
As part of OpenAI’s GPT-4 Turbo family, o3 delivers high-quality outputs at scale, supporting both chat and completion endpoints. It’s currently used in various commercial and developer-facing tools for streamlined and intelligent interactions.
- Product Builders & SaaS Startups: Add fast, reliable AI to apps and platforms for content, summarization, chat, and more.
- Developers & Engineers: Use o3 in APIs to power backend intelligence and conversational experiences.
- Marketing Teams: Automate personalized copywriting, A/B test messaging, and scale ad generation.
- Support & Ops Teams: Create bots or co-pilots to manage queries, tickets, and internal documentation.
- Data Analysts & Researchers: Summarize documents, generate insights, or analyze large text corpora.
- Educators & Students: Simplify concepts, answer questions, and generate custom learning content.
🛠️ How to Use o3?
- Step 1: Access via OpenAI Platform: Login to the OpenAI platform and choose the o3 model when calling the Chat or Completion API.
- Step 2: Choose Endpoint Type: Use either the /v1/chat/completions or /v1/completions endpoint depending on your interface style.
- Step 3: Provide Input Prompt: Feed a prompt in plain language, structured commands, or formatted queries.
- Step 4: Configure Parameters: Tune temperature, topp, maxtokens, etc., to shape the response’s tone and length.
- Step 5: Receive Fast, Accurate Output: The model returns coherent, context-aware responses ideal for a variety of production use cases.
- Step 6: Scale Seamlessly: With improved cost-efficiency and performance, o3 is built for both hobby projects and enterprise workloads.
- Advanced Language Understanding: Excellent at complex tasks such as summarization, reasoning, and code generation.
- Turbo Performance: Lower latency and faster output than GPT-4, making it ideal for real-time apps.
- Multilingual Mastery: Handles prompts and generates responses in multiple languages with fluency.
- Cost-Effective: Offers a better balance between quality and cost, especially compared to earlier GPT-4 variants.
- Structured Output Capabilities: Supports JSON-mode and function calling for integrating seamlessly with apps.
- Ecosystem-Friendly: Built to work smoothly within OpenAI tools, plugins, Assistants API, and more.
- Fast and Responsive: Minimal lag in completions—great for dynamic interfaces.
- Strong Reasoning Capabilities: Ideal for answering nuanced queries and following multi-step logic.
- Excellent Conversational Skills: Smooth, human-like dialog performance.
- Supports JSON and Function Calling: Structured outputs make it developer-friendly.
- Optimized for Versatility: From chatbots to internal tools—o3 delivers across the board.
- Still Premium-Priced: While cheaper than GPT-4, it’s more expensive than GPT-3.5 for high-volume use.
- Occasional Hallucinations: As with any LLM, factual errors can still occur in some contexts.
- Limited Public Info: OpenAI has not fully disclosed architectural details or training methods.
- Heavier for Light Use Cases: May be overkill for tasks that don't require deep reasoning or nuance.
- Fewer Fine-Tuning Options: Custom fine-tuning isn’t yet generally available for o3.
API
$10/$40
Free
$ 0.00
Standard voice mode
Real-time data from the web with search
Limited access to GPT-4o and o4-mini
Limited access to file uploads, advanced data analysis, and image generation
Use custom GPTs
Plus
$ 20.00
Extended limits on messaging, file uploads, advanced data analysis, and image generation
Standard and advanced voice mode
Access to deep research, multiple reasoning models (o4-mini, o4-mini-high, and o3), and a research preview of GPT-4.5
Create and use tasks, projects, and custom GPTs
Limited access to Sora video generation
Opportunities to test new features
Pro
$ 200.00
Unlimited access to all reasoning models and GPT-4o
Unlimited access to advanced voice
Extended access to deep research, which conducts multi-step online research for complex tasks
Access to research previews of GPT-4.5 and Operator
Access to o1 pro mode, which uses more compute for the best answers to the hardest questions
Extended access to Sora video generation
Access to a research preview of Codex agent
Proud of the love you're getting? Show off your AI Toolbook reviews—then invite more fans to share the love and build your credibility.
Add an AI Toolbook badge to your site—an easy way to drive followers, showcase updates, and collect reviews. It's like a mini 24/7 billboard for your AI.
