
- Machine Learning Developers: Deploy and showcase their models as interactive web applications.
- AI Researchers: Share demos of their research findings and models with the wider community.
- Data Scientists: Create interactive visualizations and tools for data analysis.
- Students & Educators: Learn about and experiment with various AI models and applications.
- Content Creators & Artists: Utilize generative AI models (e.g., text-to-image, music synthesis) for creative projects.
- Businesses & Startups: Rapidly prototype and demonstrate AI solutions to potential users or clients.
- Interactive ML Demos: Enables the creation and hosting of interactive web demos for machine learning models, making AI tangible.
- Multiple SDK Support: Supports Gradio and Streamlit for rapid UI development, along with Docker for custom environments.
- Git-based Version Control: Facilitates collaborative development with out-of-the-box Git-based workflows.
- Optimized ML Infrastructure: Applications run on Hugging Face's optimized ML infrastructure, with options for GPU acceleration (including ZeroGPU).
- Vast Model Hub Integration: Seamlessly integrates with the Hugging Face Model Hub, allowing easy use of thousands of pre-trained models.
- Community-Driven Ecosystem: A thriving community shares models, datasets, and Spaces, fostering collaboration and innovation.
- Accessibility: Democratizes access to complex ML models by providing user-friendly interfaces for interaction.
- Free Hosting for Public Demos: Encourages open-source contribution and experimentation.
- Ease of Deployment: Simplifies the process of deploying ML models into web applications.
- Rich Ecosystem: Access to a vast collection of models and datasets from the Hugging Face Hub.
- Supports Popular Frameworks: Compatibility with Gradio and Streamlit for quick UI development.
- Collaboration Features: Git integration allows for easy team collaboration on projects.
- Community Support: A strong and active community provides resources and assistance.
- Learning Curve for Beginners: Requires some prior ML and programming knowledge for building custom Spaces.
- Resource Demands for Complex Models: Larger or more complex models may require paid hardware options.
- Limited Customization in Free Tier: Advanced features or higher computational resources come with paid plans.
- Internet Dependency: Requires a stable internet connection for accessing and interacting with Spaces.
- Debugging Can Be Tricky: Troubleshooting issues within the deployed Space can sometimes be less straightforward than local development.




Pro
$ 9.00
Enterprise Hub
$20 per user
Proud of the love you're getting? Show off your AI Toolbook reviews—then invite more fans to share the love and build your credibility.
Add an AI Toolbook badge to your site—an easy way to drive followers, showcase updates, and collect reviews. It's like a mini 24/7 billboard for your AI.
Reviews
Rating Distribution
Average score
Popular Mention
FAQs
Similar AI Tools

Radal AI
Radal AI is a no-code platform designed to simplify the training and deployment of small language models (SLMs) without requiring engineering or MLOps expertise. With an intuitive visual interface, you can drag your data, interact with an AI copilot, and train models with a single click. Trained models can be exported in quantized form for edge or local deployment, and seamlessly pushed to Hugging Face for easy sharing and versioning. Radal enables rapid iteration on custom models—making AI accessible to startups, researchers, and teams building domain-specific intelligence.
Radal AI
Radal AI is a no-code platform designed to simplify the training and deployment of small language models (SLMs) without requiring engineering or MLOps expertise. With an intuitive visual interface, you can drag your data, interact with an AI copilot, and train models with a single click. Trained models can be exported in quantized form for edge or local deployment, and seamlessly pushed to Hugging Face for easy sharing and versioning. Radal enables rapid iteration on custom models—making AI accessible to startups, researchers, and teams building domain-specific intelligence.
Radal AI
Radal AI is a no-code platform designed to simplify the training and deployment of small language models (SLMs) without requiring engineering or MLOps expertise. With an intuitive visual interface, you can drag your data, interact with an AI copilot, and train models with a single click. Trained models can be exported in quantized form for edge or local deployment, and seamlessly pushed to Hugging Face for easy sharing and versioning. Radal enables rapid iteration on custom models—making AI accessible to startups, researchers, and teams building domain-specific intelligence.
