
- Developers & Engineers: Execute full coding workflows, large code transformations, CLI agent use, and repository navigation.
- Data Scientists & Analysts: Analyze complex data, interpret visuals, and surface insights from lengthy documents.
- AI & Automation Teams: Build sophisticated AI agents and multi-step workflows with strong reasoning.
- Enterprise & AI-Powered App Builders: Embed Sonnet 4 via API in Amazon Bedrock, Vertex AI, or Anthropic platforms.
- Writers & Knowledge Teams: Generate polished content and get accurate Q&A over extensive datasets.
How to Use Claude Sonnet 4?
- Use via Chat & API: Accessible on Claude.ai (free/Pro/Team) and via Anthropic API, AWS Bedrock, and Google Vertex AI.
- Choose Thinking Mode: Use Standard Mode for quick answers or Extended Thinking for chain-of-thought reasoning—visible to users.
- Specify Token Budgets: Set limits via API—up to 200K tokens—for faster, longer, or larger-context responses.
- Leverage “Computer Use”: Direct Claude to interact with UIs—click, type, navigate—more reliably than earlier versions.
- Hybrid Reasoning Architecture: Single model that toggles between fast replies and deep reasoning dynamically.
- Extended Thinking Transparency: Step-by-step logic is visible to users—users decide when depth is needed.
- Superior Coding & Agentic Workflows: Improved SWE-bench and TAU-bench scores, strong CLI and codebase handling.
- Large 200K Context Window: Ideal for extensive content, codebases, documents, or multi-step workflows.
- Multimodal & Vision Support: Understands charts, diagrams, visuals; extract and analyze data easily.
- Hybrid agility: Quick answers plus transparent reasoning.
- Developer-grade coding: Ideal for large codebases and CI workflows.
- Automation power: Computer interaction enables operational tasks.
- Huge context: Excellent for analyzing long docs or corpora.
- Multi-platform access: Via Claude UI, API, cloud tools, and data platforms.
- Extended thinking mode may slow down responses.
- UI‑based automation is still experimental and can misfire
- Deep thinking noticeably raises token usage and cost.
Free Tier
$ 0.00
- Chat on web, iOS, and Android
- Generate code and visualize data
- Write, edit, and create content
- Analyze text and images
- Ability to search the web
Pro Mode
$20/month
Connect Google Workspace: email, calendar, and docs
Connect any context or tool through Integrations with remote MCP
Extended thinking for complex work
Ability to use more Claude models
Max
$100/month
- Choose 5x or 20x more usage than Pro
- Higher output limits for all tasks
- Early access to advanced Claude features
- Priority access at high traffic times
API Usage
Free
- $3 per million input tokens & $15 per million output tokens
- Prompt caching write- $3.75 / MTok
- Prompt caching read- $0.30 / MTok
Proud of the love you're getting? Show off your AI Toolbook reviews—then invite more fans to share the love and build your credibility.
Add an AI Toolbook badge to your site—an easy way to drive followers, showcase updates, and collect reviews. It's like a mini 24/7 billboard for your AI.
