- Enterprise AI Teams: Deploy efficient, powerful AI models for large-scale business applications.
- Developers & System Integrators: Build advanced agentic solutions with fast computation and high accuracy.
- Data Scientists & Analysts: Use AI to streamline research, automate analysis, and generate insights.
- IT & Infrastructure Managers: Achieve cost-efficient AI deployments without sacrificing performance.
- Business Leaders & Strategists: Leverage AI-driven workflows to enhance productivity and insight.
How to Use Command A?
- Access Via Cohere Platform: Use Cohere’s cloud environment to deploy the Command A model.
- Integrate with Enterprise Systems: Connect AI with business applications for agentic task automation.
- Optimize for Efficiency: Adjust model configurations to balance speed and compute resource use.
- Leverage Developer Tools: Utilize comprehensive API documentation and support for integration.
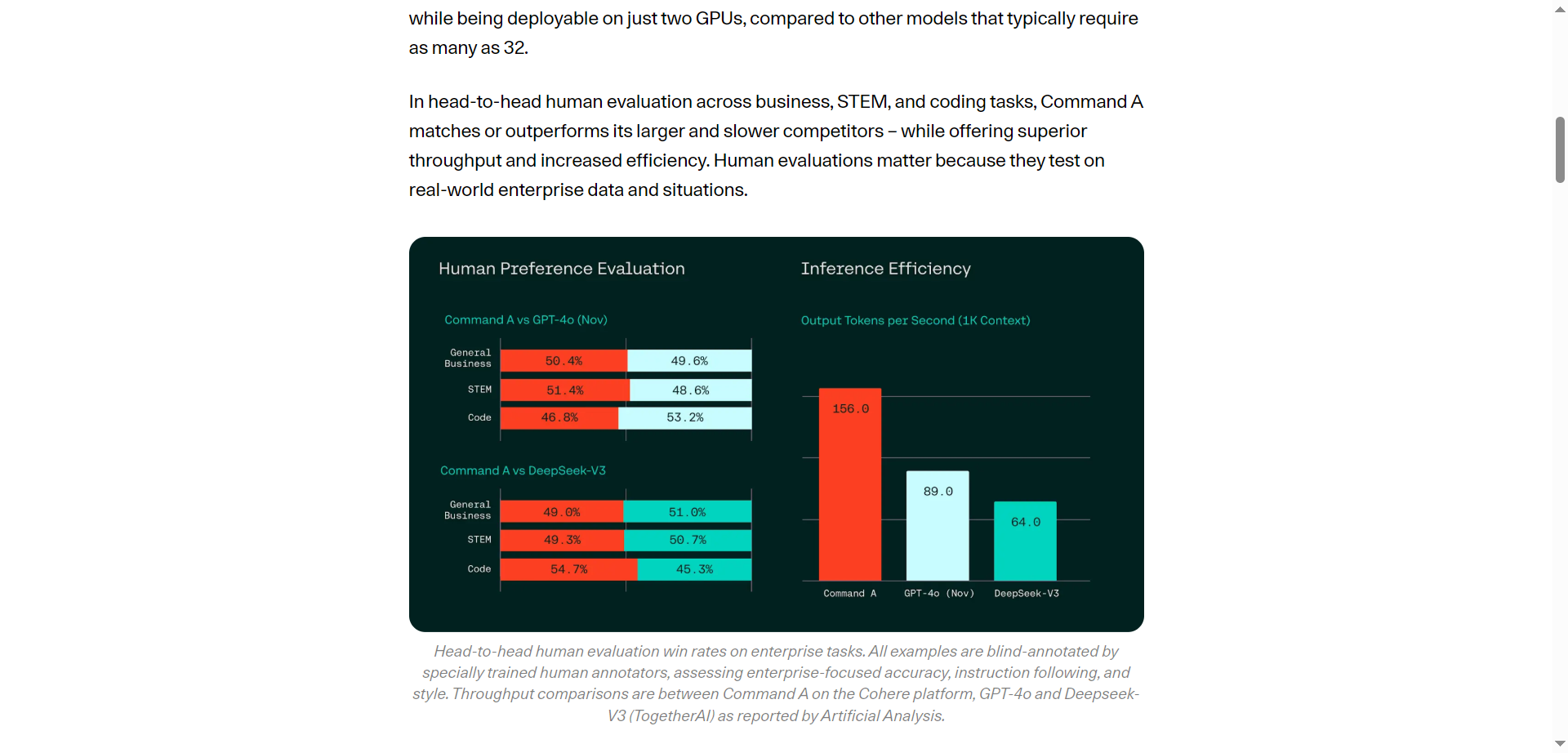
- High Accuracy with Low Compute: Matches or beats GPT-4o efficiency on demanding tasks.
