpage parsing, and visual Q&A—while preserving strong language ability.
DeepSeek VL
DeepSeek VL is DeepSeek’s open-source vision-language model designed for real-world multimodal understanding. It employs a hybrid vision encoder (SigLIP‑L + SAM), processes high-resolution images (up to 1024×1024), and supports both base and chat variants across two sizes: 1.3B and 7B parameters. It excels on tasks like OCR, diagram reasoning, webpage parsing, and visual Q&A—while preserving strong language ability.

DeepSeek-R1-Zero
DeepSeek R1 Zero is an open-source large language model introduced in January 2025 by DeepSeek AI. It is a reinforcement learning–only version of DeepSeek R1, trained without supervised fine-tuning. With 671B total parameters (37B active) and a 128K-token context window, it demonstrates strong chain-of-thought reasoning, self-verification, and reflection.
DeepSeek-R1-Zero
DeepSeek R1 Zero is an open-source large language model introduced in January 2025 by DeepSeek AI. It is a reinforcement learning–only version of DeepSeek R1, trained without supervised fine-tuning. With 671B total parameters (37B active) and a 128K-token context window, it demonstrates strong chain-of-thought reasoning, self-verification, and reflection.
DeepSeek-R1-Zero
DeepSeek R1 Zero is an open-source large language model introduced in January 2025 by DeepSeek AI. It is a reinforcement learning–only version of DeepSeek R1, trained without supervised fine-tuning. With 671B total parameters (37B active) and a 128K-token context window, it demonstrates strong chain-of-thought reasoning, self-verification, and reflection.

DeepSeek R1 Lite Preview is the lightweight preview of DeepSeek’s flagship reasoning model, released on November 20, 2024. It’s designed for advanced chain-of-thought reasoning in math, coding, and logic, showcasing transparent, multi-round reasoning. It achieves performance on par—or exceeding—OpenAI’s o1-preview on benchmarks like AIME and MATH, using test-time compute scaling.
DeepSeek R1 Lite Preview is the lightweight preview of DeepSeek’s flagship reasoning model, released on November 20, 2024. It’s designed for advanced chain-of-thought reasoning in math, coding, and logic, showcasing transparent, multi-round reasoning. It achieves performance on par—or exceeding—OpenAI’s o1-preview on benchmarks like AIME and MATH, using test-time compute scaling.
DeepSeek R1 Lite Preview is the lightweight preview of DeepSeek’s flagship reasoning model, released on November 20, 2024. It’s designed for advanced chain-of-thought reasoning in math, coding, and logic, showcasing transparent, multi-round reasoning. It achieves performance on par—or exceeding—OpenAI’s o1-preview on benchmarks like AIME and MATH, using test-time compute scaling.

DeepSeek R1 Distill Qwen‑32B is a 32-billion-parameter dense reasoning model released in early 2025. Distilled from the flagship DeepSeek R1 using Qwen 2.5‑32B as a base, it delivers state-of-the-art performance among dense LLMs—outperforming OpenAI’s o1‑mini on benchmarks like AIME, MATH‑500, GPQA Diamond, LiveCodeBench, and CodeForces rating.
DeepSeek R1 Distill Qwen‑32B is a 32-billion-parameter dense reasoning model released in early 2025. Distilled from the flagship DeepSeek R1 using Qwen 2.5‑32B as a base, it delivers state-of-the-art performance among dense LLMs—outperforming OpenAI’s o1‑mini on benchmarks like AIME, MATH‑500, GPQA Diamond, LiveCodeBench, and CodeForces rating.
DeepSeek R1 Distill Qwen‑32B is a 32-billion-parameter dense reasoning model released in early 2025. Distilled from the flagship DeepSeek R1 using Qwen 2.5‑32B as a base, it delivers state-of-the-art performance among dense LLMs—outperforming OpenAI’s o1‑mini on benchmarks like AIME, MATH‑500, GPQA Diamond, LiveCodeBench, and CodeForces rating.

DeepSeek R1 0528 – Qwen3 ‑ 8B is an 8 B-parameter dense model distilled from DeepSeek‑R1‑0528 using Qwen3‑8B as its base. Released in May 2025, it transfers high-depth chain-of-thought reasoning into a compact architecture while achieving benchmark-leading results close to much larger models.
DeepSeek R1 0528 – Qwen3 ‑ 8B is an 8 B-parameter dense model distilled from DeepSeek‑R1‑0528 using Qwen3‑8B as its base. Released in May 2025, it transfers high-depth chain-of-thought reasoning into a compact architecture while achieving benchmark-leading results close to much larger models.
DeepSeek R1 0528 – Qwen3 ‑ 8B is an 8 B-parameter dense model distilled from DeepSeek‑R1‑0528 using Qwen3‑8B as its base. Released in May 2025, it transfers high-depth chain-of-thought reasoning into a compact architecture while achieving benchmark-leading results close to much larger models.

