
- Content Creators: Produce narration for videos, podcasts, and animations.
- Educators: Generate clear audio for lessons and e-learning modules.
- Marketing Teams: Create branded voiceovers for campaigns.
- Developers: Integrate voice generation into apps or services.
- Businesses: Standardize communication and training voice assets.
- Individuals: Create personalized voices for media projects.
How to Use It?
- Choose or create a voice: Select from library voices or generate your own.
- Enter text: Type or paste the script you need narrated.
- Adjust delivery: Set tone, speed, pitch, emotion, and style.
- Generate audio: Produce high-quality voice output.
- Refine if needed: Modify settings for improved realism.
- Export: Download for use in any project.
- Custom voice creation: Users can clone or build their own AI voice.
- Emotional expressiveness: Voices can convey mood, tone, and intensity.
- Large voice library: Wide selection of natural-sounding voices.
- High-quality synthesis: Crisp, realistic delivery for professional content.
- Scalable production: Batch generation and long-form support.
- Easy workflow: Simple interface with real-time preview.
- Strong emotional voice control.
- Ability to create custom AI voices.
- Very user-friendly interface.
- High realism and clarity.
- Good fit for long-form narrations.
- Flexible export options.
- Custom voices may require high-quality input recordings.
- Emotional accuracy varies across voice models.
- Some advanced features require paid plans.
- Large projects may need time to process.
- Voice style consistency may vary.
- Limited built-in sound design tools.
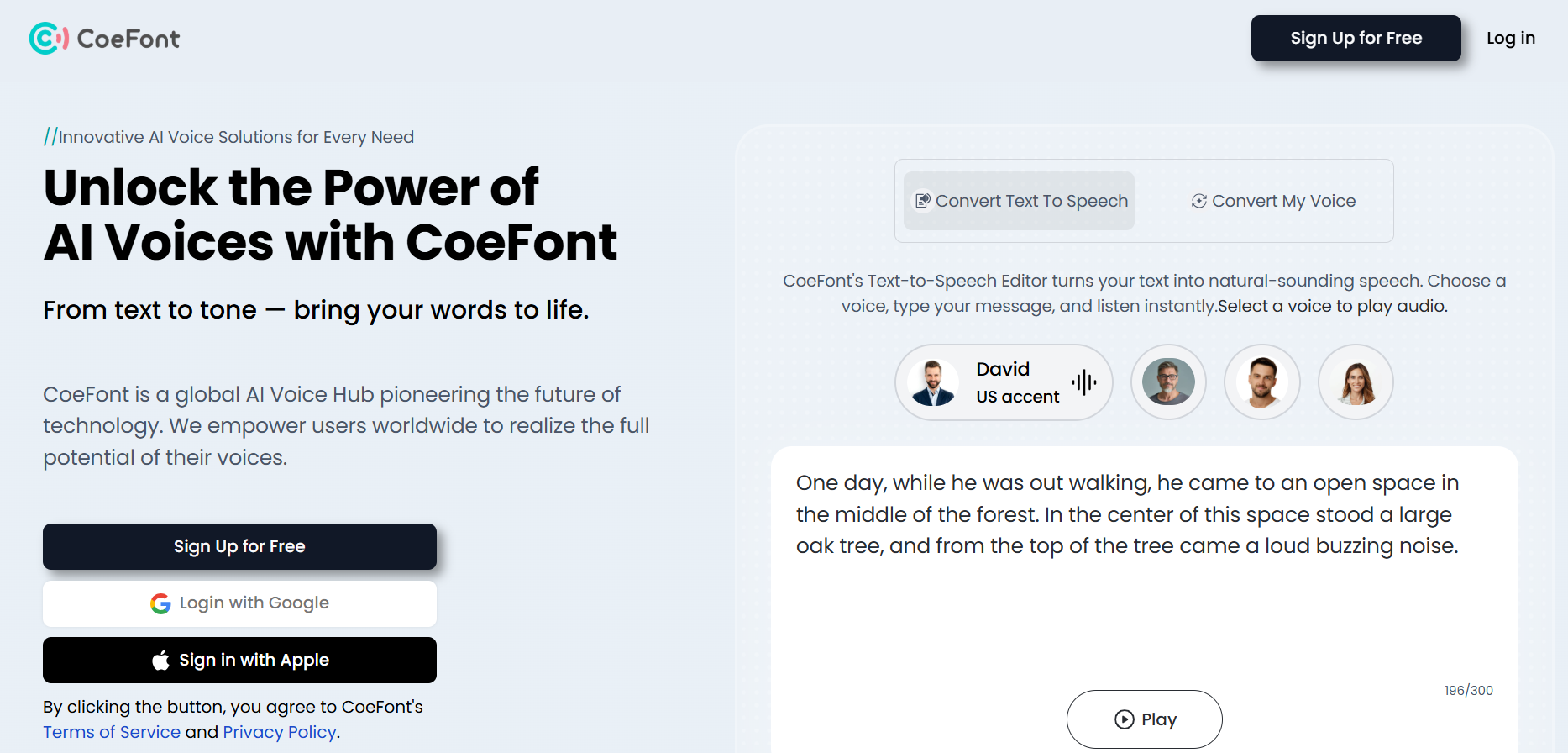
Try it for Free
Free
Premium
Custom Pricing.
Proud of the love you're getting? Show off your AI Toolbook reviews—then invite more fans to share the love and build your credibility.
