
- Fans of Science Fiction & "Hitchhiker's Guide": Individuals who appreciate the specific theme, humor, and references from the popular sci-fi series.
- Curious Minds & Learners: Users interested in exploring categorized knowledge about topics like galactic travel, alien species, planet profiles, technology, and survival tips.
- Interactive AI Enthusiasts: Those who enjoy engaging with AI tools, especially ones with unique interfaces and thematic presentations.
- Casual Users Seeking Entertainment: Anyone looking for a fun, nostalgic, and informative digital experience.
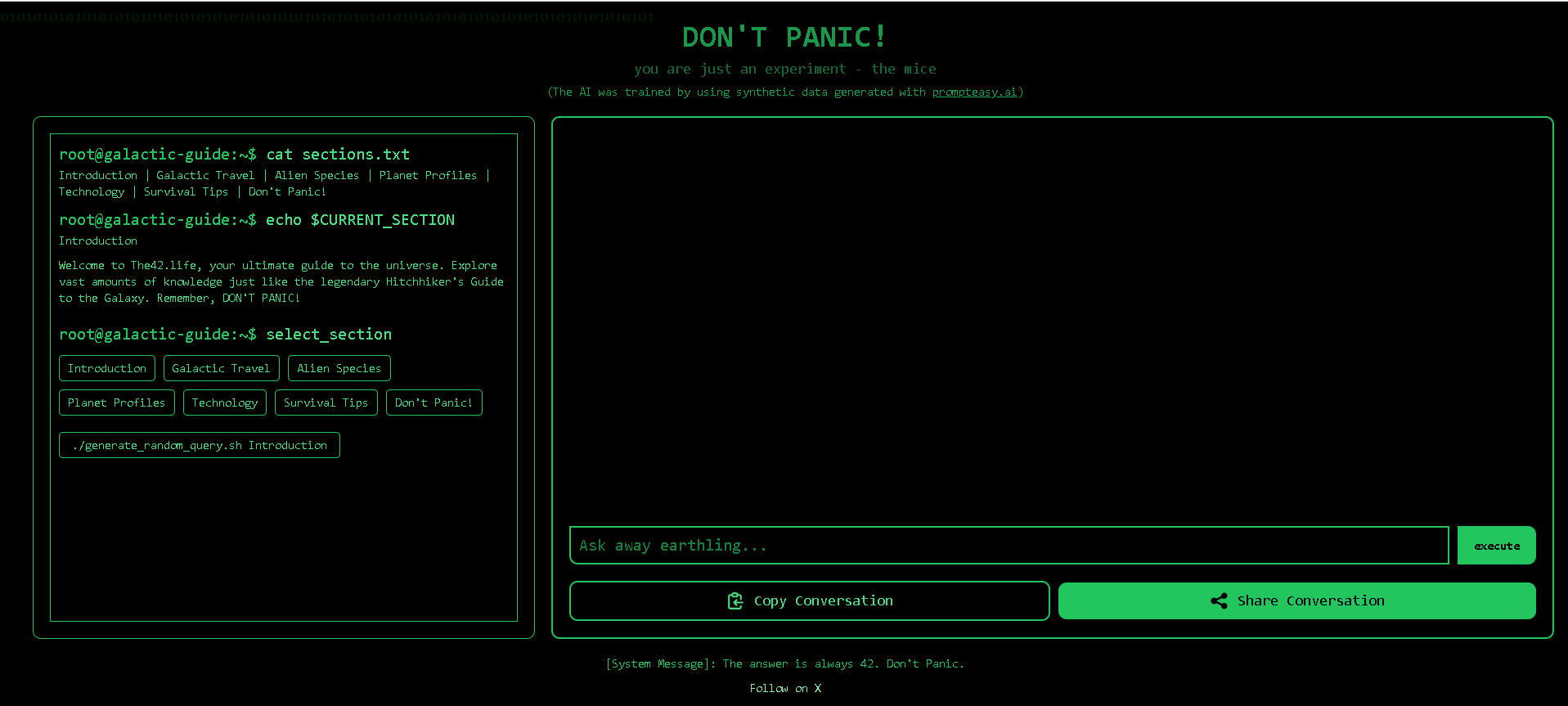
How to Use The42.life (The "DON'T PANIC!" Galactic Guide AI)?
- Select a Knowledge Section: Choose from predefined categories such as "Introduction," "Galactic Travel," "Alien Species," "Planet Profiles," "Technology," "Survival Tips," or "Don't Panic!".
- Input Your Query: Type your question or command into the designated "Ask away earthling..." text field.
- Execute Your Command: Click the "execute" button to prompt the AI to process your input and provide a response.
- Generate Random Information: Utilize the ./generaterandomquery.sh button to discover random snippets of knowledge.
- Manage Conversation: Use the "Copy Conversation" and "Share Conversation" buttons to save or share your interactions.
- Immersive Sci-Fi Theme: Fully embraces the aesthetic and philosophical humor of "The Hitchhiker's Guide to the Galaxy," from its "DON'T PANIC!" title to "The answer is always 42" system messages.
- Interactive CLI-like Interface: Provides a visually distinct and engaging user experience that simulates a command-line environment.
- AI Powered by Synthetic Data: Explicitly highlights its training using synthetic data from gemstory.ai, indicating a modern AI approach.
- Structured Galactic Knowledge: Organizes a wide array of information into specific, themed sections for easy navigation and exploration.
- Direct Association with The42.life: Presented as "The42.life, your ultimate guide to the universe," cementing its identity.
- Conversation Sharing Features: Facilitates user engagement by allowing easy sharing and copying of generated responses.
