- Enterprises & Businesses: Automate workflows involving extensive document processing and analysis.
- Developers & AI Engineers: Build AI agents with conversational tool use and external system integration.
- Data Scientists & Analysts: Extract insights and summaries from large datasets and email threads.
- Multinational Teams: Utilize strong multilingual support for global business applications.
- IT & Security Teams: Deploy AI with fine-grained control over reasoning resources and data governance.
How to Use Command A Reasoning?
- Access Via Cohere Platform: Use the model with flexible reasoning mode toggles and API integrations.
- Integrate Tool Usage: Define and connect external tools using JSON schemas within chat templates.
- Configure Reasoning Budgets: Adjust token budgets to balance response depth and latency.
- Deploy with North Platform: Utilize Cohere’s on-premises solution for private, secure agent workflows.
- Conversational Tool Use: Trained for seamless interaction with APIs, databases, and search systems.
- Huge Context Window: Handles up to 256,000 tokens for multi-GPU, large document reasoning.
- Multilingual Support: Operates effectively across 23 languages, including Arabic, French, and Hindi.
- Flexible Reasoning Control: Token budget system allows precise trade-offs between speed and depth.
- Enterprise Integration: Works within Cohere’s North platform for private, compliant AI agent deployments.
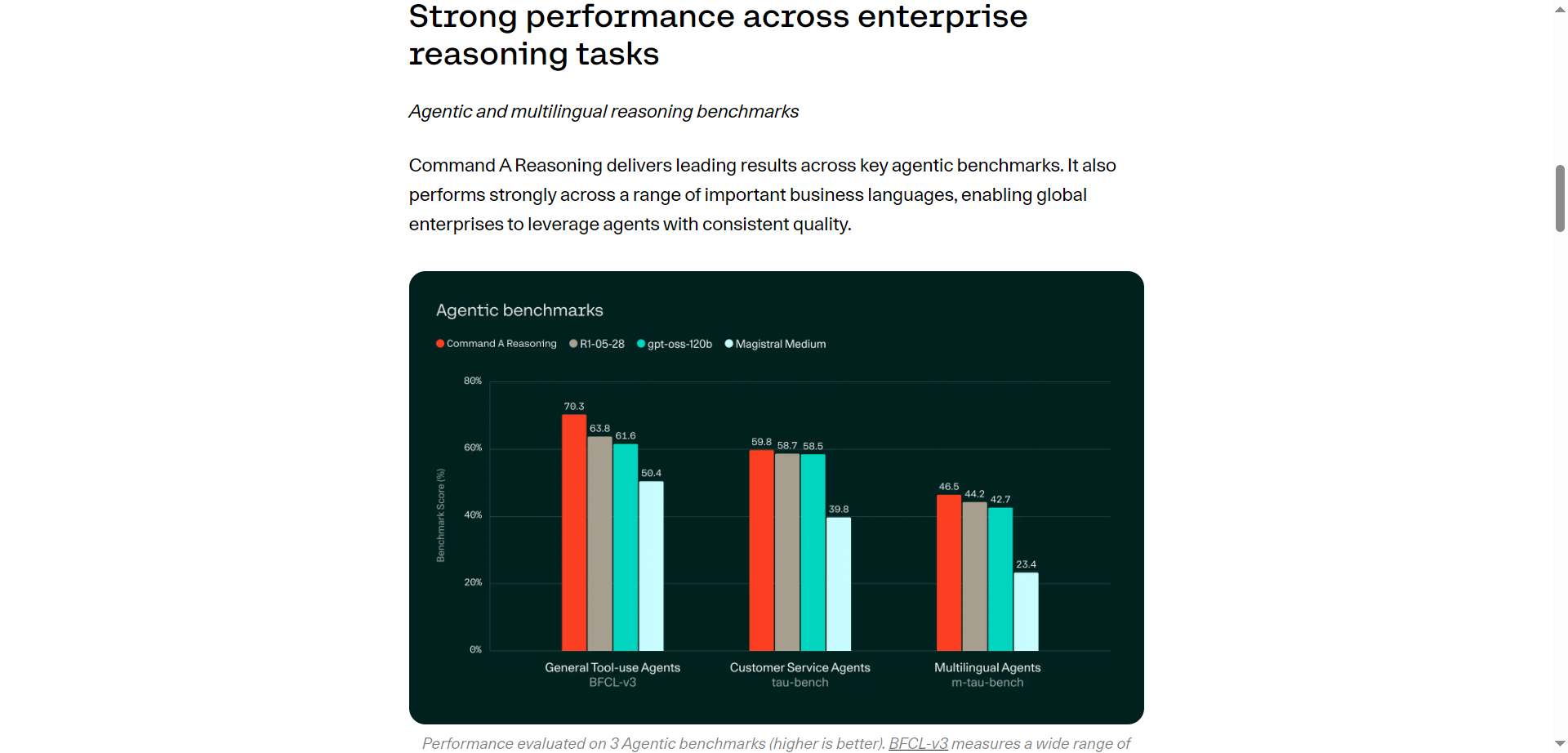
- Exceptional capability for reasoning-heavy, document-focused tasks.