- Agentic Task Mastery: Designed specifically for complex, multi-step enterprise workflows.
- Scalable for Business Needs: Supports large workloads with fast inference times.
- Cost-Effective Performance: Reduces infrastructure costs without compromising power.
- Robust Developer Ecosystem: Full support and tools for seamless integration and customization.
- Excellent balance of performance and computational efficiency.
- Strong enterprise focus for real-world AI productivity applications.
- Comprehensive documentation and developer support.
- Flexible deployment options across cloud and hybrid environments.
- Advanced features require enterprise-level access or subscription.
- May need tuning to maximize efficiency for specific workloads.
- Less public benchmarking data compared to some competitor models.
- High-performance focus might not suit smaller-scale or hobbyist projects.


Token based
$2.5/$10 per 1M tokens
Output: $10.00/1M tokens
256K token context window
8K maximum output tokens
Only requires two GPUs to run (A100s/H100s)
Proud of the love you're getting? Show off your AI Toolbook reviews—then invite more fans to share the love and build your credibility.
Add an AI Toolbook badge to your site—an easy way to drive followers, showcase updates, and collect reviews. It's like a mini 24/7 billboard for your AI.
Reviews
Rating Distribution
Average score
Popular Mention
FAQs
Similar AI Tools

GPT-4.1 Mini is a lightweight version of OpenAI’s advanced GPT-4.1 model, designed for efficiency, speed, and affordability without compromising much on performance. Tailored for developers and teams who need capable AI reasoning and natural language processing in smaller-scale or cost-sensitive applications, GPT-4.1 Mini brings the power of GPT-4.1 into a more accessible form factor. Perfect for chatbots, content suggestions, productivity tools, and streamlined AI experiences, this compact model still delivers impressive accuracy, fast responses, and a reliable understanding of nuanced prompts—all while using fewer resources.
GPT-4.1 Mini is a lightweight version of OpenAI’s advanced GPT-4.1 model, designed for efficiency, speed, and affordability without compromising much on performance. Tailored for developers and teams who need capable AI reasoning and natural language processing in smaller-scale or cost-sensitive applications, GPT-4.1 Mini brings the power of GPT-4.1 into a more accessible form factor. Perfect for chatbots, content suggestions, productivity tools, and streamlined AI experiences, this compact model still delivers impressive accuracy, fast responses, and a reliable understanding of nuanced prompts—all while using fewer resources.
GPT-4.1 Mini is a lightweight version of OpenAI’s advanced GPT-4.1 model, designed for efficiency, speed, and affordability without compromising much on performance. Tailored for developers and teams who need capable AI reasoning and natural language processing in smaller-scale or cost-sensitive applications, GPT-4.1 Mini brings the power of GPT-4.1 into a more accessible form factor. Perfect for chatbots, content suggestions, productivity tools, and streamlined AI experiences, this compact model still delivers impressive accuracy, fast responses, and a reliable understanding of nuanced prompts—all while using fewer resources.
Claude 3 Sonnet
Claude 3 Sonnet is Anthropic’s mid-tier, high-performance model in the Claude 3 family. It balances capability and cost, delivering intelligent responses for data processing, reasoning, recommendations, and image-to-text tasks. Sonnet offers twice the speed of previous Claude 2 models, supports vision inputs, and maintains a 200K‑token context window—all at a developer-friendly price of $3 per million input tokens and $15 per million output tokens.
Claude 3 Sonnet
Claude 3 Sonnet is Anthropic’s mid-tier, high-performance model in the Claude 3 family. It balances capability and cost, delivering intelligent responses for data processing, reasoning, recommendations, and image-to-text tasks. Sonnet offers twice the speed of previous Claude 2 models, supports vision inputs, and maintains a 200K‑token context window—all at a developer-friendly price of $3 per million input tokens and $15 per million output tokens.