- Highly Engaging Theme: A well-executed and nostalgic tribute to classic science fiction.
- Unique CLI-style Interface: Offers a distinctive and visually appealing way to interact with an AI.
- Structured Information Categories: Helps users explore specific areas of "galactic" knowledge efficiently.
- AI Training Transparency: Mentions gemstory.ai as the source of its synthetic training data.
- Built-in Conversation Sharing: Convenient for users to share interesting outputs or discoveries.
- Limited Scope: Thematic nature might limit its utility as a general-purpose AI beyond its "galactic guide" role.
- "Experiment" Tag: The "you are just an experiment" tagline might imply ongoing development or potential instability.
- Reliance on Text Input: Interaction is solely text-based, lacking voice commands or more dynamic UI elements.
- Ambiguity of Depth: The actual depth and comprehensiveness of information within each section are not fully clear from the interface.
- Potential for Thematic Constraints: Responses might sometimes be constrained by the theme, even for general questions.
Paid
custom
Proud of the love you're getting? Show off your AI Toolbook reviews—then invite more fans to share the love and build your credibility.
Add an AI Toolbook badge to your site—an easy way to drive followers, showcase updates, and collect reviews. It's like a mini 24/7 billboard for your AI.
Reviews
Rating Distribution
Average score
Popular Mention
FAQs
Similar AI Tools
BeFreed
BeFreed.ai is an AI-powered knowledge agent designed to revolutionize how individuals acquire and interact with knowledge. Its core purpose is to make humanity "smarter, effortlessly" by transforming lengthy content, particularly books, into high-quality, bite-sized summaries and personalized learning experiences. It uses advanced AI and large language models (LLMs) to distill information while preserving depth and quality, adapting to user preferences and learning styles.
BeFreed
BeFreed.ai is an AI-powered knowledge agent designed to revolutionize how individuals acquire and interact with knowledge. Its core purpose is to make humanity "smarter, effortlessly" by transforming lengthy content, particularly books, into high-quality, bite-sized summaries and personalized learning experiences. It uses advanced AI and large language models (LLMs) to distill information while preserving depth and quality, adapting to user preferences and learning styles.
BeFreed
BeFreed.ai is an AI-powered knowledge agent designed to revolutionize how individuals acquire and interact with knowledge. Its core purpose is to make humanity "smarter, effortlessly" by transforming lengthy content, particularly books, into high-quality, bite-sized summaries and personalized learning experiences. It uses advanced AI and large language models (LLMs) to distill information while preserving depth and quality, adapting to user preferences and learning styles.
Chat 01 AI
Chat01.ai is a platform that offers free and unlimited chat with OpenAI 01, a new series of AI models. These models are specifically designed for complex reasoning and problem-solving in areas such as science, coding, and math, by employing a "think more before responding" approach, trying different strategies, and recognizing mistakes.
Chat 01 AI
Chat01.ai is a platform that offers free and unlimited chat with OpenAI 01, a new series of AI models. These models are specifically designed for complex reasoning and problem-solving in areas such as science, coding, and math, by employing a "think more before responding" approach, trying different strategies, and recognizing mistakes.
Chat 01 AI
Chat01.ai is a platform that offers free and unlimited chat with OpenAI 01, a new series of AI models. These models are specifically designed for complex reasoning and problem-solving in areas such as science, coding, and math, by employing a "think more before responding" approach, trying different strategies, and recognizing mistakes.

LM Arena
LMArena is a platform designed to allow users to contribute to the development of AI through collective feedback. Users interact with and provide feedback on various Large Language Models (LLMs) by voting on their responses, thereby helping to shape and improve AI capabilities. The platform fosters a global community and features a leaderboard to showcase user contributions.
LM Arena
LMArena is a platform designed to allow users to contribute to the development of AI through collective feedback. Users interact with and provide feedback on various Large Language Models (LLMs) by voting on their responses, thereby helping to shape and improve AI capabilities. The platform fosters a global community and features a leaderboard to showcase user contributions.
LM Arena
LMArena is a platform designed to allow users to contribute to the development of AI through collective feedback. Users interact with and provide feedback on various Large Language Models (LLMs) by voting on their responses, thereby helping to shape and improve AI capabilities. The platform fosters a global community and features a leaderboard to showcase user contributions.