Langchain
LangChain is a powerful open-source framework designed to help developers build context-aware applications that leverage large language models (LLMs). It allows users to connect language models to various data sources, APIs, and memory components, enabling intelligent, multi-step reasoning and decision-making processes. LangChain supports both Python and JavaScript, providing modular building blocks for developers to create chatbots, AI assistants, retrieval-augmented generation (RAG) systems, and agent-based tools. The framework is widely adopted across industries for its flexibility in connecting structured and unstructured data with LLMs.
Langchain
LangChain is a powerful open-source framework designed to help developers build context-aware applications that leverage large language models (LLMs). It allows users to connect language models to various data sources, APIs, and memory components, enabling intelligent, multi-step reasoning and decision-making processes. LangChain supports both Python and JavaScript, providing modular building blocks for developers to create chatbots, AI assistants, retrieval-augmented generation (RAG) systems, and agent-based tools. The framework is widely adopted across industries for its flexibility in connecting structured and unstructured data with LLMs.
Langchain
LangChain is a powerful open-source framework designed to help developers build context-aware applications that leverage large language models (LLMs). It allows users to connect language models to various data sources, APIs, and memory components, enabling intelligent, multi-step reasoning and decision-making processes. LangChain supports both Python and JavaScript, providing modular building blocks for developers to create chatbots, AI assistants, retrieval-augmented generation (RAG) systems, and agent-based tools. The framework is widely adopted across industries for its flexibility in connecting structured and unstructured data with LLMs.

Prompts AI
Prompts.ai is an enterprise-grade AI platform designed to streamline, optimize, and govern generative AI workflows and prompt engineering across organizations. It centralizes access to over 35 large language models (LLMs) and AI tools, allowing teams to automate repetitive workflows, reduce costs, and boost productivity by up to 10 times. The platform emphasizes data security and compliance with standards such as SOC 2 Type II, HIPAA, and GDPR. It supports enterprises in building custom AI workflows, ensuring full visibility, auditability, and governance of AI interactions. Additionally, Prompts.ai fosters collaboration by providing a shared library of expert-built prompts and workflows, enabling businesses to scale AI adoption efficiently and securely.
Prompts AI
Prompts.ai is an enterprise-grade AI platform designed to streamline, optimize, and govern generative AI workflows and prompt engineering across organizations. It centralizes access to over 35 large language models (LLMs) and AI tools, allowing teams to automate repetitive workflows, reduce costs, and boost productivity by up to 10 times. The platform emphasizes data security and compliance with standards such as SOC 2 Type II, HIPAA, and GDPR. It supports enterprises in building custom AI workflows, ensuring full visibility, auditability, and governance of AI interactions. Additionally, Prompts.ai fosters collaboration by providing a shared library of expert-built prompts and workflows, enabling businesses to scale AI adoption efficiently and securely.
Prompts AI
Prompts.ai is an enterprise-grade AI platform designed to streamline, optimize, and govern generative AI workflows and prompt engineering across organizations. It centralizes access to over 35 large language models (LLMs) and AI tools, allowing teams to automate repetitive workflows, reduce costs, and boost productivity by up to 10 times. The platform emphasizes data security and compliance with standards such as SOC 2 Type II, HIPAA, and GDPR. It supports enterprises in building custom AI workflows, ensuring full visibility, auditability, and governance of AI interactions. Additionally, Prompts.ai fosters collaboration by providing a shared library of expert-built prompts and workflows, enabling businesses to scale AI adoption efficiently and securely.

