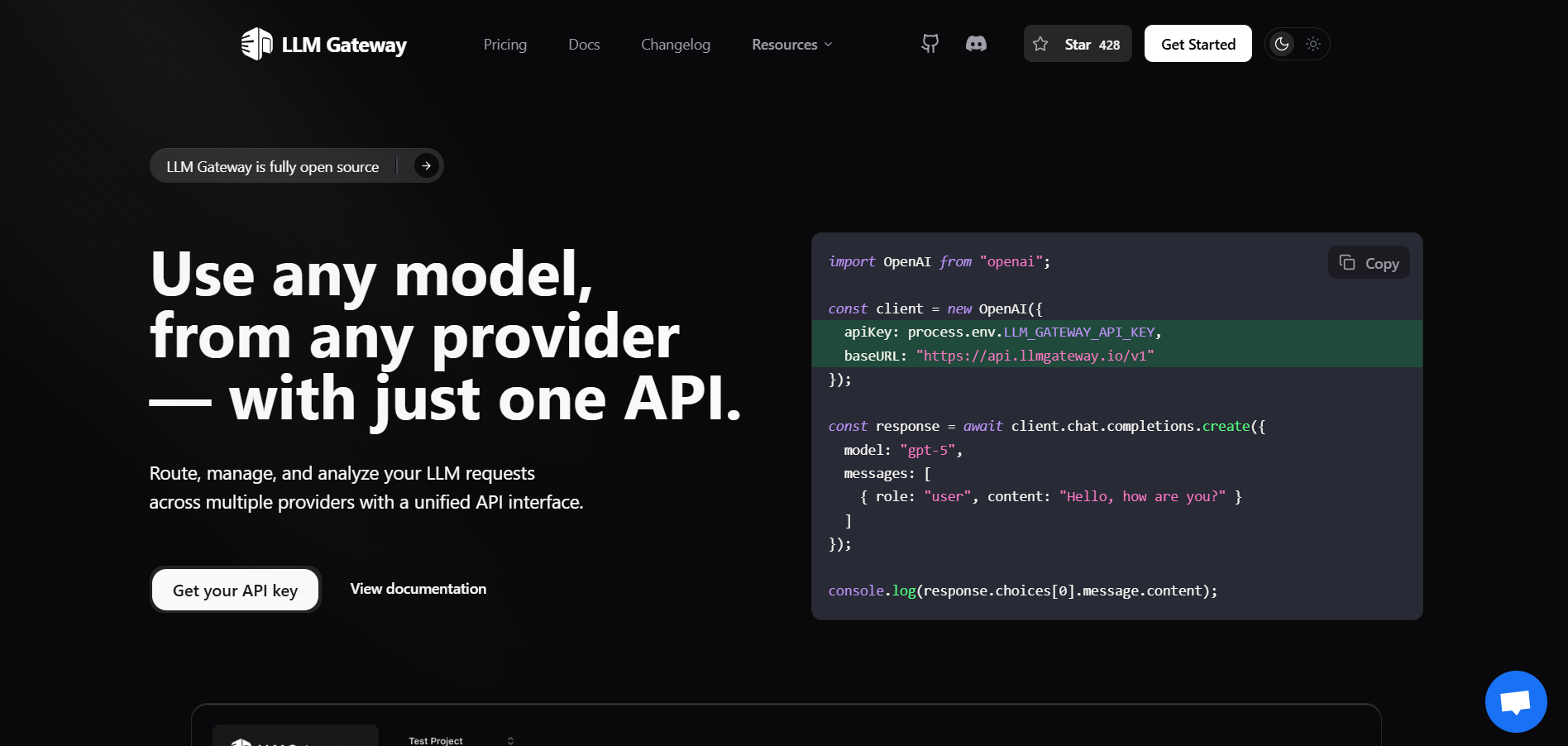
- Developers & AI Engineers: Integrate multiple LLM providers through a single API endpoint, reducing integration overhead.
- Teams Using Multiple LLM APIs: Manage provider keys, usage stats, and central analytics for seamless orchestration.
- Cost-Conscious Organizations: Track real-time token usage, latency, and expense across every LLM interaction.
- Operations & DevOps Teams: Self-host under an MIT license for full control, or opt for hosted plans with SLAs and support.
- Enterprise Users: Leverage analytics, advanced billing, uptime SLAs, and priority support through Pro and Enterprise plans.
How to Use It?
- Seamless Endpoint Swap: Simply point your API calls to LLM Gateway’s base URL; it’s drop-in compatible with OpenAI format.
- Choose Hosting Mode: Use the hosted service for simplicity, or deploy on your infrastructure for full governance.
- Observe Metrics: Utilize dashboards for real-time logging of performance, costs, errors, and response times.
- Fine-Tune Routing: Automatically route to cost-effective or fastest models, or specify providers like "anthropic/claude-3-5-sonnet".
- Upgrade for Features: Move to Pro for zero gateway fees, extended data retention, and analytics enhancements. Enterprise tiers add custom SLAs and integrations.
- One Unified API: Support for 30+ models across 8+ providers via a single, familiar interface.
- Rich Analytics by Design: Offers cost, performance, and usage breakdowns at request-level granularity.
- Flexible Deployment: Choose between self-hosting (free forever) or managed service—with the same core capabilities.
- Competitive Pricing: Pro plan allows usage of your own provider API keys with zero additional gateway fees.
- Enterprise Strength: Comes with SLAs, failover, load balancing, and support for mission-critical deployments.
- Drop-in replacement for existing LLM integrations
- Built-in visibility into cost, performance, and provider usage
- Flexible—works in both self-hosted and hosted modes
- Open-source backend ensures transparency and adaptability
- Enterprise-ready with scalable billing and support options
- Self-hosting requires DevOps expertise and infrastructure maintenance
- Advanced analytics and no-fee usage require Pro subscription
- Smart routing control may require manual configuration for nuanced workflows
- Documentation could be improved for edge-case or advanced enterprise use cases

Self Host
Free
- Host on your own infrastructure
Free
Free
- Perfect for trying out the platform
Pro
$ 50.00
- For professionals and growing teams
Enterprise
Custom Pricing.
- For large organizations with custom needs
Proud of the love you're getting? Show off your AI Toolbook reviews—then invite more fans to share the love and build your credibility.
Add an AI Toolbook badge to your site—an easy way to drive followers, showcase updates, and collect reviews. It's like a mini 24/7 billboard for your AI.
Reviews
Rating Distribution
Average score
Popular Mention
FAQs
Supports OpenAI, Anthropic, Google Vertex AI, Mistral, Groq, DeepSeek, and over 30 models across 8+ providers.
Yes—it’s MIT-licensed and open-source, allowing free self-hosting with unlimited usage.
Free self-hosting is costless. The hosted Pro plan (~$50/month) includes zero gateway fees using your own keys. Enterprise pricing is custom
LLM Gateway offers richer real-time analytics, self-hosting under open license, zero gateway fees in Pro, and enterprise-grade features.
Version 1.0 launched in May 2025 and quickly gained traction in developer and AI communities.