Reviews
Rating Distribution
Average score
Popular Mention
FAQs
Similar AI Tools
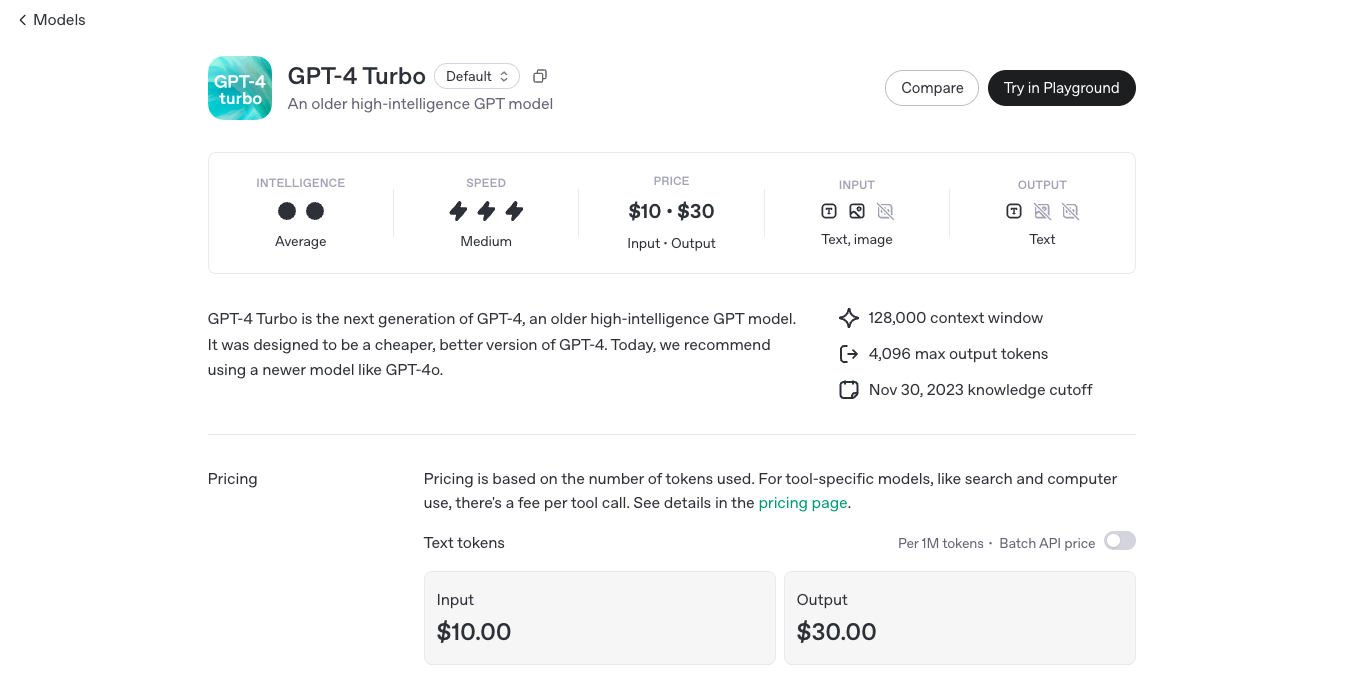
OpenAI GPT 4 Turbo
GPT-4 Turbo is OpenAI’s enhanced version of GPT-4, engineered to deliver faster performance, extended context handling, and more cost-effective usage. Released in November 2023, GPT-4 Turbo boasts a 128,000-token context window, allowing it to process and generate longer and more complex content. It supports multimodal inputs, including text and images, making it versatile for various applications.
OpenAI GPT 4 Turbo
GPT-4 Turbo is OpenAI’s enhanced version of GPT-4, engineered to deliver faster performance, extended context handling, and more cost-effective usage. Released in November 2023, GPT-4 Turbo boasts a 128,000-token context window, allowing it to process and generate longer and more complex content. It supports multimodal inputs, including text and images, making it versatile for various applications.
OpenAI GPT 4 Turbo
GPT-4 Turbo is OpenAI’s enhanced version of GPT-4, engineered to deliver faster performance, extended context handling, and more cost-effective usage. Released in November 2023, GPT-4 Turbo boasts a 128,000-token context window, allowing it to process and generate longer and more complex content. It supports multimodal inputs, including text and images, making it versatile for various applications.

Grok 3
Grok 3 is the latest flagship chatbot by Elon Musk’s xAI, described as "the world’s smartest AI." It was trained on a massive 200,000‑GPU supercomputer and offers tenfold more computing power than Grok 2. Equipped with two reasoning modes—Think and Big Brain—and featuring DeepSearch (a contextual web-and-X research tool), Grok 3 excels in math, science, coding, and truth-seeking tasks—all while offering fast, lively conversational style.
Grok 3
Grok 3 is the latest flagship chatbot by Elon Musk’s xAI, described as "the world’s smartest AI." It was trained on a massive 200,000‑GPU supercomputer and offers tenfold more computing power than Grok 2. Equipped with two reasoning modes—Think and Big Brain—and featuring DeepSearch (a contextual web-and-X research tool), Grok 3 excels in math, science, coding, and truth-seeking tasks—all while offering fast, lively conversational style.
Grok 3
Grok 3 is the latest flagship chatbot by Elon Musk’s xAI, described as "the world’s smartest AI." It was trained on a massive 200,000‑GPU supercomputer and offers tenfold more computing power than Grok 2. Equipped with two reasoning modes—Think and Big Brain—and featuring DeepSearch (a contextual web-and-X research tool), Grok 3 excels in math, science, coding, and truth-seeking tasks—all while offering fast, lively conversational style.