Claude 3 Sonnet
Claude 3 Sonnet is Anthropic’s mid-tier, high-performance model in the Claude 3 family. It balances capability and cost, delivering intelligent responses for data processing, reasoning, recommendations, and image-to-text tasks. Sonnet offers twice the speed of previous Claude 2 models, supports vision inputs, and maintains a 200K‑token context window—all at a developer-friendly price of $3 per million input tokens and $15 per million output tokens.

DeepSeek-V3
DeepSeek V3 is the latest flagship Mixture‑of‑Experts (MoE) open‑source AI model from DeepSeek. It features 671 billion total parameters (with ~37 billion activated per token), supports up to 128K context length, and excels across reasoning, code generation, language, and multimodal tasks. On standard benchmarks, it rivals or exceeds proprietary models—including GPT‑4o and Claude 3.5—as a high-performance, cost-efficient alternative.
DeepSeek-V3
DeepSeek V3 is the latest flagship Mixture‑of‑Experts (MoE) open‑source AI model from DeepSeek. It features 671 billion total parameters (with ~37 billion activated per token), supports up to 128K context length, and excels across reasoning, code generation, language, and multimodal tasks. On standard benchmarks, it rivals or exceeds proprietary models—including GPT‑4o and Claude 3.5—as a high-performance, cost-efficient alternative.
DeepSeek-V3
DeepSeek V3 is the latest flagship Mixture‑of‑Experts (MoE) open‑source AI model from DeepSeek. It features 671 billion total parameters (with ~37 billion activated per token), supports up to 128K context length, and excels across reasoning, code generation, language, and multimodal tasks. On standard benchmarks, it rivals or exceeds proprietary models—including GPT‑4o and Claude 3.5—as a high-performance, cost-efficient alternative.

DeepSeek VL
DeepSeek VL is DeepSeek’s open-source vision-language model designed for real-world multimodal understanding. It employs a hybrid vision encoder (SigLIP‑L + SAM), processes high-resolution images (up to 1024×1024), and supports both base and chat variants across two sizes: 1.3B and 7B parameters. It excels on tasks like OCR, diagram reasoning, webpage parsing, and visual Q&A—while preserving strong language ability.
DeepSeek VL
DeepSeek VL is DeepSeek’s open-source vision-language model designed for real-world multimodal understanding. It employs a hybrid vision encoder (SigLIP‑L + SAM), processes high-resolution images (up to 1024×1024), and supports both base and chat variants across two sizes: 1.3B and 7B parameters. It excels on tasks like OCR, diagram reasoning, webpage parsing, and visual Q&A—while preserving strong language ability.
DeepSeek VL
DeepSeek VL is DeepSeek’s open-source vision-language model designed for real-world multimodal understanding. It employs a hybrid vision encoder (SigLIP‑L + SAM), processes high-resolution images (up to 1024×1024), and supports both base and chat variants across two sizes: 1.3B and 7B parameters. It excels on tasks like OCR, diagram reasoning, webpage parsing, and visual Q&A—while preserving strong language ability.

Claude 3 Opus
Claude 3 Opus is Anthropic’s flagship Claude 3 model, released March 4, 2024. It offers top-tier performance for deep reasoning, complex code, advanced math, and multimodal understanding—including charts and documents—supported by a 200K‑token context window (extendable to 1 million in select enterprise cases). It consistently outperforms GPT‑4 and Gemini Ultra on benchmark tests like MMLU, HumanEval, HellaSwag, and more.
Claude 3 Opus
Claude 3 Opus is Anthropic’s flagship Claude 3 model, released March 4, 2024. It offers top-tier performance for deep reasoning, complex code, advanced math, and multimodal understanding—including charts and documents—supported by a 200K‑token context window (extendable to 1 million in select enterprise cases). It consistently outperforms GPT‑4 and Gemini Ultra on benchmark tests like MMLU, HumanEval, HellaSwag, and more.
Claude 3 Opus
Claude 3 Opus is Anthropic’s flagship Claude 3 model, released March 4, 2024. It offers top-tier performance for deep reasoning, complex code, advanced math, and multimodal understanding—including charts and documents—supported by a 200K‑token context window (extendable to 1 million in select enterprise cases). It consistently outperforms GPT‑4 and Gemini Ultra on benchmark tests like MMLU, HumanEval, HellaSwag, and more.