Similar AI Tools

GPT-4.1 Mini is a lightweight version of OpenAI’s advanced GPT-4.1 model, designed for efficiency, speed, and affordability without compromising much on performance. Tailored for developers and teams who need capable AI reasoning and natural language processing in smaller-scale or cost-sensitive applications, GPT-4.1 Mini brings the power of GPT-4.1 into a more accessible form factor. Perfect for chatbots, content suggestions, productivity tools, and streamlined AI experiences, this compact model still delivers impressive accuracy, fast responses, and a reliable understanding of nuanced prompts—all while using fewer resources.
GPT-4.1 Mini is a lightweight version of OpenAI’s advanced GPT-4.1 model, designed for efficiency, speed, and affordability without compromising much on performance. Tailored for developers and teams who need capable AI reasoning and natural language processing in smaller-scale or cost-sensitive applications, GPT-4.1 Mini brings the power of GPT-4.1 into a more accessible form factor. Perfect for chatbots, content suggestions, productivity tools, and streamlined AI experiences, this compact model still delivers impressive accuracy, fast responses, and a reliable understanding of nuanced prompts—all while using fewer resources.
GPT-4.1 Mini is a lightweight version of OpenAI’s advanced GPT-4.1 model, designed for efficiency, speed, and affordability without compromising much on performance. Tailored for developers and teams who need capable AI reasoning and natural language processing in smaller-scale or cost-sensitive applications, GPT-4.1 Mini brings the power of GPT-4.1 into a more accessible form factor. Perfect for chatbots, content suggestions, productivity tools, and streamlined AI experiences, this compact model still delivers impressive accuracy, fast responses, and a reliable understanding of nuanced prompts—all while using fewer resources.


Odia Gen AI
OdiaGenAI is a collaborative open-source initiative launched in 2023 to develop generative AI and LLM technologies tailored for Odia—a low-resource Indic language—and other regional languages. Led by Odia technologists and hosted under Odisha AI, it focuses on building pretrained, fine-tuned, and instruction-following models, datasets, and tools to empower areas like education, governance, agriculture, tourism, health, and industry.
Odia Gen AI
OdiaGenAI is a collaborative open-source initiative launched in 2023 to develop generative AI and LLM technologies tailored for Odia—a low-resource Indic language—and other regional languages. Led by Odia technologists and hosted under Odisha AI, it focuses on building pretrained, fine-tuned, and instruction-following models, datasets, and tools to empower areas like education, governance, agriculture, tourism, health, and industry.
Odia Gen AI
OdiaGenAI is a collaborative open-source initiative launched in 2023 to develop generative AI and LLM technologies tailored for Odia—a low-resource Indic language—and other regional languages. Led by Odia technologists and hosted under Odisha AI, it focuses on building pretrained, fine-tuned, and instruction-following models, datasets, and tools to empower areas like education, governance, agriculture, tourism, health, and industry.

Mistral Large 2
Mistral Large 2 is the second-generation flagship model from Mistral AI, released in July 2024. Also referenced as mistral-large-2407, it’s a 123 B-parameter dense LLM with a 128 K-token context window, supporting dozens of languages and 80+ coding languages. It excels in reasoning, code generation, mathematics, instruction-following, and function calling—designed for high throughput on single-node setups.
Mistral Large 2
Mistral Large 2 is the second-generation flagship model from Mistral AI, released in July 2024. Also referenced as mistral-large-2407, it’s a 123 B-parameter dense LLM with a 128 K-token context window, supporting dozens of languages and 80+ coding languages. It excels in reasoning, code generation, mathematics, instruction-following, and function calling—designed for high throughput on single-node setups.
Mistral Large 2
Mistral Large 2 is the second-generation flagship model from Mistral AI, released in July 2024. Also referenced as mistral-large-2407, it’s a 123 B-parameter dense LLM with a 128 K-token context window, supporting dozens of languages and 80+ coding languages. It excels in reasoning, code generation, mathematics, instruction-following, and function calling—designed for high throughput on single-node setups.
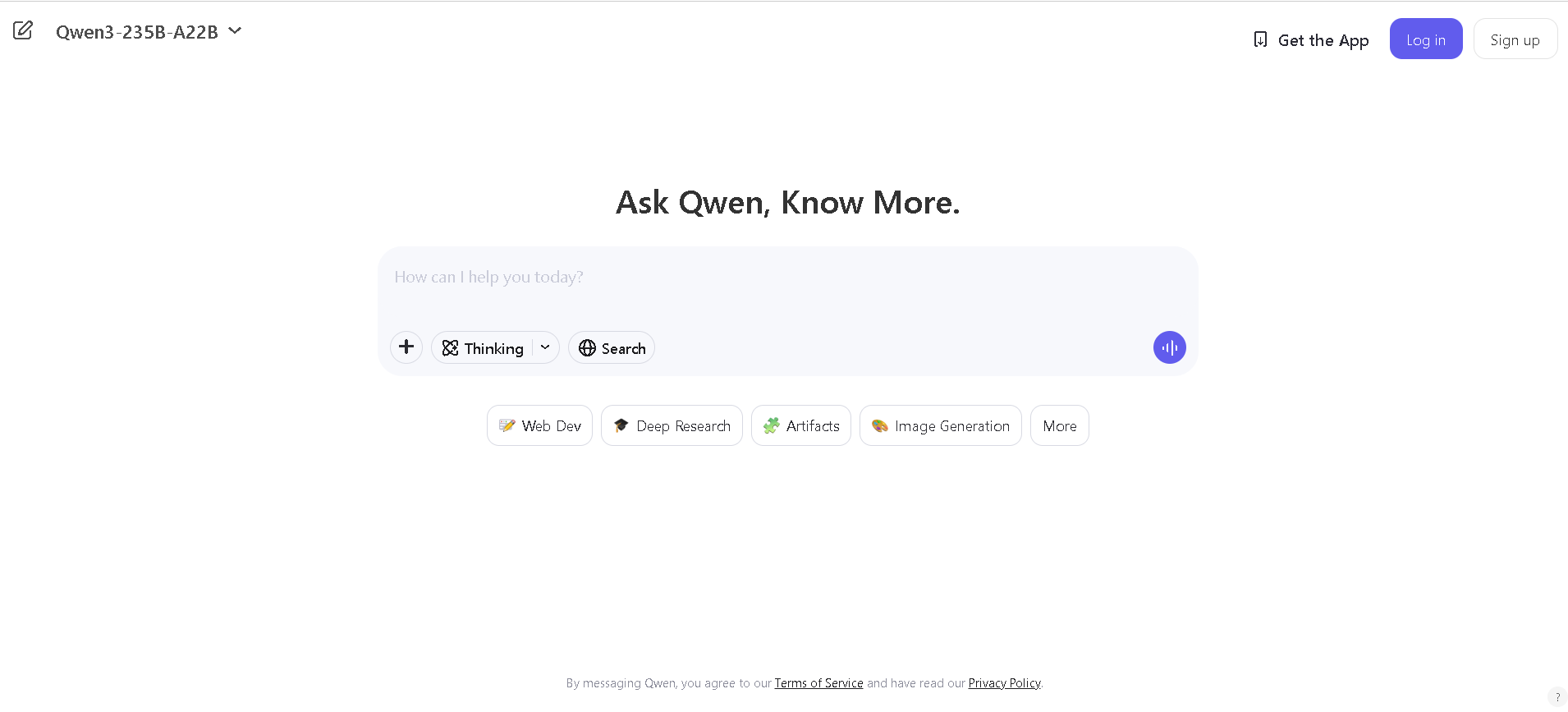
Qwen Chat
Qwen Chat is Alibaba Cloud’s conversational AI assistant built on the Qwen series (e.g., Qwen‑7B‑Chat, Qwen1.5‑7B‑Chat, Qwen‑VL, Qwen‑Audio, and Qwen2.5‑Omni). It supports text, vision, audio, and video understanding, plus image and document processing, web search integration, and image generation—all through a unified chat interface.