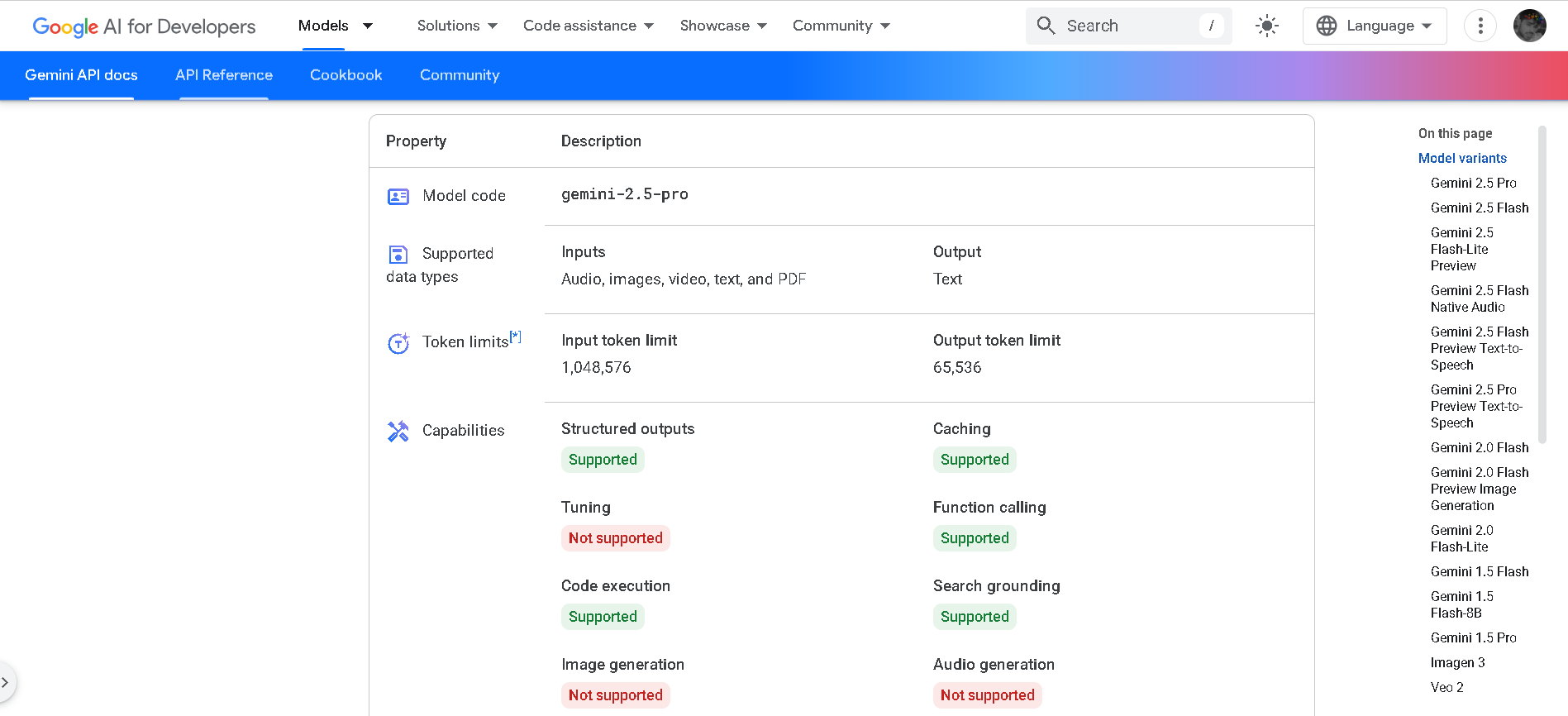

Gemini 2.5 Pro
Gemini 2.5 Pro is Google DeepMind’s advanced hybrid-reasoning AI model, designed to think deeply before responding. With support for multimodal inputs—text, images, audio, video, and code—it offers lightning-fast inference performance, up to 2 million tokens of context, and top-tier results in math, science, and coding benchmarks.