Add an AI Toolbook badge to your site—an easy way to drive followers, showcase updates, and collect reviews. It's like a mini 24/7 billboard for your AI.
Reviews
Rating Distribution
Average score
Popular Mention
FAQs
Similar AI Tools
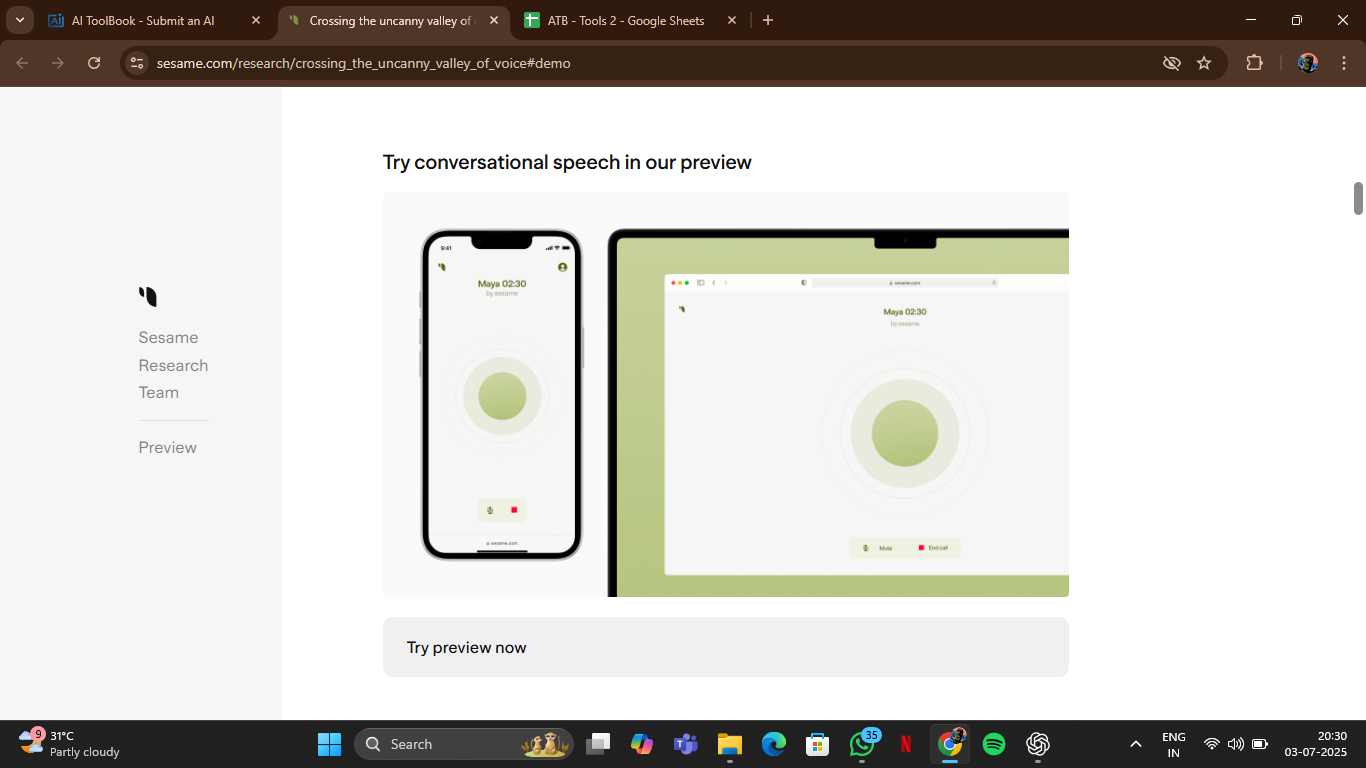
Sesame AI
Sesame Voice AI is a cutting-edge voice synthesis platform that specializes in generating highly realistic and emotionally expressive synthetic voices. Developed by Sesame Labs, this tool bridges the gap between robotic-sounding voice models and human-like speech by incorporating nuanced emotion, context-awareness, and personality into generated audio. Whether it's for games, virtual assistants, films, or branded audio experiences, Sesame aims to "cross the uncanny valley" of voice, producing voices that sound indistinguishably human. It leverages deep learning, large-scale neural networks, and novel techniques in voice conditioning to bring personality-rich, expressive voice capabilities to creators and developers—without needing a real voice actor every time.
Sesame AI
Sesame Voice AI is a cutting-edge voice synthesis platform that specializes in generating highly realistic and emotionally expressive synthetic voices. Developed by Sesame Labs, this tool bridges the gap between robotic-sounding voice models and human-like speech by incorporating nuanced emotion, context-awareness, and personality into generated audio. Whether it's for games, virtual assistants, films, or branded audio experiences, Sesame aims to "cross the uncanny valley" of voice, producing voices that sound indistinguishably human. It leverages deep learning, large-scale neural networks, and novel techniques in voice conditioning to bring personality-rich, expressive voice capabilities to creators and developers—without needing a real voice actor every time.
Sesame AI
Sesame Voice AI is a cutting-edge voice synthesis platform that specializes in generating highly realistic and emotionally expressive synthetic voices. Developed by Sesame Labs, this tool bridges the gap between robotic-sounding voice models and human-like speech by incorporating nuanced emotion, context-awareness, and personality into generated audio. Whether it's for games, virtual assistants, films, or branded audio experiences, Sesame aims to "cross the uncanny valley" of voice, producing voices that sound indistinguishably human. It leverages deep learning, large-scale neural networks, and novel techniques in voice conditioning to bring personality-rich, expressive voice capabilities to creators and developers—without needing a real voice actor every time.
