- Developers on Edge Devices: Deploy AI models where compute resources and power are limited.
- Startups and Small Teams: Build fast AI applications without costly infrastructure.
- Product Managers: Incorporate real-time AI features into consumer or enterprise apps.
- AI Researchers: Experiment with efficient generation models for lightweight deployments.
- Organizations with Budget Constraints: Run generative AI workflows on commodity GPUs affordably.
How to Use Command R7B?
- Deploy on Edge or Local GPUs: Optimize model for use on lower-power hardware setups.
- Integrate via APIs: Use Cohere’s APIs to quickly add R7B into existing products.
- Customize for Speed: Tune workload parameters balancing latency and output quality.
- Monitor Performance: Use performance tools to maintain efficiency in production.
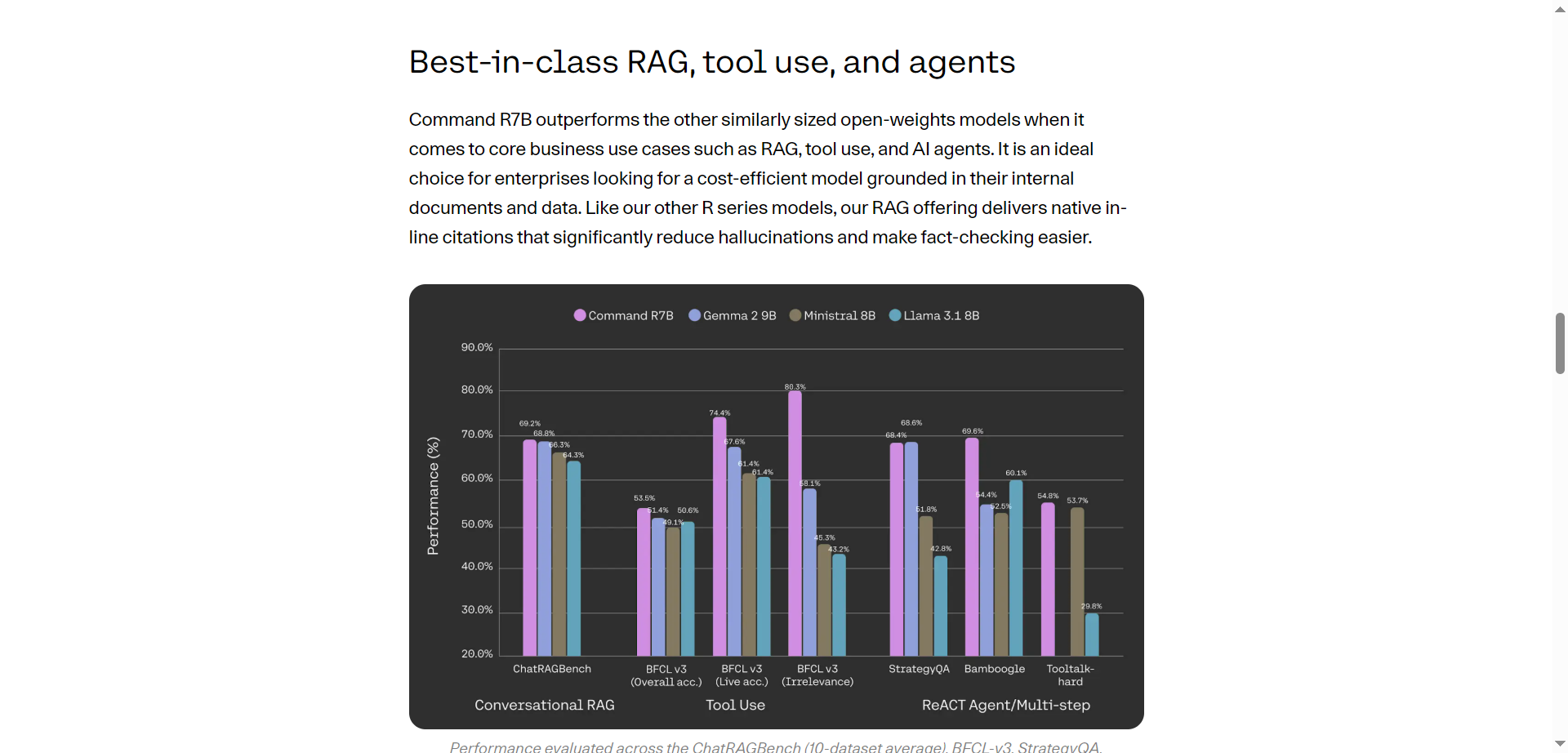
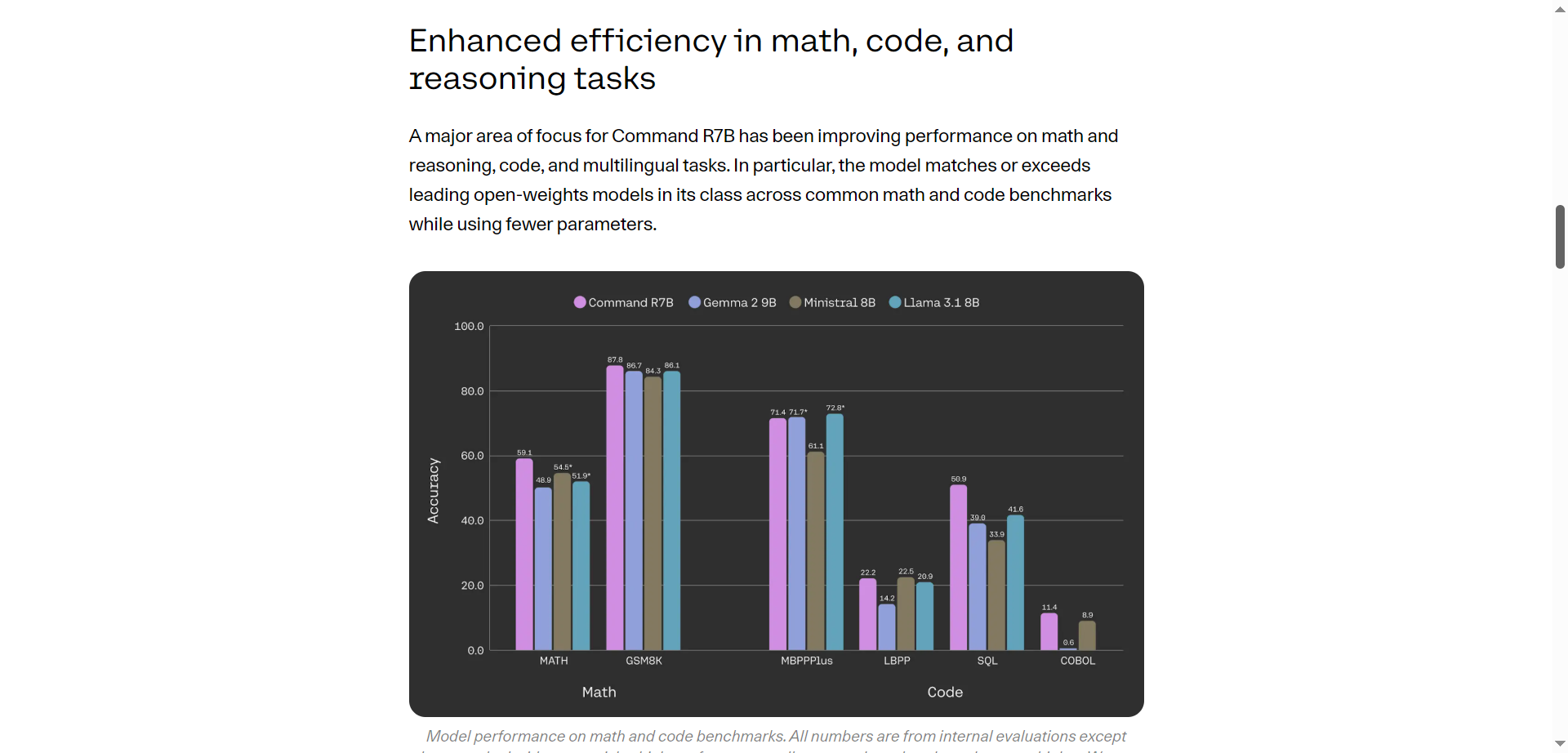
- Compact Yet Powerful: Smallest in the Command family with robust generative output.
- Optimized for Efficiency: Designed for speed on commodity and edge GPUs.
- Real-Time Performance: Suitable for applications demanding quick AI responses.
- Cost-Effective: Enables AI deployment with lower hardware costs.
- Scalable Integration: Fits in ecosystems requiring seamless API usage and scaling.
- Delivers fast AI generation even on limited hardware.
