
- Japanese Enterprises: Deploy enterprise-grade generative AI optimized for business processes and local language needs.
- Industry Solution Developers: Customize the model for finance, legal, healthcare, and manufacturing workflows.
- Strategic IT & AI Teams: Achieve cost-effective, secure AI with top accuracy and business-relevant outputs.
- Global Firms Expanding to Japan: Integrate a high-performance Japanese LLM with proven architecture and support.
- R&D and Innovation Labs: Foster new, industry-specific AI use cases with flexible fine-tuning and best practices.
How to Use Syn?
- Deploy via AWS Marketplace: Launch secure, enterprise-grade applications tailored to business needs.
- Customize with Industry Data: Rapidly fine-tune Syn for unique sector or workflow requirements.
- Integrate into Existing Systems: Use straightforward APIs and deployment options for seamless adoption.
- Scale with Enterprise Support: Benefit from Upstage’s and Karakuri’s proven implementation, consulting, and ongoing updates.
- Designed for Japanese Enterprise: High alignment with local language, regulations, and business process needs.
- Best-in-Class Accuracy & Safety: Top-ranked under 14B models on Nejumi with superior reliability for real business usage.
- Cost-Optimized Performance: Delivers enterprise results with significantly lower infrastructure and training costs.
- Fast, Flexible Fine-Tuning: Rapid customization and adaptation for industry-specific requirements.
- Secure, Enterprise-Level Deployment: Meets strict security standards, available on AWS Marketplace, and designed for flexible integration.
- Outstanding accuracy and natural Japanese output for real business tasks.
- Lightweight, efficient architecture based on proven Solar Mini model.
- Flexible deployment with cost, speed, and security advantages.
- Designed for industry-specific fine-tuning and rapid adoption.
- Primarily focused on Japanese language and enterprise—less suitable for general-purpose or global LLM use.
- Requires careful customization for the most effective sector applications.
- Some advanced features and deployments may only be available through AWS or enterprise channels.
- Documentation and community outside Japan may be more limited.

Developers
Custom
Public models (See detailed pricing)
REST API
Public cloud
Help center
Enterprise
Custom
All public models
Custom LLM and RAG
Custom key information extraction
Custom document classification
REST API
Custom integrations
Serverless (API)
Private cloud
On-premises
Upstage Fine-tuning Studio
Upstage Labeling Studio
Personal information masking
Usage and resource monitoring
SSO
24/7 priority support
99% uptime SLA
Dedicated success manager
Proud of the love you're getting? Show off your AI Toolbook reviews—then invite more fans to share the love and build your credibility.
