- Large Enterprises & Corporations: Manage and analyze vast business data securely with retrieval-powered AI.
- Business Leaders: Drive productivity and insights through integrated workplace automation.
- Developers & Integrators: Build scalable applications using RAG within Azure’s robust cloud environment.
- Regulated Industry Teams: Deploy in compliance with data security policies for finance, healthcare, and more.
- IT Managers & Architects: Customize, monitor, and maintain LLM deployments across private cloud infrastructure.
How to Use Command R+?
- Deploy on Microsoft Azure: Integrate the model immediately in Azure’s cloud, using built-in tools.
- Embed Into Business Apps: Connect to internal workplace systems for retrieval-augmented workflows.
- Customize Security & Access: Configure private deployment, data flow, and access controls for compliance.
- Utilize Developer Resources: Leverage comprehensive documentation and APIs for integration and optimization.
- Enterprise-Grade RAG Optimization: Built for scale and business workflows involving complex data.
- Seamless Azure Integration: First available on Microsoft Azure with native cloud deployment features.
- Customizable Security & Compliance: Supports deep cloud configuration for regulatory requirements.
- Reliable Performance at Scale: Engineered for robust throughput and fast, trustworthy responses.
- End-to-End Developer Support: Full resources and documentation for easy business application integration.
- Powerful handling of enterprise-scale, complex RAG tasks.
- Deep integration and deployment flexibility in Microsoft Azure.
- Security customization for regulated industries and privacy needs.
- Comprehensive tools for developers and IT teams.
- Initial access limited to Microsoft Azure deployments.
- Requires expertise in cloud, RAG, and business data integration.
- Complex business-focused features may be overkill for smaller projects.
- Ongoing platform evolution may need constant monitoring and updates.



Custom
Pricing information is not directly provided.
Proud of the love you're getting? Show off your AI Toolbook reviews—then invite more fans to share the love and build your credibility.
Add an AI Toolbook badge to your site—an easy way to drive followers, showcase updates, and collect reviews. It's like a mini 24/7 billboard for your AI.
Reviews
Rating Distribution
Average score
Popular Mention
FAQs
Similar AI Tools

Aider
Aider.ai is an open-source AI-powered coding assistant that allows developers to collaborate with large language models like GPT-4 directly from the command line. It integrates seamlessly with Git, enabling conversational programming, code editing, and refactoring within your existing development workflow. With Aider, you can modify multiple files at once, get code explanations, and maintain clean version history—all from your terminal.
Aider
Aider.ai is an open-source AI-powered coding assistant that allows developers to collaborate with large language models like GPT-4 directly from the command line. It integrates seamlessly with Git, enabling conversational programming, code editing, and refactoring within your existing development workflow. With Aider, you can modify multiple files at once, get code explanations, and maintain clean version history—all from your terminal.
Aider
Aider.ai is an open-source AI-powered coding assistant that allows developers to collaborate with large language models like GPT-4 directly from the command line. It integrates seamlessly with Git, enabling conversational programming, code editing, and refactoring within your existing development workflow. With Aider, you can modify multiple files at once, get code explanations, and maintain clean version history—all from your terminal.

DeepSeek-R1
DeepSeek‑R1 is the flagship reasoning-oriented AI model from Chinese startup DeepSeek. It’s an open-source, mixture-of-experts (MoE) model combining model weights clarity and chain-of-thought reasoning trained primarily through reinforcement learning. R1 delivers top-tier benchmark performance—on par with or surpassing OpenAI o1 in math, coding, and reasoning—while being significantly more cost-efficient.
DeepSeek-R1
DeepSeek‑R1 is the flagship reasoning-oriented AI model from Chinese startup DeepSeek. It’s an open-source, mixture-of-experts (MoE) model combining model weights clarity and chain-of-thought reasoning trained primarily through reinforcement learning. R1 delivers top-tier benchmark performance—on par with or surpassing OpenAI o1 in math, coding, and reasoning—while being significantly more cost-efficient.
DeepSeek-R1
DeepSeek‑R1 is the flagship reasoning-oriented AI model from Chinese startup DeepSeek. It’s an open-source, mixture-of-experts (MoE) model combining model weights clarity and chain-of-thought reasoning trained primarily through reinforcement learning. R1 delivers top-tier benchmark performance—on par with or surpassing OpenAI o1 in math, coding, and reasoning—while being significantly more cost-efficient.