grok-2-1212
Grok 2 – 1212 is xAI’s enhanced version of Grok 2, released December 12, 2024. It’s designed to be faster—up to 3× speed boost—with sharper accuracy, improved instruction-following, and stronger multilingual support. It includes web search, citations, and the Aurora image-generation feature. Now available to all users on X, with Premium tiers getting higher usage limits.
grok-2-1212
Grok 2 – 1212 is xAI’s enhanced version of Grok 2, released December 12, 2024. It’s designed to be faster—up to 3× speed boost—with sharper accuracy, improved instruction-following, and stronger multilingual support. It includes web search, citations, and the Aurora image-generation feature. Now available to all users on X, with Premium tiers getting higher usage limits.
grok-2-1212
Grok 2 – 1212 is xAI’s enhanced version of Grok 2, released December 12, 2024. It’s designed to be faster—up to 3× speed boost—with sharper accuracy, improved instruction-following, and stronger multilingual support. It includes web search, citations, and the Aurora image-generation feature. Now available to all users on X, with Premium tiers getting higher usage limits.

Meta Llama 3.3
Llama 3.3 is Meta’s instruction-tuned, text-only large language model released on December 6, 2024, available in a 70B-parameter size. It matches the performance of much larger models using significantly fewer parameters, is multilingual across eight key languages, and supports a massive 128,000-token context window—ideal for handling long-form documents, codebases, and detailed reasoning tasks.
Meta Llama 3.3
Llama 3.3 is Meta’s instruction-tuned, text-only large language model released on December 6, 2024, available in a 70B-parameter size. It matches the performance of much larger models using significantly fewer parameters, is multilingual across eight key languages, and supports a massive 128,000-token context window—ideal for handling long-form documents, codebases, and detailed reasoning tasks.
Meta Llama 3.3
Llama 3.3 is Meta’s instruction-tuned, text-only large language model released on December 6, 2024, available in a 70B-parameter size. It matches the performance of much larger models using significantly fewer parameters, is multilingual across eight key languages, and supports a massive 128,000-token context window—ideal for handling long-form documents, codebases, and detailed reasoning tasks.

Mistral Large 2
Mistral Large 2 is the second-generation flagship model from Mistral AI, released in July 2024. Also referenced as mistral-large-2407, it’s a 123 B-parameter dense LLM with a 128 K-token context window, supporting dozens of languages and 80+ coding languages. It excels in reasoning, code generation, mathematics, instruction-following, and function calling—designed for high throughput on single-node setups.
Mistral Large 2
Mistral Large 2 is the second-generation flagship model from Mistral AI, released in July 2024. Also referenced as mistral-large-2407, it’s a 123 B-parameter dense LLM with a 128 K-token context window, supporting dozens of languages and 80+ coding languages. It excels in reasoning, code generation, mathematics, instruction-following, and function calling—designed for high throughput on single-node setups.
Mistral Large 2
Mistral Large 2 is the second-generation flagship model from Mistral AI, released in July 2024. Also referenced as mistral-large-2407, it’s a 123 B-parameter dense LLM with a 128 K-token context window, supporting dozens of languages and 80+ coding languages. It excels in reasoning, code generation, mathematics, instruction-following, and function calling—designed for high throughput on single-node setups.
Mistral Nemotron
Mistral Nemotron is a preview large language model, jointly developed by Mistral AI and NVIDIA, released on June 11, 2025. Optimized by NVIDIA for inference using TensorRT-LLM and vLLM, it supports a massive 128K-token context window and is built for agentic workflows—excelling in instruction-following, function calling, and code generation—while delivering state-of-the-art performance across reasoning, math, coding, and multilingual benchmarks.
Mistral Nemotron
Mistral Nemotron is a preview large language model, jointly developed by Mistral AI and NVIDIA, released on June 11, 2025. Optimized by NVIDIA for inference using TensorRT-LLM and vLLM, it supports a massive 128K-token context window and is built for agentic workflows—excelling in instruction-following, function calling, and code generation—while delivering state-of-the-art performance across reasoning, math, coding, and multilingual benchmarks.
Mistral Nemotron
Mistral Nemotron is a preview large language model, jointly developed by Mistral AI and NVIDIA, released on June 11, 2025. Optimized by NVIDIA for inference using TensorRT-LLM and vLLM, it supports a massive 128K-token context window and is built for agentic workflows—excelling in instruction-following, function calling, and code generation—while delivering state-of-the-art performance across reasoning, math, coding, and multilingual benchmarks.