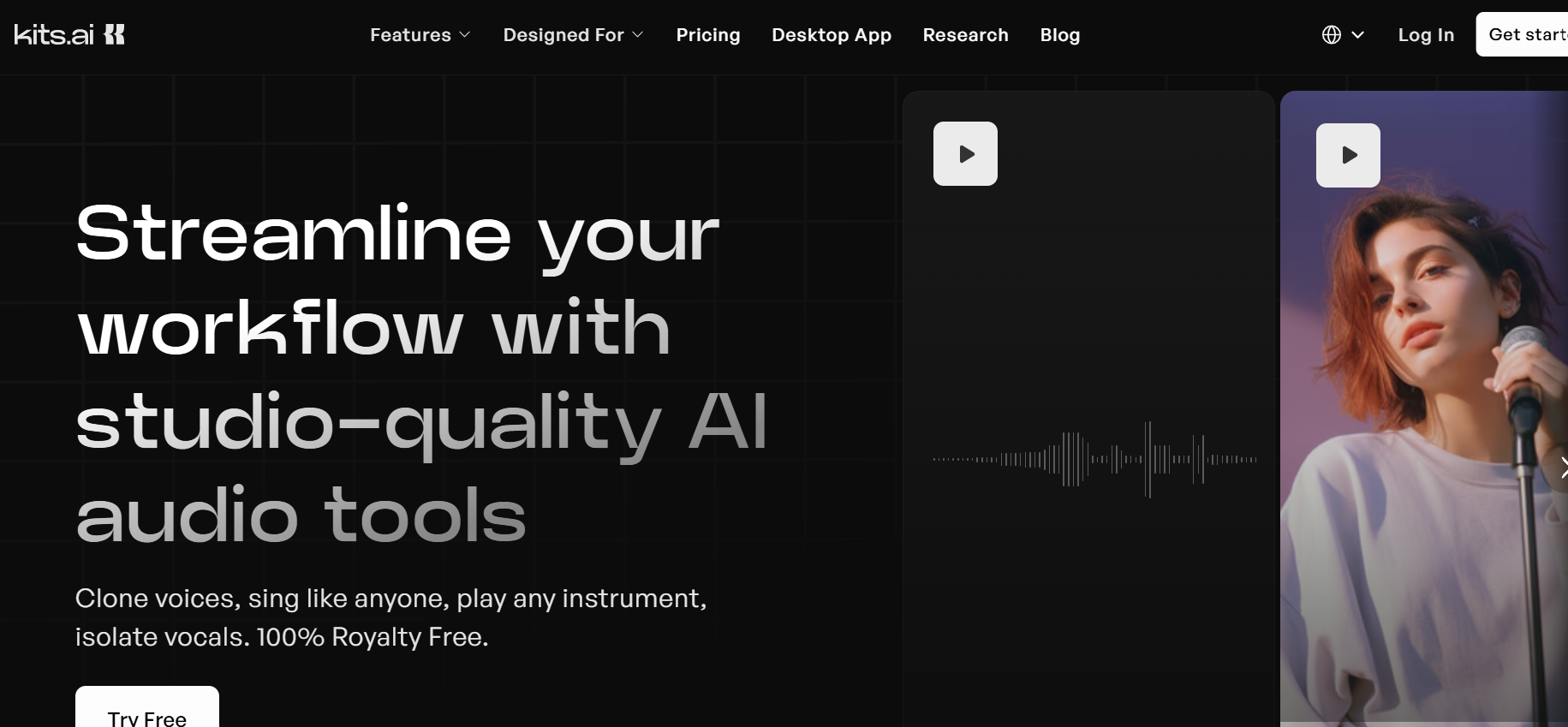

Kits AI
Kits.AI is a studio-quality AI voice toolkit built to turbocharge modern music workflows. From voice cloning, vocal separation, and pitch correction to AI mastering and text-to-voice generation, Kits wraps every essential audio tool into a sleek browser studio. Jump into the revamped Kits Studio interface to upload, record, swap audio, apply effects, and manage projects with ease. With ethically sourced AI voice models—trained on compensated artists—Kits empowers creators to experiment, remix, and generate vocals without legal fuzz or artist exploitation. It’s like having a pro recording booth, vocal lab, and mastering desk all in one browser tab.
Kits AI
Kits.AI is a studio-quality AI voice toolkit built to turbocharge modern music workflows. From voice cloning, vocal separation, and pitch correction to AI mastering and text-to-voice generation, Kits wraps every essential audio tool into a sleek browser studio. Jump into the revamped Kits Studio interface to upload, record, swap audio, apply effects, and manage projects with ease. With ethically sourced AI voice models—trained on compensated artists—Kits empowers creators to experiment, remix, and generate vocals without legal fuzz or artist exploitation. It’s like having a pro recording booth, vocal lab, and mastering desk all in one browser tab.