Qwen Chat
Qwen Chat is Alibaba Cloud’s conversational AI assistant built on the Qwen series (e.g., Qwen‑7B‑Chat, Qwen1.5‑7B‑Chat, Qwen‑VL, Qwen‑Audio, and Qwen2.5‑Omni). It supports text, vision, audio, and video understanding, plus image and document processing, web search integration, and image generation—all through a unified chat interface.
Qwen Chat
Qwen Chat is Alibaba Cloud’s conversational AI assistant built on the Qwen series (e.g., Qwen‑7B‑Chat, Qwen1.5‑7B‑Chat, Qwen‑VL, Qwen‑Audio, and Qwen2.5‑Omni). It supports text, vision, audio, and video understanding, plus image and document processing, web search integration, and image generation—all through a unified chat interface.
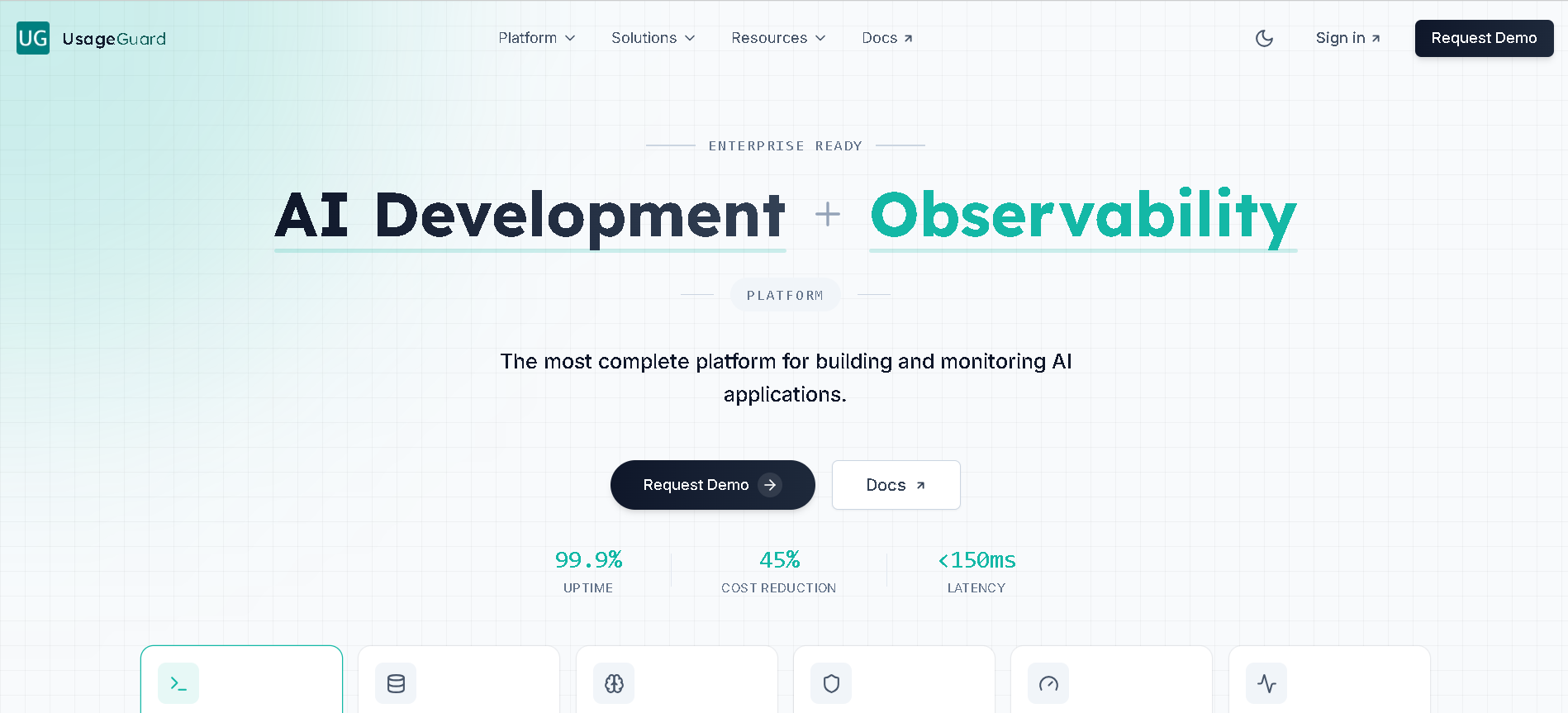
UsageGuard
UsageGuard is an AI infrastructure platform designed to help businesses build, deploy, and monitor AI applications with confidence. It acts as a proxy service for Large Language Model (LLM) API calls, providing a unified endpoint that offers a suite of enterprise-grade features. Its core mission is to empower developers and enterprises with robust solutions for AI security, cost control, usage tracking, and comprehensive observability.
UsageGuard
UsageGuard is an AI infrastructure platform designed to help businesses build, deploy, and monitor AI applications with confidence. It acts as a proxy service for Large Language Model (LLM) API calls, providing a unified endpoint that offers a suite of enterprise-grade features. Its core mission is to empower developers and enterprises with robust solutions for AI security, cost control, usage tracking, and comprehensive observability.
UsageGuard
UsageGuard is an AI infrastructure platform designed to help businesses build, deploy, and monitor AI applications with confidence. It acts as a proxy service for Large Language Model (LLM) API calls, providing a unified endpoint that offers a suite of enterprise-grade features. Its core mission is to empower developers and enterprises with robust solutions for AI security, cost control, usage tracking, and comprehensive observability.