Reviews
Rating Distribution
Average score
Popular Mention
FAQs
Similar AI Tools

text-embedding-3-large is OpenAI’s most advanced embedding model designed to convert natural language text into high-dimensional vector representations. With 3,072 dimensions per embedding and cutting-edge architecture, it offers best-in-class performance for tasks like semantic search, content recommendations, clustering, classification, and more. Built to deliver top-tier semantic understanding, this model is ideal when accuracy and relevance are mission-critical. It’s the spiritual successor to text-embedding-ada-002, bringing huge improvements in contextual understanding, generalization, and relevance scoring.
text-embedding-3-large is OpenAI’s most advanced embedding model designed to convert natural language text into high-dimensional vector representations. With 3,072 dimensions per embedding and cutting-edge architecture, it offers best-in-class performance for tasks like semantic search, content recommendations, clustering, classification, and more. Built to deliver top-tier semantic understanding, this model is ideal when accuracy and relevance are mission-critical. It’s the spiritual successor to text-embedding-ada-002, bringing huge improvements in contextual understanding, generalization, and relevance scoring.
text-embedding-3-large is OpenAI’s most advanced embedding model designed to convert natural language text into high-dimensional vector representations. With 3,072 dimensions per embedding and cutting-edge architecture, it offers best-in-class performance for tasks like semantic search, content recommendations, clustering, classification, and more. Built to deliver top-tier semantic understanding, this model is ideal when accuracy and relevance are mission-critical. It’s the spiritual successor to text-embedding-ada-002, bringing huge improvements in contextual understanding, generalization, and relevance scoring.

OpenAI o1-pro
o1-pro is a highly capable AI model developed by OpenAI, designed to deliver efficient, high-quality text generation across a wide range of use cases. As part of OpenAI’s GPT-4 architecture family, o1-pro is optimized for low-latency performance and high accuracy—making it suitable for both everyday tasks and enterprise-scale applications. It powers natural language interactions, content creation, summarization, and more, offering developers a solid balance between performance, cost, and output quality.
OpenAI o1-pro
o1-pro is a highly capable AI model developed by OpenAI, designed to deliver efficient, high-quality text generation across a wide range of use cases. As part of OpenAI’s GPT-4 architecture family, o1-pro is optimized for low-latency performance and high accuracy—making it suitable for both everyday tasks and enterprise-scale applications. It powers natural language interactions, content creation, summarization, and more, offering developers a solid balance between performance, cost, and output quality.
OpenAI o1-pro
o1-pro is a highly capable AI model developed by OpenAI, designed to deliver efficient, high-quality text generation across a wide range of use cases. As part of OpenAI’s GPT-4 architecture family, o1-pro is optimized for low-latency performance and high accuracy—making it suitable for both everyday tasks and enterprise-scale applications. It powers natural language interactions, content creation, summarization, and more, offering developers a solid balance between performance, cost, and output quality.

OpenAI - GPT 4.1
GPT-4.1 is OpenAI’s newest multimodal large language model, designed to deliver highly capable, efficient, and intelligent performance across a broad range of tasks. It builds on the foundation of GPT-4 and GPT-4 Turbo, offering enhanced reasoning, greater factual accuracy, and smoother integration with tools like code interpreters, retrieval systems, and image understanding. With native support for a 128K token context window, function calling, and robust tool usage, GPT-4.1 brings AI closer to behaving like a reliable, adaptive assistant—ready to work, build, and collaborate across tasks with speed and precision.
OpenAI - GPT 4.1
GPT-4.1 is OpenAI’s newest multimodal large language model, designed to deliver highly capable, efficient, and intelligent performance across a broad range of tasks. It builds on the foundation of GPT-4 and GPT-4 Turbo, offering enhanced reasoning, greater factual accuracy, and smoother integration with tools like code interpreters, retrieval systems, and image understanding. With native support for a 128K token context window, function calling, and robust tool usage, GPT-4.1 brings AI closer to behaving like a reliable, adaptive assistant—ready to work, build, and collaborate across tasks with speed and precision.