Add an AI Toolbook badge to your site—an easy way to drive followers, showcase updates, and collect reviews. It's like a mini 24/7 billboard for your AI.
Reviews
Rating Distribution
Average score
Popular Mention
FAQs
Similar AI Tools
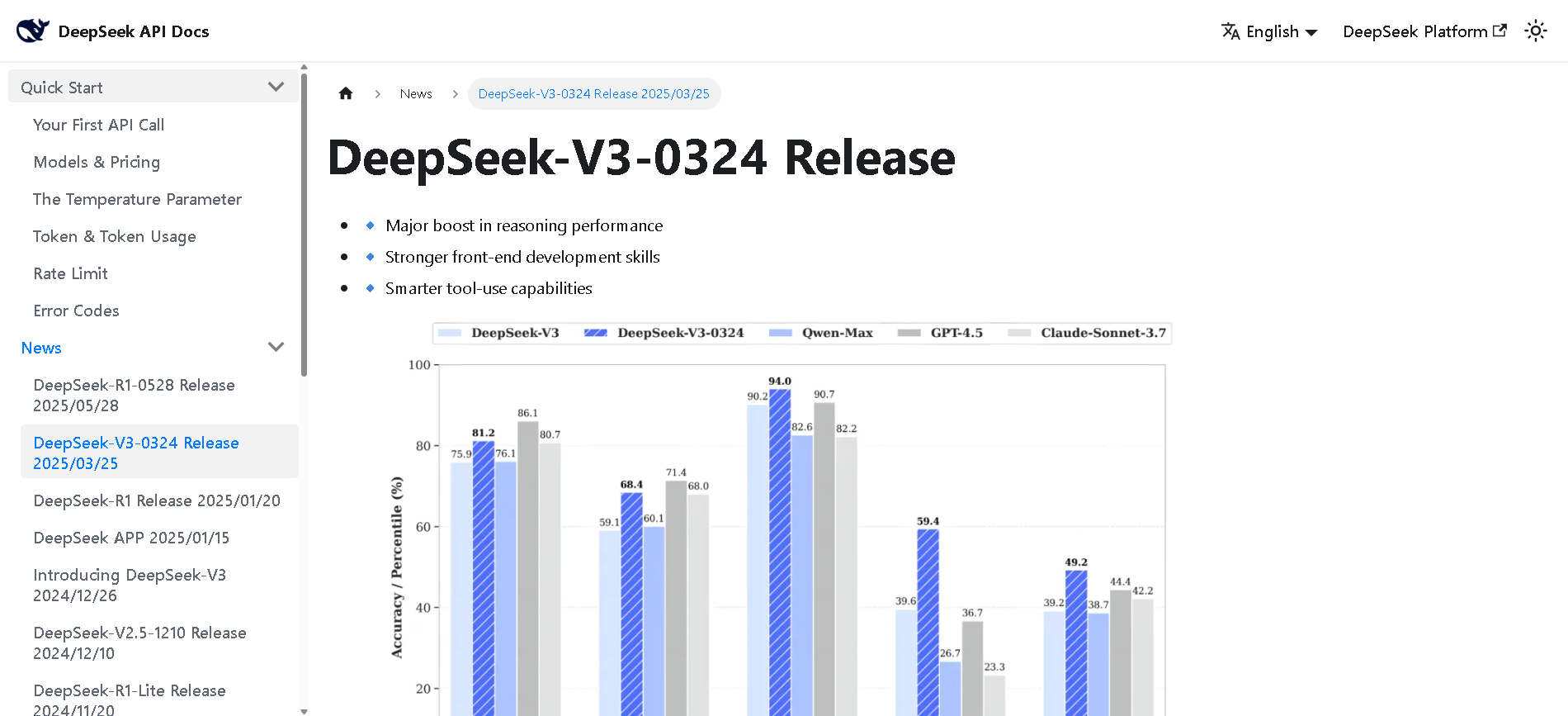
DeepSeek-V3-0324
DeepSeek V3 (0324) is the latest open-source Mixture-of-Experts (MoE) language model from DeepSeek, featuring 671B parameters (37B active per token). Released in March 2025 under the MIT license, it builds on DeepSeek V3 with major enhancements in reasoning, coding, front-end generation, and Chinese proficiency. It maintains cost-efficiency and function-calling support.
DeepSeek-V3-0324
DeepSeek V3 (0324) is the latest open-source Mixture-of-Experts (MoE) language model from DeepSeek, featuring 671B parameters (37B active per token). Released in March 2025 under the MIT license, it builds on DeepSeek V3 with major enhancements in reasoning, coding, front-end generation, and Chinese proficiency. It maintains cost-efficiency and function-calling support.
DeepSeek-V3-0324
DeepSeek V3 (0324) is the latest open-source Mixture-of-Experts (MoE) language model from DeepSeek, featuring 671B parameters (37B active per token). Released in March 2025 under the MIT license, it builds on DeepSeek V3 with major enhancements in reasoning, coding, front-end generation, and Chinese proficiency. It maintains cost-efficiency and function-calling support.

DeepSeek-V2
DeepSeek V2 is an open-source, Mixture‑of‑Experts (MoE) language model developed by DeepSeek-AI, released in May 2024. It features a massive 236 B total parameters with approximately 21 B activated per token, supports up to 128 K token context, and adopts innovative MLA (Multi‑head Latent Attention) and sparse expert routing. DeepSeek V2 delivers top-tier performance on benchmarks while cutting training and inference costs significantly.
DeepSeek-V2
DeepSeek V2 is an open-source, Mixture‑of‑Experts (MoE) language model developed by DeepSeek-AI, released in May 2024. It features a massive 236 B total parameters with approximately 21 B activated per token, supports up to 128 K token context, and adopts innovative MLA (Multi‑head Latent Attention) and sparse expert routing. DeepSeek V2 delivers top-tier performance on benchmarks while cutting training and inference costs significantly.
DeepSeek-V2
DeepSeek V2 is an open-source, Mixture‑of‑Experts (MoE) language model developed by DeepSeek-AI, released in May 2024. It features a massive 236 B total parameters with approximately 21 B activated per token, supports up to 128 K token context, and adopts innovative MLA (Multi‑head Latent Attention) and sparse expert routing. DeepSeek V2 delivers top-tier performance on benchmarks while cutting training and inference costs significantly.