TrainKore
Trainkore is a versatile AI orchestration platform that automates prompt generation, model selection, and cost optimization across large language models (LLMs). The Model Router intelligently routes prompt requests to the best-priced or highest-performing model, achieving up to 85% cost savings. Users benefit from an auto-prompt generation playground, advanced settings, and seamless control—all through an intuitive UI. Ideal for teams managing multiple AI providers, Trainkore dramatically simplifies LLM workflows while improving efficiency and oversight.
TrainKore
Trainkore is a versatile AI orchestration platform that automates prompt generation, model selection, and cost optimization across large language models (LLMs). The Model Router intelligently routes prompt requests to the best-priced or highest-performing model, achieving up to 85% cost savings. Users benefit from an auto-prompt generation playground, advanced settings, and seamless control—all through an intuitive UI. Ideal for teams managing multiple AI providers, Trainkore dramatically simplifies LLM workflows while improving efficiency and oversight.
TrainKore
Trainkore is a versatile AI orchestration platform that automates prompt generation, model selection, and cost optimization across large language models (LLMs). The Model Router intelligently routes prompt requests to the best-priced or highest-performing model, achieving up to 85% cost savings. Users benefit from an auto-prompt generation playground, advanced settings, and seamless control—all through an intuitive UI. Ideal for teams managing multiple AI providers, Trainkore dramatically simplifies LLM workflows while improving efficiency and oversight.
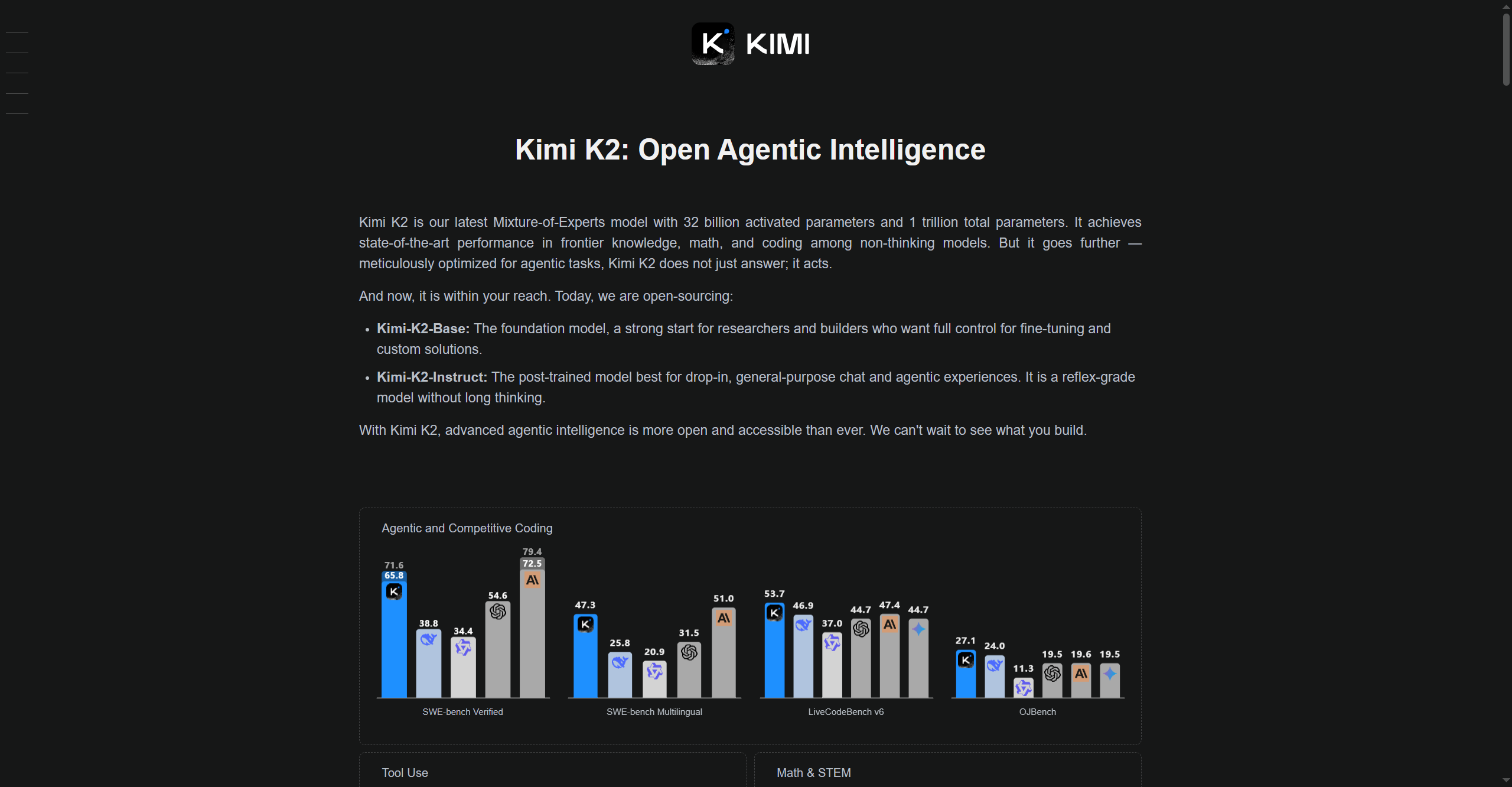

Kimi K2
Kimi-K2 is Moonshot AI’s advanced large language model (LLM) designed for high-speed reasoning, multi-modal understanding, and adaptable deployment across research, enterprise, and technical applications. Leveraging optimized architectures for efficiency and accuracy, Kimi-K2 excels in problem-solving, coding, knowledge retrieval, and interactive AI conversations. It is built to process complex real-world tasks, supporting both text and multi-modal inputs, and it provides customizable tools for experimentation and workflow automation.
Kimi K2
Kimi-K2 is Moonshot AI’s advanced large language model (LLM) designed for high-speed reasoning, multi-modal understanding, and adaptable deployment across research, enterprise, and technical applications. Leveraging optimized architectures for efficiency and accuracy, Kimi-K2 excels in problem-solving, coding, knowledge retrieval, and interactive AI conversations. It is built to process complex real-world tasks, supporting both text and multi-modal inputs, and it provides customizable tools for experimentation and workflow automation.