- Robust tool integration amplifies AI usefulness in workflows.
- Multilingual support enables global enterprise reach.
- Flexible token budgeting empowers efficiency and customization.
- Higher resource demands for longer reasoning tasks in multi-GPU setups.
- Steeper learning curve for setting up tool integrations and budgets.
- Enterprise-focused features may not suit smaller or simpler use cases.
- Limited public benchmarking data compared to some competitor models.

Custom
Pricing information is not directly provided.
Proud of the love you're getting? Show off your AI Toolbook reviews—then invite more fans to share the love and build your credibility.
Add an AI Toolbook badge to your site—an easy way to drive followers, showcase updates, and collect reviews. It's like a mini 24/7 billboard for your AI.
Reviews
Rating Distribution
Average score
Popular Mention
FAQs
Similar AI Tools

Claude Opus 4
Claude Opus 4 is Anthropic’s most powerful, frontier-capability AI model optimized for deep reasoning and advanced software engineering. It sets industry-leading scores in coding (SWE-bench: 72.5 %; Terminal-bench: 43.2 %) and can sustain autonomous workflows—like an open-source refactor—for up to seven hours straight
Claude Opus 4
Claude Opus 4 is Anthropic’s most powerful, frontier-capability AI model optimized for deep reasoning and advanced software engineering. It sets industry-leading scores in coding (SWE-bench: 72.5 %; Terminal-bench: 43.2 %) and can sustain autonomous workflows—like an open-source refactor—for up to seven hours straight
Claude Opus 4
Claude Opus 4 is Anthropic’s most powerful, frontier-capability AI model optimized for deep reasoning and advanced software engineering. It sets industry-leading scores in coding (SWE-bench: 72.5 %; Terminal-bench: 43.2 %) and can sustain autonomous workflows—like an open-source refactor—for up to seven hours straight