OpenAI - GPT 4.1
GPT-4.1 is OpenAI’s newest multimodal large language model, designed to deliver highly capable, efficient, and intelligent performance across a broad range of tasks. It builds on the foundation of GPT-4 and GPT-4 Turbo, offering enhanced reasoning, greater factual accuracy, and smoother integration with tools like code interpreters, retrieval systems, and image understanding. With native support for a 128K token context window, function calling, and robust tool usage, GPT-4.1 brings AI closer to behaving like a reliable, adaptive assistant—ready to work, build, and collaborate across tasks with speed and precision.

codex-mini-latest is OpenAI’s lightweight, high-speed AI coding model, fine-tuned from the o4-mini architecture. Designed specifically for use with the Codex CLI, it brings ChatGPT-level reasoning directly to your terminal, enabling efficient code generation, debugging, and editing tasks. Despite its compact size, codex-mini-latest delivers impressive performance, making it ideal for developers seeking a fast, cost-effective coding assistant.
codex-mini-latest is OpenAI’s lightweight, high-speed AI coding model, fine-tuned from the o4-mini architecture. Designed specifically for use with the Codex CLI, it brings ChatGPT-level reasoning directly to your terminal, enabling efficient code generation, debugging, and editing tasks. Despite its compact size, codex-mini-latest delivers impressive performance, making it ideal for developers seeking a fast, cost-effective coding assistant.
codex-mini-latest is OpenAI’s lightweight, high-speed AI coding model, fine-tuned from the o4-mini architecture. Designed specifically for use with the Codex CLI, it brings ChatGPT-level reasoning directly to your terminal, enabling efficient code generation, debugging, and editing tasks. Despite its compact size, codex-mini-latest delivers impressive performance, making it ideal for developers seeking a fast, cost-effective coding assistant.
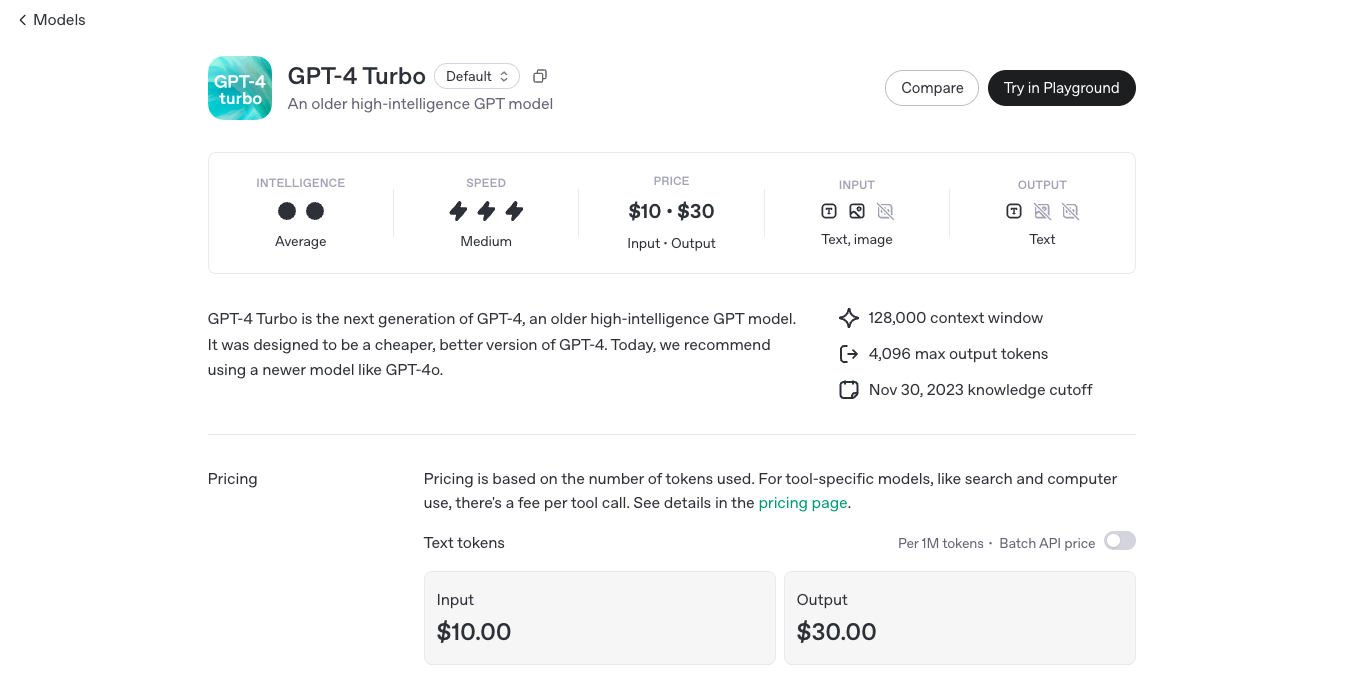
OpenAI GPT 4 Turbo
GPT-4 Turbo is OpenAI’s enhanced version of GPT-4, engineered to deliver faster performance, extended context handling, and more cost-effective usage. Released in November 2023, GPT-4 Turbo boasts a 128,000-token context window, allowing it to process and generate longer and more complex content. It supports multimodal inputs, including text and images, making it versatile for various applications.