Meta Llama 3.3
Llama 3.3 is Meta’s instruction-tuned, text-only large language model released on December 6, 2024, available in a 70B-parameter size. It matches the performance of much larger models using significantly fewer parameters, is multilingual across eight key languages, and supports a massive 128,000-token context window—ideal for handling long-form documents, codebases, and detailed reasoning tasks.
Meta Llama 3.3
Llama 3.3 is Meta’s instruction-tuned, text-only large language model released on December 6, 2024, available in a 70B-parameter size. It matches the performance of much larger models using significantly fewer parameters, is multilingual across eight key languages, and supports a massive 128,000-token context window—ideal for handling long-form documents, codebases, and detailed reasoning tasks.
Meta Llama 3.3
Llama 3.3 is Meta’s instruction-tuned, text-only large language model released on December 6, 2024, available in a 70B-parameter size. It matches the performance of much larger models using significantly fewer parameters, is multilingual across eight key languages, and supports a massive 128,000-token context window—ideal for handling long-form documents, codebases, and detailed reasoning tasks.

DeepSeek-R1-0528
DeepSeek R1 0528 is the May 28, 2025 update to DeepSeek’s flagship reasoning model. It brings significantly enhanced benchmark performance, deeper chain-of-thought reasoning (now using ~23K tokens per problem), reduced hallucinations, and support for JSON output, function calling, multi-round chat, and context caching.
DeepSeek-R1-0528
DeepSeek R1 0528 is the May 28, 2025 update to DeepSeek’s flagship reasoning model. It brings significantly enhanced benchmark performance, deeper chain-of-thought reasoning (now using ~23K tokens per problem), reduced hallucinations, and support for JSON output, function calling, multi-round chat, and context caching.
DeepSeek-R1-0528
DeepSeek R1 0528 is the May 28, 2025 update to DeepSeek’s flagship reasoning model. It brings significantly enhanced benchmark performance, deeper chain-of-thought reasoning (now using ~23K tokens per problem), reduced hallucinations, and support for JSON output, function calling, multi-round chat, and context caching.


Odia Gen AI
OdiaGenAI is a collaborative open-source initiative launched in 2023 to develop generative AI and LLM technologies tailored for Odia—a low-resource Indic language—and other regional languages. Led by Odia technologists and hosted under Odisha AI, it focuses on building pretrained, fine-tuned, and instruction-following models, datasets, and tools to empower areas like education, governance, agriculture, tourism, health, and industry.
Odia Gen AI
OdiaGenAI is a collaborative open-source initiative launched in 2023 to develop generative AI and LLM technologies tailored for Odia—a low-resource Indic language—and other regional languages. Led by Odia technologists and hosted under Odisha AI, it focuses on building pretrained, fine-tuned, and instruction-following models, datasets, and tools to empower areas like education, governance, agriculture, tourism, health, and industry.
Odia Gen AI
OdiaGenAI is a collaborative open-source initiative launched in 2023 to develop generative AI and LLM technologies tailored for Odia—a low-resource Indic language—and other regional languages. Led by Odia technologists and hosted under Odisha AI, it focuses on building pretrained, fine-tuned, and instruction-following models, datasets, and tools to empower areas like education, governance, agriculture, tourism, health, and industry.

Mistral Large 2
Mistral Large 2 is the second-generation flagship model from Mistral AI, released in July 2024. Also referenced as mistral-large-2407, it’s a 123 B-parameter dense LLM with a 128 K-token context window, supporting dozens of languages and 80+ coding languages. It excels in reasoning, code generation, mathematics, instruction-following, and function calling—designed for high throughput on single-node setups.
Mistral Large 2
Mistral Large 2 is the second-generation flagship model from Mistral AI, released in July 2024. Also referenced as mistral-large-2407, it’s a 123 B-parameter dense LLM with a 128 K-token context window, supporting dozens of languages and 80+ coding languages. It excels in reasoning, code generation, mathematics, instruction-following, and function calling—designed for high throughput on single-node setups.
Mistral Large 2
Mistral Large 2 is the second-generation flagship model from Mistral AI, released in July 2024. Also referenced as mistral-large-2407, it’s a 123 B-parameter dense LLM with a 128 K-token context window, supporting dozens of languages and 80+ coding languages. It excels in reasoning, code generation, mathematics, instruction-following, and function calling—designed for high throughput on single-node setups.