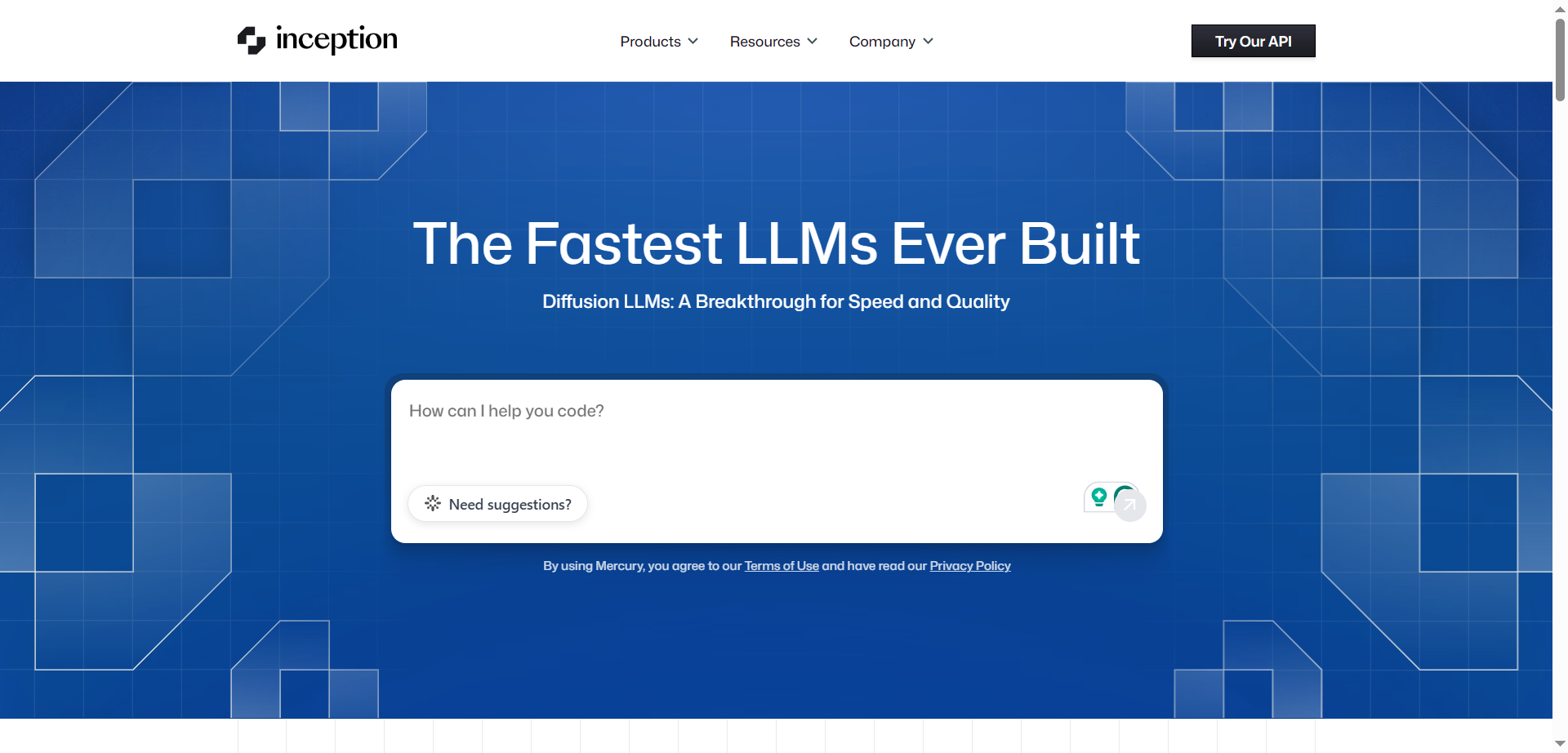

inception
Inception Labs is an AI research company that develops Mercury, the world's first commercial diffusion-based large language models. Unlike traditional autoregressive LLMs that generate tokens sequentially, Mercury models use diffusion architecture to generate text through parallel refinement passes. This breakthrough approach enables ultra-fast inference speeds of over 1,000 tokens per second while maintaining frontier-level quality. The platform offers Mercury for general-purpose tasks and Mercury Coder for development workflows, both featuring streaming capabilities, tool use, structured output, and 128K context windows. These models serve as drop-in replacements for traditional LLMs through OpenAI-compatible APIs and are available across major cloud providers including AWS Bedrock, Azure Foundry, and various AI platforms for enterprise deployment.
inception
Inception Labs is an AI research company that develops Mercury, the world's first commercial diffusion-based large language models. Unlike traditional autoregressive LLMs that generate tokens sequentially, Mercury models use diffusion architecture to generate text through parallel refinement passes. This breakthrough approach enables ultra-fast inference speeds of over 1,000 tokens per second while maintaining frontier-level quality. The platform offers Mercury for general-purpose tasks and Mercury Coder for development workflows, both featuring streaming capabilities, tool use, structured output, and 128K context windows. These models serve as drop-in replacements for traditional LLMs through OpenAI-compatible APIs and are available across major cloud providers including AWS Bedrock, Azure Foundry, and various AI platforms for enterprise deployment.
inception
Inception Labs is an AI research company that develops Mercury, the world's first commercial diffusion-based large language models. Unlike traditional autoregressive LLMs that generate tokens sequentially, Mercury models use diffusion architecture to generate text through parallel refinement passes. This breakthrough approach enables ultra-fast inference speeds of over 1,000 tokens per second while maintaining frontier-level quality. The platform offers Mercury for general-purpose tasks and Mercury Coder for development workflows, both featuring streaming capabilities, tool use, structured output, and 128K context windows. These models serve as drop-in replacements for traditional LLMs through OpenAI-compatible APIs and are available across major cloud providers including AWS Bedrock, Azure Foundry, and various AI platforms for enterprise deployment.