Awan LLM
Awan LLM is a cost-effective, unlimited token large language model inference API platform designed for power users and developers. Unlike traditional API providers that charge per token, Awan LLM offers a monthly subscription model that enables users to send and receive unlimited tokens up to the model's context limit. It supports unrestricted use of LLM models without censorship or constraints. The platform is built on privately owned data centers and GPUs, allowing it to offer efficient and scalable AI services. Awan LLM supports numerous use cases including AI assistants, AI agents, roleplaying, data processing, code completion, and building AI-powered applications without worrying about token limits or costs.
Awan LLM
Awan LLM is a cost-effective, unlimited token large language model inference API platform designed for power users and developers. Unlike traditional API providers that charge per token, Awan LLM offers a monthly subscription model that enables users to send and receive unlimited tokens up to the model's context limit. It supports unrestricted use of LLM models without censorship or constraints. The platform is built on privately owned data centers and GPUs, allowing it to offer efficient and scalable AI services. Awan LLM supports numerous use cases including AI assistants, AI agents, roleplaying, data processing, code completion, and building AI-powered applications without worrying about token limits or costs.
Awan LLM
Awan LLM is a cost-effective, unlimited token large language model inference API platform designed for power users and developers. Unlike traditional API providers that charge per token, Awan LLM offers a monthly subscription model that enables users to send and receive unlimited tokens up to the model's context limit. It supports unrestricted use of LLM models without censorship or constraints. The platform is built on privately owned data centers and GPUs, allowing it to offer efficient and scalable AI services. Awan LLM supports numerous use cases including AI assistants, AI agents, roleplaying, data processing, code completion, and building AI-powered applications without worrying about token limits or costs.
Gud prompt
GudPrompt is an AI-powered prompt engineering and workflow automation platform designed for teams and creators who want to build, organize, and optimize their AI prompts. It allows users to create prompt libraries, version prompts, collaborate with teammates, and run complex multi-step AI workflows. With its prompt templates, testing tools, and multi-model support, GudPrompt helps users generate consistent, high-quality AI outputs across various applications.
Gud prompt
GudPrompt is an AI-powered prompt engineering and workflow automation platform designed for teams and creators who want to build, organize, and optimize their AI prompts. It allows users to create prompt libraries, version prompts, collaborate with teammates, and run complex multi-step AI workflows. With its prompt templates, testing tools, and multi-model support, GudPrompt helps users generate consistent, high-quality AI outputs across various applications.
Gud prompt
GudPrompt is an AI-powered prompt engineering and workflow automation platform designed for teams and creators who want to build, organize, and optimize their AI prompts. It allows users to create prompt libraries, version prompts, collaborate with teammates, and run complex multi-step AI workflows. With its prompt templates, testing tools, and multi-model support, GudPrompt helps users generate consistent, high-quality AI outputs across various applications.
Convolut
Convolut is a smart platform called ConAir that acts as a central hub for managing, organizing, and streaming context snippets to Large Language Models and AI agents. It lets users store knowledge bases, retrieve info quickly, and export data to supercharge AI interactions with relevant context. Perfect for developers and teams, it handles everything from basic storage to advanced organization, making AI responses more accurate and nuanced by feeding in the right details every time. Teams love how it streamlines workflows, cuts down on manual data hunting, and boosts AI performance across projects.
Convolut
Convolut is a smart platform called ConAir that acts as a central hub for managing, organizing, and streaming context snippets to Large Language Models and AI agents. It lets users store knowledge bases, retrieve info quickly, and export data to supercharge AI interactions with relevant context. Perfect for developers and teams, it handles everything from basic storage to advanced organization, making AI responses more accurate and nuanced by feeding in the right details every time. Teams love how it streamlines workflows, cuts down on manual data hunting, and boosts AI performance across projects.
Convolut
Convolut is a smart platform called ConAir that acts as a central hub for managing, organizing, and streaming context snippets to Large Language Models and AI agents. It lets users store knowledge bases, retrieve info quickly, and export data to supercharge AI interactions with relevant context. Perfect for developers and teams, it handles everything from basic storage to advanced organization, making AI responses more accurate and nuanced by feeding in the right details every time. Teams love how it streamlines workflows, cuts down on manual data hunting, and boosts AI performance across projects.