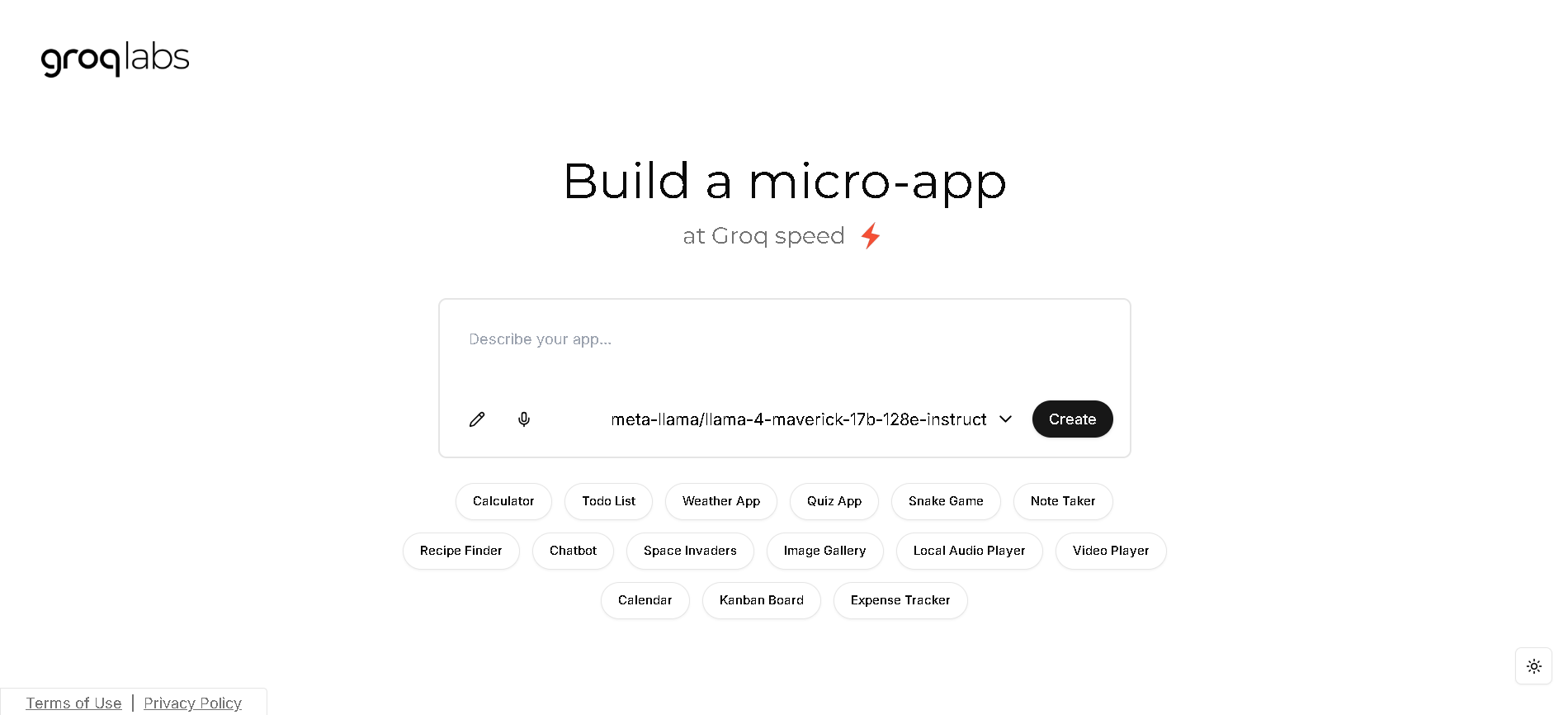
Groq APP Gen
Groq AppGen is an innovative, web-based tool that uses AI to generate and modify web applications in real-time. Powered by Groq's LLM API and the Llama 3.3 70B model, it allows users to create full-stack applications and components using simple, natural language queries. The platform's primary purpose is to dramatically accelerate the development process by generating code in milliseconds, providing an open-source solution for both developers and "no-code" users.
Groq APP Gen
Groq AppGen is an innovative, web-based tool that uses AI to generate and modify web applications in real-time. Powered by Groq's LLM API and the Llama 3.3 70B model, it allows users to create full-stack applications and components using simple, natural language queries. The platform's primary purpose is to dramatically accelerate the development process by generating code in milliseconds, providing an open-source solution for both developers and "no-code" users.
Groq APP Gen
Groq AppGen is an innovative, web-based tool that uses AI to generate and modify web applications in real-time. Powered by Groq's LLM API and the Llama 3.3 70B model, it allows users to create full-stack applications and components using simple, natural language queries. The platform's primary purpose is to dramatically accelerate the development process by generating code in milliseconds, providing an open-source solution for both developers and "no-code" users.
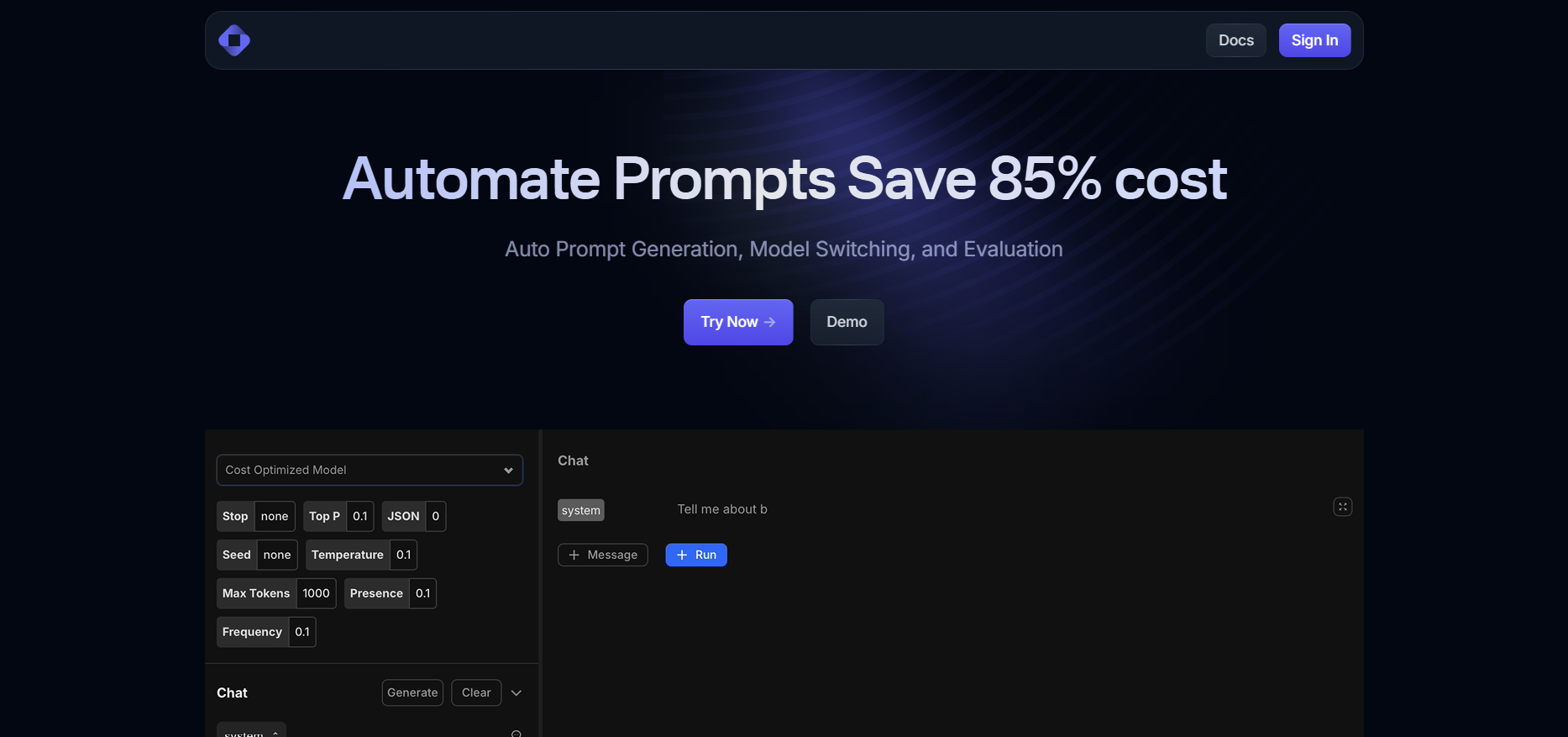
TrainKore
Trainkore is a versatile AI orchestration platform that automates prompt generation, model selection, and cost optimization across large language models (LLMs). The Model Router intelligently routes prompt requests to the best-priced or highest-performing model, achieving up to 85% cost savings. Users benefit from an auto-prompt generation playground, advanced settings, and seamless control—all through an intuitive UI. Ideal for teams managing multiple AI providers, Trainkore dramatically simplifies LLM workflows while improving efficiency and oversight.