Mistral Nemotron
Mistral Nemotron is a preview large language model, jointly developed by Mistral AI and NVIDIA, released on June 11, 2025. Optimized by NVIDIA for inference using TensorRT-LLM and vLLM, it supports a massive 128K-token context window and is built for agentic workflows—excelling in instruction-following, function calling, and code generation—while delivering state-of-the-art performance across reasoning, math, coding, and multilingual benchmarks.
Mistral Nemotron
Mistral Nemotron is a preview large language model, jointly developed by Mistral AI and NVIDIA, released on June 11, 2025. Optimized by NVIDIA for inference using TensorRT-LLM and vLLM, it supports a massive 128K-token context window and is built for agentic workflows—excelling in instruction-following, function calling, and code generation—while delivering state-of-the-art performance across reasoning, math, coding, and multilingual benchmarks.
Mistral Nemotron
Mistral Nemotron is a preview large language model, jointly developed by Mistral AI and NVIDIA, released on June 11, 2025. Optimized by NVIDIA for inference using TensorRT-LLM and vLLM, it supports a massive 128K-token context window and is built for agentic workflows—excelling in instruction-following, function calling, and code generation—while delivering state-of-the-art performance across reasoning, math, coding, and multilingual benchmarks.
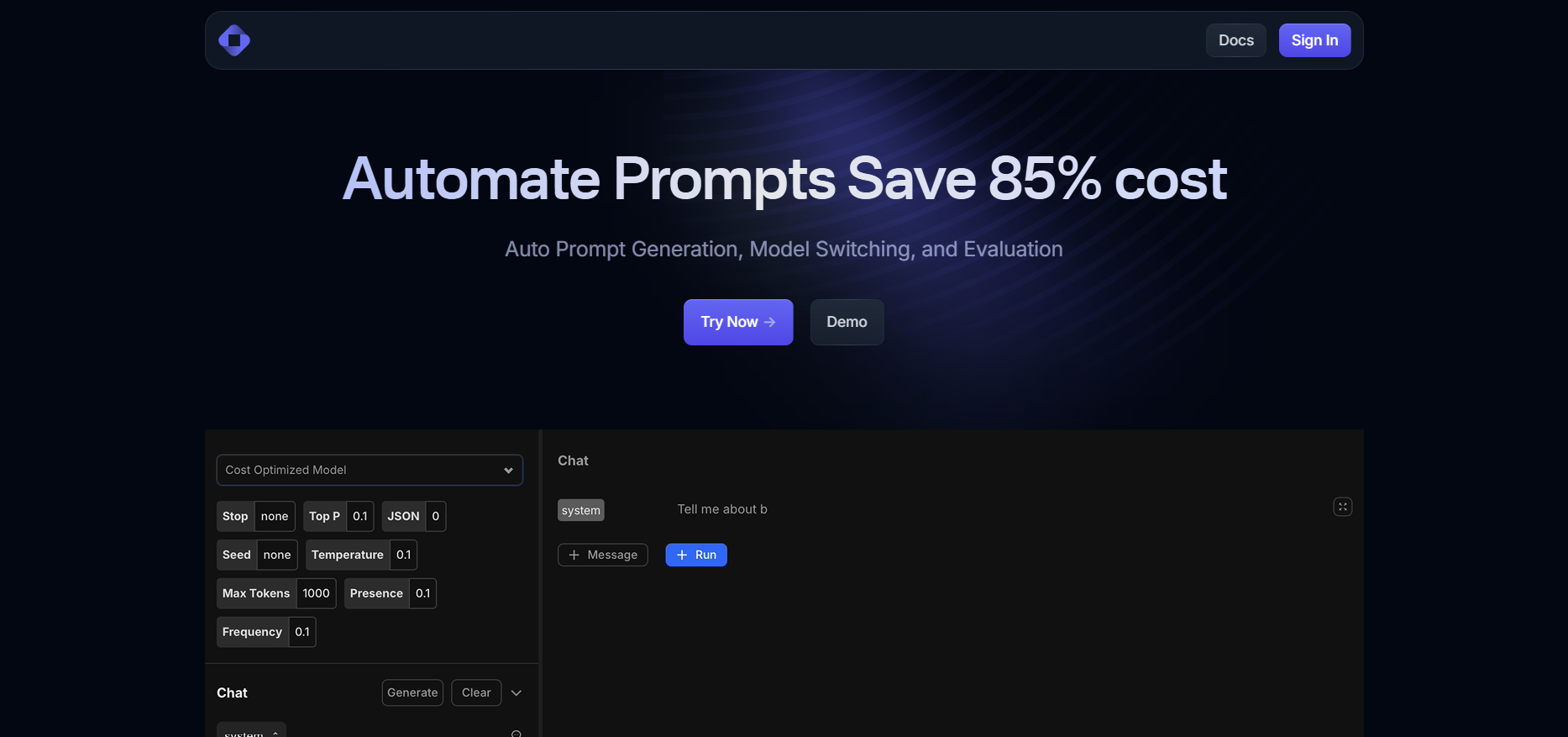
TrainKore
Trainkore is a versatile AI orchestration platform that automates prompt generation, model selection, and cost optimization across large language models (LLMs). The Model Router intelligently routes prompt requests to the best-priced or highest-performing model, achieving up to 85% cost savings. Users benefit from an auto-prompt generation playground, advanced settings, and seamless control—all through an intuitive UI. Ideal for teams managing multiple AI providers, Trainkore dramatically simplifies LLM workflows while improving efficiency and oversight.