Kits AI
Kits.AI is a studio-quality AI voice toolkit built to turbocharge modern music workflows. From voice cloning, vocal separation, and pitch correction to AI mastering and text-to-voice generation, Kits wraps every essential audio tool into a sleek browser studio. Jump into the revamped Kits Studio interface to upload, record, swap audio, apply effects, and manage projects with ease. With ethically sourced AI voice models—trained on compensated artists—Kits empowers creators to experiment, remix, and generate vocals without legal fuzz or artist exploitation. It’s like having a pro recording booth, vocal lab, and mastering desk all in one browser tab.
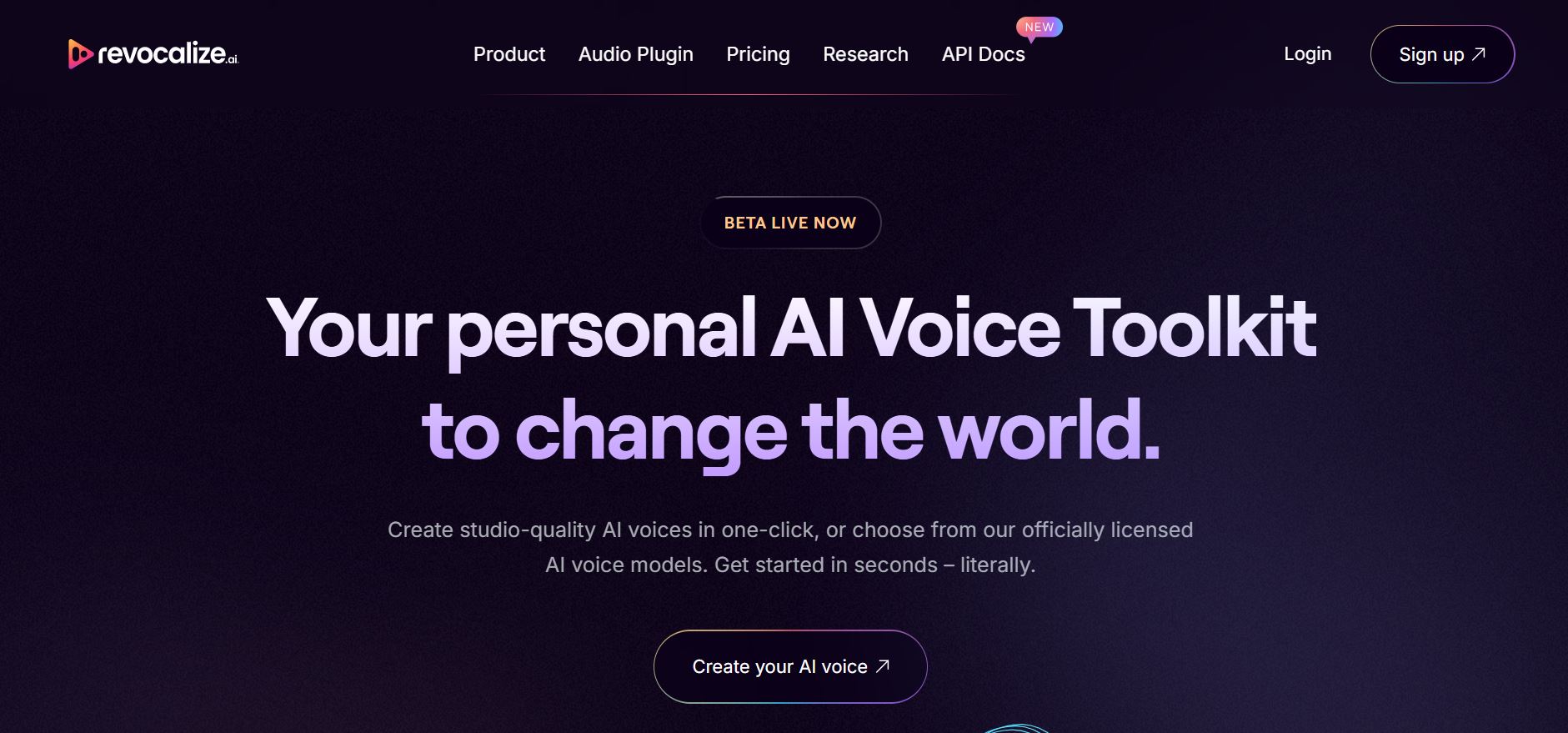

Revocalize AI
Revocalize AI is a next-gen studio-grade voice toolkit that transforms your raw vocals into expressive, polished performance-ready tracks—they call it “Photoshop for voices.” In just one click, you can clone your voice or choose from officially licensed AI voice models, and generate harmonies, covers, or voice conversions with deep emotional nuance. Whether you're releasing your inner rock legend, shining as an R&B maestro, or crafting soulful country demos, it delivers lifelike vocal transformations—complete with real-time auto-pitch, multilingual expressiveness, and a voice fingerprint that secures your unique vocal identity like a digital legacy platform.
Revocalize AI
Revocalize AI is a next-gen studio-grade voice toolkit that transforms your raw vocals into expressive, polished performance-ready tracks—they call it “Photoshop for voices.” In just one click, you can clone your voice or choose from officially licensed AI voice models, and generate harmonies, covers, or voice conversions with deep emotional nuance. Whether you're releasing your inner rock legend, shining as an R&B maestro, or crafting soulful country demos, it delivers lifelike vocal transformations—complete with real-time auto-pitch, multilingual expressiveness, and a voice fingerprint that secures your unique vocal identity like a digital legacy platform.