- Enables real-time applications with low latency requirements.
- Accessible for smaller teams and budget-conscious users.
- Flexible integration with existing AI workflows and platforms.
- Smaller size may limit complex reasoning or large-scale tasks.
- Not ideal for compute-intensive, high-accuracy needs.
- Lacks some advanced features available in larger Command models.
- May require tuning to balance speed and output quality optimally.


Custom
$ 0.15
$0.0375/1M tokens
Output
$0.15/1M tokens
128K token context window
4K maximum output tokens
Proud of the love you're getting? Show off your AI Toolbook reviews—then invite more fans to share the love and build your credibility.
Add an AI Toolbook badge to your site—an easy way to drive followers, showcase updates, and collect reviews. It's like a mini 24/7 billboard for your AI.
Reviews
Rating Distribution
Average score
Popular Mention
FAQs
Similar AI Tools

OpenAI - GPT 4.1
GPT-4.1 is OpenAI’s newest multimodal large language model, designed to deliver highly capable, efficient, and intelligent performance across a broad range of tasks. It builds on the foundation of GPT-4 and GPT-4 Turbo, offering enhanced reasoning, greater factual accuracy, and smoother integration with tools like code interpreters, retrieval systems, and image understanding. With native support for a 128K token context window, function calling, and robust tool usage, GPT-4.1 brings AI closer to behaving like a reliable, adaptive assistant—ready to work, build, and collaborate across tasks with speed and precision.
OpenAI - GPT 4.1
GPT-4.1 is OpenAI’s newest multimodal large language model, designed to deliver highly capable, efficient, and intelligent performance across a broad range of tasks. It builds on the foundation of GPT-4 and GPT-4 Turbo, offering enhanced reasoning, greater factual accuracy, and smoother integration with tools like code interpreters, retrieval systems, and image understanding. With native support for a 128K token context window, function calling, and robust tool usage, GPT-4.1 brings AI closer to behaving like a reliable, adaptive assistant—ready to work, build, and collaborate across tasks with speed and precision.
OpenAI - GPT 4.1
GPT-4.1 is OpenAI’s newest multimodal large language model, designed to deliver highly capable, efficient, and intelligent performance across a broad range of tasks. It builds on the foundation of GPT-4 and GPT-4 Turbo, offering enhanced reasoning, greater factual accuracy, and smoother integration with tools like code interpreters, retrieval systems, and image understanding. With native support for a 128K token context window, function calling, and robust tool usage, GPT-4.1 brings AI closer to behaving like a reliable, adaptive assistant—ready to work, build, and collaborate across tasks with speed and precision.

GPT-4.1 Nano is OpenAI’s smallest and most efficient language model in the GPT-4.1 family, designed to deliver ultra-fast, ultra-cheap, and surprisingly capable natural language responses. Though compact in size, GPT-4.1 Nano handles lightweight NLP tasks with impressive speed and minimal resource consumption, making it perfect for mobile apps, edge computing, and large-scale deployments with cost sensitivity. It’s built for real-time applications and use cases where milliseconds matter, and budgets are tight—yet you still want a taste of OpenAI-grade intelligence.
GPT-4.1 Nano is OpenAI’s smallest and most efficient language model in the GPT-4.1 family, designed to deliver ultra-fast, ultra-cheap, and surprisingly capable natural language responses. Though compact in size, GPT-4.1 Nano handles lightweight NLP tasks with impressive speed and minimal resource consumption, making it perfect for mobile apps, edge computing, and large-scale deployments with cost sensitivity. It’s built for real-time applications and use cases where milliseconds matter, and budgets are tight—yet you still want a taste of OpenAI-grade intelligence.
GPT-4.1 Nano is OpenAI’s smallest and most efficient language model in the GPT-4.1 family, designed to deliver ultra-fast, ultra-cheap, and surprisingly capable natural language responses. Though compact in size, GPT-4.1 Nano handles lightweight NLP tasks with impressive speed and minimal resource consumption, making it perfect for mobile apps, edge computing, and large-scale deployments with cost sensitivity. It’s built for real-time applications and use cases where milliseconds matter, and budgets are tight—yet you still want a taste of OpenAI-grade intelligence.