Langdock
Langdock is an enterprise-ready AI platform that allows organizations to deploy AI securely across all employees while giving developers the tools to build and customize advanced AI workflows. It centralizes AI access, policy controls, and workflow automation into one system, making corporate AI adoption organized and compliant. Langdock supports custom workflows, integrations, and internal tools, ensuring that teams across departments can use AI productively while maintaining governance and security. It is designed for full organizational rollout—from individual employees to technical developer teams.
Langdock
Langdock is an enterprise-ready AI platform that allows organizations to deploy AI securely across all employees while giving developers the tools to build and customize advanced AI workflows. It centralizes AI access, policy controls, and workflow automation into one system, making corporate AI adoption organized and compliant. Langdock supports custom workflows, integrations, and internal tools, ensuring that teams across departments can use AI productively while maintaining governance and security. It is designed for full organizational rollout—from individual employees to technical developer teams.
Langdock
Langdock is an enterprise-ready AI platform that allows organizations to deploy AI securely across all employees while giving developers the tools to build and customize advanced AI workflows. It centralizes AI access, policy controls, and workflow automation into one system, making corporate AI adoption organized and compliant. Langdock supports custom workflows, integrations, and internal tools, ensuring that teams across departments can use AI productively while maintaining governance and security. It is designed for full organizational rollout—from individual employees to technical developer teams.
ModelRiver
ModelRiver is a unified AI integration platform that allows developers to access multiple AI providers through a single API. Instead of integrating each model separately, teams integrate once and gain access to a wide range of AI services. Built-in failover ensures applications remain online even if one provider experiences issues. ModelRiver is designed for reliability, scalability, and simplicity, making it ideal for production environments that depend on AI availability.
ModelRiver