TrainKore
Trainkore is a versatile AI orchestration platform that automates prompt generation, model selection, and cost optimization across large language models (LLMs). The Model Router intelligently routes prompt requests to the best-priced or highest-performing model, achieving up to 85% cost savings. Users benefit from an auto-prompt generation playground, advanced settings, and seamless control—all through an intuitive UI. Ideal for teams managing multiple AI providers, Trainkore dramatically simplifies LLM workflows while improving efficiency and oversight.
TrainKore
Trainkore is a versatile AI orchestration platform that automates prompt generation, model selection, and cost optimization across large language models (LLMs). The Model Router intelligently routes prompt requests to the best-priced or highest-performing model, achieving up to 85% cost savings. Users benefit from an auto-prompt generation playground, advanced settings, and seamless control—all through an intuitive UI. Ideal for teams managing multiple AI providers, Trainkore dramatically simplifies LLM workflows while improving efficiency and oversight.
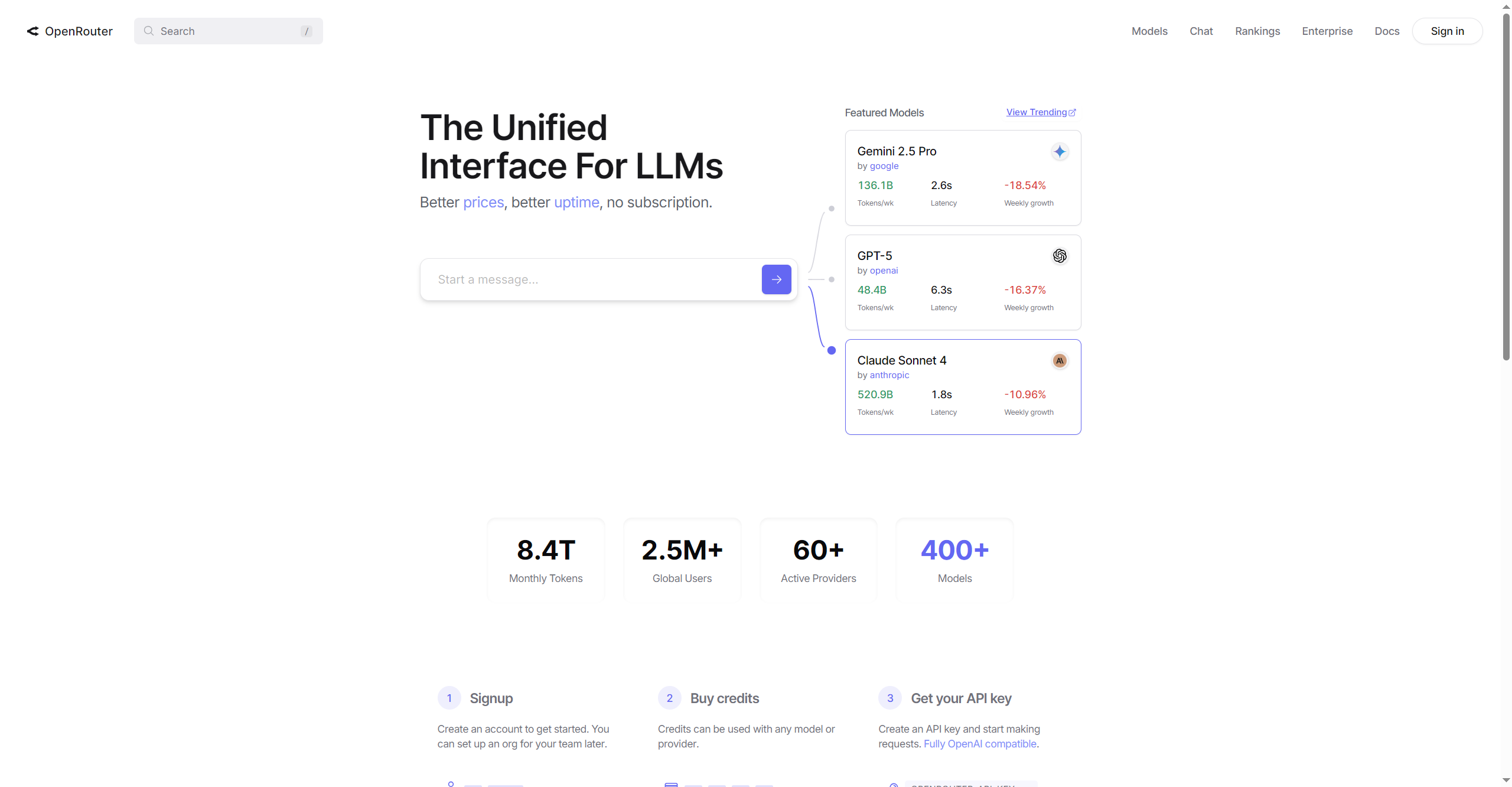

OpenRouter
OpenRouter is a unified platform designed to connect developers and organizations to leading AI models from over 60 providers using a single, streamlined interface. The platform boasts over 400 models and supports more than 2.5 million global users, letting teams access, manage, and scale large language model (LLM) workloads reliably and efficiently. With OpenAI-compatible APIs, dynamic provider fallback, fast edge network performance, and fine-grained data control, OpenRouter ensures both flexibility and security for advanced AI deployments and experimentation.
OpenRouter
OpenRouter is a unified platform designed to connect developers and organizations to leading AI models from over 60 providers using a single, streamlined interface. The platform boasts over 400 models and supports more than 2.5 million global users, letting teams access, manage, and scale large language model (LLM) workloads reliably and efficiently. With OpenAI-compatible APIs, dynamic provider fallback, fast edge network performance, and fine-grained data control, OpenRouter ensures both flexibility and security for advanced AI deployments and experimentation.