DeepSeek-V3
DeepSeek V3 is the latest flagship Mixture‑of‑Experts (MoE) open‑source AI model from DeepSeek. It features 671 billion total parameters (with ~37 billion activated per token), supports up to 128K context length, and excels across reasoning, code generation, language, and multimodal tasks. On standard benchmarks, it rivals or exceeds proprietary models—including GPT‑4o and Claude 3.5—as a high-performance, cost-efficient alternative.
DeepSeek-V3
DeepSeek V3 is the latest flagship Mixture‑of‑Experts (MoE) open‑source AI model from DeepSeek. It features 671 billion total parameters (with ~37 billion activated per token), supports up to 128K context length, and excels across reasoning, code generation, language, and multimodal tasks. On standard benchmarks, it rivals or exceeds proprietary models—including GPT‑4o and Claude 3.5—as a high-performance, cost-efficient alternative.
DeepSeek-V3
DeepSeek V3 is the latest flagship Mixture‑of‑Experts (MoE) open‑source AI model from DeepSeek. It features 671 billion total parameters (with ~37 billion activated per token), supports up to 128K context length, and excels across reasoning, code generation, language, and multimodal tasks. On standard benchmarks, it rivals or exceeds proprietary models—including GPT‑4o and Claude 3.5—as a high-performance, cost-efficient alternative.

Claude 3 Opus
Claude 3 Opus is Anthropic’s flagship Claude 3 model, released March 4, 2024. It offers top-tier performance for deep reasoning, complex code, advanced math, and multimodal understanding—including charts and documents—supported by a 200K‑token context window (extendable to 1 million in select enterprise cases). It consistently outperforms GPT‑4 and Gemini Ultra on benchmark tests like MMLU, HumanEval, HellaSwag, and more.
Claude 3 Opus
Claude 3 Opus is Anthropic’s flagship Claude 3 model, released March 4, 2024. It offers top-tier performance for deep reasoning, complex code, advanced math, and multimodal understanding—including charts and documents—supported by a 200K‑token context window (extendable to 1 million in select enterprise cases). It consistently outperforms GPT‑4 and Gemini Ultra on benchmark tests like MMLU, HumanEval, HellaSwag, and more.
Claude 3 Opus
Claude 3 Opus is Anthropic’s flagship Claude 3 model, released March 4, 2024. It offers top-tier performance for deep reasoning, complex code, advanced math, and multimodal understanding—including charts and documents—supported by a 200K‑token context window (extendable to 1 million in select enterprise cases). It consistently outperforms GPT‑4 and Gemini Ultra on benchmark tests like MMLU, HumanEval, HellaSwag, and more.
Mistral Nemotron
Mistral Nemotron is a preview large language model, jointly developed by Mistral AI and NVIDIA, released on June 11, 2025. Optimized by NVIDIA for inference using TensorRT-LLM and vLLM, it supports a massive 128K-token context window and is built for agentic workflows—excelling in instruction-following, function calling, and code generation—while delivering state-of-the-art performance across reasoning, math, coding, and multilingual benchmarks.
Mistral Nemotron
Mistral Nemotron is a preview large language model, jointly developed by Mistral AI and NVIDIA, released on June 11, 2025. Optimized by NVIDIA for inference using TensorRT-LLM and vLLM, it supports a massive 128K-token context window and is built for agentic workflows—excelling in instruction-following, function calling, and code generation—while delivering state-of-the-art performance across reasoning, math, coding, and multilingual benchmarks.
Mistral Nemotron
Mistral Nemotron is a preview large language model, jointly developed by Mistral AI and NVIDIA, released on June 11, 2025. Optimized by NVIDIA for inference using TensorRT-LLM and vLLM, it supports a massive 128K-token context window and is built for agentic workflows—excelling in instruction-following, function calling, and code generation—while delivering state-of-the-art performance across reasoning, math, coding, and multilingual benchmarks.
Aider.chat
Aider.chat is an open-source AI pair‑programming assistant you run from your terminal. It connects to LLMs (like Claude 3.7 Sonnet, DeepSeek R1, GPT‑4o, and more) to write, refactor, and test code across your repository—integrated with Git to auto-commit changes, display diffs, and maintain full project context.
Aider.chat
Aider.chat is an open-source AI pair‑programming assistant you run from your terminal. It connects to LLMs (like Claude 3.7 Sonnet, DeepSeek R1, GPT‑4o, and more) to write, refactor, and test code across your repository—integrated with Git to auto-commit changes, display diffs, and maintain full project context.