TrainKore
Trainkore is a versatile AI orchestration platform that automates prompt generation, model selection, and cost optimization across large language models (LLMs). The Model Router intelligently routes prompt requests to the best-priced or highest-performing model, achieving up to 85% cost savings. Users benefit from an auto-prompt generation playground, advanced settings, and seamless control—all through an intuitive UI. Ideal for teams managing multiple AI providers, Trainkore dramatically simplifies LLM workflows while improving efficiency and oversight.
TrainKore
Trainkore is a versatile AI orchestration platform that automates prompt generation, model selection, and cost optimization across large language models (LLMs). The Model Router intelligently routes prompt requests to the best-priced or highest-performing model, achieving up to 85% cost savings. Users benefit from an auto-prompt generation playground, advanced settings, and seamless control—all through an intuitive UI. Ideal for teams managing multiple AI providers, Trainkore dramatically simplifies LLM workflows while improving efficiency and oversight.
Grok 4
Grok 4 is the latest and most intelligent AI model developed by xAI, designed for expert-level reasoning and real-time knowledge integration. It combines large-scale reinforcement learning with native tool use, including code interpretation, web browsing, and advanced search capabilities, to provide highly accurate and up-to-date responses. Grok 4 excels across diverse domains such as math, coding, science, and complex reasoning, supporting multimodal inputs like text and vision. With its massive 256,000-token context window and advanced toolset, Grok 4 is built to push the boundaries of AI intelligence and practical utility for both developers and enterprises.
Grok 4
Grok 4 is the latest and most intelligent AI model developed by xAI, designed for expert-level reasoning and real-time knowledge integration. It combines large-scale reinforcement learning with native tool use, including code interpretation, web browsing, and advanced search capabilities, to provide highly accurate and up-to-date responses. Grok 4 excels across diverse domains such as math, coding, science, and complex reasoning, supporting multimodal inputs like text and vision. With its massive 256,000-token context window and advanced toolset, Grok 4 is built to push the boundaries of AI intelligence and practical utility for both developers and enterprises.
Grok 4
Grok 4 is the latest and most intelligent AI model developed by xAI, designed for expert-level reasoning and real-time knowledge integration. It combines large-scale reinforcement learning with native tool use, including code interpretation, web browsing, and advanced search capabilities, to provide highly accurate and up-to-date responses. Grok 4 excels across diverse domains such as math, coding, science, and complex reasoning, supporting multimodal inputs like text and vision. With its massive 256,000-token context window and advanced toolset, Grok 4 is built to push the boundaries of AI intelligence and practical utility for both developers and enterprises.