Gemini 2.5 Pro
Gemini 2.5 Pro is Google DeepMind’s advanced hybrid-reasoning AI model, designed to think deeply before responding. With support for multimodal inputs—text, images, audio, video, and code—it offers lightning-fast inference performance, up to 2 million tokens of context, and top-tier results in math, science, and coding benchmarks.
Gemini 2.5 Pro
Gemini 2.5 Pro is Google DeepMind’s advanced hybrid-reasoning AI model, designed to think deeply before responding. With support for multimodal inputs—text, images, audio, video, and code—it offers lightning-fast inference performance, up to 2 million tokens of context, and top-tier results in math, science, and coding benchmarks.

Meta Llama 4
Meta Llama 4 is the latest generation of Meta’s large language model series. It features a mixture-of-experts (MoE) architecture, making it both highly efficient and powerful. Llama 4 is natively multimodal—supporting text and image inputs—and offers three key variants: Scout (17B active parameters, 10 M token context), Maverick (17B active, 1 M token context), and Behemoth (288B active, 2 T total parameters; still in development). Designed for long-context reasoning, multilingual understanding, and open-weight availability (with license restrictions), Llama 4 excels in benchmarks and versatility.
Meta Llama 4
Meta Llama 4 is the latest generation of Meta’s large language model series. It features a mixture-of-experts (MoE) architecture, making it both highly efficient and powerful. Llama 4 is natively multimodal—supporting text and image inputs—and offers three key variants: Scout (17B active parameters, 10 M token context), Maverick (17B active, 1 M token context), and Behemoth (288B active, 2 T total parameters; still in development). Designed for long-context reasoning, multilingual understanding, and open-weight availability (with license restrictions), Llama 4 excels in benchmarks and versatility.
Meta Llama 4
Meta Llama 4 is the latest generation of Meta’s large language model series. It features a mixture-of-experts (MoE) architecture, making it both highly efficient and powerful. Llama 4 is natively multimodal—supporting text and image inputs—and offers three key variants: Scout (17B active parameters, 10 M token context), Maverick (17B active, 1 M token context), and Behemoth (288B active, 2 T total parameters; still in development). Designed for long-context reasoning, multilingual understanding, and open-weight availability (with license restrictions), Llama 4 excels in benchmarks and versatility.

DeepSeek-V3
DeepSeek V3 is the latest flagship Mixture‑of‑Experts (MoE) open‑source AI model from DeepSeek. It features 671 billion total parameters (with ~37 billion activated per token), supports up to 128K context length, and excels across reasoning, code generation, language, and multimodal tasks. On standard benchmarks, it rivals or exceeds proprietary models—including GPT‑4o and Claude 3.5—as a high-performance, cost-efficient alternative.
DeepSeek-V3
DeepSeek V3 is the latest flagship Mixture‑of‑Experts (MoE) open‑source AI model from DeepSeek. It features 671 billion total parameters (with ~37 billion activated per token), supports up to 128K context length, and excels across reasoning, code generation, language, and multimodal tasks. On standard benchmarks, it rivals or exceeds proprietary models—including GPT‑4o and Claude 3.5—as a high-performance, cost-efficient alternative.
DeepSeek-V3
DeepSeek V3 is the latest flagship Mixture‑of‑Experts (MoE) open‑source AI model from DeepSeek. It features 671 billion total parameters (with ~37 billion activated per token), supports up to 128K context length, and excels across reasoning, code generation, language, and multimodal tasks. On standard benchmarks, it rivals or exceeds proprietary models—including GPT‑4o and Claude 3.5—as a high-performance, cost-efficient alternative.

grok-3-fast
Grok 3 Fast is xAI’s low-latency variant of their flagship Grok 3 model. It delivers identical output quality but responds faster by leveraging optimized serving infrastructure—ideal for real-time, speed-sensitive applications. It inherits the same multimodal, reasoning, and chain-of-thought capabilities as Grok 3, with a large context window of ~131K tokens.
grok-3-fast
Grok 3 Fast is xAI’s low-latency variant of their flagship Grok 3 model. It delivers identical output quality but responds faster by leveraging optimized serving infrastructure—ideal for real-time, speed-sensitive applications. It inherits the same multimodal, reasoning, and chain-of-thought capabilities as Grok 3, with a large context window of ~131K tokens.
grok-3-fast
Grok 3 Fast is xAI’s low-latency variant of their flagship Grok 3 model. It delivers identical output quality but responds faster by leveraging optimized serving infrastructure—ideal for real-time, speed-sensitive applications. It inherits the same multimodal, reasoning, and chain-of-thought capabilities as Grok 3, with a large context window of ~131K tokens.