ModelRiver is a unified AI integration platform that allows developers to access multiple AI providers through a single API. Instead of integrating each model separately, teams integrate once and gain access to a wide range of AI services. Built-in failover ensures applications remain online even if one provider experiences issues. ModelRiver is designed for reliability, scalability, and simplicity, making it ideal for production environments that depend on AI availability.
ModelRiver
ModelRiver is a unified AI integration platform that allows developers to access multiple AI providers through a single API. Instead of integrating each model separately, teams integrate once and gain access to a wide range of AI services. Built-in failover ensures applications remain online even if one provider experiences issues. ModelRiver is designed for reliability, scalability, and simplicity, making it ideal for production environments that depend on AI availability.
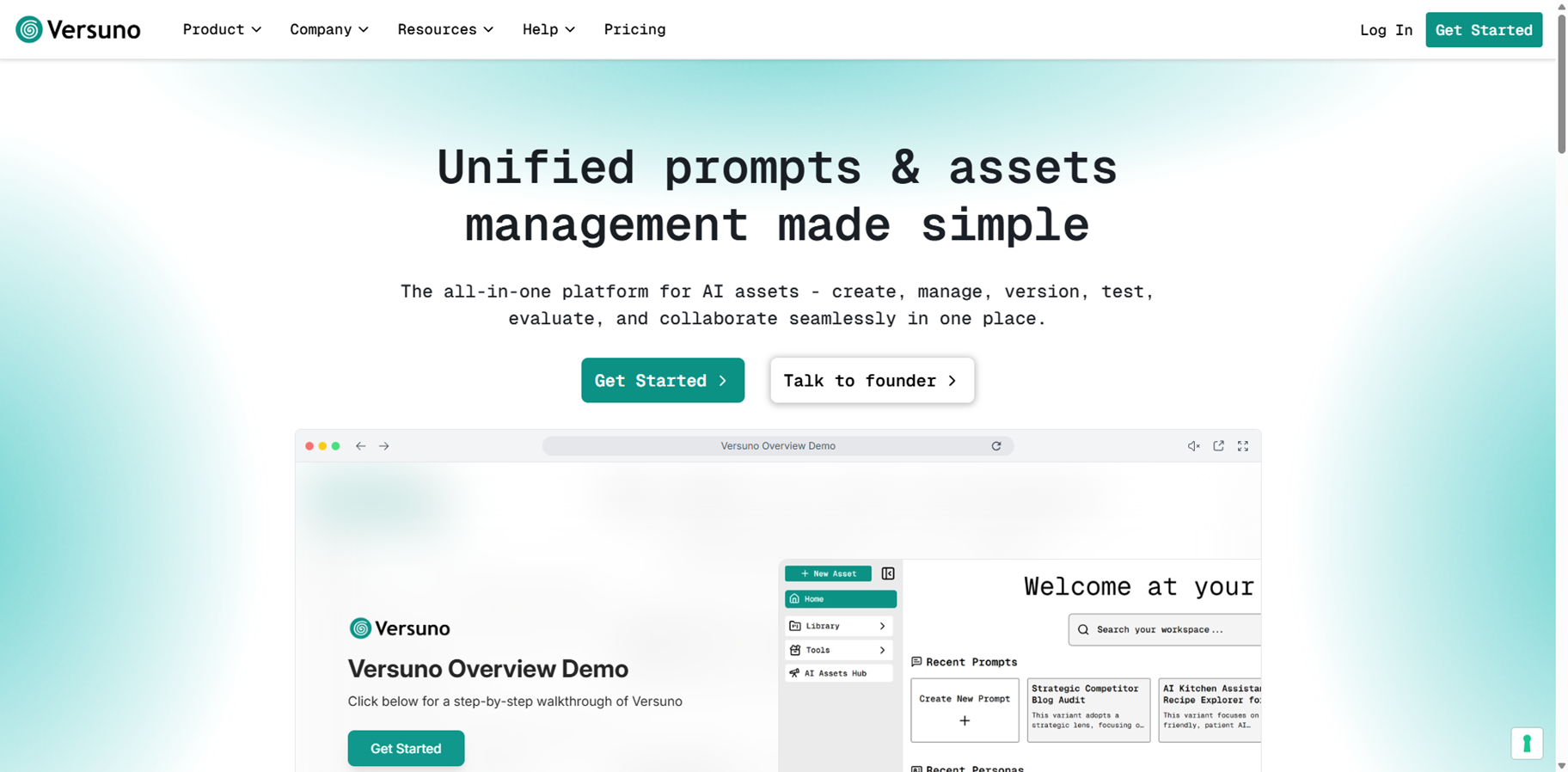

Versuno
Versuno is an all-in-one AI platform for managing prompts, personas, system prompts, contexts, and knowledge bases in a unified, searchable workspace. It lets users create, version like GitHub, test across 50+ models from OpenAI, Anthropic, and Google, evaluate performance, and collaborate seamlessly. With a built-in Prompt Engineer named Sage for co-creation and an AI Assets Hub for community sharing, it eliminates scattered notes and recreations, saving 5+ hours weekly. Perfect for individuals, prompt engineers, and teams optimizing AI workflows data-driven.
Versuno
Versuno is an all-in-one AI platform for managing prompts, personas, system prompts, contexts, and knowledge bases in a unified, searchable workspace. It lets users create, version like GitHub, test across 50+ models from OpenAI, Anthropic, and Google, evaluate performance, and collaborate seamlessly. With a built-in Prompt Engineer named Sage for co-creation and an AI Assets Hub for community sharing, it eliminates scattered notes and recreations, saving 5+ hours weekly. Perfect for individuals, prompt engineers, and teams optimizing AI workflows data-driven.
Versuno
Versuno is an all-in-one AI platform for managing prompts, personas, system prompts, contexts, and knowledge bases in a unified, searchable workspace. It lets users create, version like GitHub, test across 50+ models from OpenAI, Anthropic, and Google, evaluate performance, and collaborate seamlessly. With a built-in Prompt Engineer named Sage for co-creation and an AI Assets Hub for community sharing, it eliminates scattered notes and recreations, saving 5+ hours weekly. Perfect for individuals, prompt engineers, and teams optimizing AI workflows data-driven.
