
✅ Filmmakers & Animators – Generate cinematic sequences and storyboards.
✅ Content Creators & Marketers – Create short-form videos, ads, and promotional clips.
✅ Game Developers – Design animated scenes and game assets.
✅ Educators & Businesses – Generate visual learning materials and presentations.
✅ AI Enthusiasts & Artists – Experiment with AI-generated storytelling and creative visuals.
How to Use OpenAI Sora?
1️⃣ Access Sora – OpenAI is rolling out Sora gradually, with access for select creators and developers.
2️⃣ Enter a Text Prompt – Describe the video you want in detail. Example:"A futuristic cityscape at night, neon lights reflecting on wet streets, people walking in cyberpunk outfits."
3️⃣ Generate the Video – Sora will process the prompt and create a short AI-generated video.
4️⃣ Refine the Output (Optional) – OpenAI may allow prompt-based refinements for better accuracy.
5️⃣ Download & Use the Video – Save and edit the generated video for your projects.
6️⃣ API Integration (Future Possibility) – Developers may be able to embed Sora into applications for automated video generation.
📝 Better Prompt Understanding – Captures complex scenes with accurate motion.
🚀 Smooth & Realistic Animations – Maintains consistency in characters, lighting, and physics.
🎨 Works for a Variety of Styles – From realistic footage to stylized animations.
⚡ Potential for API & Professional Use – Could integrate into creative workflows.
- High-Resolution, Coherent Video Generation – Realistic movement and smooth transitions.
- Diverse Creative Applications – Suitable for content creation, filmmaking, and advertising.
- AI-Driven Visual Storytelling – Great for conceptualizing ideas quickly.
- Limited Access – Not publicly available yet, only selected users can try it.
- Processing Limitations – Long or highly complex videos may still face challenges.
- Editing Flexibility Unclear – Currently unclear how much post-generation editing is possible.
Plus
$ 20.00
Learn more about everything you get with ChatGPT Plus
Pro
$ 200.00
Up to 1080p resolution and 20s duration videos
Up to 5 concurrent generations
Download videos without watermark
Learn more about everything you get with ChatGPT Pro
Proud of the love you're getting? Show off your AI Toolbook reviews—then invite more fans to share the love and build your credibility.
Add an AI Toolbook badge to your site—an easy way to drive followers, showcase updates, and collect reviews. It's like a mini 24/7 billboard for your AI.
Reviews
Rating Distribution
Average score
Popular Mention
FAQs
Similar AI Tools

OpenAI GPT-4o mini
GPT-4o Mini is a lighter, faster, and more affordable version of GPT-4o. It offers strong performance at a lower cost, making it ideal for applications requiring efficiency and speed over raw power.
OpenAI GPT-4o mini
GPT-4o Mini is a lighter, faster, and more affordable version of GPT-4o. It offers strong performance at a lower cost, making it ideal for applications requiring efficiency and speed over raw power.
OpenAI GPT-4o mini
GPT-4o Mini is a lighter, faster, and more affordable version of GPT-4o. It offers strong performance at a lower cost, making it ideal for applications requiring efficiency and speed over raw power.

OpenAI o1
o1 is a fast, highly capable language model developed by OpenAI, optimized for performance, cost-efficiency, and general-purpose use. It represents the entry point into OpenAI’s GPT-4 class of models, delivering high-quality natural language generation, comprehension, and interaction at lower latency and cost than GPT-4 Turbo. Despite being a newer and smaller variant, o1 is robust enough for most AI applications—from content generation to customer support—making it a reliable choice for developers looking to build intelligent and responsive systems.
OpenAI o1
o1 is a fast, highly capable language model developed by OpenAI, optimized for performance, cost-efficiency, and general-purpose use. It represents the entry point into OpenAI’s GPT-4 class of models, delivering high-quality natural language generation, comprehension, and interaction at lower latency and cost than GPT-4 Turbo. Despite being a newer and smaller variant, o1 is robust enough for most AI applications—from content generation to customer support—making it a reliable choice for developers looking to build intelligent and responsive systems.