OpenRouter
OpenRouter is a unified platform designed to connect developers and organizations to leading AI models from over 60 providers using a single, streamlined interface. The platform boasts over 400 models and supports more than 2.5 million global users, letting teams access, manage, and scale large language model (LLM) workloads reliably and efficiently. With OpenAI-compatible APIs, dynamic provider fallback, fast edge network performance, and fine-grained data control, OpenRouter ensures both flexibility and security for advanced AI deployments and experimentation.
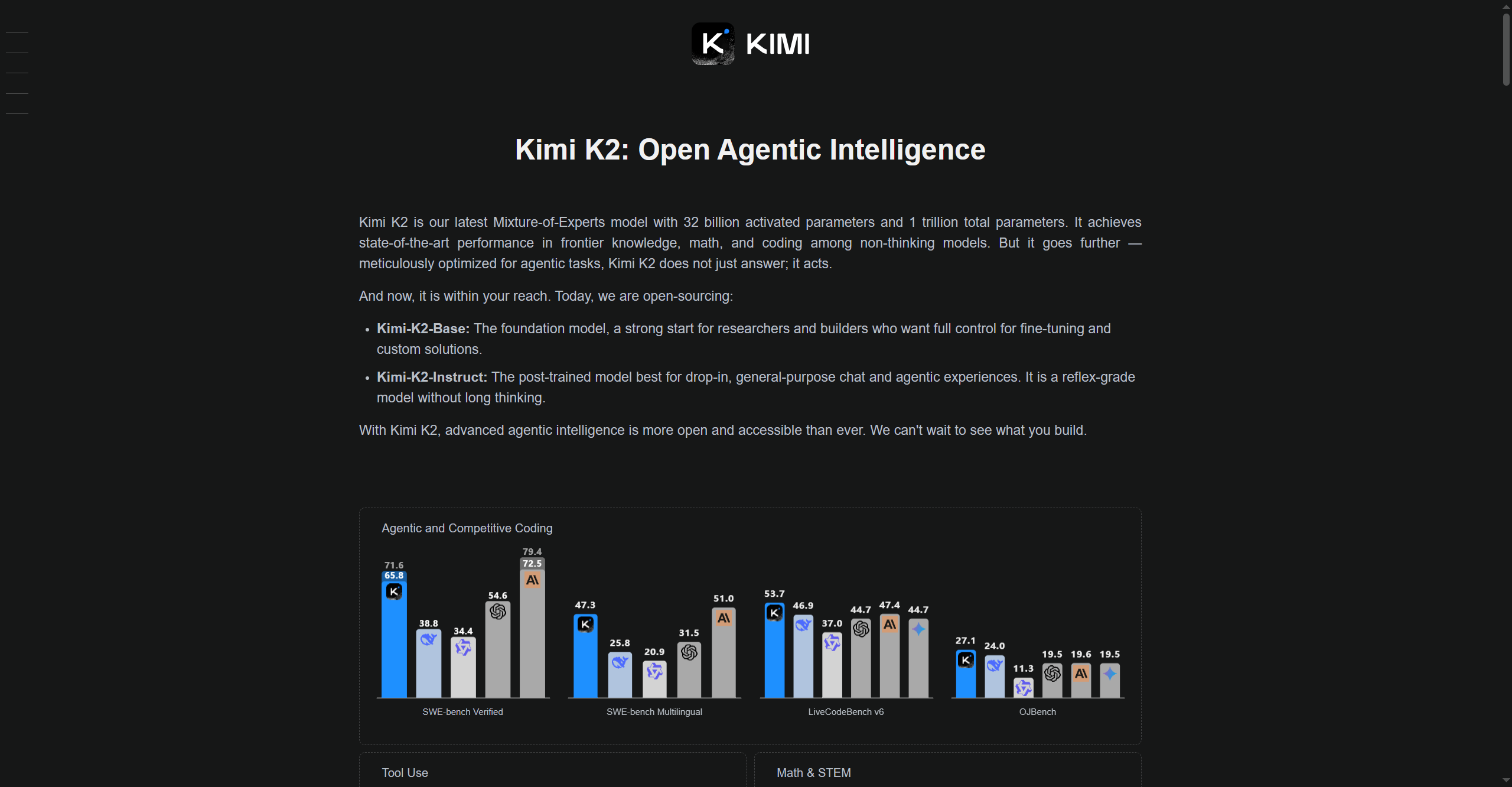

Kimi K2
Kimi-K2 is Moonshot AI’s advanced large language model (LLM) designed for high-speed reasoning, multi-modal understanding, and adaptable deployment across research, enterprise, and technical applications. Leveraging optimized architectures for efficiency and accuracy, Kimi-K2 excels in problem-solving, coding, knowledge retrieval, and interactive AI conversations. It is built to process complex real-world tasks, supporting both text and multi-modal inputs, and it provides customizable tools for experimentation and workflow automation.
Kimi K2
Kimi-K2 is Moonshot AI’s advanced large language model (LLM) designed for high-speed reasoning, multi-modal understanding, and adaptable deployment across research, enterprise, and technical applications. Leveraging optimized architectures for efficiency and accuracy, Kimi-K2 excels in problem-solving, coding, knowledge retrieval, and interactive AI conversations. It is built to process complex real-world tasks, supporting both text and multi-modal inputs, and it provides customizable tools for experimentation and workflow automation.
Kimi K2
Kimi-K2 is Moonshot AI’s advanced large language model (LLM) designed for high-speed reasoning, multi-modal understanding, and adaptable deployment across research, enterprise, and technical applications. Leveraging optimized architectures for efficiency and accuracy, Kimi-K2 excels in problem-solving, coding, knowledge retrieval, and interactive AI conversations. It is built to process complex real-world tasks, supporting both text and multi-modal inputs, and it provides customizable tools for experimentation and workflow automation.