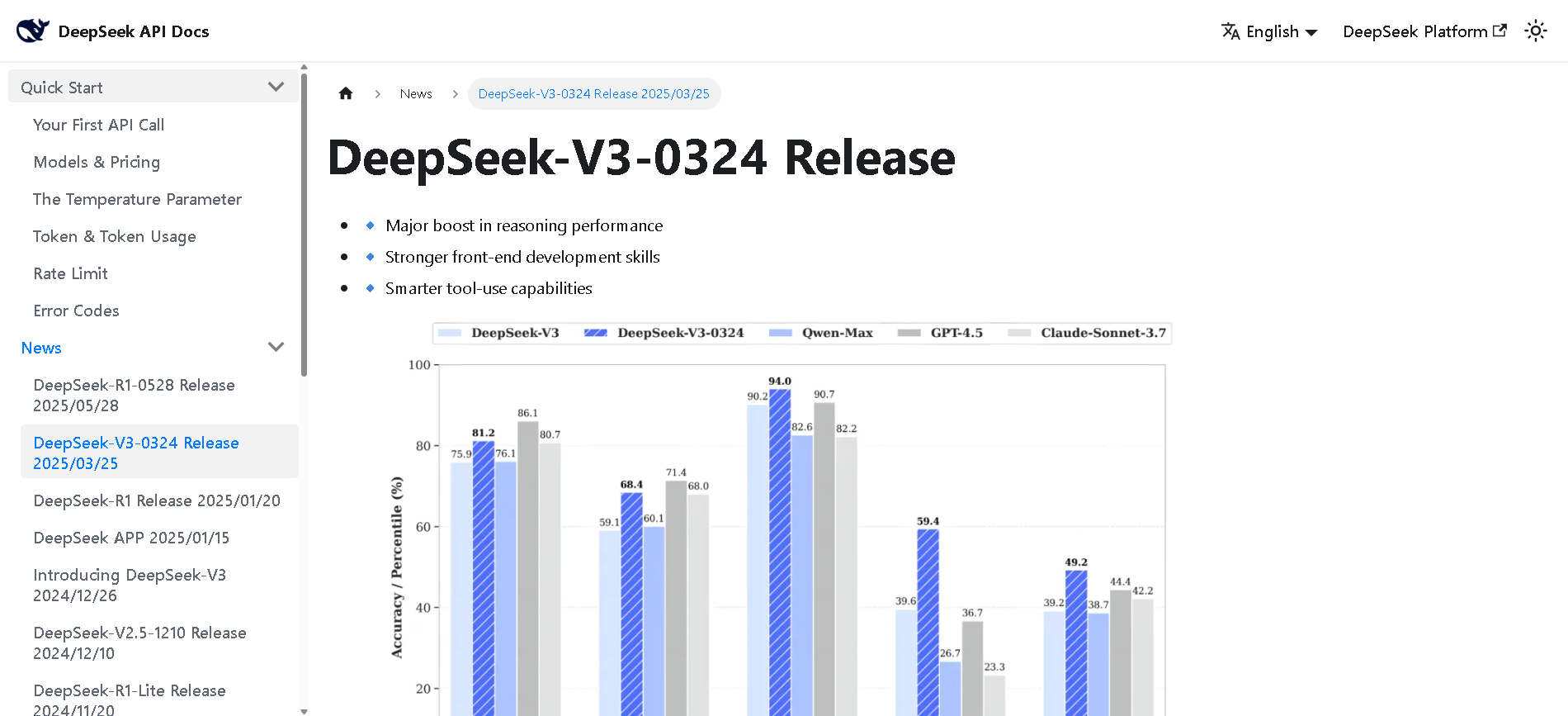
DeepSeek-V3-0324
DeepSeek V3 (0324) is the latest open-source Mixture-of-Experts (MoE) language model from DeepSeek, featuring 671B parameters (37B active per token). Released in March 2025 under the MIT license, it builds on DeepSeek V3 with major enhancements in reasoning, coding, front-end generation, and Chinese proficiency. It maintains cost-efficiency and function-calling support.
DeepSeek-V3-0324
DeepSeek V3 (0324) is the latest open-source Mixture-of-Experts (MoE) language model from DeepSeek, featuring 671B parameters (37B active per token). Released in March 2025 under the MIT license, it builds on DeepSeek V3 with major enhancements in reasoning, coding, front-end generation, and Chinese proficiency. It maintains cost-efficiency and function-calling support.
DeepSeek-V3-0324
DeepSeek V3 (0324) is the latest open-source Mixture-of-Experts (MoE) language model from DeepSeek, featuring 671B parameters (37B active per token). Released in March 2025 under the MIT license, it builds on DeepSeek V3 with major enhancements in reasoning, coding, front-end generation, and Chinese proficiency. It maintains cost-efficiency and function-calling support.

DeepSeek VL
DeepSeek VL is DeepSeek’s open-source vision-language model designed for real-world multimodal understanding. It employs a hybrid vision encoder (SigLIP‑L + SAM), processes high-resolution images (up to 1024×1024), and supports both base and chat variants across two sizes: 1.3B and 7B parameters. It excels on tasks like OCR, diagram reasoning, webpage parsing, and visual Q&A—while preserving strong language ability.