OpenAI o1
o1 is a fast, highly capable language model developed by OpenAI, optimized for performance, cost-efficiency, and general-purpose use. It represents the entry point into OpenAI’s GPT-4 class of models, delivering high-quality natural language generation, comprehension, and interaction at lower latency and cost than GPT-4 Turbo. Despite being a newer and smaller variant, o1 is robust enough for most AI applications—from content generation to customer support—making it a reliable choice for developers looking to build intelligent and responsive systems.

OpenAI o3-mini
OpenAI o3-mini is a lightweight, efficient AI model from OpenAI’s "o3" series, designed to balance cost, speed, and intelligence. It is optimized for faster inference and lower computational costs, making it an ideal choice for businesses and developers who need AI-powered applications without the high expense of larger models like GPT-4o.
OpenAI o3-mini
OpenAI o3-mini is a lightweight, efficient AI model from OpenAI’s "o3" series, designed to balance cost, speed, and intelligence. It is optimized for faster inference and lower computational costs, making it an ideal choice for businesses and developers who need AI-powered applications without the high expense of larger models like GPT-4o.
OpenAI o3-mini
OpenAI o3-mini is a lightweight, efficient AI model from OpenAI’s "o3" series, designed to balance cost, speed, and intelligence. It is optimized for faster inference and lower computational costs, making it an ideal choice for businesses and developers who need AI-powered applications without the high expense of larger models like GPT-4o.

OpenAI Dall-E 2
DALL·E 2 is an AI model developed by OpenAI that generates images from text descriptions (prompts). It improves upon its predecessor, DALL·E 1, by producing higher-resolution, more realistic, and creative images based on user input. The model can also edit existing images, expand images beyond their original borders (inpainting), and create artistic interpretations of text descriptions. ❗ Note: OpenAI has phased out DALL·E 2 in favor of DALL·E 3, which offers more advanced image generation.
OpenAI Dall-E 2
DALL·E 2 is an AI model developed by OpenAI that generates images from text descriptions (prompts). It improves upon its predecessor, DALL·E 1, by producing higher-resolution, more realistic, and creative images based on user input. The model can also edit existing images, expand images beyond their original borders (inpainting), and create artistic interpretations of text descriptions. ❗ Note: OpenAI has phased out DALL·E 2 in favor of DALL·E 3, which offers more advanced image generation.
OpenAI Dall-E 2
DALL·E 2 is an AI model developed by OpenAI that generates images from text descriptions (prompts). It improves upon its predecessor, DALL·E 1, by producing higher-resolution, more realistic, and creative images based on user input. The model can also edit existing images, expand images beyond their original borders (inpainting), and create artistic interpretations of text descriptions. ❗ Note: OpenAI has phased out DALL·E 2 in favor of DALL·E 3, which offers more advanced image generation.