GPT-4o-mini-tts is OpenAI's lightweight, high-speed text-to-speech (TTS) model designed for fast, real-time voice synthesis using the GPT-4o-mini architecture. It's built to deliver natural, expressive, and low-latency speech output—ideal for developers building interactive applications that require instant voice responses, such as AI assistants, voice agents, or educational tools. Unlike larger TTS models, GPT-4o-mini-tts balances performance and efficiency, enabling responsive, engaging voice output even in environments with limited compute resources.
GPT-4o-mini-tts is OpenAI's lightweight, high-speed text-to-speech (TTS) model designed for fast, real-time voice synthesis using the GPT-4o-mini architecture. It's built to deliver natural, expressive, and low-latency speech output—ideal for developers building interactive applications that require instant voice responses, such as AI assistants, voice agents, or educational tools. Unlike larger TTS models, GPT-4o-mini-tts balances performance and efficiency, enabling responsive, engaging voice output even in environments with limited compute resources.
GPT-4o-mini-tts is OpenAI's lightweight, high-speed text-to-speech (TTS) model designed for fast, real-time voice synthesis using the GPT-4o-mini architecture. It's built to deliver natural, expressive, and low-latency speech output—ideal for developers building interactive applications that require instant voice responses, such as AI assistants, voice agents, or educational tools. Unlike larger TTS models, GPT-4o-mini-tts balances performance and efficiency, enabling responsive, engaging voice output even in environments with limited compute resources.

GPT-4o-mini Search Preview is OpenAI’s lightweight semantic search feature powered by the GPT-4o-mini model. Designed for real-time applications and low-latency environments, it brings retrieval-augmented intelligence to any product or tool that needs blazing-fast, accurate information lookup. While compact in size, it offers the power of contextual understanding, enabling smarter, more relevant search results with fewer resources. It’s ideal for startups, embedded systems, or anyone who needs search that just works—fast, efficient, and tuned for integration.
GPT-4o-mini Search Preview is OpenAI’s lightweight semantic search feature powered by the GPT-4o-mini model. Designed for real-time applications and low-latency environments, it brings retrieval-augmented intelligence to any product or tool that needs blazing-fast, accurate information lookup. While compact in size, it offers the power of contextual understanding, enabling smarter, more relevant search results with fewer resources. It’s ideal for startups, embedded systems, or anyone who needs search that just works—fast, efficient, and tuned for integration.
GPT-4o-mini Search Preview is OpenAI’s lightweight semantic search feature powered by the GPT-4o-mini model. Designed for real-time applications and low-latency environments, it brings retrieval-augmented intelligence to any product or tool that needs blazing-fast, accurate information lookup. While compact in size, it offers the power of contextual understanding, enabling smarter, more relevant search results with fewer resources. It’s ideal for startups, embedded systems, or anyone who needs search that just works—fast, efficient, and tuned for integration.

Ecommerce AI Website Advisor is a ChatGPT-powered assistant created by PageFly, designed to guide Shopify users through decisions like choosing the right plan, apps, and themes. It's like having an on-demand Shopify expert in chat form—no fluff, just personalized advice to optimize your e-commerce setup.
Ecommerce AI Website Advisor is a ChatGPT-powered assistant created by PageFly, designed to guide Shopify users through decisions like choosing the right plan, apps, and themes. It's like having an on-demand Shopify expert in chat form—no fluff, just personalized advice to optimize your e-commerce setup.
Ecommerce AI Website Advisor is a ChatGPT-powered assistant created by PageFly, designed to guide Shopify users through decisions like choosing the right plan, apps, and themes. It's like having an on-demand Shopify expert in chat form—no fluff, just personalized advice to optimize your e-commerce setup.

Claude 3.7 Sonnet
Claude 3.7 Sonnet is Anthropic’s first hybrid reasoning AI model, combining fast, near-instant replies with optional step-by-step “extended thinking” in a single model. It’s their most intelligent Sonnet release yet—excelling at coding, math, planning, vision, and agentic tasks—while maintaining the same cost and speed structure .
Claude 3.7 Sonnet
Claude 3.7 Sonnet is Anthropic’s first hybrid reasoning AI model, combining fast, near-instant replies with optional step-by-step “extended thinking” in a single model. It’s their most intelligent Sonnet release yet—excelling at coding, math, planning, vision, and agentic tasks—while maintaining the same cost and speed structure .
Claude 3.7 Sonnet
Claude 3.7 Sonnet is Anthropic’s first hybrid reasoning AI model, combining fast, near-instant replies with optional step-by-step “extended thinking” in a single model. It’s their most intelligent Sonnet release yet—excelling at coding, math, planning, vision, and agentic tasks—while maintaining the same cost and speed structure .