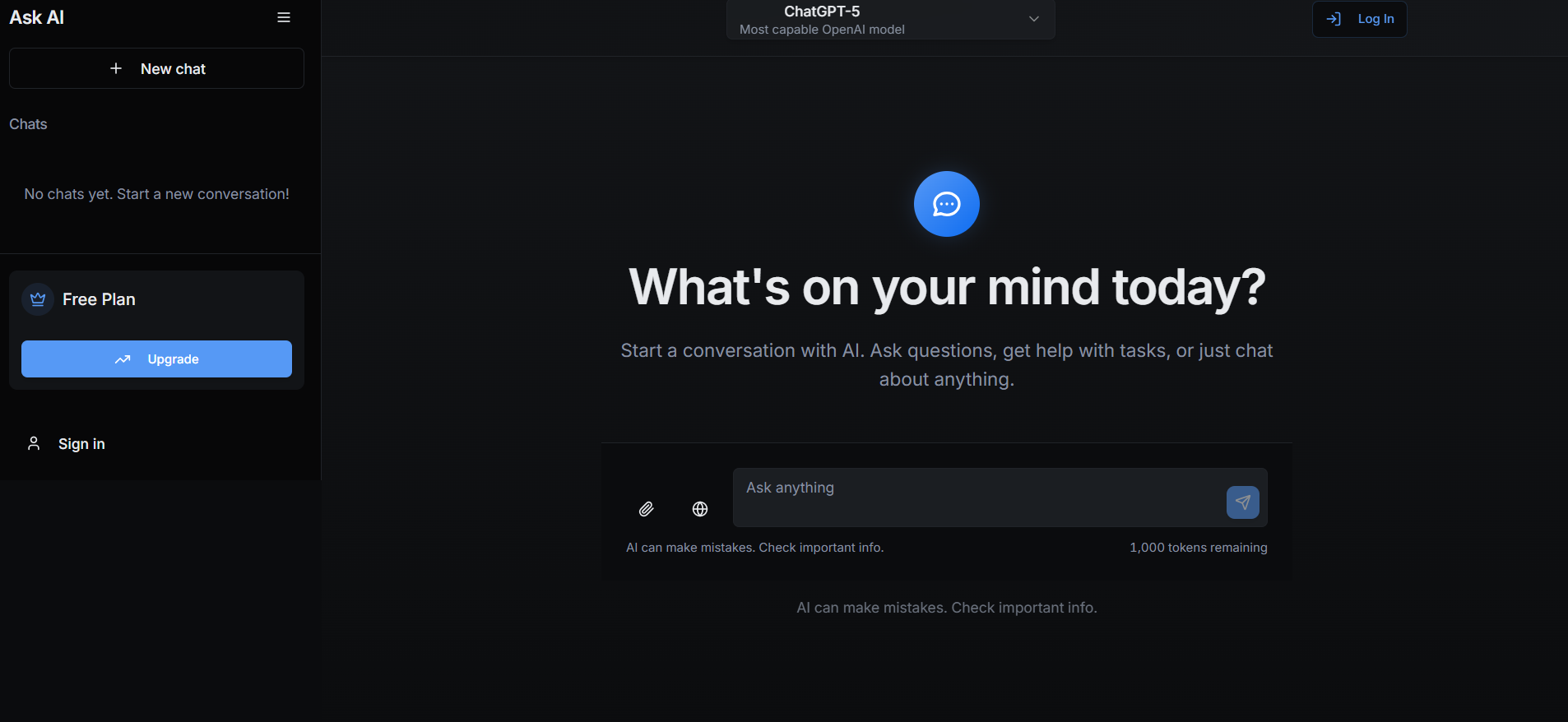
Ask Any Model
AskAnyModel is a unified AI interface that allows users to interact with multiple leading AI models — such as GPT, Claude, Gemini, and Mistral — from a single platform. It eliminates the need for multiple subscriptions and interfaces by bringing top AI models into one streamlined environment. Users can compare responses, analyze outputs, and select the best AI model for specific tasks like content creation, coding, data analysis, or research. AskAnyModel empowers individuals and teams to harness AI diversity efficiently, offering advanced tools for prompt testing, model benchmarking, and workflow integration.
Ask Any Model
AskAnyModel is a unified AI interface that allows users to interact with multiple leading AI models — such as GPT, Claude, Gemini, and Mistral — from a single platform. It eliminates the need for multiple subscriptions and interfaces by bringing top AI models into one streamlined environment. Users can compare responses, analyze outputs, and select the best AI model for specific tasks like content creation, coding, data analysis, or research. AskAnyModel empowers individuals and teams to harness AI diversity efficiently, offering advanced tools for prompt testing, model benchmarking, and workflow integration.
Ask Any Model
AskAnyModel is a unified AI interface that allows users to interact with multiple leading AI models — such as GPT, Claude, Gemini, and Mistral — from a single platform. It eliminates the need for multiple subscriptions and interfaces by bringing top AI models into one streamlined environment. Users can compare responses, analyze outputs, and select the best AI model for specific tasks like content creation, coding, data analysis, or research. AskAnyModel empowers individuals and teams to harness AI diversity efficiently, offering advanced tools for prompt testing, model benchmarking, and workflow integration.
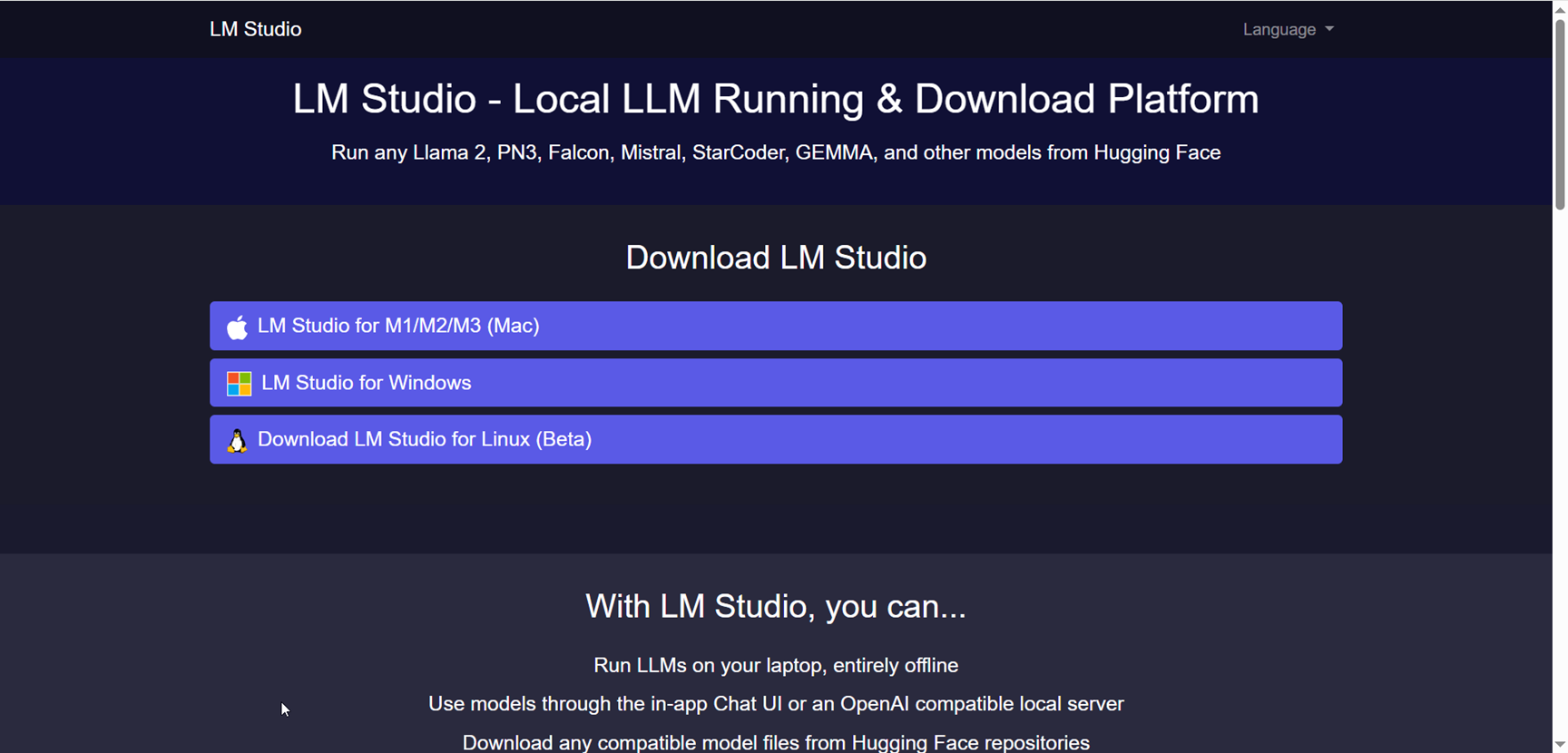
LM Studio
LM Studio is a local large language model (LLM) platform that enables users to run and download powerful AI language models like LLaMa, MPT, and Gemma directly on their own computers. This platform supports Mac, Windows, and Linux operating systems, providing flexibility to users across different devices. LM Studio focuses on privacy and control by allowing users to work with AI models locally without relying on cloud-based services, ensuring data stays on the user’s device. It offers an easy-to-install interface with step-by-step guidance for setup, facilitating access to advanced AI capabilities for developers, researchers, and AI enthusiasts without requiring an internet connection.