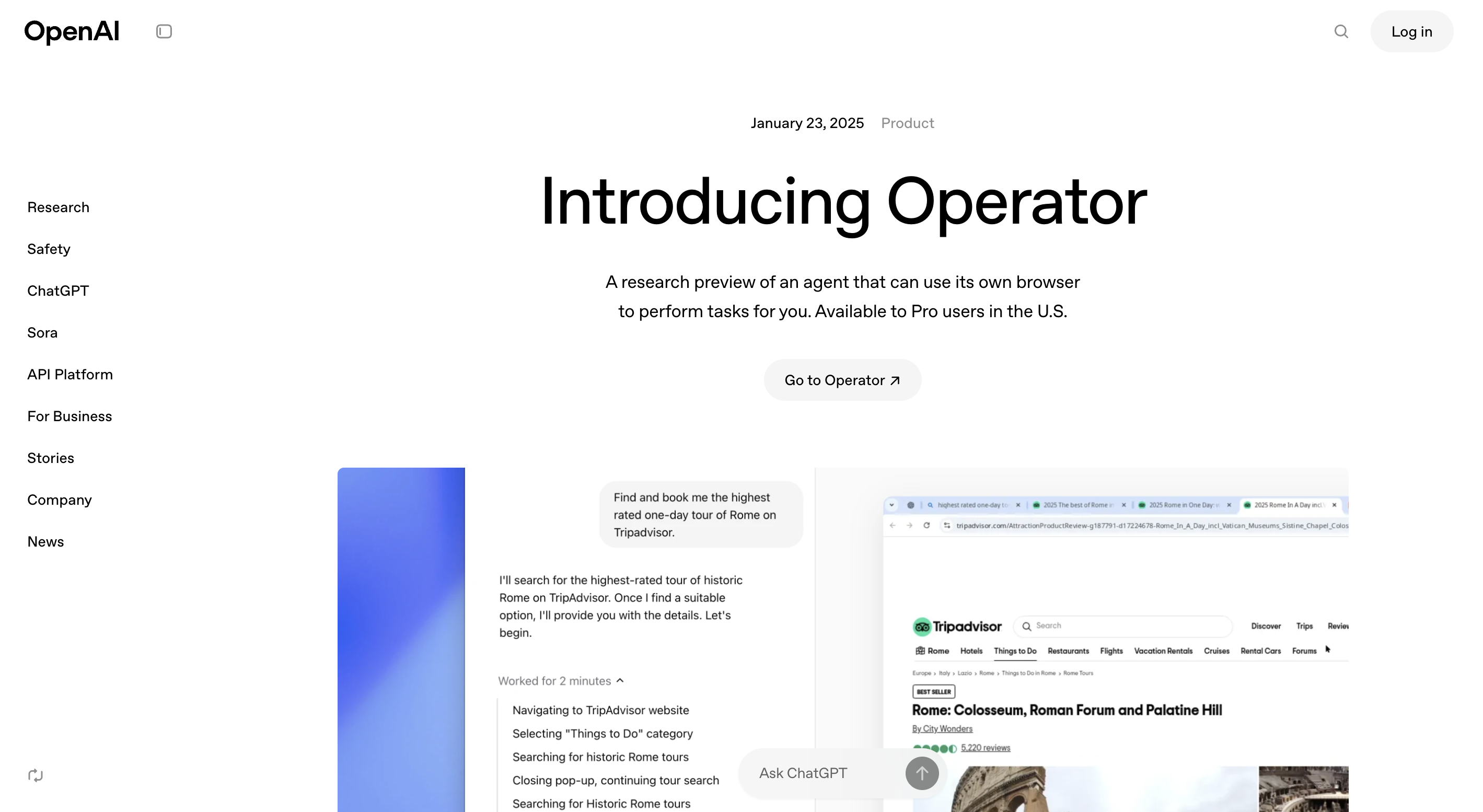
OpenAI Operator
OpenAI Operator is a cloud-native orchestration layer designed to help businesses deploy and manage AI models at scale. It optimizes performance, cost, and efficiency by dynamically selecting and running AI models based on workload demands. Operator enables seamless AI model deployment, monitoring, and scaling for enterprises, ensuring that AI-powered applications run efficiently and cost-effectively.
OpenAI Operator
OpenAI Operator is a cloud-native orchestration layer designed to help businesses deploy and manage AI models at scale. It optimizes performance, cost, and efficiency by dynamically selecting and running AI models based on workload demands. Operator enables seamless AI model deployment, monitoring, and scaling for enterprises, ensuring that AI-powered applications run efficiently and cost-effectively.
OpenAI Operator
OpenAI Operator is a cloud-native orchestration layer designed to help businesses deploy and manage AI models at scale. It optimizes performance, cost, and efficiency by dynamically selecting and running AI models based on workload demands. Operator enables seamless AI model deployment, monitoring, and scaling for enterprises, ensuring that AI-powered applications run efficiently and cost-effectively.

Deep Research is an AI-powered agent that autonomously browses the web, interprets and analyzes text, images, and PDFs, and generates comprehensive, cited reports on user-specified topics. It leverages OpenAI's advanced o3 model to conduct multi-step research tasks, delivering results within 5 to 30 minutes.