Revocalize AI
Revocalize AI is a next-gen studio-grade voice toolkit that transforms your raw vocals into expressive, polished performance-ready tracks—they call it “Photoshop for voices.” In just one click, you can clone your voice or choose from officially licensed AI voice models, and generate harmonies, covers, or voice conversions with deep emotional nuance. Whether you're releasing your inner rock legend, shining as an R&B maestro, or crafting soulful country demos, it delivers lifelike vocal transformations—complete with real-time auto-pitch, multilingual expressiveness, and a voice fingerprint that secures your unique vocal identity like a digital legacy platform.
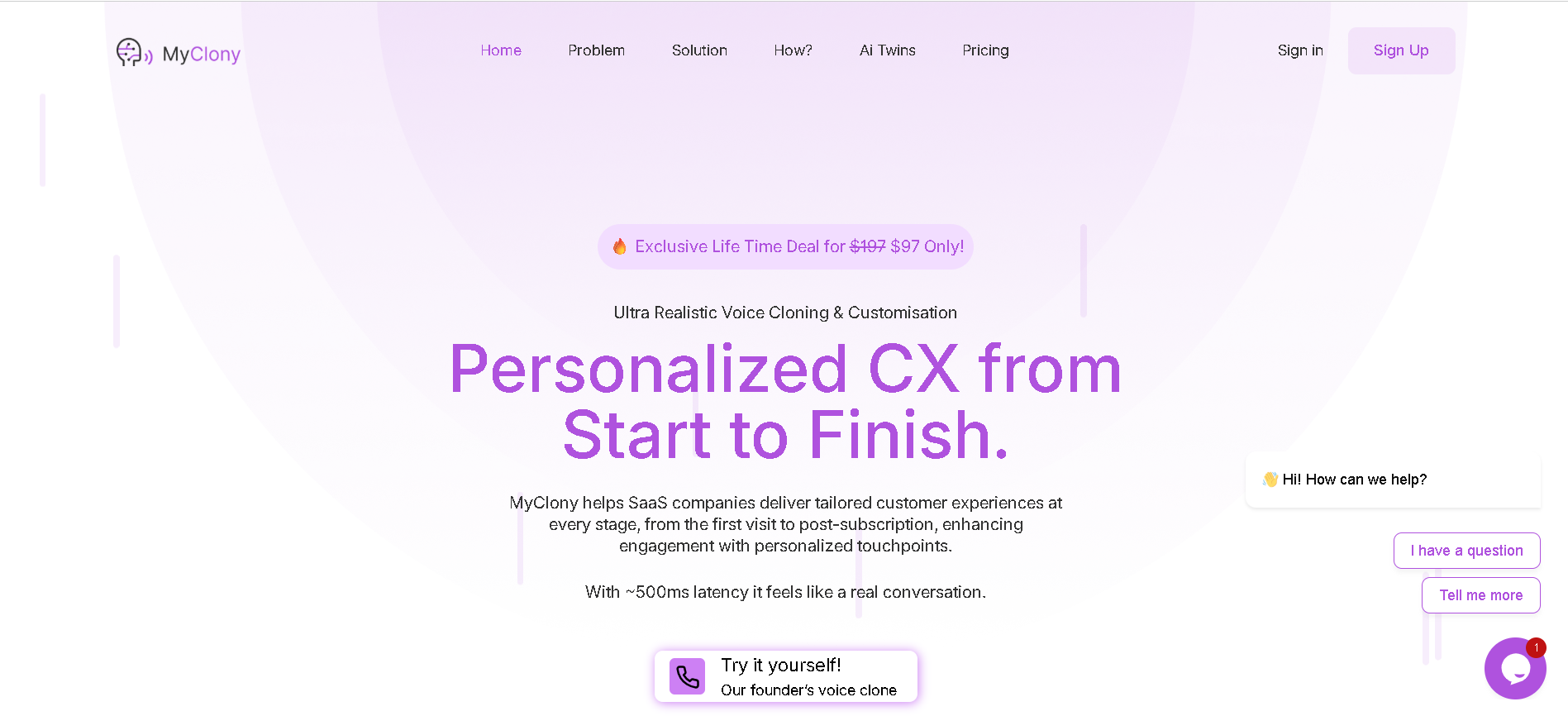
MyClony
Myclony is an AI-powered interactive voice cloning platform designed to enhance customer experience for SaaS companies. It creates personalized "Voice Twins" that provide real-time, human-like assistance, helping businesses to automate customer support and sales processes while fostering deeper emotional connections and trust.
MyClony
Myclony is an AI-powered interactive voice cloning platform designed to enhance customer experience for SaaS companies. It creates personalized "Voice Twins" that provide real-time, human-like assistance, helping businesses to automate customer support and sales processes while fostering deeper emotional connections and trust.
MyClony
Myclony is an AI-powered interactive voice cloning platform designed to enhance customer experience for SaaS companies. It creates personalized "Voice Twins" that provide real-time, human-like assistance, helping businesses to automate customer support and sales processes while fostering deeper emotional connections and trust.