DeepSeek VL
DeepSeek VL is DeepSeek’s open-source vision-language model designed for real-world multimodal understanding. It employs a hybrid vision encoder (SigLIP‑L + SAM), processes high-resolution images (up to 1024×1024), and supports both base and chat variants across two sizes: 1.3B and 7B parameters. It excels on tasks like OCR, diagram reasoning, webpage parsing, and visual Q&A—while preserving strong language ability.
DeepSeek VL
DeepSeek VL is DeepSeek’s open-source vision-language model designed for real-world multimodal understanding. It employs a hybrid vision encoder (SigLIP‑L + SAM), processes high-resolution images (up to 1024×1024), and supports both base and chat variants across two sizes: 1.3B and 7B parameters. It excels on tasks like OCR, diagram reasoning, webpage parsing, and visual Q&A—while preserving strong language ability.
DeepSeek-Coder-V2
DeepSeek‑Coder V2 is an open-source, Mixture‑of‑Experts (MoE) code-focused variant of DeepSeek‑V2, purpose-built for code generation, completion, debugging, and mathematical reasoning. Trained with an additional 6 trillion tokens of code and text, it supports up to 338 programming languages and a massive 128K‑token context window, rivaling or exceeding commercial code models in performance.
DeepSeek-Coder-V2
DeepSeek‑Coder V2 is an open-source, Mixture‑of‑Experts (MoE) code-focused variant of DeepSeek‑V2, purpose-built for code generation, completion, debugging, and mathematical reasoning. Trained with an additional 6 trillion tokens of code and text, it supports up to 338 programming languages and a massive 128K‑token context window, rivaling or exceeding commercial code models in performance.
DeepSeek-Coder-V2
DeepSeek‑Coder V2 is an open-source, Mixture‑of‑Experts (MoE) code-focused variant of DeepSeek‑V2, purpose-built for code generation, completion, debugging, and mathematical reasoning. Trained with an additional 6 trillion tokens of code and text, it supports up to 338 programming languages and a massive 128K‑token context window, rivaling or exceeding commercial code models in performance.

DeepSeek-Math
DeepSeek Math (also called DeepSeekMath) is DeepSeek’s specialized, open-source, math-centric large language model. Built on DeepSeek‑Coder‑Base‑7B and further pre-trained on ~500B tokens—including 120B from its own math-focused corpus—it excels at competition-level reasoning, achieving 51.7 % on the MATH benchmark and ~64.2 % on GSM8K, rivaling models like GPT‑4 and Gemini‑Ultra—all without external toolkits or voting methods .
DeepSeek-Math
DeepSeek Math (also called DeepSeekMath) is DeepSeek’s specialized, open-source, math-centric large language model. Built on DeepSeek‑Coder‑Base‑7B and further pre-trained on ~500B tokens—including 120B from its own math-focused corpus—it excels at competition-level reasoning, achieving 51.7 % on the MATH benchmark and ~64.2 % on GSM8K, rivaling models like GPT‑4 and Gemini‑Ultra—all without external toolkits or voting methods .
DeepSeek-Math
DeepSeek Math (also called DeepSeekMath) is DeepSeek’s specialized, open-source, math-centric large language model. Built on DeepSeek‑Coder‑Base‑7B and further pre-trained on ~500B tokens—including 120B from its own math-focused corpus—it excels at competition-level reasoning, achieving 51.7 % on the MATH benchmark and ~64.2 % on GSM8K, rivaling models like GPT‑4 and Gemini‑Ultra—all without external toolkits or voting methods .


Grok 3 Latest
Grok 3 is xAI’s newest flagship AI chatbot, released on February 17, 2025, running on the massive Colossus supercluster (~200,000 GPUs). It offers elite-level reasoning, chain-of-thought transparency (“Think” mode), advanced “Big Brain” deeper reasoning, multimodal support (text, images), and integrated real-time DeepSearch—positioning it as a top-tier competitor to GPT‑4o, Gemini, Claude, and DeepSeek V3 on benchmarks.
Grok 3 Latest
Grok 3 is xAI’s newest flagship AI chatbot, released on February 17, 2025, running on the massive Colossus supercluster (~200,000 GPUs). It offers elite-level reasoning, chain-of-thought transparency (“Think” mode), advanced “Big Brain” deeper reasoning, multimodal support (text, images), and integrated real-time DeepSearch—positioning it as a top-tier competitor to GPT‑4o, Gemini, Claude, and DeepSeek V3 on benchmarks.