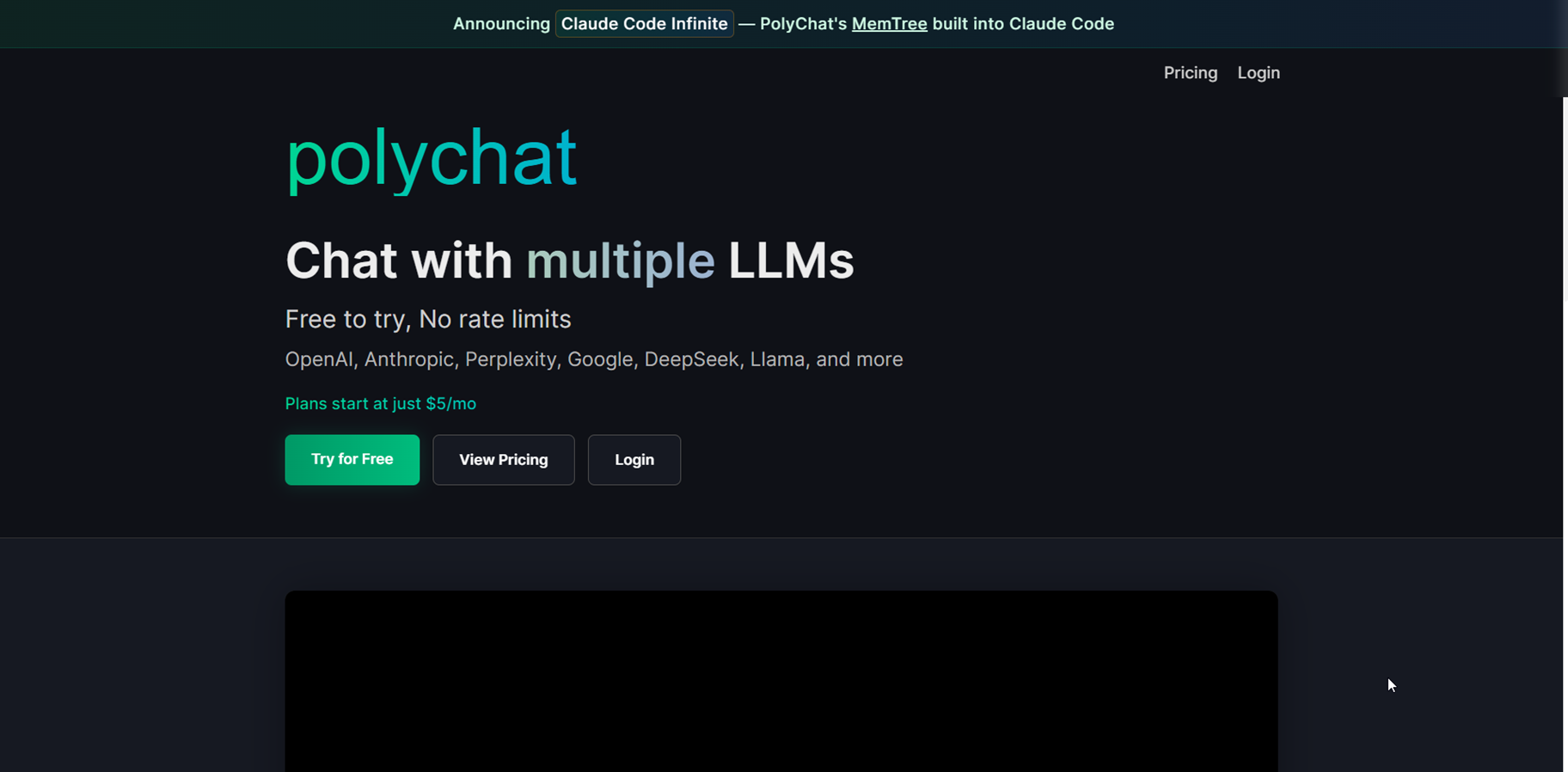

polychat
polychat is a multi-LLM chat platform that lets you interact with numerous AI models like OpenAI, Anthropic, Perplexity, Google, DeepSeek, Llama, and others in one interface, with free trials and no rate limits. Switch between models seamlessly for the best responses to your queries, whether coding, writing, or research, all at affordable plans starting $5/month. It's designed for power users wanting flexibility without juggling multiple apps or hitting usage caps quickly.