Aider.chat
Aider.chat is an open-source AI pair‑programming assistant you run from your terminal. It connects to LLMs (like Claude 3.7 Sonnet, DeepSeek R1, GPT‑4o, and more) to write, refactor, and test code across your repository—integrated with Git to auto-commit changes, display diffs, and maintain full project context.
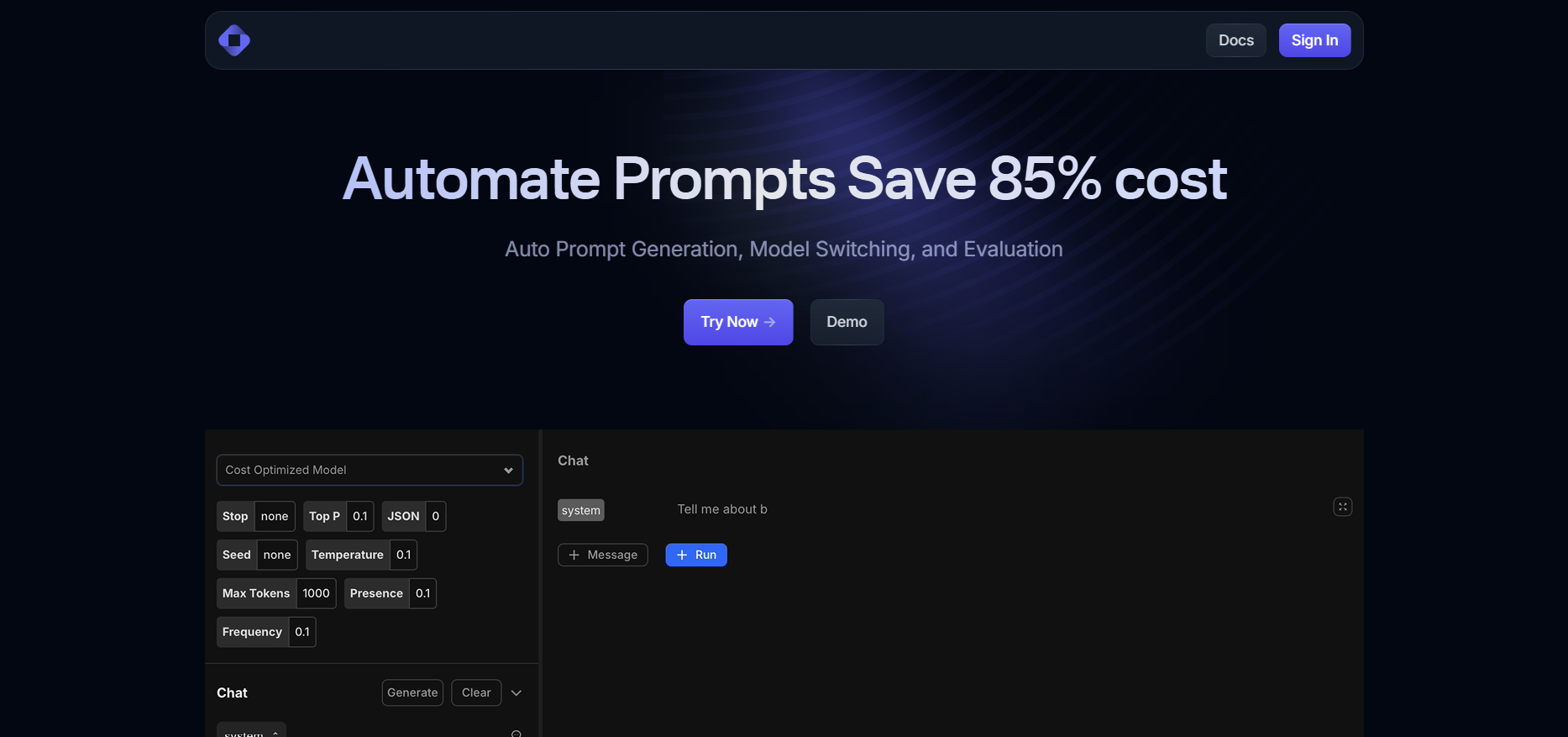
TrainKore
Trainkore is a versatile AI orchestration platform that automates prompt generation, model selection, and cost optimization across large language models (LLMs). The Model Router intelligently routes prompt requests to the best-priced or highest-performing model, achieving up to 85% cost savings. Users benefit from an auto-prompt generation playground, advanced settings, and seamless control—all through an intuitive UI. Ideal for teams managing multiple AI providers, Trainkore dramatically simplifies LLM workflows while improving efficiency and oversight.