Deep Research is an AI-powered agent that autonomously browses the web, interprets and analyzes text, images, and PDFs, and generates comprehensive, cited reports on user-specified topics. It leverages OpenAI's advanced o3 model to conduct multi-step research tasks, delivering results within 5 to 30 minutes.
Deep Research is an AI-powered agent that autonomously browses the web, interprets and analyzes text, images, and PDFs, and generates comprehensive, cited reports on user-specified topics. It leverages OpenAI's advanced o3 model to conduct multi-step research tasks, delivering results within 5 to 30 minutes.

OpenAI Dall-E 3
OpenAI DALL·E 3 is an advanced AI image generation model that creates highly detailed and realistic images from text prompts. It builds upon previous versions by offering better composition, improved understanding of complex prompts, and seamless integration with ChatGPT. DALL·E 3 is designed for artists, designers, marketers, and content creators who want high-quality AI-generated visuals.
OpenAI Dall-E 3
OpenAI DALL·E 3 is an advanced AI image generation model that creates highly detailed and realistic images from text prompts. It builds upon previous versions by offering better composition, improved understanding of complex prompts, and seamless integration with ChatGPT. DALL·E 3 is designed for artists, designers, marketers, and content creators who want high-quality AI-generated visuals.
OpenAI Dall-E 3
OpenAI DALL·E 3 is an advanced AI image generation model that creates highly detailed and realistic images from text prompts. It builds upon previous versions by offering better composition, improved understanding of complex prompts, and seamless integration with ChatGPT. DALL·E 3 is designed for artists, designers, marketers, and content creators who want high-quality AI-generated visuals.

OpenAI’s Real-Time API is a game-changing advancement in AI interaction, enabling developers to build apps that respond instantly—literally in milliseconds—to user inputs. It drastically reduces the response latency of OpenAI’s GPT-4o model to as low as 100 milliseconds, unlocking a whole new world of AI-powered experiences that feel more human, responsive, and conversational in real time. Whether you're building a live voice assistant, a responsive chatbot, or interactive multiplayer tools powered by AI, this API puts real in real-time AI.
OpenAI’s Real-Time API is a game-changing advancement in AI interaction, enabling developers to build apps that respond instantly—literally in milliseconds—to user inputs. It drastically reduces the response latency of OpenAI’s GPT-4o model to as low as 100 milliseconds, unlocking a whole new world of AI-powered experiences that feel more human, responsive, and conversational in real time. Whether you're building a live voice assistant, a responsive chatbot, or interactive multiplayer tools powered by AI, this API puts real in real-time AI.
OpenAI’s Real-Time API is a game-changing advancement in AI interaction, enabling developers to build apps that respond instantly—literally in milliseconds—to user inputs. It drastically reduces the response latency of OpenAI’s GPT-4o model to as low as 100 milliseconds, unlocking a whole new world of AI-powered experiences that feel more human, responsive, and conversational in real time. Whether you're building a live voice assistant, a responsive chatbot, or interactive multiplayer tools powered by AI, this API puts real in real-time AI.