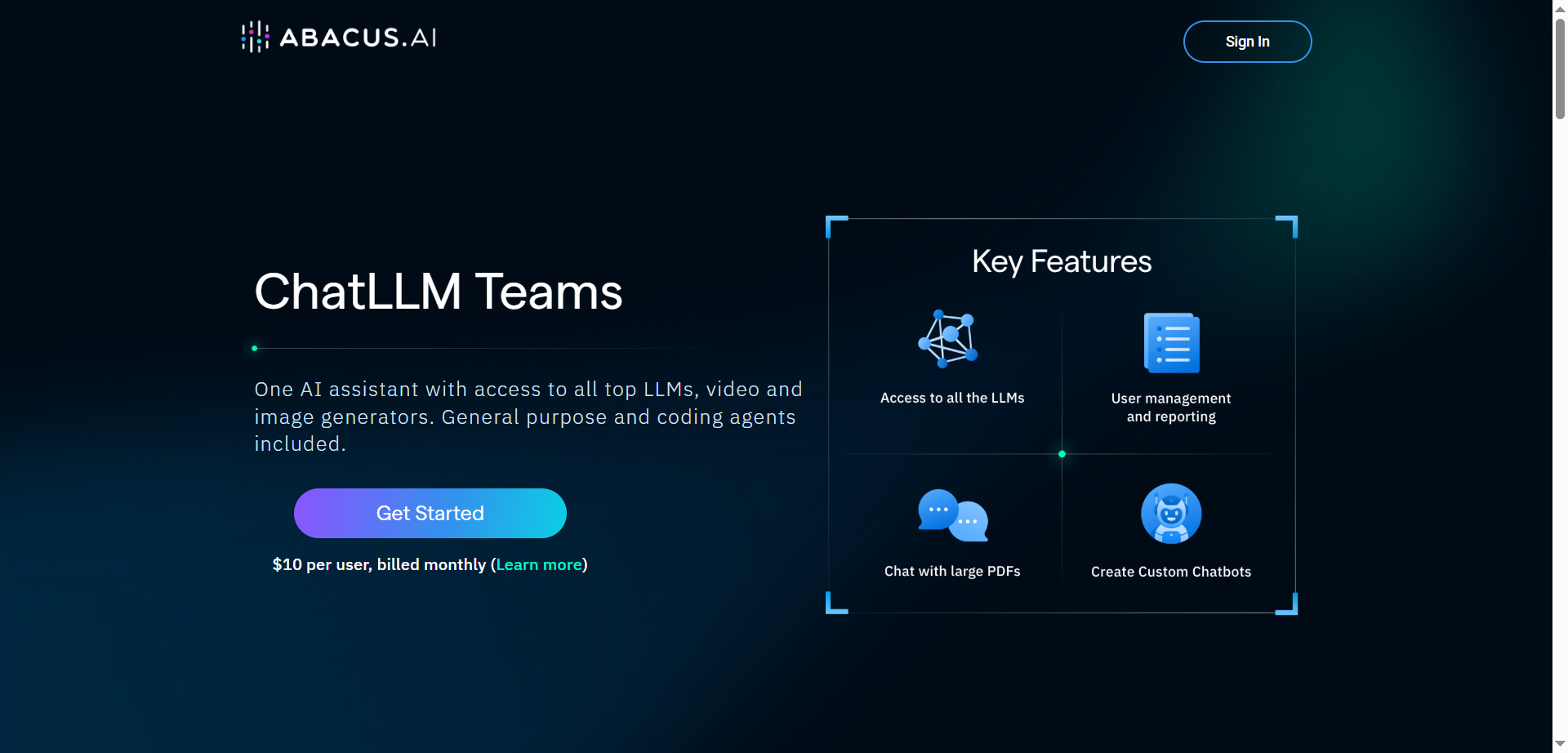

Abacus.AI
ChatLLM Teams by Abacus.AI is an all‑in‑one AI assistant that unifies access to top LLMs, image and video generators, and powerful agentic tools in a single workspace. It includes DeepAgent for complex, multi‑step tasks, code execution with an editor, document/chat with files, web search, TTS, and slide/doc generation. Users can build custom chatbots, set up AI workflows, generate images and videos from multiple models, and organize work with projects across desktop and mobile apps. The platform is OpenAI‑style in usability but adds operator features for running tasks on a computer, plus DeepAgent Desktop and AppLLM for building and hosting small apps.
Abacus.AI
ChatLLM Teams by Abacus.AI is an all‑in‑one AI assistant that unifies access to top LLMs, image and video generators, and powerful agentic tools in a single workspace. It includes DeepAgent for complex, multi‑step tasks, code execution with an editor, document/chat with files, web search, TTS, and slide/doc generation. Users can build custom chatbots, set up AI workflows, generate images and videos from multiple models, and organize work with projects across desktop and mobile apps. The platform is OpenAI‑style in usability but adds operator features for running tasks on a computer, plus DeepAgent Desktop and AppLLM for building and hosting small apps.
Abacus.AI
ChatLLM Teams by Abacus.AI is an all‑in‑one AI assistant that unifies access to top LLMs, image and video generators, and powerful agentic tools in a single workspace. It includes DeepAgent for complex, multi‑step tasks, code execution with an editor, document/chat with files, web search, TTS, and slide/doc generation. Users can build custom chatbots, set up AI workflows, generate images and videos from multiple models, and organize work with projects across desktop and mobile apps. The platform is OpenAI‑style in usability but adds operator features for running tasks on a computer, plus DeepAgent Desktop and AppLLM for building and hosting small apps.


TextCortex
TextCortex is an enterprise-grade AI platform that helps organizations deploy secure, task-specific AI agents powered by internal knowledge and leading LLMs. It centralizes knowledge with collaborative management, retrieval-augmented generation for precise answers, and robust governance to keep data private and compliant. Teams work across 30,000+ apps via a browser extension, desktop app, and integrations, avoiding context switching. The platform enables end-to-end content and knowledge lifecycles, from drafting proposals and analyses to search and insights, with multilingual support for global teams. Built on EU-hosted, GDPR-compliant infrastructure and strict no-training-on-user-data policies, it balances flexibility, performance, and enterprise trust.
TextCortex
TextCortex is an enterprise-grade AI platform that helps organizations deploy secure, task-specific AI agents powered by internal knowledge and leading LLMs. It centralizes knowledge with collaborative management, retrieval-augmented generation for precise answers, and robust governance to keep data private and compliant. Teams work across 30,000+ apps via a browser extension, desktop app, and integrations, avoiding context switching. The platform enables end-to-end content and knowledge lifecycles, from drafting proposals and analyses to search and insights, with multilingual support for global teams. Built on EU-hosted, GDPR-compliant infrastructure and strict no-training-on-user-data policies, it balances flexibility, performance, and enterprise trust.