TrainKore
Trainkore is a versatile AI orchestration platform that automates prompt generation, model selection, and cost optimization across large language models (LLMs). The Model Router intelligently routes prompt requests to the best-priced or highest-performing model, achieving up to 85% cost savings. Users benefit from an auto-prompt generation playground, advanced settings, and seamless control—all through an intuitive UI. Ideal for teams managing multiple AI providers, Trainkore dramatically simplifies LLM workflows while improving efficiency and oversight.
TrainKore
Trainkore is a versatile AI orchestration platform that automates prompt generation, model selection, and cost optimization across large language models (LLMs). The Model Router intelligently routes prompt requests to the best-priced or highest-performing model, achieving up to 85% cost savings. Users benefit from an auto-prompt generation playground, advanced settings, and seamless control—all through an intuitive UI. Ideal for teams managing multiple AI providers, Trainkore dramatically simplifies LLM workflows while improving efficiency and oversight.
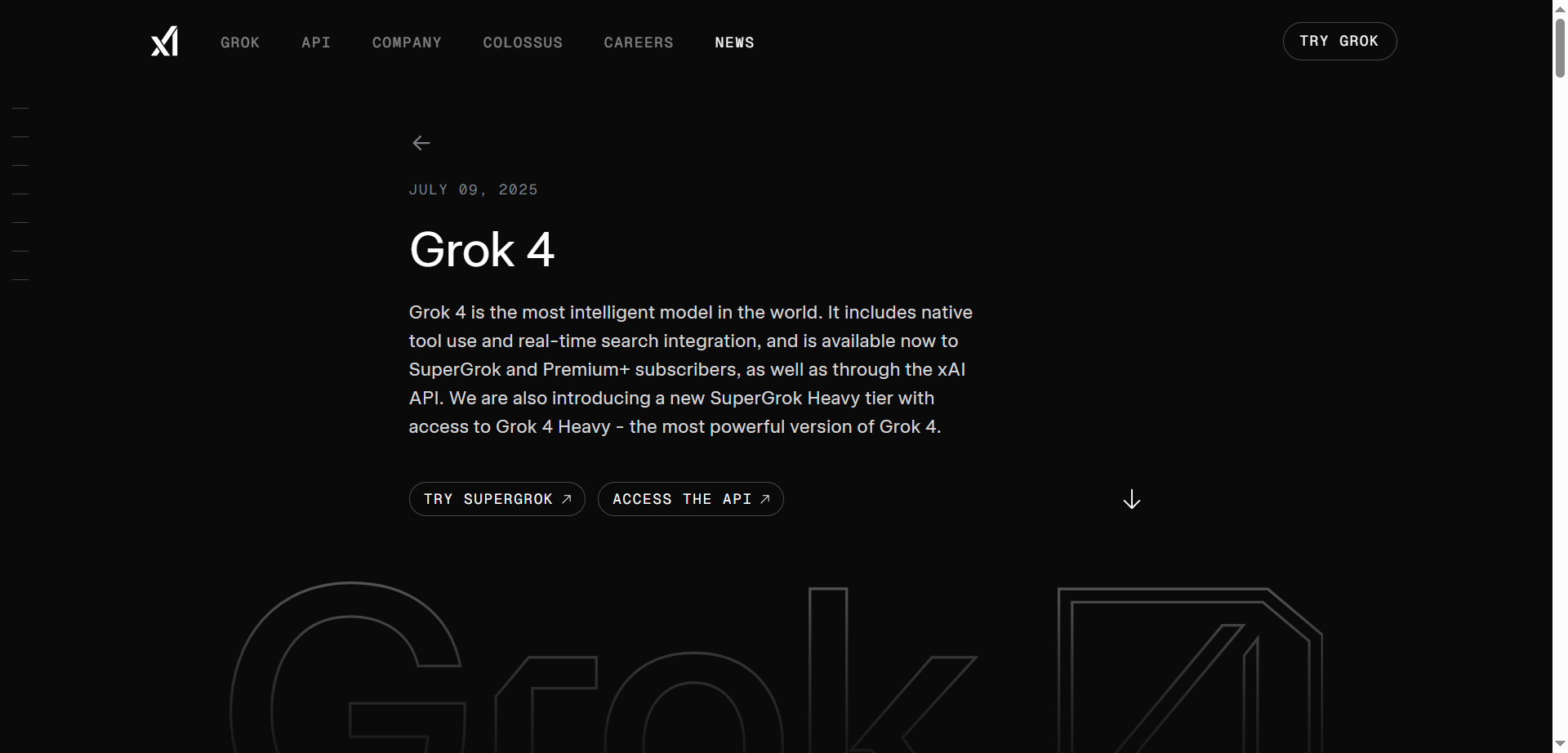
Grok 4
Grok 4 is the latest and most intelligent AI model developed by xAI, designed for expert-level reasoning and real-time knowledge integration. It combines large-scale reinforcement learning with native tool use, including code interpretation, web browsing, and advanced search capabilities, to provide highly accurate and up-to-date responses. Grok 4 excels across diverse domains such as math, coding, science, and complex reasoning, supporting multimodal inputs like text and vision. With its massive 256,000-token context window and advanced toolset, Grok 4 is built to push the boundaries of AI intelligence and practical utility for both developers and enterprises.