OpenAI GPT 4 Turbo
GPT-4 Turbo is OpenAI’s enhanced version of GPT-4, engineered to deliver faster performance, extended context handling, and more cost-effective usage. Released in November 2023, GPT-4 Turbo boasts a 128,000-token context window, allowing it to process and generate longer and more complex content. It supports multimodal inputs, including text and images, making it versatile for various applications.
OpenAI GPT 4 Turbo
GPT-4 Turbo is OpenAI’s enhanced version of GPT-4, engineered to deliver faster performance, extended context handling, and more cost-effective usage. Released in November 2023, GPT-4 Turbo boasts a 128,000-token context window, allowing it to process and generate longer and more complex content. It supports multimodal inputs, including text and images, making it versatile for various applications.
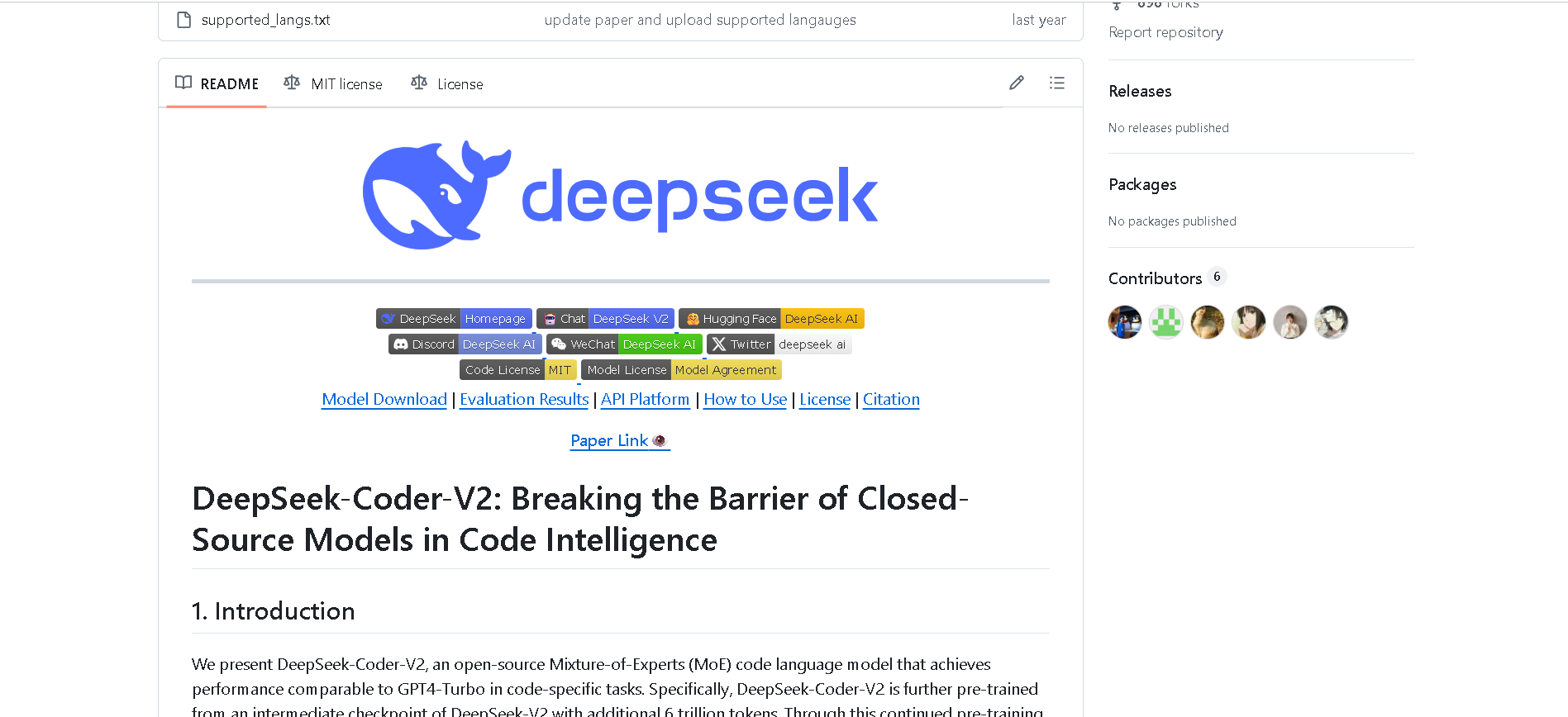
DeepSeek-Coder-V2
DeepSeek‑Coder V2 is an open-source, Mixture‑of‑Experts (MoE) code-focused variant of DeepSeek‑V2, purpose-built for code generation, completion, debugging, and mathematical reasoning. Trained with an additional 6 trillion tokens of code and text, it supports up to 338 programming languages and a massive 128K‑token context window, rivaling or exceeding commercial code models in performance.
DeepSeek-Coder-V2
DeepSeek‑Coder V2 is an open-source, Mixture‑of‑Experts (MoE) code-focused variant of DeepSeek‑V2, purpose-built for code generation, completion, debugging, and mathematical reasoning. Trained with an additional 6 trillion tokens of code and text, it supports up to 338 programming languages and a massive 128K‑token context window, rivaling or exceeding commercial code models in performance.
DeepSeek-Coder-V2
DeepSeek‑Coder V2 is an open-source, Mixture‑of‑Experts (MoE) code-focused variant of DeepSeek‑V2, purpose-built for code generation, completion, debugging, and mathematical reasoning. Trained with an additional 6 trillion tokens of code and text, it supports up to 338 programming languages and a massive 128K‑token context window, rivaling or exceeding commercial code models in performance.