polychat
polychat is a multi-LLM chat platform that lets you interact with numerous AI models like OpenAI, Anthropic, Perplexity, Google, DeepSeek, Llama, and others in one interface, with free trials and no rate limits. Switch between models seamlessly for the best responses to your queries, whether coding, writing, or research, all at affordable plans starting $5/month. It's designed for power users wanting flexibility without juggling multiple apps or hitting usage caps quickly.
polychat
polychat is a multi-LLM chat platform that lets you interact with numerous AI models like OpenAI, Anthropic, Perplexity, Google, DeepSeek, Llama, and others in one interface, with free trials and no rate limits. Switch between models seamlessly for the best responses to your queries, whether coding, writing, or research, all at affordable plans starting $5/month. It's designed for power users wanting flexibility without juggling multiple apps or hitting usage caps quickly.
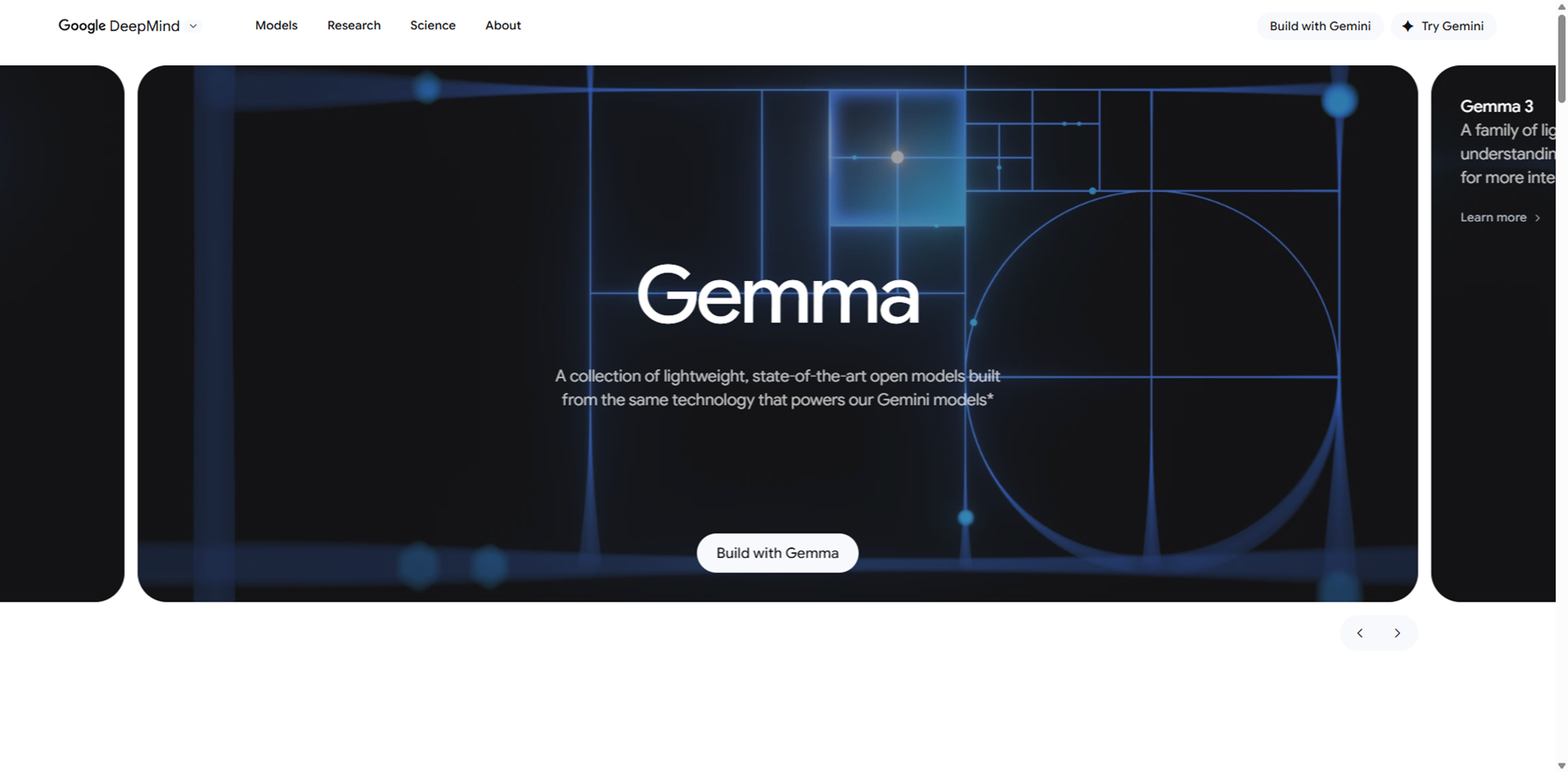

Gemma
Gemma is a family of lightweight, state-of-the-art open models from Google DeepMind, built using the same research and technology that powers the Gemini models. Available in sizes from 270M to 27B parameters, they support multimodal understanding with text, image, video, and audio inputs while generating text outputs, alongside strong multilingual capabilities across over 140 languages. Specialized variants like CodeGemma for coding, PaliGemma for vision-language tasks, ShieldGemma for safety classification, MedGemma for medical imaging and text, and mobile-optimized Gemma 3n enable developers to create efficient AI apps that run on devices from phones to servers. These models excel in tasks like summarization, question answering, reasoning, code generation, and translation, with tools for fine-tuning and deployment.
Gemma