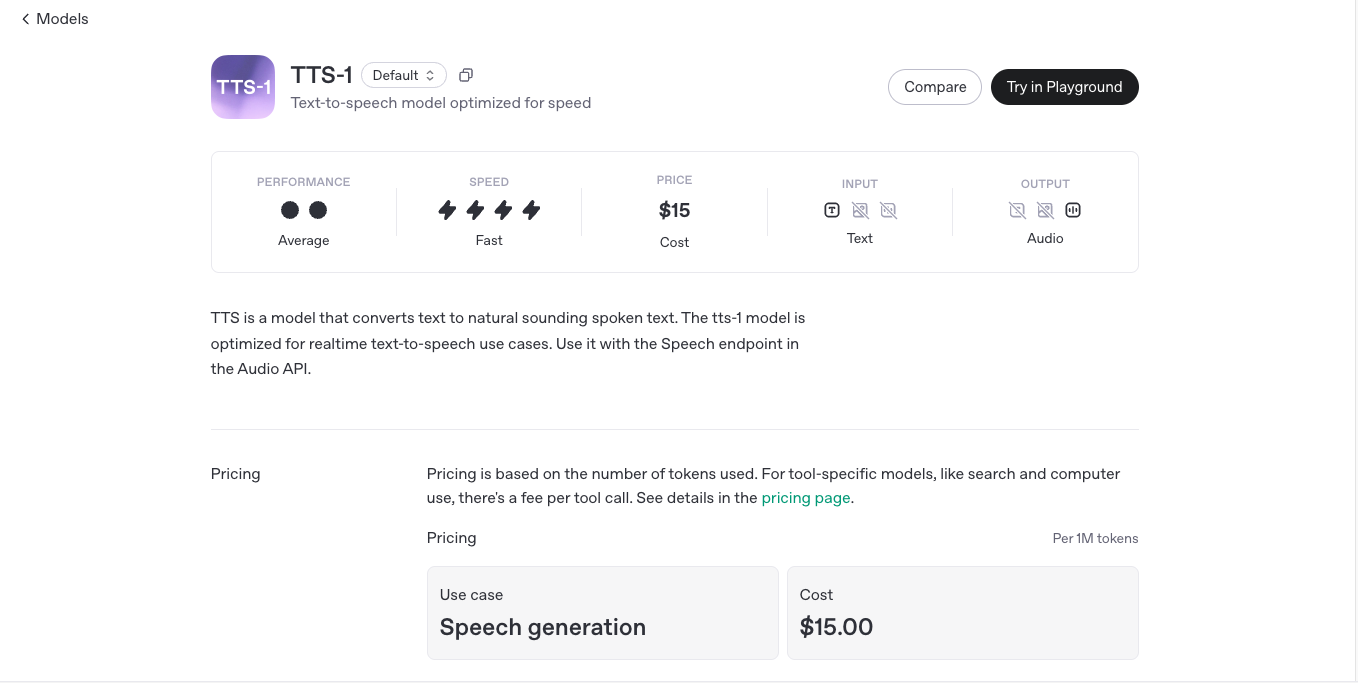
OpenAI TTS1
OpenAI's TTS-1 (Text-to-Speech) is a cutting-edge generative voice model that converts written text into natural-sounding speech with astonishing clarity, pacing, and emotional nuance. TTS-1 is designed to power real-time voice applications—like assistants, narrators, or conversational agents—with near-human vocal quality and minimal latency. Available through OpenAI’s API, this model makes it easy for developers to give their applications a voice that actually sounds human—not robotic. With multiple voices, languages, and low-latency streaming, TTS-1 redefines the synthetic voice experience.
OpenAI TTS1
OpenAI's TTS-1 (Text-to-Speech) is a cutting-edge generative voice model that converts written text into natural-sounding speech with astonishing clarity, pacing, and emotional nuance. TTS-1 is designed to power real-time voice applications—like assistants, narrators, or conversational agents—with near-human vocal quality and minimal latency. Available through OpenAI’s API, this model makes it easy for developers to give their applications a voice that actually sounds human—not robotic. With multiple voices, languages, and low-latency streaming, TTS-1 redefines the synthetic voice experience.
OpenAI TTS1
OpenAI's TTS-1 (Text-to-Speech) is a cutting-edge generative voice model that converts written text into natural-sounding speech with astonishing clarity, pacing, and emotional nuance. TTS-1 is designed to power real-time voice applications—like assistants, narrators, or conversational agents—with near-human vocal quality and minimal latency. Available through OpenAI’s API, this model makes it easy for developers to give their applications a voice that actually sounds human—not robotic. With multiple voices, languages, and low-latency streaming, TTS-1 redefines the synthetic voice experience.