grok-2-latest
Grok 2 is xAI’s second-generation chatbot model, launched in August 2024 as a substantial upgrade over Grok 1.5. It delivers frontier-level performance in chat, coding, reasoning, vision tasks, and image generation via the FLUX.1 system. On leaderboards, it outscored Claude 3.5 Sonnet and GPT‑4 Turbo, with strong results in GPQA (56%), MMLU (87.5%), MATH (76.1%), HumanEval (88.4%), MathVista, and DocVQA benchmarks.
grok-2-latest
Grok 2 is xAI’s second-generation chatbot model, launched in August 2024 as a substantial upgrade over Grok 1.5. It delivers frontier-level performance in chat, coding, reasoning, vision tasks, and image generation via the FLUX.1 system. On leaderboards, it outscored Claude 3.5 Sonnet and GPT‑4 Turbo, with strong results in GPQA (56%), MMLU (87.5%), MATH (76.1%), HumanEval (88.4%), MathVista, and DocVQA benchmarks.
grok-2-latest
Grok 2 is xAI’s second-generation chatbot model, launched in August 2024 as a substantial upgrade over Grok 1.5. It delivers frontier-level performance in chat, coding, reasoning, vision tasks, and image generation via the FLUX.1 system. On leaderboards, it outscored Claude 3.5 Sonnet and GPT‑4 Turbo, with strong results in GPQA (56%), MMLU (87.5%), MATH (76.1%), HumanEval (88.4%), MathVista, and DocVQA benchmarks.
Llama 4 Behemoth is Meta’s ultimate “teacher” model within the Llama 4 series, currently in preview and training. Featuring an enormous 2 trillion total parameters with 288 billion active in a Mixture-of-Experts architecture (16 experts), it's designed to push the limits of multimodal reasoning, STEM, and long-context tasks. Initially slated for April 2025, its release has been postponed to fall 2025 or later due to internal performance and alignment concerns.
Llama 4 Behemoth is Meta’s ultimate “teacher” model within the Llama 4 series, currently in preview and training. Featuring an enormous 2 trillion total parameters with 288 billion active in a Mixture-of-Experts architecture (16 experts), it's designed to push the limits of multimodal reasoning, STEM, and long-context tasks. Initially slated for April 2025, its release has been postponed to fall 2025 or later due to internal performance and alignment concerns.
Llama 4 Behemoth is Meta’s ultimate “teacher” model within the Llama 4 series, currently in preview and training. Featuring an enormous 2 trillion total parameters with 288 billion active in a Mixture-of-Experts architecture (16 experts), it's designed to push the limits of multimodal reasoning, STEM, and long-context tasks. Initially slated for April 2025, its release has been postponed to fall 2025 or later due to internal performance and alignment concerns.

DeepSeek R1 0528 – Qwen3 ‑ 8B is an 8 B-parameter dense model distilled from DeepSeek‑R1‑0528 using Qwen3‑8B as its base. Released in May 2025, it transfers high-depth chain-of-thought reasoning into a compact architecture while achieving benchmark-leading results close to much larger models.
DeepSeek R1 0528 – Qwen3 ‑ 8B is an 8 B-parameter dense model distilled from DeepSeek‑R1‑0528 using Qwen3‑8B as its base. Released in May 2025, it transfers high-depth chain-of-thought reasoning into a compact architecture while achieving benchmark-leading results close to much larger models.
DeepSeek R1 0528 – Qwen3 ‑ 8B is an 8 B-parameter dense model distilled from DeepSeek‑R1‑0528 using Qwen3‑8B as its base. Released in May 2025, it transfers high-depth chain-of-thought reasoning into a compact architecture while achieving benchmark-leading results close to much larger models.

Perplexity AI
Perplexity AI is a powerful AI‑powered answer engine and search assistant launched in December 2022. It combines real‑time web search with large language models (like GPT‑4.1, Claude 4, Sonar), delivering direct answers with in‑text citations and multi‑turn conversational context.