Grok 4
Grok 4 is the latest and most intelligent AI model developed by xAI, designed for expert-level reasoning and real-time knowledge integration. It combines large-scale reinforcement learning with native tool use, including code interpretation, web browsing, and advanced search capabilities, to provide highly accurate and up-to-date responses. Grok 4 excels across diverse domains such as math, coding, science, and complex reasoning, supporting multimodal inputs like text and vision. With its massive 256,000-token context window and advanced toolset, Grok 4 is built to push the boundaries of AI intelligence and practical utility for both developers and enterprises.
Grok 4
Grok 4 is the latest and most intelligent AI model developed by xAI, designed for expert-level reasoning and real-time knowledge integration. It combines large-scale reinforcement learning with native tool use, including code interpretation, web browsing, and advanced search capabilities, to provide highly accurate and up-to-date responses. Grok 4 excels across diverse domains such as math, coding, science, and complex reasoning, supporting multimodal inputs like text and vision. With its massive 256,000-token context window and advanced toolset, Grok 4 is built to push the boundaries of AI intelligence and practical utility for both developers and enterprises.
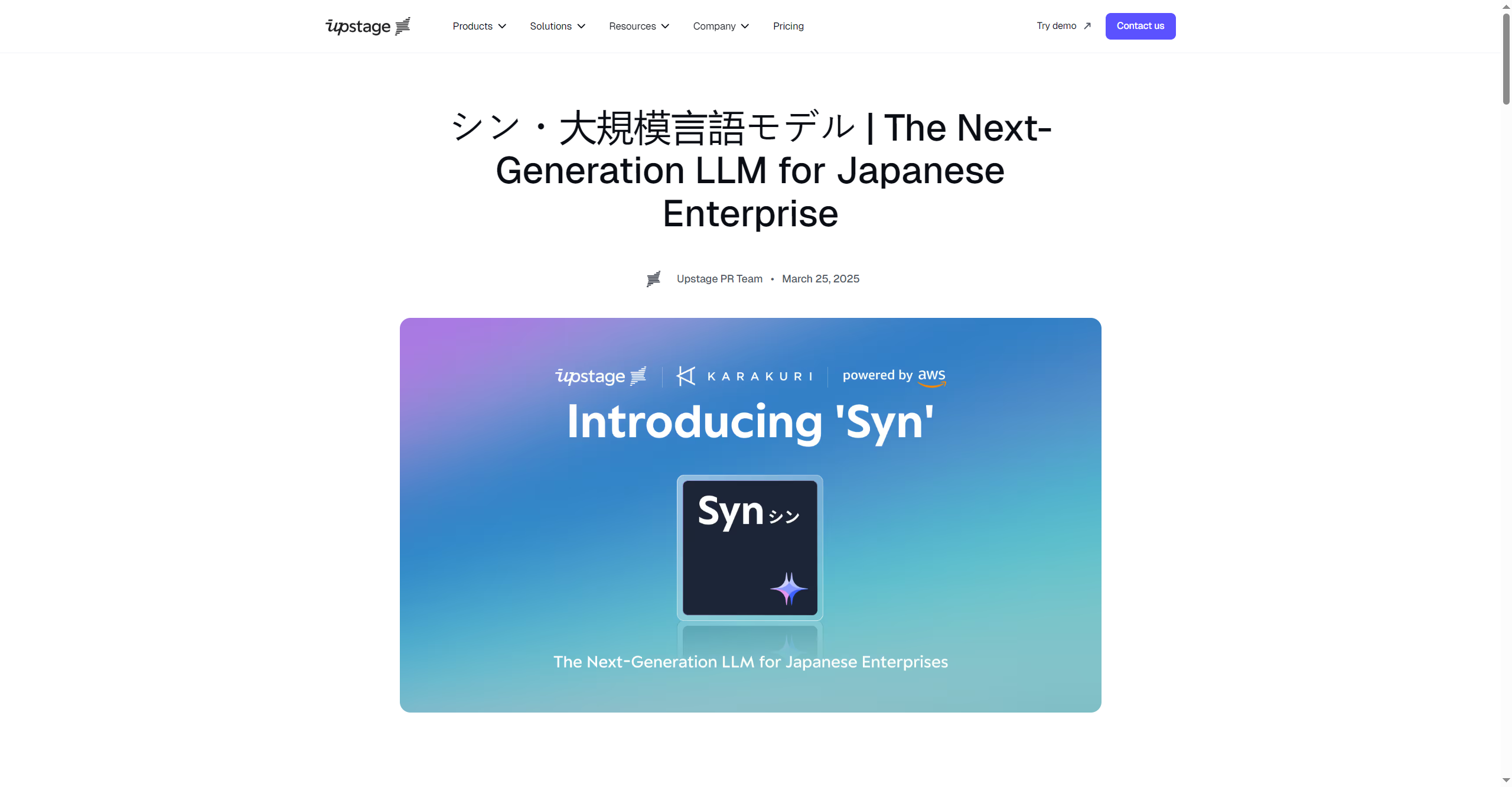

Upstage - Syn
Syn is a next-generation Japanese Large Language Model (LLM) collaboratively developed by Upstage and Karakuri Inc., designed specifically for enterprise use in Japan. With fewer than 14 billion parameters, Syn delivers top-tier AI accuracy, safety, and business alignment, outperforming competitors in Japanese on leading benchmarks like the Nejumi Leaderboard. Built on Upstage’s Solar Mini architecture, Syn balances cost efficiency and performance, offering rapid deployment, fine-tuned reliability, and flexible application across industries such as finance, legal, manufacturing, and healthcare.
Upstage - Syn