GPT-4o Realtime Preview is OpenAI’s latest and most advanced multimodal AI model—designed for lightning-fast, real-time interaction across text, vision, and audio. The "o" stands for "omni," reflecting its groundbreaking ability to understand and generate across multiple input and output types. With human-like responsiveness, low latency, and top-tier intelligence, GPT-4o Realtime Preview offers a glimpse into the future of natural AI interfaces. Whether you're building voice assistants, dynamic UIs, or smart multi-input applications, GPT-4o is the new gold standard in real-time AI performance.
GPT-4o Realtime Preview is OpenAI’s latest and most advanced multimodal AI model—designed for lightning-fast, real-time interaction across text, vision, and audio. The "o" stands for "omni," reflecting its groundbreaking ability to understand and generate across multiple input and output types. With human-like responsiveness, low latency, and top-tier intelligence, GPT-4o Realtime Preview offers a glimpse into the future of natural AI interfaces. Whether you're building voice assistants, dynamic UIs, or smart multi-input applications, GPT-4o is the new gold standard in real-time AI performance.
GPT-4o Realtime Preview is OpenAI’s latest and most advanced multimodal AI model—designed for lightning-fast, real-time interaction across text, vision, and audio. The "o" stands for "omni," reflecting its groundbreaking ability to understand and generate across multiple input and output types. With human-like responsiveness, low latency, and top-tier intelligence, GPT-4o Realtime Preview offers a glimpse into the future of natural AI interfaces. Whether you're building voice assistants, dynamic UIs, or smart multi-input applications, GPT-4o is the new gold standard in real-time AI performance.

omni-moderation-latest is OpenAI’s most advanced content moderation model, designed to detect and flag harmful, unsafe, or policy-violating content across a wide range of modalities and languages. Built on the GPT-4o architecture, it leverages multimodal understanding and multilingual capabilities to provide robust moderation for text, images, and audio inputs. This model is particularly effective in identifying nuanced and culturally specific toxic content, including implicit insults, sarcasm, and aggression that general-purpose systems might overlook.
omni-moderation-latest is OpenAI’s most advanced content moderation model, designed to detect and flag harmful, unsafe, or policy-violating content across a wide range of modalities and languages. Built on the GPT-4o architecture, it leverages multimodal understanding and multilingual capabilities to provide robust moderation for text, images, and audio inputs. This model is particularly effective in identifying nuanced and culturally specific toxic content, including implicit insults, sarcasm, and aggression that general-purpose systems might overlook.
omni-moderation-latest is OpenAI’s most advanced content moderation model, designed to detect and flag harmful, unsafe, or policy-violating content across a wide range of modalities and languages. Built on the GPT-4o architecture, it leverages multimodal understanding and multilingual capabilities to provide robust moderation for text, images, and audio inputs. This model is particularly effective in identifying nuanced and culturally specific toxic content, including implicit insults, sarcasm, and aggression that general-purpose systems might overlook.