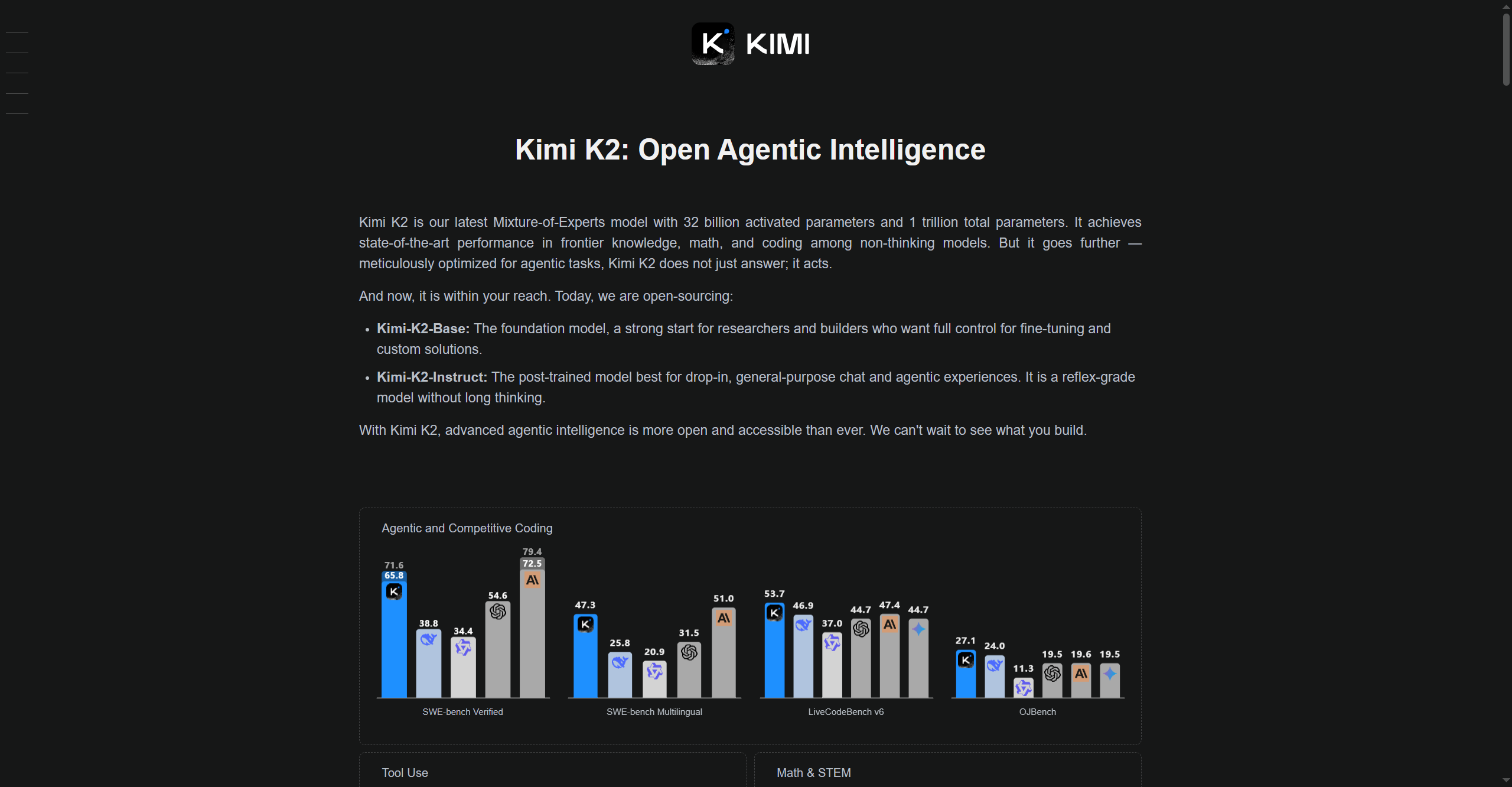

Kimi K2
Kimi-K2 is Moonshot AI’s advanced large language model (LLM) designed for high-speed reasoning, multi-modal understanding, and adaptable deployment across research, enterprise, and technical applications. Leveraging optimized architectures for efficiency and accuracy, Kimi-K2 excels in problem-solving, coding, knowledge retrieval, and interactive AI conversations. It is built to process complex real-world tasks, supporting both text and multi-modal inputs, and it provides customizable tools for experimentation and workflow automation.
Kimi K2
Kimi-K2 is Moonshot AI’s advanced large language model (LLM) designed for high-speed reasoning, multi-modal understanding, and adaptable deployment across research, enterprise, and technical applications. Leveraging optimized architectures for efficiency and accuracy, Kimi-K2 excels in problem-solving, coding, knowledge retrieval, and interactive AI conversations. It is built to process complex real-world tasks, supporting both text and multi-modal inputs, and it provides customizable tools for experimentation and workflow automation.