Grok 3 Latest
Grok 3 is xAI’s newest flagship AI chatbot, released on February 17, 2025, running on the massive Colossus supercluster (~200,000 GPUs). It offers elite-level reasoning, chain-of-thought transparency (“Think” mode), advanced “Big Brain” deeper reasoning, multimodal support (text, images), and integrated real-time DeepSearch—positioning it as a top-tier competitor to GPT‑4o, Gemini, Claude, and DeepSeek V3 on benchmarks.

grok-3-fast-latest
Grok 3 Fast is xAI’s speed-optimized variant of their flagship Grok 3 model, offering identical output quality with lower latency. It leverages the same underlying architecture—including multimodal input, chain-of-thought reasoning, and large context—but serves through optimized infrastructure for real-time responsiveness. It supports up to 131,072 tokens of context.
grok-3-fast-latest
Grok 3 Fast is xAI’s speed-optimized variant of their flagship Grok 3 model, offering identical output quality with lower latency. It leverages the same underlying architecture—including multimodal input, chain-of-thought reasoning, and large context—but serves through optimized infrastructure for real-time responsiveness. It supports up to 131,072 tokens of context.
grok-3-fast-latest
Grok 3 Fast is xAI’s speed-optimized variant of their flagship Grok 3 model, offering identical output quality with lower latency. It leverages the same underlying architecture—including multimodal input, chain-of-thought reasoning, and large context—but serves through optimized infrastructure for real-time responsiveness. It supports up to 131,072 tokens of context.

grok-2-latest
Grok 2 is xAI’s second-generation chatbot model, launched in August 2024 as a substantial upgrade over Grok 1.5. It delivers frontier-level performance in chat, coding, reasoning, vision tasks, and image generation via the FLUX.1 system. On leaderboards, it outscored Claude 3.5 Sonnet and GPT‑4 Turbo, with strong results in GPQA (56%), MMLU (87.5%), MATH (76.1%), HumanEval (88.4%), MathVista, and DocVQA benchmarks.
grok-2-latest
Grok 2 is xAI’s second-generation chatbot model, launched in August 2024 as a substantial upgrade over Grok 1.5. It delivers frontier-level performance in chat, coding, reasoning, vision tasks, and image generation via the FLUX.1 system. On leaderboards, it outscored Claude 3.5 Sonnet and GPT‑4 Turbo, with strong results in GPQA (56%), MMLU (87.5%), MATH (76.1%), HumanEval (88.4%), MathVista, and DocVQA benchmarks.
grok-2-latest
Grok 2 is xAI’s second-generation chatbot model, launched in August 2024 as a substantial upgrade over Grok 1.5. It delivers frontier-level performance in chat, coding, reasoning, vision tasks, and image generation via the FLUX.1 system. On leaderboards, it outscored Claude 3.5 Sonnet and GPT‑4 Turbo, with strong results in GPQA (56%), MMLU (87.5%), MATH (76.1%), HumanEval (88.4%), MathVista, and DocVQA benchmarks.

DeepSeek R1 Lite Preview is the lightweight preview of DeepSeek’s flagship reasoning model, released on November 20, 2024. It’s designed for advanced chain-of-thought reasoning in math, coding, and logic, showcasing transparent, multi-round reasoning. It achieves performance on par—or exceeding—OpenAI’s o1-preview on benchmarks like AIME and MATH, using test-time compute scaling.
DeepSeek R1 Lite Preview is the lightweight preview of DeepSeek’s flagship reasoning model, released on November 20, 2024. It’s designed for advanced chain-of-thought reasoning in math, coding, and logic, showcasing transparent, multi-round reasoning. It achieves performance on par—or exceeding—OpenAI’s o1-preview on benchmarks like AIME and MATH, using test-time compute scaling.
DeepSeek R1 Lite Preview is the lightweight preview of DeepSeek’s flagship reasoning model, released on November 20, 2024. It’s designed for advanced chain-of-thought reasoning in math, coding, and logic, showcasing transparent, multi-round reasoning. It achieves performance on par—or exceeding—OpenAI’s o1-preview on benchmarks like AIME and MATH, using test-time compute scaling.