ChatBetter
ChatBetter is an AI platform designed to unify access to all major large language models (LLMs) within a single chat interface. Built for productivity and accuracy, ChatBetter leverages automatic model selection to route every query to the most capable AI—eliminating guesswork about which model to use. Users can directly compare responses from OpenAI, Anthropic, Google, Meta, DeepSeek, Perplexity, Mistral, xAI, and Cohere models side by side, or merge answers for comprehensive insights. The system is crafted for teams and individuals alike, enabling complex research, planning, and writing tasks to be accomplished efficiently in one place.
ChatBetter
ChatBetter is an AI platform designed to unify access to all major large language models (LLMs) within a single chat interface. Built for productivity and accuracy, ChatBetter leverages automatic model selection to route every query to the most capable AI—eliminating guesswork about which model to use. Users can directly compare responses from OpenAI, Anthropic, Google, Meta, DeepSeek, Perplexity, Mistral, xAI, and Cohere models side by side, or merge answers for comprehensive insights. The system is crafted for teams and individuals alike, enabling complex research, planning, and writing tasks to be accomplished efficiently in one place.
ChatBetter
ChatBetter is an AI platform designed to unify access to all major large language models (LLMs) within a single chat interface. Built for productivity and accuracy, ChatBetter leverages automatic model selection to route every query to the most capable AI—eliminating guesswork about which model to use. Users can directly compare responses from OpenAI, Anthropic, Google, Meta, DeepSeek, Perplexity, Mistral, xAI, and Cohere models side by side, or merge answers for comprehensive insights. The system is crafted for teams and individuals alike, enabling complex research, planning, and writing tasks to be accomplished efficiently in one place.
Yes Chat
YesChat AI is an all-in-one AI platform powered by advanced models such as DeepSeek-R1, GPT-o1, GPT-4o, Claude 3.5 Sonnet, and Claude 3 Opus. It offers AI chat, music generation, video creation, and image generation within one environment. The platform gives users ultra-fast, intelligent responses while enabling creative and multimedia capabilities through multiple high-performance models. By combining several leading AI engines, YesChat AI provides flexibility for writing, research, creativity, and content generation without requiring different subscriptions or tools.
Yes Chat
YesChat AI is an all-in-one AI platform powered by advanced models such as DeepSeek-R1, GPT-o1, GPT-4o, Claude 3.5 Sonnet, and Claude 3 Opus. It offers AI chat, music generation, video creation, and image generation within one environment. The platform gives users ultra-fast, intelligent responses while enabling creative and multimedia capabilities through multiple high-performance models. By combining several leading AI engines, YesChat AI provides flexibility for writing, research, creativity, and content generation without requiring different subscriptions or tools.