TextCortex
TextCortex is an enterprise-grade AI platform that helps organizations deploy secure, task-specific AI agents powered by internal knowledge and leading LLMs. It centralizes knowledge with collaborative management, retrieval-augmented generation for precise answers, and robust governance to keep data private and compliant. Teams work across 30,000+ apps via a browser extension, desktop app, and integrations, avoiding context switching. The platform enables end-to-end content and knowledge lifecycles, from drafting proposals and analyses to search and insights, with multilingual support for global teams. Built on EU-hosted, GDPR-compliant infrastructure and strict no-training-on-user-data policies, it balances flexibility, performance, and enterprise trust.
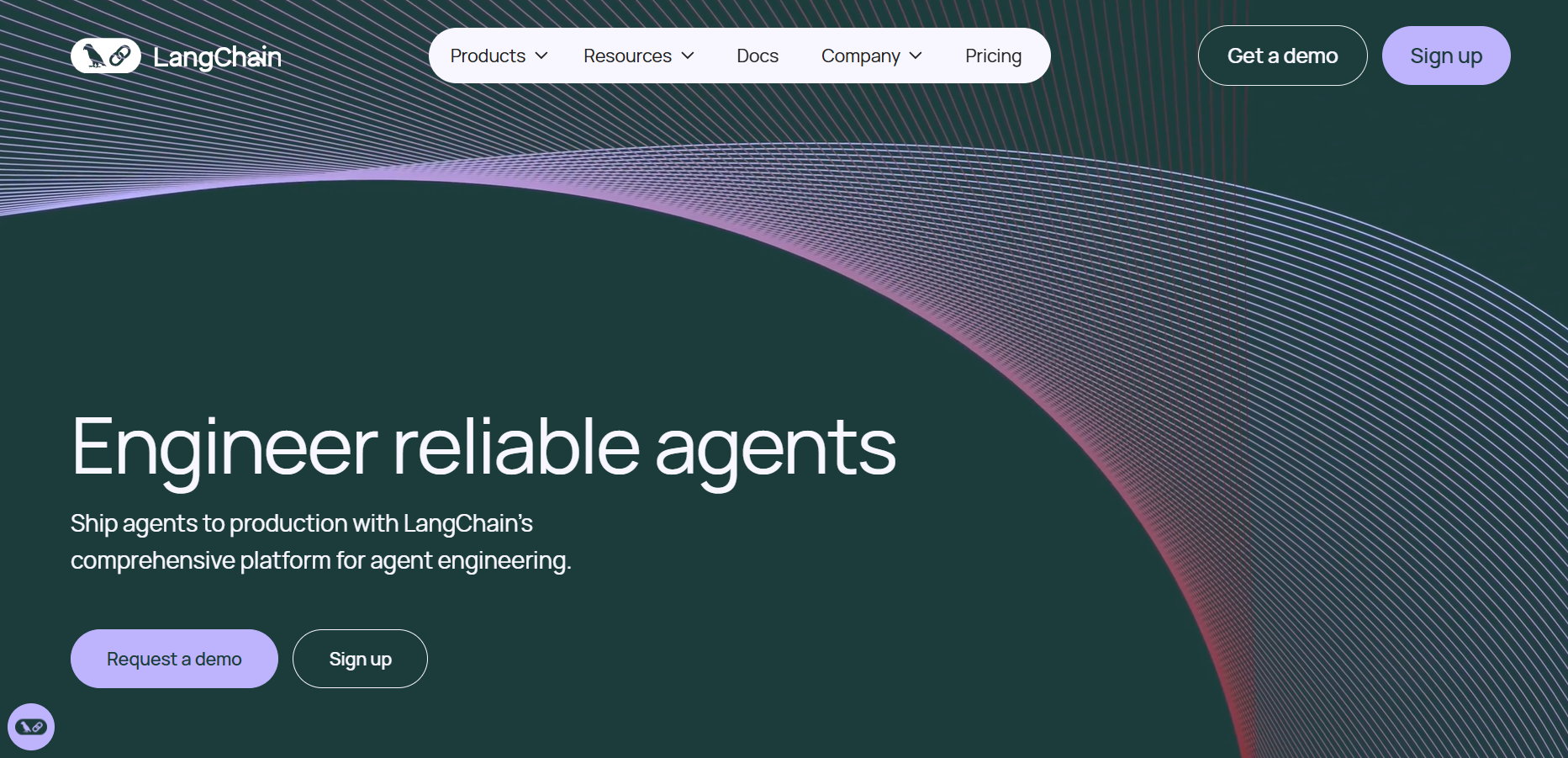
Langchain
LangChain is a powerful open-source framework designed to help developers build context-aware applications that leverage large language models (LLMs). It allows users to connect language models to various data sources, APIs, and memory components, enabling intelligent, multi-step reasoning and decision-making processes. LangChain supports both Python and JavaScript, providing modular building blocks for developers to create chatbots, AI assistants, retrieval-augmented generation (RAG) systems, and agent-based tools. The framework is widely adopted across industries for its flexibility in connecting structured and unstructured data with LLMs.