Langchain
LangChain is a powerful open-source framework designed to help developers build context-aware applications that leverage large language models (LLMs). It allows users to connect language models to various data sources, APIs, and memory components, enabling intelligent, multi-step reasoning and decision-making processes. LangChain supports both Python and JavaScript, providing modular building blocks for developers to create chatbots, AI assistants, retrieval-augmented generation (RAG) systems, and agent-based tools. The framework is widely adopted across industries for its flexibility in connecting structured and unstructured data with LLMs.
Langchain
LangChain is a powerful open-source framework designed to help developers build context-aware applications that leverage large language models (LLMs). It allows users to connect language models to various data sources, APIs, and memory components, enabling intelligent, multi-step reasoning and decision-making processes. LangChain supports both Python and JavaScript, providing modular building blocks for developers to create chatbots, AI assistants, retrieval-augmented generation (RAG) systems, and agent-based tools. The framework is widely adopted across industries for its flexibility in connecting structured and unstructured data with LLMs.
Langchain
LangChain is a powerful open-source framework designed to help developers build context-aware applications that leverage large language models (LLMs). It allows users to connect language models to various data sources, APIs, and memory components, enabling intelligent, multi-step reasoning and decision-making processes. LangChain supports both Python and JavaScript, providing modular building blocks for developers to create chatbots, AI assistants, retrieval-augmented generation (RAG) systems, and agent-based tools. The framework is widely adopted across industries for its flexibility in connecting structured and unstructured data with LLMs.