Perplexity AI
Perplexity AI is a powerful AI‑powered answer engine and search assistant launched in December 2022. It combines real‑time web search with large language models (like GPT‑4.1, Claude 4, Sonar), delivering direct answers with in‑text citations and multi‑turn conversational context.
Perplexity AI
Perplexity AI is a powerful AI‑powered answer engine and search assistant launched in December 2022. It combines real‑time web search with large language models (like GPT‑4.1, Claude 4, Sonar), delivering direct answers with in‑text citations and multi‑turn conversational context.
Qwen Chat
Qwen Chat is Alibaba Cloud’s conversational AI assistant built on the Qwen series (e.g., Qwen‑7B‑Chat, Qwen1.5‑7B‑Chat, Qwen‑VL, Qwen‑Audio, and Qwen2.5‑Omni). It supports text, vision, audio, and video understanding, plus image and document processing, web search integration, and image generation—all through a unified chat interface.
Qwen Chat
Qwen Chat is Alibaba Cloud’s conversational AI assistant built on the Qwen series (e.g., Qwen‑7B‑Chat, Qwen1.5‑7B‑Chat, Qwen‑VL, Qwen‑Audio, and Qwen2.5‑Omni). It supports text, vision, audio, and video understanding, plus image and document processing, web search integration, and image generation—all through a unified chat interface.
Qwen Chat
Qwen Chat is Alibaba Cloud’s conversational AI assistant built on the Qwen series (e.g., Qwen‑7B‑Chat, Qwen1.5‑7B‑Chat, Qwen‑VL, Qwen‑Audio, and Qwen2.5‑Omni). It supports text, vision, audio, and video understanding, plus image and document processing, web search integration, and image generation—all through a unified chat interface.


GlobalGPT
GlobalGPT is an all-in-one AI platform that unifies leading models for writing, coding, research, image generation, and video creation—accessible through a single account and subscription. It brings together top models like GPT-5, GPT-4.1, GPT-4o, GPT-o3, Claude Opus 4.1, Claude Sonnet 4, Gemini 2.5 Pro, DeepSeek V3, Unikorn (MJ-like) V7, Flux, Ideogram, and Google Veo 3 so you can chat, draft content, analyze documents, generate images, and produce cinematic videos without switching tools. Designed for over 2 million users worldwide, GlobalGPT also includes advanced research agents powered by GPT-4o and perplexity for deep web analysis, PDF summarization, and market insights, all wrapped in a clean interface with flexible credit-based plans.
GlobalGPT
GlobalGPT is an all-in-one AI platform that unifies leading models for writing, coding, research, image generation, and video creation—accessible through a single account and subscription. It brings together top models like GPT-5, GPT-4.1, GPT-4o, GPT-o3, Claude Opus 4.1, Claude Sonnet 4, Gemini 2.5 Pro, DeepSeek V3, Unikorn (MJ-like) V7, Flux, Ideogram, and Google Veo 3 so you can chat, draft content, analyze documents, generate images, and produce cinematic videos without switching tools. Designed for over 2 million users worldwide, GlobalGPT also includes advanced research agents powered by GPT-4o and perplexity for deep web analysis, PDF summarization, and market insights, all wrapped in a clean interface with flexible credit-based plans.
GlobalGPT
GlobalGPT is an all-in-one AI platform that unifies leading models for writing, coding, research, image generation, and video creation—accessible through a single account and subscription. It brings together top models like GPT-5, GPT-4.1, GPT-4o, GPT-o3, Claude Opus 4.1, Claude Sonnet 4, Gemini 2.5 Pro, DeepSeek V3, Unikorn (MJ-like) V7, Flux, Ideogram, and Google Veo 3 so you can chat, draft content, analyze documents, generate images, and produce cinematic videos without switching tools. Designed for over 2 million users worldwide, GlobalGPT also includes advanced research agents powered by GPT-4o and perplexity for deep web analysis, PDF summarization, and market insights, all wrapped in a clean interface with flexible credit-based plans.
Editorial Note
This page was researched and written by the ATB Editorial Team. Our team researches each AI tool by reviewing its official website, testing features, exploring real use cases, and considering user feedback. Every page is fact-checked and regularly updated to ensure the information stays accurate, neutral, and useful for our readers.
If you have any suggestions or questions, email us at hello@aitoolbook.ai