Langchain
LangChain is a powerful open-source framework designed to help developers build context-aware applications that leverage large language models (LLMs). It allows users to connect language models to various data sources, APIs, and memory components, enabling intelligent, multi-step reasoning and decision-making processes. LangChain supports both Python and JavaScript, providing modular building blocks for developers to create chatbots, AI assistants, retrieval-augmented generation (RAG) systems, and agent-based tools. The framework is widely adopted across industries for its flexibility in connecting structured and unstructured data with LLMs.
Langchain
LangChain is a powerful open-source framework designed to help developers build context-aware applications that leverage large language models (LLMs). It allows users to connect language models to various data sources, APIs, and memory components, enabling intelligent, multi-step reasoning and decision-making processes. LangChain supports both Python and JavaScript, providing modular building blocks for developers to create chatbots, AI assistants, retrieval-augmented generation (RAG) systems, and agent-based tools. The framework is widely adopted across industries for its flexibility in connecting structured and unstructured data with LLMs.
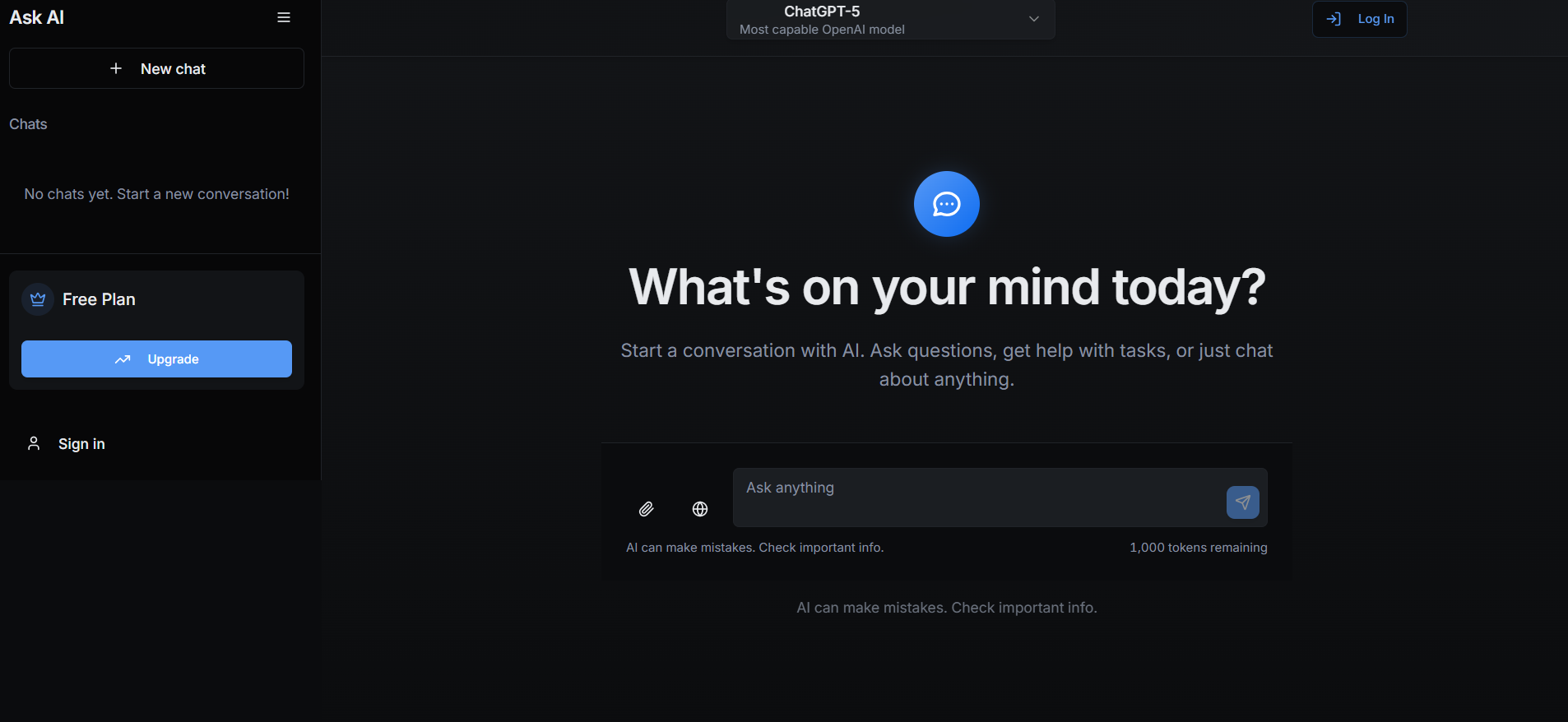
Ask Any Model
AskAnyModel is a unified AI interface that allows users to interact with multiple leading AI models — such as GPT, Claude, Gemini, and Mistral — from a single platform. It eliminates the need for multiple subscriptions and interfaces by bringing top AI models into one streamlined environment. Users can compare responses, analyze outputs, and select the best AI model for specific tasks like content creation, coding, data analysis, or research. AskAnyModel empowers individuals and teams to harness AI diversity efficiently, offering advanced tools for prompt testing, model benchmarking, and workflow integration.
Ask Any Model
AskAnyModel is a unified AI interface that allows users to interact with multiple leading AI models — such as GPT, Claude, Gemini, and Mistral — from a single platform. It eliminates the need for multiple subscriptions and interfaces by bringing top AI models into one streamlined environment. Users can compare responses, analyze outputs, and select the best AI model for specific tasks like content creation, coding, data analysis, or research. AskAnyModel empowers individuals and teams to harness AI diversity efficiently, offering advanced tools for prompt testing, model benchmarking, and workflow integration.