Mistral Magistral
Magistral is Mistral AI’s first dedicated reasoning model, released on June 10, 2025, available in two versions: open-source 24 B Magistral Small and enterprise-grade Magistral Medium. It’s built to provide transparent, multilingual, domain-specific chain-of-thought reasoning, excelling in step-by-step logic tasks like math, finance, legal, and engineering.
Mistral Magistral
Magistral is Mistral AI’s first dedicated reasoning model, released on June 10, 2025, available in two versions: open-source 24 B Magistral Small and enterprise-grade Magistral Medium. It’s built to provide transparent, multilingual, domain-specific chain-of-thought reasoning, excelling in step-by-step logic tasks like math, finance, legal, and engineering.
Mistral Magistral
Magistral is Mistral AI’s first dedicated reasoning model, released on June 10, 2025, available in two versions: open-source 24 B Magistral Small and enterprise-grade Magistral Medium. It’s built to provide transparent, multilingual, domain-specific chain-of-thought reasoning, excelling in step-by-step logic tasks like math, finance, legal, and engineering.
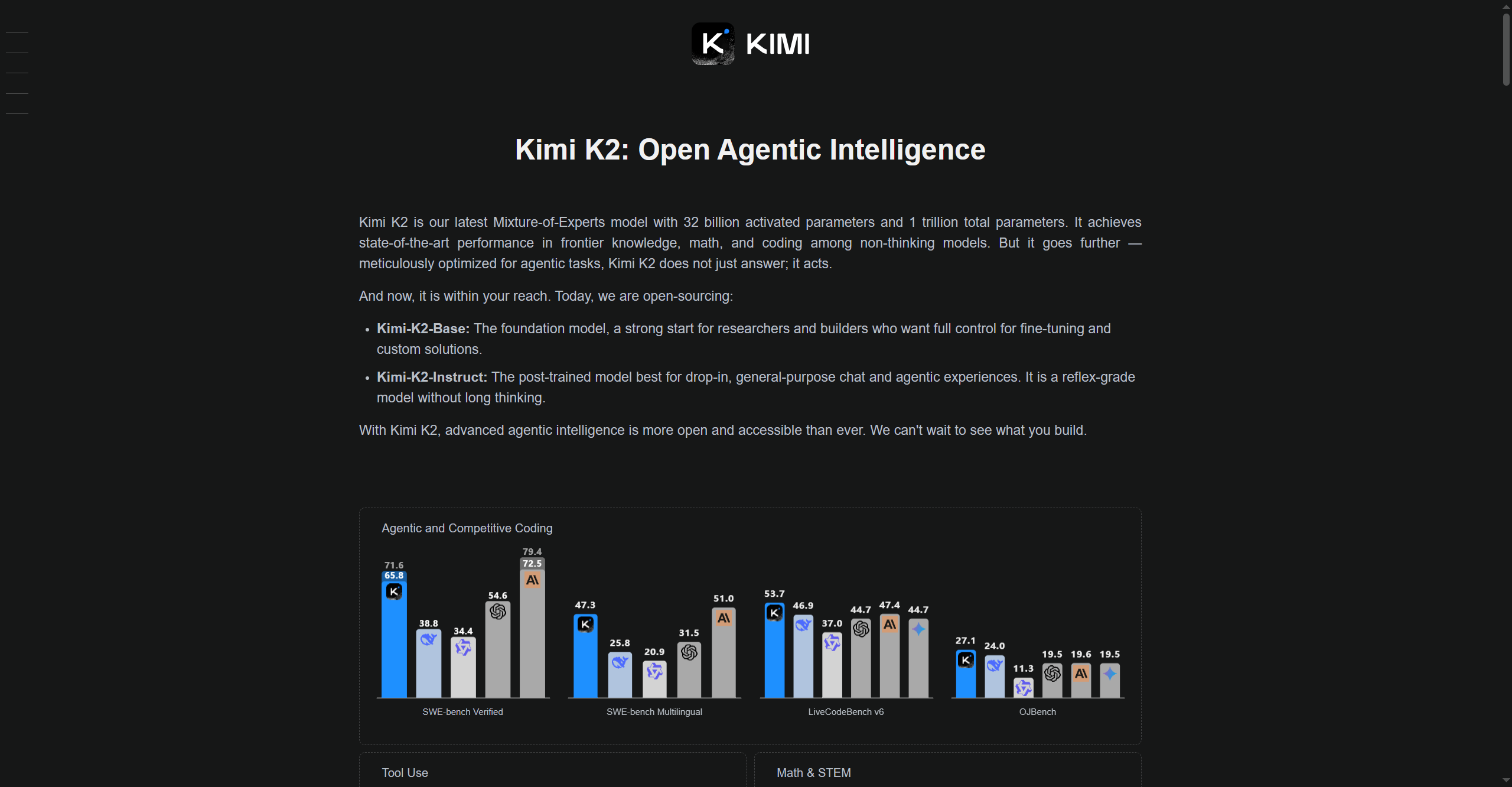

Kimi K2
Kimi-K2 is Moonshot AI’s advanced large language model (LLM) designed for high-speed reasoning, multi-modal understanding, and adaptable deployment across research, enterprise, and technical applications. Leveraging optimized architectures for efficiency and accuracy, Kimi-K2 excels in problem-solving, coding, knowledge retrieval, and interactive AI conversations. It is built to process complex real-world tasks, supporting both text and multi-modal inputs, and it provides customizable tools for experimentation and workflow automation.
Kimi K2
Kimi-K2 is Moonshot AI’s advanced large language model (LLM) designed for high-speed reasoning, multi-modal understanding, and adaptable deployment across research, enterprise, and technical applications. Leveraging optimized architectures for efficiency and accuracy, Kimi-K2 excels in problem-solving, coding, knowledge retrieval, and interactive AI conversations. It is built to process complex real-world tasks, supporting both text and multi-modal inputs, and it provides customizable tools for experimentation and workflow automation.
Kimi K2