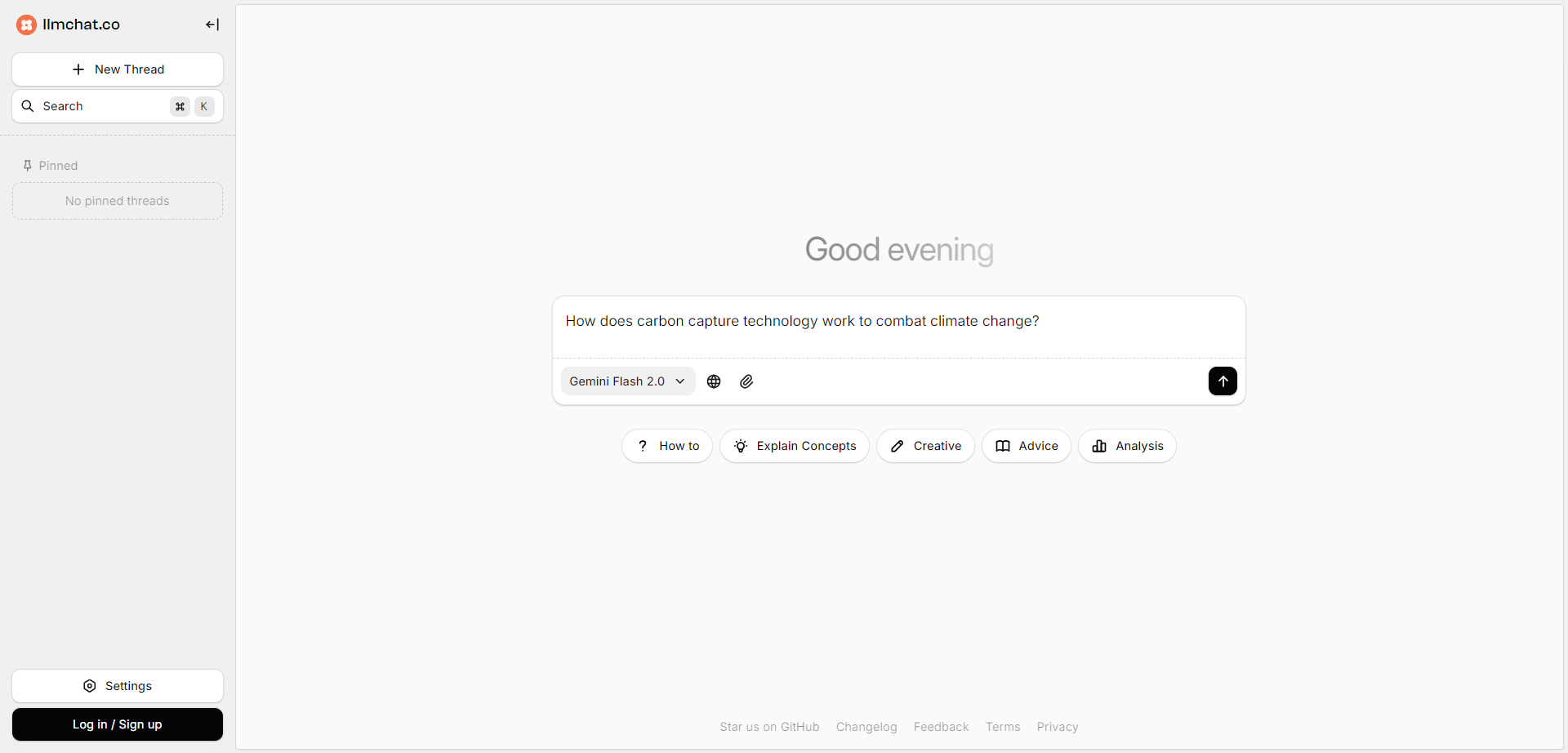

LLM Chat
LLMChat is a privacy-focused, open-source AI chatbot platform designed for advanced research, agentic workflows, and seamless interaction with multiple large language models (LLMs). It offers users a minimalistic and intuitive interface enabling deep exploration of complex topics with modes like Deep Research and Pro Search, which incorporates real-time web integration for current data. The platform emphasizes user privacy by storing all chat history locally in the browser, ensuring conversations never leave the device. LLMChat supports many popular LLM providers such as OpenAI, Anthropic, Google, and more, allowing users to customize AI assistants with personalized instructions and knowledge bases for a wide variety of applications ranging from research to content generation and coding assistance.