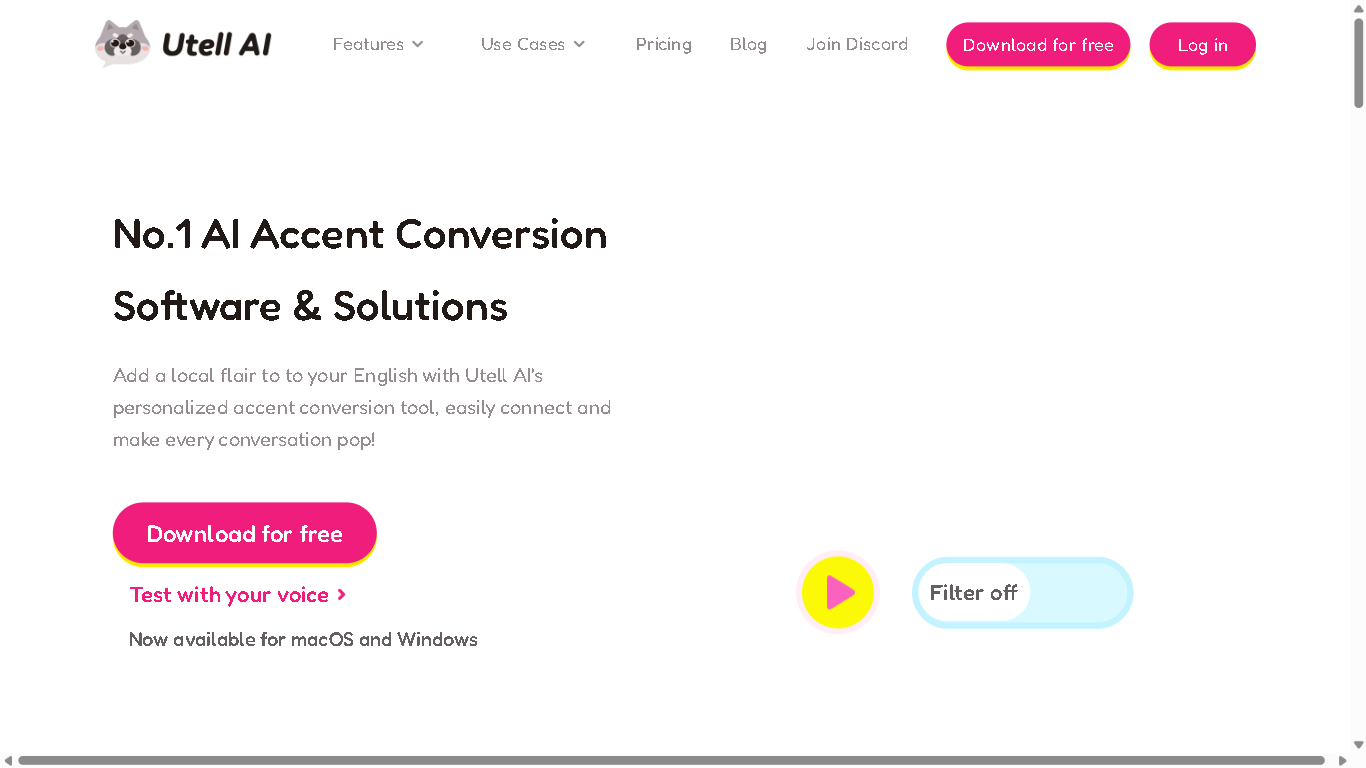
Utell AI
Utell AI is an advanced AI-powered accent conversion platform that helps individuals and businesses improve communication by refining non-native English accents in real-time. It provides a seamless experience for enhancing clarity, preserving natural voice characteristics, and facilitating smooth interactions across meetings, calls, gaming, and online streaming.
Utell AI
Utell AI is an advanced AI-powered accent conversion platform that helps individuals and businesses improve communication by refining non-native English accents in real-time. It provides a seamless experience for enhancing clarity, preserving natural voice characteristics, and facilitating smooth interactions across meetings, calls, gaming, and online streaming.
Utell AI
Utell AI is an advanced AI-powered accent conversion platform that helps individuals and businesses improve communication by refining non-native English accents in real-time. It provides a seamless experience for enhancing clarity, preserving natural voice characteristics, and facilitating smooth interactions across meetings, calls, gaming, and online streaming.