Kimi K2
Kimi-K2 is Moonshot AI’s advanced large language model (LLM) designed for high-speed reasoning, multi-modal understanding, and adaptable deployment across research, enterprise, and technical applications. Leveraging optimized architectures for efficiency and accuracy, Kimi-K2 excels in problem-solving, coding, knowledge retrieval, and interactive AI conversations. It is built to process complex real-world tasks, supporting both text and multi-modal inputs, and it provides customizable tools for experimentation and workflow automation.

Command R+ is Cohere’s latest state-of-the-art language model built for enterprise, optimized specifically for retrieval-augmented generation (RAG) workloads at scale. Available first on Microsoft Azure, Command R+ handles complex business data, integrates with secure infrastructure, and powers advanced AI workflows with fast, accurate responses. Designed for reliability, customization, and seamless deployment, it offers enterprises the ability to leverage cutting-edge generative and retrieval technologies across regulated industries.
Command R+ is Cohere’s latest state-of-the-art language model built for enterprise, optimized specifically for retrieval-augmented generation (RAG) workloads at scale. Available first on Microsoft Azure, Command R+ handles complex business data, integrates with secure infrastructure, and powers advanced AI workflows with fast, accurate responses. Designed for reliability, customization, and seamless deployment, it offers enterprises the ability to leverage cutting-edge generative and retrieval technologies across regulated industries.
Command R+ is Cohere’s latest state-of-the-art language model built for enterprise, optimized specifically for retrieval-augmented generation (RAG) workloads at scale. Available first on Microsoft Azure, Command R+ handles complex business data, integrates with secure infrastructure, and powers advanced AI workflows with fast, accurate responses. Designed for reliability, customization, and seamless deployment, it offers enterprises the ability to leverage cutting-edge generative and retrieval technologies across regulated industries.
Editorial Note
This page was researched and written by the ATB Editorial Team. Our team researches each AI tool by reviewing its official website, testing features, exploring real use cases, and considering user feedback. Every page is fact-checked and regularly updated to ensure the information stays accurate, neutral, and useful for our readers.
If you have any suggestions or questions, email us at hello@aitoolbook.ai