LLM Chat
LLMChat is a privacy-focused, open-source AI chatbot platform designed for advanced research, agentic workflows, and seamless interaction with multiple large language models (LLMs). It offers users a minimalistic and intuitive interface enabling deep exploration of complex topics with modes like Deep Research and Pro Search, which incorporates real-time web integration for current data. The platform emphasizes user privacy by storing all chat history locally in the browser, ensuring conversations never leave the device. LLMChat supports many popular LLM providers such as OpenAI, Anthropic, Google, and more, allowing users to customize AI assistants with personalized instructions and knowledge bases for a wide variety of applications ranging from research to content generation and coding assistance.
LLM Chat
LLMChat is a privacy-focused, open-source AI chatbot platform designed for advanced research, agentic workflows, and seamless interaction with multiple large language models (LLMs). It offers users a minimalistic and intuitive interface enabling deep exploration of complex topics with modes like Deep Research and Pro Search, which incorporates real-time web integration for current data. The platform emphasizes user privacy by storing all chat history locally in the browser, ensuring conversations never leave the device. LLMChat supports many popular LLM providers such as OpenAI, Anthropic, Google, and more, allowing users to customize AI assistants with personalized instructions and knowledge bases for a wide variety of applications ranging from research to content generation and coding assistance.

Awan LLM
Awan LLM is a cost-effective, unlimited token large language model inference API platform designed for power users and developers. Unlike traditional API providers that charge per token, Awan LLM offers a monthly subscription model that enables users to send and receive unlimited tokens up to the model's context limit. It supports unrestricted use of LLM models without censorship or constraints. The platform is built on privately owned data centers and GPUs, allowing it to offer efficient and scalable AI services. Awan LLM supports numerous use cases including AI assistants, AI agents, roleplaying, data processing, code completion, and building AI-powered applications without worrying about token limits or costs.
Awan LLM
Awan LLM is a cost-effective, unlimited token large language model inference API platform designed for power users and developers. Unlike traditional API providers that charge per token, Awan LLM offers a monthly subscription model that enables users to send and receive unlimited tokens up to the model's context limit. It supports unrestricted use of LLM models without censorship or constraints. The platform is built on privately owned data centers and GPUs, allowing it to offer efficient and scalable AI services. Awan LLM supports numerous use cases including AI assistants, AI agents, roleplaying, data processing, code completion, and building AI-powered applications without worrying about token limits or costs.
Awan LLM
Awan LLM is a cost-effective, unlimited token large language model inference API platform designed for power users and developers. Unlike traditional API providers that charge per token, Awan LLM offers a monthly subscription model that enables users to send and receive unlimited tokens up to the model's context limit. It supports unrestricted use of LLM models without censorship or constraints. The platform is built on privately owned data centers and GPUs, allowing it to offer efficient and scalable AI services. Awan LLM supports numerous use cases including AI assistants, AI agents, roleplaying, data processing, code completion, and building AI-powered applications without worrying about token limits or costs.
LM Studio
LM Studio is a local large language model (LLM) platform that enables users to run and download powerful AI language models like LLaMa, MPT, and Gemma directly on their own computers. This platform supports Mac, Windows, and Linux operating systems, providing flexibility to users across different devices. LM Studio focuses on privacy and control by allowing users to work with AI models locally without relying on cloud-based services, ensuring data stays on the user’s device. It offers an easy-to-install interface with step-by-step guidance for setup, facilitating access to advanced AI capabilities for developers, researchers, and AI enthusiasts without requiring an internet connection.
LM Studio
LM Studio is a local large language model (LLM) platform that enables users to run and download powerful AI language models like LLaMa, MPT, and Gemma directly on their own computers. This platform supports Mac, Windows, and Linux operating systems, providing flexibility to users across different devices. LM Studio focuses on privacy and control by allowing users to work with AI models locally without relying on cloud-based services, ensuring data stays on the user’s device. It offers an easy-to-install interface with step-by-step guidance for setup, facilitating access to advanced AI capabilities for developers, researchers, and AI enthusiasts without requiring an internet connection.
LM Studio
LM Studio is a local large language model (LLM) platform that enables users to run and download powerful AI language models like LLaMa, MPT, and Gemma directly on their own computers. This platform supports Mac, Windows, and Linux operating systems, providing flexibility to users across different devices. LM Studio focuses on privacy and control by allowing users to work with AI models locally without relying on cloud-based services, ensuring data stays on the user’s device. It offers an easy-to-install interface with step-by-step guidance for setup, facilitating access to advanced AI capabilities for developers, researchers, and AI enthusiasts without requiring an internet connection.