Yes Chat
YesChat AI is an all-in-one AI platform powered by advanced models such as DeepSeek-R1, GPT-o1, GPT-4o, Claude 3.5 Sonnet, and Claude 3 Opus. It offers AI chat, music generation, video creation, and image generation within one environment. The platform gives users ultra-fast, intelligent responses while enabling creative and multimedia capabilities through multiple high-performance models. By combining several leading AI engines, YesChat AI provides flexibility for writing, research, creativity, and content generation without requiring different subscriptions or tools.
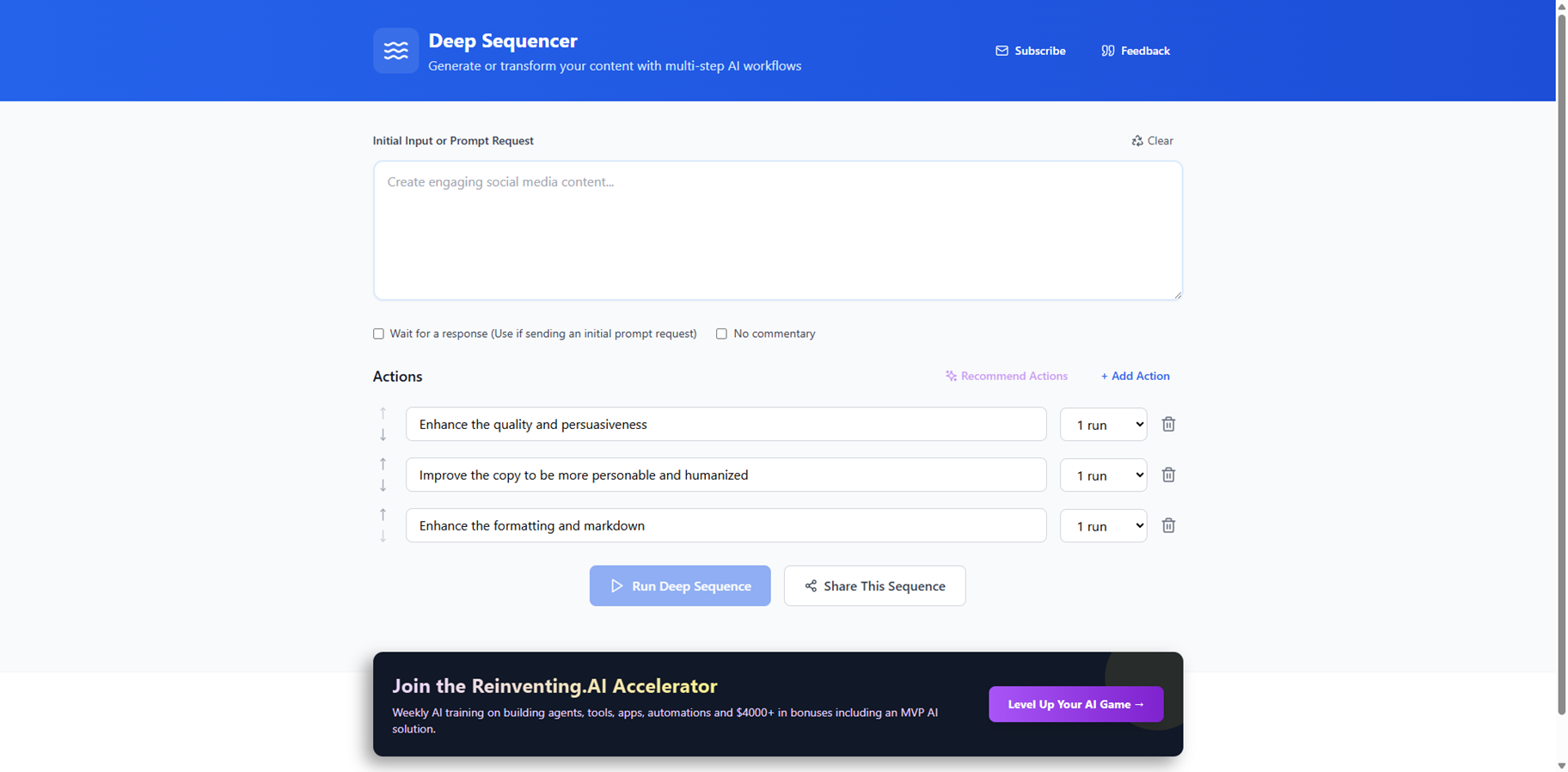
Deep Sequencer
DeepSequencer.netlify.app is a slick web app for crafting multi-step AI workflows that generate or transform content using chained prompts to DeepSeek v3. Start with an initial input or prompt, then layer up to 10 actions or runs, like recommending next steps, waiting for responses, or running sequences multiple times, without extra commentary cluttering things. Perfect for complex tasks needing sequential AI thinking, it lets you build, run up to 10 iterations, share sequences, and clear setups easily. No-code interface makes advanced prompt chaining accessible for creators tackling content, ideas, or data flows in one go. Subscribe for more power.
Deep Sequencer
DeepSequencer.netlify.app is a slick web app for crafting multi-step AI workflows that generate or transform content using chained prompts to DeepSeek v3. Start with an initial input or prompt, then layer up to 10 actions or runs, like recommending next steps, waiting for responses, or running sequences multiple times, without extra commentary cluttering things. Perfect for complex tasks needing sequential AI thinking, it lets you build, run up to 10 iterations, share sequences, and clear setups easily. No-code interface makes advanced prompt chaining accessible for creators tackling content, ideas, or data flows in one go. Subscribe for more power.
Deep Sequencer
DeepSequencer.netlify.app is a slick web app for crafting multi-step AI workflows that generate or transform content using chained prompts to DeepSeek v3. Start with an initial input or prompt, then layer up to 10 actions or runs, like recommending next steps, waiting for responses, or running sequences multiple times, without extra commentary cluttering things. Perfect for complex tasks needing sequential AI thinking, it lets you build, run up to 10 iterations, share sequences, and clear setups easily. No-code interface makes advanced prompt chaining accessible for creators tackling content, ideas, or data flows in one go. Subscribe for more power.
Editorial Note
This page was researched and written by the ATB Editorial Team. Our team researches each AI tool by reviewing its official website, testing features, exploring real use cases, and considering user feedback. Every page is fact-checked and regularly updated to ensure the information stays accurate, neutral, and useful for our readers.
If you have any suggestions or questions, email us at hello@aitoolbook.ai