Ask Any Model
AskAnyModel is a unified AI interface that allows users to interact with multiple leading AI models — such as GPT, Claude, Gemini, and Mistral — from a single platform. It eliminates the need for multiple subscriptions and interfaces by bringing top AI models into one streamlined environment. Users can compare responses, analyze outputs, and select the best AI model for specific tasks like content creation, coding, data analysis, or research. AskAnyModel empowers individuals and teams to harness AI diversity efficiently, offering advanced tools for prompt testing, model benchmarking, and workflow integration.


Mobisoft Infotech
MI Team AI is a robust multi-LLM platform designed for enterprises seeking secure, scalable, and cost-effective AI access. It consolidates multiple AI models such as ChatGPT, Claude, Gemini, and various open-source large language models into a single platform, enabling users to switch seamlessly without juggling different tools. The platform supports deployment on private cloud or on-premises infrastructure to ensure complete data privacy and compliance. MI Team AI provides a unified workspace with role-based access controls, single sign-on (SSO), and comprehensive chat logs for transparency and auditability. It offers fixed licensing fees allowing unlimited team access under the company’s brand, making it ideal for organizations needing full control over AI usage.
Mobisoft Infotech
MI Team AI is a robust multi-LLM platform designed for enterprises seeking secure, scalable, and cost-effective AI access. It consolidates multiple AI models such as ChatGPT, Claude, Gemini, and various open-source large language models into a single platform, enabling users to switch seamlessly without juggling different tools. The platform supports deployment on private cloud or on-premises infrastructure to ensure complete data privacy and compliance. MI Team AI provides a unified workspace with role-based access controls, single sign-on (SSO), and comprehensive chat logs for transparency and auditability. It offers fixed licensing fees allowing unlimited team access under the company’s brand, making it ideal for organizations needing full control over AI usage.
Mobisoft Infotech
MI Team AI is a robust multi-LLM platform designed for enterprises seeking secure, scalable, and cost-effective AI access. It consolidates multiple AI models such as ChatGPT, Claude, Gemini, and various open-source large language models into a single platform, enabling users to switch seamlessly without juggling different tools. The platform supports deployment on private cloud or on-premises infrastructure to ensure complete data privacy and compliance. MI Team AI provides a unified workspace with role-based access controls, single sign-on (SSO), and comprehensive chat logs for transparency and auditability. It offers fixed licensing fees allowing unlimited team access under the company’s brand, making it ideal for organizations needing full control over AI usage.

Awan LLM
Awan LLM is a cost-effective, unlimited token large language model inference API platform designed for power users and developers. Unlike traditional API providers that charge per token, Awan LLM offers a monthly subscription model that enables users to send and receive unlimited tokens up to the model's context limit. It supports unrestricted use of LLM models without censorship or constraints. The platform is built on privately owned data centers and GPUs, allowing it to offer efficient and scalable AI services. Awan LLM supports numerous use cases including AI assistants, AI agents, roleplaying, data processing, code completion, and building AI-powered applications without worrying about token limits or costs.
Awan LLM
Awan LLM is a cost-effective, unlimited token large language model inference API platform designed for power users and developers. Unlike traditional API providers that charge per token, Awan LLM offers a monthly subscription model that enables users to send and receive unlimited tokens up to the model's context limit. It supports unrestricted use of LLM models without censorship or constraints. The platform is built on privately owned data centers and GPUs, allowing it to offer efficient and scalable AI services. Awan LLM supports numerous use cases including AI assistants, AI agents, roleplaying, data processing, code completion, and building AI-powered applications without worrying about token limits or costs.
Awan LLM
Awan LLM is a cost-effective, unlimited token large language model inference API platform designed for power users and developers. Unlike traditional API providers that charge per token, Awan LLM offers a monthly subscription model that enables users to send and receive unlimited tokens up to the model's context limit. It supports unrestricted use of LLM models without censorship or constraints. The platform is built on privately owned data centers and GPUs, allowing it to offer efficient and scalable AI services. Awan LLM supports numerous use cases including AI assistants, AI agents, roleplaying, data processing, code completion, and building AI-powered applications without worrying about token limits or costs.

LLM as-a-service
LLM.co LLM-as-a-Service (LLMaaS) is a secure, enterprise-grade AI platform that provides private and fully managed large language model deployments tailored to an organization’s specific industry, workflows, and data. Unlike public LLM APIs, each client receives a dedicated, single-tenant model hosted in private clouds or virtual private clouds (VPCs), ensuring complete data privacy and compliance. The platform offers model fine-tuning on proprietary internal documents, semantic search, multi-document Q&A, custom AI agents, contract review, and offline AI capabilities for regulated industries. It removes infrastructure burdens by handling deployment, scaling, and monitoring, while enabling businesses to customize models for domain-specific language, regulatory compliance, and unique operational needs.
LLM as-a-service
LLM.co LLM-as-a-Service (LLMaaS) is a secure, enterprise-grade AI platform that provides private and fully managed large language model deployments tailored to an organization’s specific industry, workflows, and data. Unlike public LLM APIs, each client receives a dedicated, single-tenant model hosted in private clouds or virtual private clouds (VPCs), ensuring complete data privacy and compliance. The platform offers model fine-tuning on proprietary internal documents, semantic search, multi-document Q&A, custom AI agents, contract review, and offline AI capabilities for regulated industries. It removes infrastructure burdens by handling deployment, scaling, and monitoring, while enabling businesses to customize models for domain-specific language, regulatory compliance, and unique operational needs.