Kimi-K2 is Moonshot AI’s advanced large language model (LLM) designed for high-speed reasoning, multi-modal understanding, and adaptable deployment across research, enterprise, and technical applications. Leveraging optimized architectures for efficiency and accuracy, Kimi-K2 excels in problem-solving, coding, knowledge retrieval, and interactive AI conversations. It is built to process complex real-world tasks, supporting both text and multi-modal inputs, and it provides customizable tools for experimentation and workflow automation.

Command R+ is Cohere’s latest state-of-the-art language model built for enterprise, optimized specifically for retrieval-augmented generation (RAG) workloads at scale. Available first on Microsoft Azure, Command R+ handles complex business data, integrates with secure infrastructure, and powers advanced AI workflows with fast, accurate responses. Designed for reliability, customization, and seamless deployment, it offers enterprises the ability to leverage cutting-edge generative and retrieval technologies across regulated industries.
Command R+ is Cohere’s latest state-of-the-art language model built for enterprise, optimized specifically for retrieval-augmented generation (RAG) workloads at scale. Available first on Microsoft Azure, Command R+ handles complex business data, integrates with secure infrastructure, and powers advanced AI workflows with fast, accurate responses. Designed for reliability, customization, and seamless deployment, it offers enterprises the ability to leverage cutting-edge generative and retrieval technologies across regulated industries.
Command R+ is Cohere’s latest state-of-the-art language model built for enterprise, optimized specifically for retrieval-augmented generation (RAG) workloads at scale. Available first on Microsoft Azure, Command R+ handles complex business data, integrates with secure infrastructure, and powers advanced AI workflows with fast, accurate responses. Designed for reliability, customization, and seamless deployment, it offers enterprises the ability to leverage cutting-edge generative and retrieval technologies across regulated industries.
Editorial Note
This page was researched and written by the ATB Editorial Team. Our team researches each AI tool by reviewing its official website, testing features, exploring real use cases, and considering user feedback. Every page is fact-checked and regularly updated to ensure the information stays accurate, neutral, and useful for our readers.
If you have any suggestions or questions, email us at hello@aitoolbook.ai