LM Studio
LM Studio is a local large language model (LLM) platform that enables users to run and download powerful AI language models like LLaMa, MPT, and Gemma directly on their own computers. This platform supports Mac, Windows, and Linux operating systems, providing flexibility to users across different devices. LM Studio focuses on privacy and control by allowing users to work with AI models locally without relying on cloud-based services, ensuring data stays on the user’s device. It offers an easy-to-install interface with step-by-step guidance for setup, facilitating access to advanced AI capabilities for developers, researchers, and AI enthusiasts without requiring an internet connection.
LM Studio
LM Studio is a local large language model (LLM) platform that enables users to run and download powerful AI language models like LLaMa, MPT, and Gemma directly on their own computers. This platform supports Mac, Windows, and Linux operating systems, providing flexibility to users across different devices. LM Studio focuses on privacy and control by allowing users to work with AI models locally without relying on cloud-based services, ensuring data stays on the user’s device. It offers an easy-to-install interface with step-by-step guidance for setup, facilitating access to advanced AI capabilities for developers, researchers, and AI enthusiasts without requiring an internet connection.
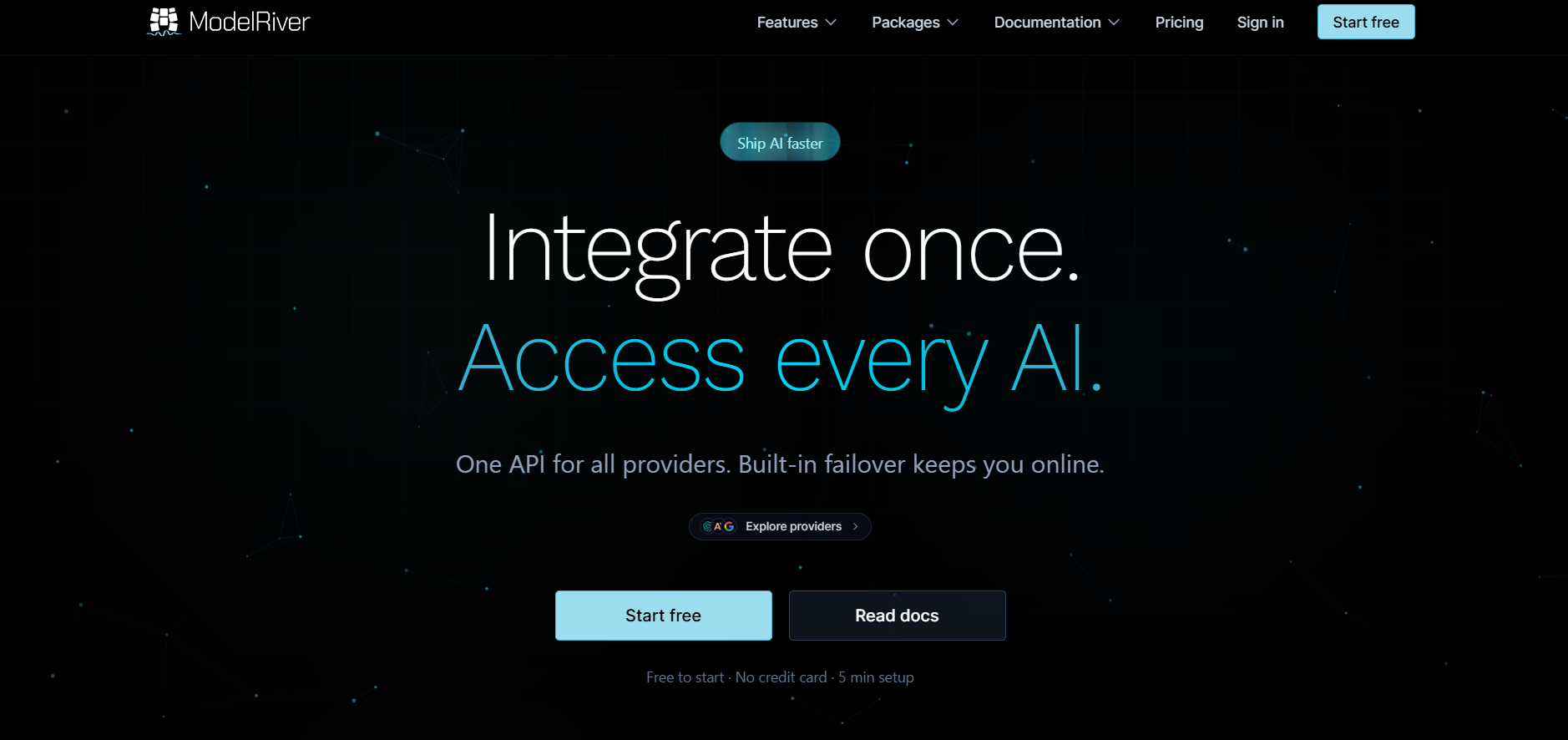
ModelRiver
ModelRiver is a unified AI integration platform that allows developers to access multiple AI providers through a single API. Instead of integrating each model separately, teams integrate once and gain access to a wide range of AI services. Built-in failover ensures applications remain online even if one provider experiences issues. ModelRiver is designed for reliability, scalability, and simplicity, making it ideal for production environments that depend on AI availability.
ModelRiver
ModelRiver is a unified AI integration platform that allows developers to access multiple AI providers through a single API. Instead of integrating each model separately, teams integrate once and gain access to a wide range of AI services. Built-in failover ensures applications remain online even if one provider experiences issues. ModelRiver is designed for reliability, scalability, and simplicity, making it ideal for production environments that depend on AI availability.
ModelRiver
ModelRiver is a unified AI integration platform that allows developers to access multiple AI providers through a single API. Instead of integrating each model separately, teams integrate once and gain access to a wide range of AI services. Built-in failover ensures applications remain online even if one provider experiences issues. ModelRiver is designed for reliability, scalability, and simplicity, making it ideal for production environments that depend on AI availability.
Editorial Note
This page was researched and written by the ATB Editorial Team. Our team researches each AI tool by reviewing its official website, testing features, exploring real use cases, and considering user feedback. Every page is fact-checked and regularly updated to ensure the information stays accurate, neutral, and useful for our readers.
If you have any suggestions or questions, email us at hello@aitoolbook.ai