Syn is a next-generation Japanese Large Language Model (LLM) collaboratively developed by Upstage and Karakuri Inc., designed specifically for enterprise use in Japan. With fewer than 14 billion parameters, Syn delivers top-tier AI accuracy, safety, and business alignment, outperforming competitors in Japanese on leading benchmarks like the Nejumi Leaderboard. Built on Upstage’s Solar Mini architecture, Syn balances cost efficiency and performance, offering rapid deployment, fine-tuned reliability, and flexible application across industries such as finance, legal, manufacturing, and healthcare.
Upstage - Syn
Syn is a next-generation Japanese Large Language Model (LLM) collaboratively developed by Upstage and Karakuri Inc., designed specifically for enterprise use in Japan. With fewer than 14 billion parameters, Syn delivers top-tier AI accuracy, safety, and business alignment, outperforming competitors in Japanese on leading benchmarks like the Nejumi Leaderboard. Built on Upstage’s Solar Mini architecture, Syn balances cost efficiency and performance, offering rapid deployment, fine-tuned reliability, and flexible application across industries such as finance, legal, manufacturing, and healthcare.


UnificAlly
Unifically is an AI-powered API marketplace that gives developers unified, low-cost access to today’s most in-demand generative models—for images, video, music, speech, and more—through a single, consistent interface. By aggregating multiple providers and handling usage metering, authentication, and cost optimization behind the scenes, Unifically lets teams prototype, ship, and scale AI features faster while paying only for what they use. Flexible pay-as-you-go pricing, clear rate limits, and detailed analytics make it a practical choice for startups and enterprises alike.
UnificAlly
Unifically is an AI-powered API marketplace that gives developers unified, low-cost access to today’s most in-demand generative models—for images, video, music, speech, and more—through a single, consistent interface. By aggregating multiple providers and handling usage metering, authentication, and cost optimization behind the scenes, Unifically lets teams prototype, ship, and scale AI features faster while paying only for what they use. Flexible pay-as-you-go pricing, clear rate limits, and detailed analytics make it a practical choice for startups and enterprises alike.