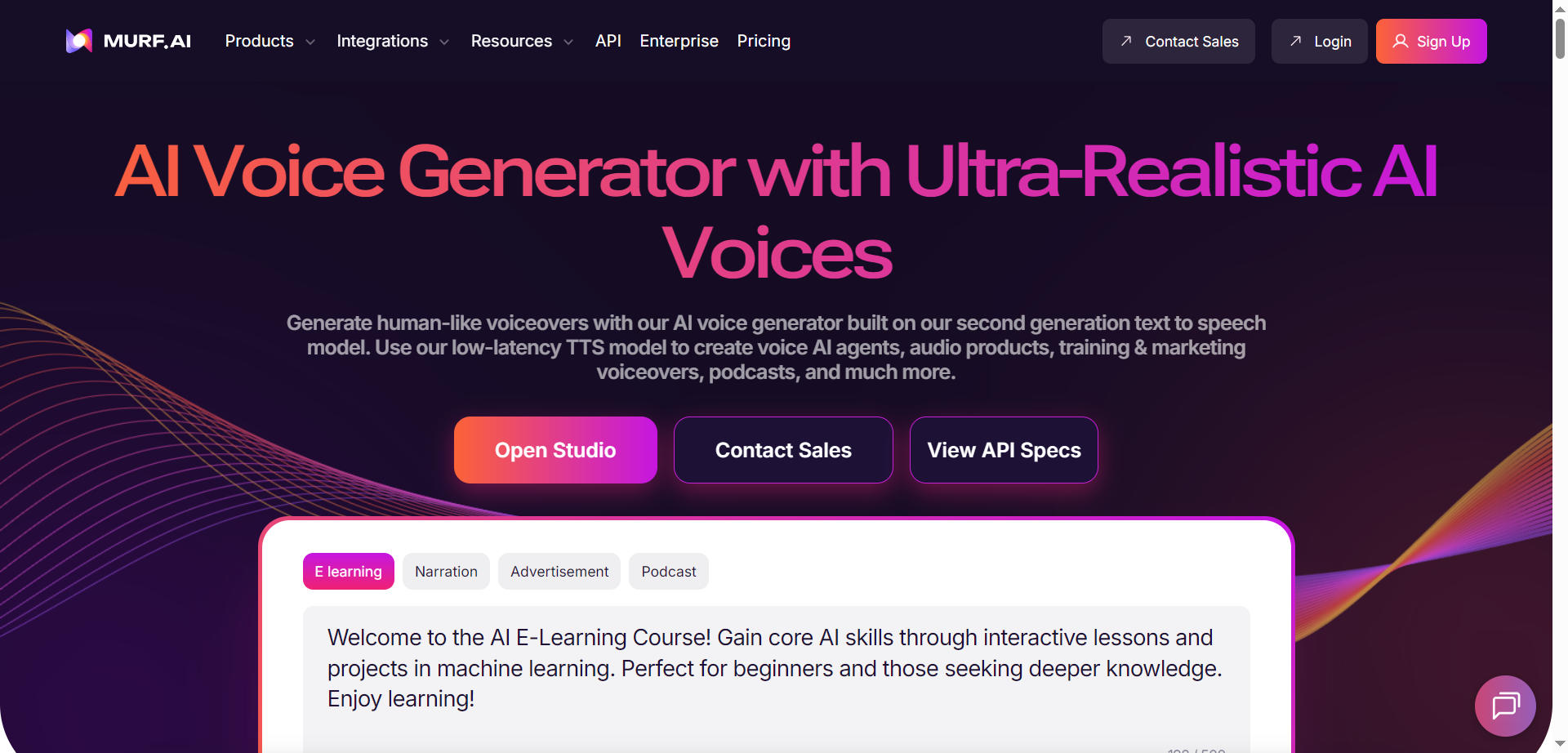

Murf.ai
Murf.ai is an AI voice generator and text-to-speech platform that delivers ultra-realistic voiceovers for creators, teams, and developers. It offers 200+ multilingual voices, 10+ speaking styles, and fine-grained controls over pitch, speed, tone, prosody, and pronunciation. A low-latency TTS model powers conversational agents with sub-200 ms response, while APIs enable voice cloning, voice changing, streaming TTS, and translation/dubbing in 30+ languages. A studio workspace supports scripting, timing, and rapid iteration for ads, training, audiobooks, podcasts, and product audio. Pronunciation libraries, team workspaces, and tool integrations help standardize brand voice at scale without complex audio engineering.
Murf.ai
Murf.ai is an AI voice generator and text-to-speech platform that delivers ultra-realistic voiceovers for creators, teams, and developers. It offers 200+ multilingual voices, 10+ speaking styles, and fine-grained controls over pitch, speed, tone, prosody, and pronunciation. A low-latency TTS model powers conversational agents with sub-200 ms response, while APIs enable voice cloning, voice changing, streaming TTS, and translation/dubbing in 30+ languages. A studio workspace supports scripting, timing, and rapid iteration for ads, training, audiobooks, podcasts, and product audio. Pronunciation libraries, team workspaces, and tool integrations help standardize brand voice at scale without complex audio engineering.
Murf.ai
Murf.ai is an AI voice generator and text-to-speech platform that delivers ultra-realistic voiceovers for creators, teams, and developers. It offers 200+ multilingual voices, 10+ speaking styles, and fine-grained controls over pitch, speed, tone, prosody, and pronunciation. A low-latency TTS model powers conversational agents with sub-200 ms response, while APIs enable voice cloning, voice changing, streaming TTS, and translation/dubbing in 30+ languages. A studio workspace supports scripting, timing, and rapid iteration for ads, training, audiobooks, podcasts, and product audio. Pronunciation libraries, team workspaces, and tool integrations help standardize brand voice at scale without complex audio engineering.
PlayAI
Play.ht is an AI voice generator and text-to-speech platform for creating humanlike voiceovers in minutes. It offers a large, growing library of natural voices across 30+ languages and accents, with controls for pitch, pace, emphasis, pauses, and SSML. Dialog-enabled generation supports multi-speaker, multi-turn conversations in a single file, ideal for podcasts and character-driven audio. Teams can define and reuse pronunciations for brand terms, preview segments, and fine-tune emotion and speaking styles. Voice cloning and custom voice creation enable consistent brand sound, while ultra-low-latency streaming suits live apps. Use cases span videos, audiobooks, training, assistants, games, IVR, and localization.