Kimi K2
Kimi-K2 is Moonshot AI’s advanced large language model (LLM) designed for high-speed reasoning, multi-modal understanding, and adaptable deployment across research, enterprise, and technical applications. Leveraging optimized architectures for efficiency and accuracy, Kimi-K2 excels in problem-solving, coding, knowledge retrieval, and interactive AI conversations. It is built to process complex real-world tasks, supporting both text and multi-modal inputs, and it provides customizable tools for experimentation and workflow automation.

Upstage Document Parse is an advanced AI-powered document processing tool designed to convert complex documents such as PDFs, scanned images, spreadsheets, and slides into structured, machine-readable text formats like HTML and Markdown. It excels at accurately recognizing and preserving complex layouts, tables, charts, and even handwritten elements with unmatched speed—processing over 100 pages in under a minute. The tool improves knowledge retrieval, enables quick decision-making through AI-driven summarization, and enhances accessibility by converting lengthy reports and legal documents into clean digital formats. Upstage Document Parse is scalable, easy to integrate via REST API or on-premises deployment, and certified for enterprise-grade security including SOC2 and ISO 27001.
Upstage Document Parse is an advanced AI-powered document processing tool designed to convert complex documents such as PDFs, scanned images, spreadsheets, and slides into structured, machine-readable text formats like HTML and Markdown. It excels at accurately recognizing and preserving complex layouts, tables, charts, and even handwritten elements with unmatched speed—processing over 100 pages in under a minute. The tool improves knowledge retrieval, enables quick decision-making through AI-driven summarization, and enhances accessibility by converting lengthy reports and legal documents into clean digital formats. Upstage Document Parse is scalable, easy to integrate via REST API or on-premises deployment, and certified for enterprise-grade security including SOC2 and ISO 27001.
Upstage Document Parse is an advanced AI-powered document processing tool designed to convert complex documents such as PDFs, scanned images, spreadsheets, and slides into structured, machine-readable text formats like HTML and Markdown. It excels at accurately recognizing and preserving complex layouts, tables, charts, and even handwritten elements with unmatched speed—processing over 100 pages in under a minute. The tool improves knowledge retrieval, enables quick decision-making through AI-driven summarization, and enhances accessibility by converting lengthy reports and legal documents into clean digital formats. Upstage Document Parse is scalable, easy to integrate via REST API or on-premises deployment, and certified for enterprise-grade security including SOC2 and ISO 27001.

Awan LLM
Awan LLM is a cost-effective, unlimited token large language model inference API platform designed for power users and developers. Unlike traditional API providers that charge per token, Awan LLM offers a monthly subscription model that enables users to send and receive unlimited tokens up to the model's context limit. It supports unrestricted use of LLM models without censorship or constraints. The platform is built on privately owned data centers and GPUs, allowing it to offer efficient and scalable AI services. Awan LLM supports numerous use cases including AI assistants, AI agents, roleplaying, data processing, code completion, and building AI-powered applications without worrying about token limits or costs.
Awan LLM
Awan LLM is a cost-effective, unlimited token large language model inference API platform designed for power users and developers. Unlike traditional API providers that charge per token, Awan LLM offers a monthly subscription model that enables users to send and receive unlimited tokens up to the model's context limit. It supports unrestricted use of LLM models without censorship or constraints. The platform is built on privately owned data centers and GPUs, allowing it to offer efficient and scalable AI services. Awan LLM supports numerous use cases including AI assistants, AI agents, roleplaying, data processing, code completion, and building AI-powered applications without worrying about token limits or costs.
Awan LLM
Awan LLM is a cost-effective, unlimited token large language model inference API platform designed for power users and developers. Unlike traditional API providers that charge per token, Awan LLM offers a monthly subscription model that enables users to send and receive unlimited tokens up to the model's context limit. It supports unrestricted use of LLM models without censorship or constraints. The platform is built on privately owned data centers and GPUs, allowing it to offer efficient and scalable AI services. Awan LLM supports numerous use cases including AI assistants, AI agents, roleplaying, data processing, code completion, and building AI-powered applications without worrying about token limits or costs.
Editorial Note
This page was researched and written by the ATB Editorial Team. Our team researches each AI tool by reviewing its official website, testing features, exploring real use cases, and considering user feedback. Every page is fact-checked and regularly updated to ensure the information stays accurate, neutral, and useful for our readers.
If you have any suggestions or questions, email us at hello@aitoolbook.ai