Gemini 2.0 Flash‑Lite is Google DeepMind’s most cost-efficient, low-latency variant of the Gemini 2.0 Flash model, now publicly available in preview. It delivers fast, multimodal reasoning across text, image, audio, and video inputs, supports native tool use, and processes up to a 1 million token context window—all while keeping latency and cost exceptionally low .
Gemini 2.0 Flash‑Lite is Google DeepMind’s most cost-efficient, low-latency variant of the Gemini 2.0 Flash model, now publicly available in preview. It delivers fast, multimodal reasoning across text, image, audio, and video inputs, supports native tool use, and processes up to a 1 million token context window—all while keeping latency and cost exceptionally low .
Gemini 2.0 Flash‑Lite is Google DeepMind’s most cost-efficient, low-latency variant of the Gemini 2.0 Flash model, now publicly available in preview. It delivers fast, multimodal reasoning across text, image, audio, and video inputs, supports native tool use, and processes up to a 1 million token context window—all while keeping latency and cost exceptionally low .

DeepSeek R1 Distill refers to a family of dense, smaller models distilled from DeepSeek’s flagship DeepSeek R1 reasoning model. Released early 2025, these models come in sizes ranging from 1.5B to 70B parameters (e.g., DeepSeek‑R1‑Distill‑Qwen‑32B) and retain powerful reasoning and chain-of-thought abilities in a more efficient architecture. Benchmarks show distilled variants outperform models like OpenAI’s o1‑mini, while remaining open‑source under MIT license.
DeepSeek R1 Distill refers to a family of dense, smaller models distilled from DeepSeek’s flagship DeepSeek R1 reasoning model. Released early 2025, these models come in sizes ranging from 1.5B to 70B parameters (e.g., DeepSeek‑R1‑Distill‑Qwen‑32B) and retain powerful reasoning and chain-of-thought abilities in a more efficient architecture. Benchmarks show distilled variants outperform models like OpenAI’s o1‑mini, while remaining open‑source under MIT license.
DeepSeek R1 Distill refers to a family of dense, smaller models distilled from DeepSeek’s flagship DeepSeek R1 reasoning model. Released early 2025, these models come in sizes ranging from 1.5B to 70B parameters (e.g., DeepSeek‑R1‑Distill‑Qwen‑32B) and retain powerful reasoning and chain-of-thought abilities in a more efficient architecture. Benchmarks show distilled variants outperform models like OpenAI’s o1‑mini, while remaining open‑source under MIT license.

Mistral Small 3.1
Mistral Small 3.1 is the March 17, 2025 update to Mistral AI's open-source 24B-parameter small model. It offers instruction-following, multimodal vision understanding, and an expanded 128K-token context window, delivering performance on par with or better than GPT‑4o Mini, Gemma 3, and Claude 3.5 Haiku—all while maintaining fast inference speeds (~150 tokens/sec) and running on devices like an RTX 4090 or a 32 GB Mac.
Mistral Small 3.1
Mistral Small 3.1 is the March 17, 2025 update to Mistral AI's open-source 24B-parameter small model. It offers instruction-following, multimodal vision understanding, and an expanded 128K-token context window, delivering performance on par with or better than GPT‑4o Mini, Gemma 3, and Claude 3.5 Haiku—all while maintaining fast inference speeds (~150 tokens/sec) and running on devices like an RTX 4090 or a 32 GB Mac.
Mistral Small 3.1
Mistral Small 3.1 is the March 17, 2025 update to Mistral AI's open-source 24B-parameter small model. It offers instruction-following, multimodal vision understanding, and an expanded 128K-token context window, delivering performance on par with or better than GPT‑4o Mini, Gemma 3, and Claude 3.5 Haiku—all while maintaining fast inference speeds (~150 tokens/sec) and running on devices like an RTX 4090 or a 32 GB Mac.
Open AI GPT 5
GPT-5 is OpenAI’s smartest and most versatile AI model yet, delivering expert-level intelligence across coding, writing, math, health, and multimodal tasks. It is a unified system that dynamically determines when to respond quickly or engage in deeper reasoning, providing accurate and context-aware answers. Powered by advanced neural architectures, GPT-5 significantly reduces hallucinations, enhances instruction following, and excels in real-world applications like software development, creative writing, and health guidance, making it a powerful AI assistant for a broad range of complex tasks and everyday needs.