LLM as-a-service
LLM.co LLM-as-a-Service (LLMaaS) is a secure, enterprise-grade AI platform that provides private and fully managed large language model deployments tailored to an organization’s specific industry, workflows, and data. Unlike public LLM APIs, each client receives a dedicated, single-tenant model hosted in private clouds or virtual private clouds (VPCs), ensuring complete data privacy and compliance. The platform offers model fine-tuning on proprietary internal documents, semantic search, multi-document Q&A, custom AI agents, contract review, and offline AI capabilities for regulated industries. It removes infrastructure burdens by handling deployment, scaling, and monitoring, while enabling businesses to customize models for domain-specific language, regulatory compliance, and unique operational needs.
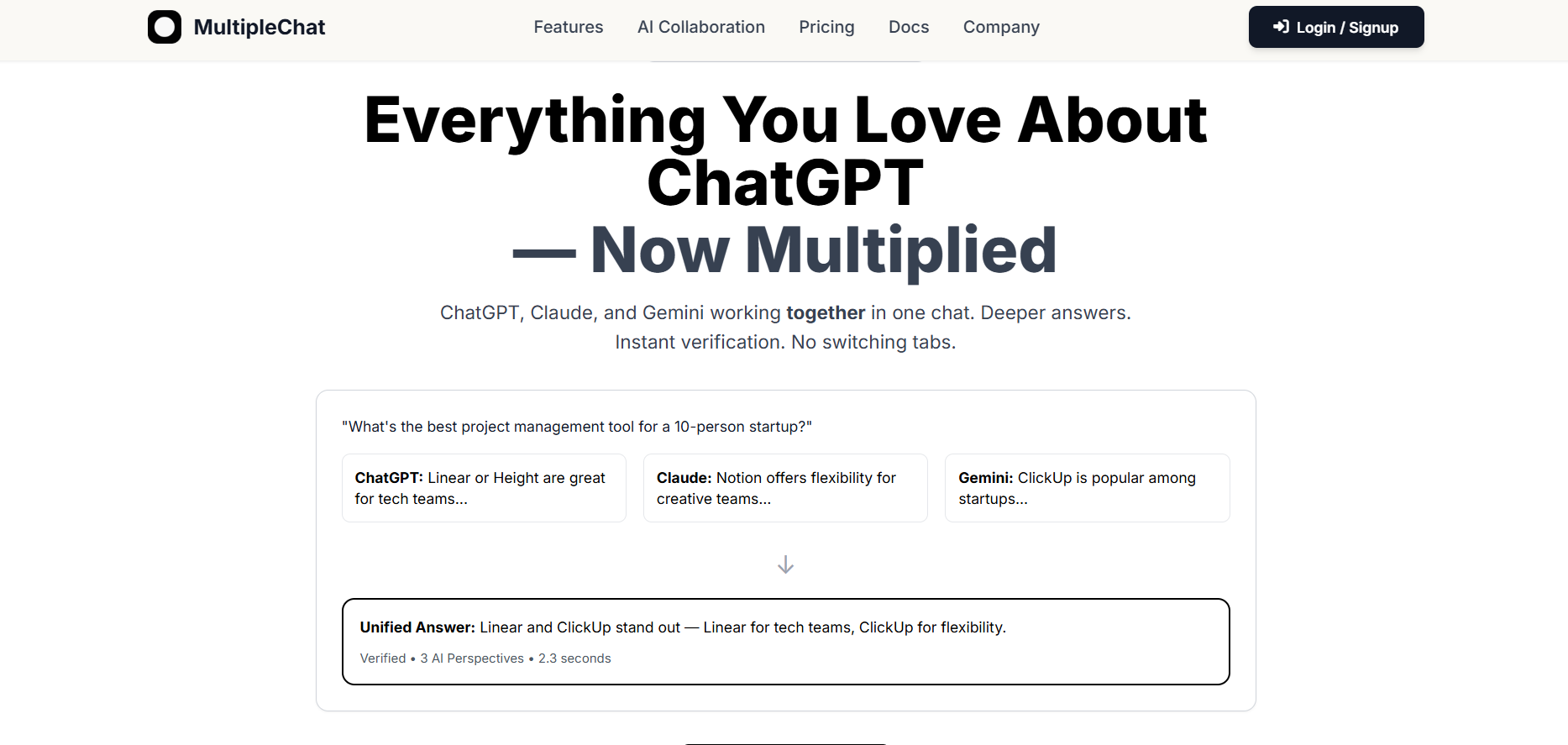
Multiple Chat
Multiple is a multi-model AI chat platform that allows users to interact with several leading AI models within a single interface. By combining responses from different AI systems, it enables deeper exploration, comparison, and verification of answers without switching tabs. The platform is designed for users who rely heavily on conversational AI and want improved accuracy, broader perspectives, and more confident outputs.
Multiple Chat
Multiple is a multi-model AI chat platform that allows users to interact with several leading AI models within a single interface. By combining responses from different AI systems, it enables deeper exploration, comparison, and verification of answers without switching tabs. The platform is designed for users who rely heavily on conversational AI and want improved accuracy, broader perspectives, and more confident outputs.
Multiple Chat
Multiple is a multi-model AI chat platform that allows users to interact with several leading AI models within a single interface. By combining responses from different AI systems, it enables deeper exploration, comparison, and verification of answers without switching tabs. The platform is designed for users who rely heavily on conversational AI and want improved accuracy, broader perspectives, and more confident outputs.
Editorial Note
This page was researched and written by the ATB Editorial Team. Our team researches each AI tool by reviewing its official website, testing features, exploring real use cases, and considering user feedback. Every page is fact-checked and regularly updated to ensure the information stays accurate, neutral, and useful for our readers.
If you have any suggestions or questions, email us at hello@aitoolbook.ai