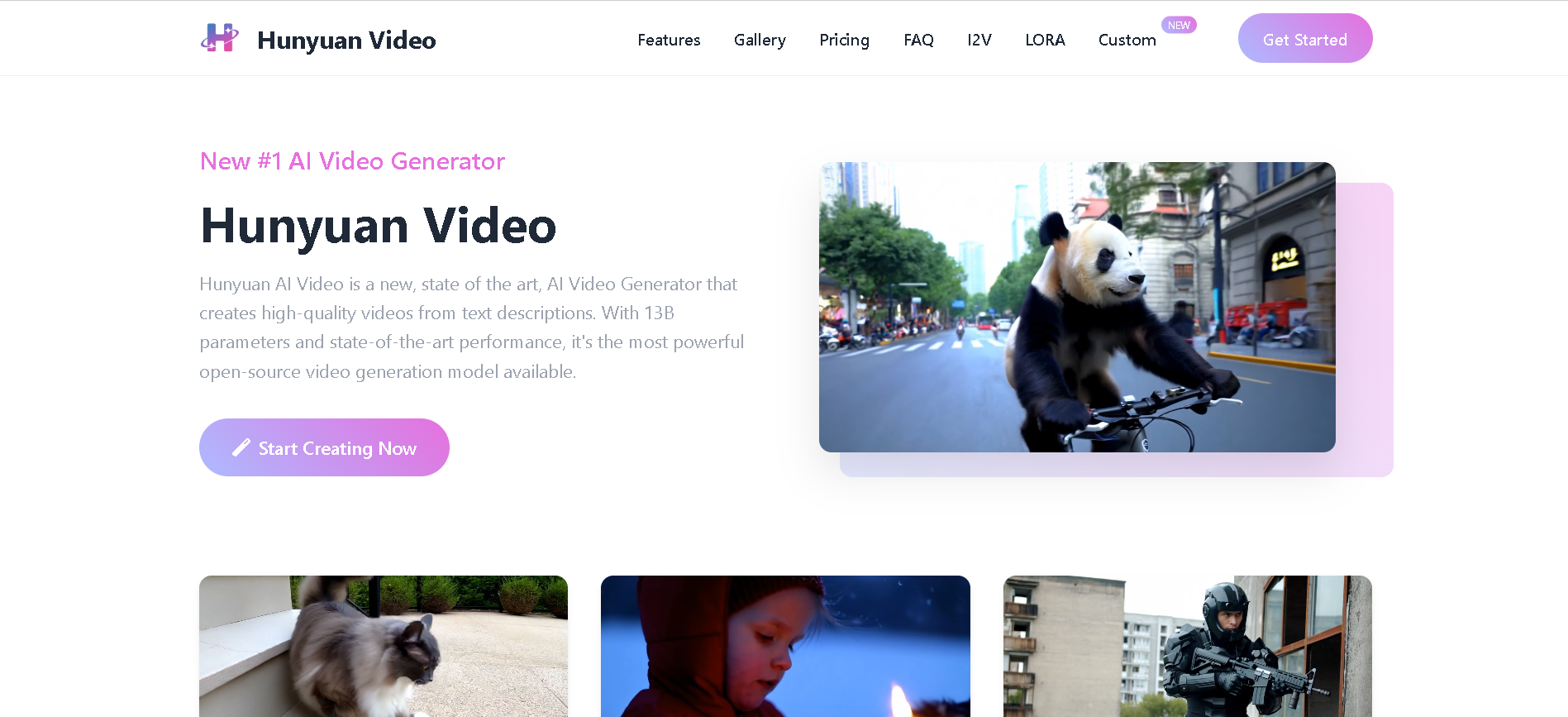

Hunyuan Video
Hunyuan Video AI, developed by Tencent, is a powerful and advanced AI model for generating video content. Positioned as a free, open-source alternative to models like OpenAI's Sora, it is capable of creating high-quality, realistic videos from simple text prompts or a single image. While the core model requires significant computing power to run locally, it is also available through various third-party platforms and apps that provide an accessible, cloud-based experience.
Hunyuan Video
Hunyuan Video AI, developed by Tencent, is a powerful and advanced AI model for generating video content. Positioned as a free, open-source alternative to models like OpenAI's Sora, it is capable of creating high-quality, realistic videos from simple text prompts or a single image. While the core model requires significant computing power to run locally, it is also available through various third-party platforms and apps that provide an accessible, cloud-based experience.
Hunyuan Video
Hunyuan Video AI, developed by Tencent, is a powerful and advanced AI model for generating video content. Positioned as a free, open-source alternative to models like OpenAI's Sora, it is capable of creating high-quality, realistic videos from simple text prompts or a single image. While the core model requires significant computing power to run locally, it is also available through various third-party platforms and apps that provide an accessible, cloud-based experience.
Editorial Note
This page was researched and written by the ATB Editorial Team. Our team researches each AI tool by reviewing its official website, testing features, exploring real use cases, and considering user feedback. Every page is fact-checked and regularly updated to ensure the information stays accurate, neutral, and useful for our readers.
If you have any suggestions or questions, email us at hello@aitoolbook.ai