Open AI GPT 5
GPT-5 is OpenAI’s smartest and most versatile AI model yet, delivering expert-level intelligence across coding, writing, math, health, and multimodal tasks. It is a unified system that dynamically determines when to respond quickly or engage in deeper reasoning, providing accurate and context-aware answers. Powered by advanced neural architectures, GPT-5 significantly reduces hallucinations, enhances instruction following, and excels in real-world applications like software development, creative writing, and health guidance, making it a powerful AI assistant for a broad range of complex tasks and everyday needs.
Open AI GPT 5
GPT-5 is OpenAI’s smartest and most versatile AI model yet, delivering expert-level intelligence across coding, writing, math, health, and multimodal tasks. It is a unified system that dynamically determines when to respond quickly or engage in deeper reasoning, providing accurate and context-aware answers. Powered by advanced neural architectures, GPT-5 significantly reduces hallucinations, enhances instruction following, and excels in real-world applications like software development, creative writing, and health guidance, making it a powerful AI assistant for a broad range of complex tasks and everyday needs.

Command R+ is Cohere’s latest state-of-the-art language model built for enterprise, optimized specifically for retrieval-augmented generation (RAG) workloads at scale. Available first on Microsoft Azure, Command R+ handles complex business data, integrates with secure infrastructure, and powers advanced AI workflows with fast, accurate responses. Designed for reliability, customization, and seamless deployment, it offers enterprises the ability to leverage cutting-edge generative and retrieval technologies across regulated industries.
Command R+ is Cohere’s latest state-of-the-art language model built for enterprise, optimized specifically for retrieval-augmented generation (RAG) workloads at scale. Available first on Microsoft Azure, Command R+ handles complex business data, integrates with secure infrastructure, and powers advanced AI workflows with fast, accurate responses. Designed for reliability, customization, and seamless deployment, it offers enterprises the ability to leverage cutting-edge generative and retrieval technologies across regulated industries.
Command R+ is Cohere’s latest state-of-the-art language model built for enterprise, optimized specifically for retrieval-augmented generation (RAG) workloads at scale. Available first on Microsoft Azure, Command R+ handles complex business data, integrates with secure infrastructure, and powers advanced AI workflows with fast, accurate responses. Designed for reliability, customization, and seamless deployment, it offers enterprises the ability to leverage cutting-edge generative and retrieval technologies across regulated industries.
Command A Reasoning is Cohere’s enterprise-grade large language model optimized for complex reasoning, tool use, and multilingual capabilities. It supports extended context windows of up to 256,000 tokens, enabling advanced workflows involving large documents and conversations. Designed to integrate with external APIs, databases, and search engines, Command A Reasoning excels in transforming complex queries into clear, accurate, and actionable responses. It balances efficiency with powerful reasoning, supporting 23 languages and enabling businesses to deploy reliable, agentic AI solutions tailored for document-heavy and knowledge-intensive environments.
Command A Reasoning is Cohere’s enterprise-grade large language model optimized for complex reasoning, tool use, and multilingual capabilities. It supports extended context windows of up to 256,000 tokens, enabling advanced workflows involving large documents and conversations. Designed to integrate with external APIs, databases, and search engines, Command A Reasoning excels in transforming complex queries into clear, accurate, and actionable responses. It balances efficiency with powerful reasoning, supporting 23 languages and enabling businesses to deploy reliable, agentic AI solutions tailored for document-heavy and knowledge-intensive environments.
Command A Reasoning is Cohere’s enterprise-grade large language model optimized for complex reasoning, tool use, and multilingual capabilities. It supports extended context windows of up to 256,000 tokens, enabling advanced workflows involving large documents and conversations. Designed to integrate with external APIs, databases, and search engines, Command A Reasoning excels in transforming complex queries into clear, accurate, and actionable responses. It balances efficiency with powerful reasoning, supporting 23 languages and enabling businesses to deploy reliable, agentic AI solutions tailored for document-heavy and knowledge-intensive environments.
Editorial Note
This page was researched and written by the ATB Editorial Team. Our team researches each AI tool by reviewing its official website, testing features, exploring real use cases, and considering user feedback. Every page is fact-checked and regularly updated to ensure the information stays accurate, neutral, and useful for our readers.
If you have any suggestions or questions, email us at hello@aitoolbook.ai