Snowflake - Arctic
Snowflake's Arctic is a family of open-source large language models optimized for enterprise workloads, featuring a unique dense-MoE hybrid architecture that delivers top-tier performance in SQL generation, code tasks, and instruction following at a fraction of comparable model development costs. Released under Apache 2.0 license with fully ungated access to weights, code, open data recipes, and research insights, it excels in complex business scenarios while remaining capable across general tasks. Enterprises can fine-tune or deploy using popular frameworks like LoRA, TRT-LLM, and vLLM, with detailed training and inference cookbooks available. The models lead benchmarks for enterprise intelligence, balancing expert efficiency for fast inference and broad applicability without restrictive gates or proprietary limits.
Snowflake - Arctic
Snowflake's Arctic is a family of open-source large language models optimized for enterprise workloads, featuring a unique dense-MoE hybrid architecture that delivers top-tier performance in SQL generation, code tasks, and instruction following at a fraction of comparable model development costs. Released under Apache 2.0 license with fully ungated access to weights, code, open data recipes, and research insights, it excels in complex business scenarios while remaining capable across general tasks. Enterprises can fine-tune or deploy using popular frameworks like LoRA, TRT-LLM, and vLLM, with detailed training and inference cookbooks available. The models lead benchmarks for enterprise intelligence, balancing expert efficiency for fast inference and broad applicability without restrictive gates or proprietary limits.
Snowflake - Arctic
Snowflake's Arctic is a family of open-source large language models optimized for enterprise workloads, featuring a unique dense-MoE hybrid architecture that delivers top-tier performance in SQL generation, code tasks, and instruction following at a fraction of comparable model development costs. Released under Apache 2.0 license with fully ungated access to weights, code, open data recipes, and research insights, it excels in complex business scenarios while remaining capable across general tasks. Enterprises can fine-tune or deploy using popular frameworks like LoRA, TRT-LLM, and vLLM, with detailed training and inference cookbooks available. The models lead benchmarks for enterprise intelligence, balancing expert efficiency for fast inference and broad applicability without restrictive gates or proprietary limits.

FastRouter.ai
FastRouter.ai serves as a unified API gateway for large language models, simplifying access to over 100 LLMs from providers like OpenAI, Anthropic, Google, Meta, and more through a single OpenAI-compatible endpoint. Developers and enterprises route requests intelligently based on speed, cost, reliability, and performance, with automatic failover, real-time analytics, and no transaction fees. Key features include multimodal support for text, images, video, embeddings, web search integration, custom model lists, project governance with budgets and permissions, a model playground for comparisons, and seamless IDE integrations like Cursor and Cline. It handles high-scale workloads with superior latency and uptime.
FastRouter.ai
FastRouter.ai serves as a unified API gateway for large language models, simplifying access to over 100 LLMs from providers like OpenAI, Anthropic, Google, Meta, and more through a single OpenAI-compatible endpoint. Developers and enterprises route requests intelligently based on speed, cost, reliability, and performance, with automatic failover, real-time analytics, and no transaction fees. Key features include multimodal support for text, images, video, embeddings, web search integration, custom model lists, project governance with budgets and permissions, a model playground for comparisons, and seamless IDE integrations like Cursor and Cline. It handles high-scale workloads with superior latency and uptime.
FastRouter.ai
FastRouter.ai serves as a unified API gateway for large language models, simplifying access to over 100 LLMs from providers like OpenAI, Anthropic, Google, Meta, and more through a single OpenAI-compatible endpoint. Developers and enterprises route requests intelligently based on speed, cost, reliability, and performance, with automatic failover, real-time analytics, and no transaction fees. Key features include multimodal support for text, images, video, embeddings, web search integration, custom model lists, project governance with budgets and permissions, a model playground for comparisons, and seamless IDE integrations like Cursor and Cline. It handles high-scale workloads with superior latency and uptime.
Editorial Note
This page was researched and written by the ATB Editorial Team. Our team researches each AI tool by reviewing its official website, testing features, exploring real use cases, and considering user feedback. Every page is fact-checked and regularly updated to ensure the information stays accurate, neutral, and useful for our readers.
If you have any suggestions or questions, email us at hello@aitoolbook.ai