UnificAlly
Unifically is an AI-powered API marketplace that gives developers unified, low-cost access to today’s most in-demand generative models—for images, video, music, speech, and more—through a single, consistent interface. By aggregating multiple providers and handling usage metering, authentication, and cost optimization behind the scenes, Unifically lets teams prototype, ship, and scale AI features faster while paying only for what they use. Flexible pay-as-you-go pricing, clear rate limits, and detailed analytics make it a practical choice for startups and enterprises alike.

GPT Proto
GPT Proto provides developers with a unified API to access top AI models for text, image, video, and audio generation, offering rock-solid uptime, lightning-fast responses, and the lowest prices without managing multiple keys or platforms. It aggregates leading models like GPT-5 series, Claude Opus/Sonnet/Haiku, Gemini variants, Grok, and specialized tools for creators, with significant discounts such as 40% off market rates on many. From solo projects to enterprise scale, it ensures 95% of requests respond within 20 seconds, half in just 6 seconds, via robust infrastructure and failover. Quick setup lets you sign up, add credits, generate one API key, and integrate seamlessly into apps, agents, or workflows for prototyping or production.
GPT Proto
GPT Proto provides developers with a unified API to access top AI models for text, image, video, and audio generation, offering rock-solid uptime, lightning-fast responses, and the lowest prices without managing multiple keys or platforms. It aggregates leading models like GPT-5 series, Claude Opus/Sonnet/Haiku, Gemini variants, Grok, and specialized tools for creators, with significant discounts such as 40% off market rates on many. From solo projects to enterprise scale, it ensures 95% of requests respond within 20 seconds, half in just 6 seconds, via robust infrastructure and failover. Quick setup lets you sign up, add credits, generate one API key, and integrate seamlessly into apps, agents, or workflows for prototyping or production.
GPT Proto
GPT Proto provides developers with a unified API to access top AI models for text, image, video, and audio generation, offering rock-solid uptime, lightning-fast responses, and the lowest prices without managing multiple keys or platforms. It aggregates leading models like GPT-5 series, Claude Opus/Sonnet/Haiku, Gemini variants, Grok, and specialized tools for creators, with significant discounts such as 40% off market rates on many. From solo projects to enterprise scale, it ensures 95% of requests respond within 20 seconds, half in just 6 seconds, via robust infrastructure and failover. Quick setup lets you sign up, add credits, generate one API key, and integrate seamlessly into apps, agents, or workflows for prototyping or production.

cognee
Cognee is an AI memory engine and knowledge graph platform that transforms raw data into a living, self-improving knowledge base for AI agents, surpassing traditional RAG by adding ontologies, personalization, and continuous learning. It ingests 38+ data types like PDFs, docs, audio, and images, builds custom ontologies, and integrates with 29+ vector/graph databases, LLMs, and agent frameworks for domain-smart copilots that adapt from feedback. Used in production by banks, edtech, and policy teams, it unifies scattered data for precise, cited answers and multi-step reasoning.
cognee
Cognee is an AI memory engine and knowledge graph platform that transforms raw data into a living, self-improving knowledge base for AI agents, surpassing traditional RAG by adding ontologies, personalization, and continuous learning. It ingests 38+ data types like PDFs, docs, audio, and images, builds custom ontologies, and integrates with 29+ vector/graph databases, LLMs, and agent frameworks for domain-smart copilots that adapt from feedback. Used in production by banks, edtech, and policy teams, it unifies scattered data for precise, cited answers and multi-step reasoning.
cognee
Cognee is an AI memory engine and knowledge graph platform that transforms raw data into a living, self-improving knowledge base for AI agents, surpassing traditional RAG by adding ontologies, personalization, and continuous learning. It ingests 38+ data types like PDFs, docs, audio, and images, builds custom ontologies, and integrates with 29+ vector/graph databases, LLMs, and agent frameworks for domain-smart copilots that adapt from feedback. Used in production by banks, edtech, and policy teams, it unifies scattered data for precise, cited answers and multi-step reasoning.
Editorial Note
This page was researched and written by the ATB Editorial Team. Our team researches each AI tool by reviewing its official website, testing features, exploring real use cases, and considering user feedback. Every page is fact-checked and regularly updated to ensure the information stays accurate, neutral, and useful for our readers.
If you have any suggestions or questions, email us at hello@aitoolbook.ai