Gemma is a family of lightweight, state-of-the-art open models from Google DeepMind, built using the same research and technology that powers the Gemini models. Available in sizes from 270M to 27B parameters, they support multimodal understanding with text, image, video, and audio inputs while generating text outputs, alongside strong multilingual capabilities across over 140 languages. Specialized variants like CodeGemma for coding, PaliGemma for vision-language tasks, ShieldGemma for safety classification, MedGemma for medical imaging and text, and mobile-optimized Gemma 3n enable developers to create efficient AI apps that run on devices from phones to servers. These models excel in tasks like summarization, question answering, reasoning, code generation, and translation, with tools for fine-tuning and deployment.
Gemma
Gemma is a family of lightweight, state-of-the-art open models from Google DeepMind, built using the same research and technology that powers the Gemini models. Available in sizes from 270M to 27B parameters, they support multimodal understanding with text, image, video, and audio inputs while generating text outputs, alongside strong multilingual capabilities across over 140 languages. Specialized variants like CodeGemma for coding, PaliGemma for vision-language tasks, ShieldGemma for safety classification, MedGemma for medical imaging and text, and mobile-optimized Gemma 3n enable developers to create efficient AI apps that run on devices from phones to servers. These models excel in tasks like summarization, question answering, reasoning, code generation, and translation, with tools for fine-tuning and deployment.
Editorial Note
This page was researched and written by the ATB Editorial Team. Our team researches each AI tool by reviewing its official website, testing features, exploring real use cases, and considering user feedback. Every page is fact-checked and regularly updated to ensure the information stays accurate, neutral, and useful for our readers.
If you have any suggestions or questions, email us at hello@aitoolbook.ai