PlayAI
Play.ht is an AI voice generator and text-to-speech platform for creating humanlike voiceovers in minutes. It offers a large, growing library of natural voices across 30+ languages and accents, with controls for pitch, pace, emphasis, pauses, and SSML. Dialog-enabled generation supports multi-speaker, multi-turn conversations in a single file, ideal for podcasts and character-driven audio. Teams can define and reuse pronunciations for brand terms, preview segments, and fine-tune emotion and speaking styles. Voice cloning and custom voice creation enable consistent brand sound, while ultra-low-latency streaming suits live apps. Use cases span videos, audiobooks, training, assistants, games, IVR, and localization.
PlayAI
Play.ht is an AI voice generator and text-to-speech platform for creating humanlike voiceovers in minutes. It offers a large, growing library of natural voices across 30+ languages and accents, with controls for pitch, pace, emphasis, pauses, and SSML. Dialog-enabled generation supports multi-speaker, multi-turn conversations in a single file, ideal for podcasts and character-driven audio. Teams can define and reuse pronunciations for brand terms, preview segments, and fine-tune emotion and speaking styles. Voice cloning and custom voice creation enable consistent brand sound, while ultra-low-latency streaming suits live apps. Use cases span videos, audiobooks, training, assistants, games, IVR, and localization.
FakeYou
FakeYou is a community-driven AI voice platform that converts text into speech using a large catalog of celebrity, character, and creator-trained voices. It emphasizes ease of use for quick meme audio, voiceovers, and creative projects, while also supporting longer scripts with stable generation. Users select from many fan-made and studio-quality voice models, then fine-tune outputs with controls like pace and emphasis for better delivery. The platform focuses on fun, experimentation, and shareability, letting creators generate clips for videos, streams, and social posts. With a lively community and frequent new voices, FakeYou makes voice cloning and character TTS accessible for everyday content creation.
FakeYou
FakeYou is a community-driven AI voice platform that converts text into speech using a large catalog of celebrity, character, and creator-trained voices. It emphasizes ease of use for quick meme audio, voiceovers, and creative projects, while also supporting longer scripts with stable generation. Users select from many fan-made and studio-quality voice models, then fine-tune outputs with controls like pace and emphasis for better delivery. The platform focuses on fun, experimentation, and shareability, letting creators generate clips for videos, streams, and social posts. With a lively community and frequent new voices, FakeYou makes voice cloning and character TTS accessible for everyday content creation.
FakeYou
FakeYou is a community-driven AI voice platform that converts text into speech using a large catalog of celebrity, character, and creator-trained voices. It emphasizes ease of use for quick meme audio, voiceovers, and creative projects, while also supporting longer scripts with stable generation. Users select from many fan-made and studio-quality voice models, then fine-tune outputs with controls like pace and emphasis for better delivery. The platform focuses on fun, experimentation, and shareability, letting creators generate clips for videos, streams, and social posts. With a lively community and frequent new voices, FakeYou makes voice cloning and character TTS accessible for everyday content creation.

AI Song
AI Song is an innovative AI-powered music creation platform that makes studio-quality music production accessible to everyone. By leveraging next-generation artificial intelligence, AI Song enables users to instantly generate professional music, unique melodies, harmonies, and rhythms simply by describing the desired style, mood, and genre. The platform offers a free song generator, quick conversion from text or lyrics to complete compositions, and studio-grade audio output—no watermarks, full commercial rights, and no musical experience required. With support for 30+ genres and multilingual capabilities, AI Song eliminates the need for costly studio sessions and lengthy production processes, making creative music creation fast and effortless.
AI Song
AI Song is an innovative AI-powered music creation platform that makes studio-quality music production accessible to everyone. By leveraging next-generation artificial intelligence, AI Song enables users to instantly generate professional music, unique melodies, harmonies, and rhythms simply by describing the desired style, mood, and genre. The platform offers a free song generator, quick conversion from text or lyrics to complete compositions, and studio-grade audio output—no watermarks, full commercial rights, and no musical experience required. With support for 30+ genres and multilingual capabilities, AI Song eliminates the need for costly studio sessions and lengthy production processes, making creative music creation fast and effortless.
AI Song
AI Song is an innovative AI-powered music creation platform that makes studio-quality music production accessible to everyone. By leveraging next-generation artificial intelligence, AI Song enables users to instantly generate professional music, unique melodies, harmonies, and rhythms simply by describing the desired style, mood, and genre. The platform offers a free song generator, quick conversion from text or lyrics to complete compositions, and studio-grade audio output—no watermarks, full commercial rights, and no musical experience required. With support for 30+ genres and multilingual capabilities, AI Song eliminates the need for costly studio sessions and lengthy production processes, making creative music creation fast and effortless.
AI Awaaz
Ai Awaaz is a text-to-speech (TTS) and voice-generation platform developed in India and marketed as India’s first emotion-based TTS AI engine. It enables users to convert text into natural-sounding voiceovers in 20+ Indian languages and 140+ voices, with selectable emotions (e.g., cheerful, sad, whispering) and export formats suitable for videos, podcasts, audiobooks and e-learning modules. The platform emphasises speed and scalability, claiming that a voiceover can be created in just minutes, compared to traditional voice-actor turnaround times. It is positioned for marketers, educators, content creators and agencies needing multi-language voice production with minimal friction.
AI Awaaz
Ai Awaaz is a text-to-speech (TTS) and voice-generation platform developed in India and marketed as India’s first emotion-based TTS AI engine. It enables users to convert text into natural-sounding voiceovers in 20+ Indian languages and 140+ voices, with selectable emotions (e.g., cheerful, sad, whispering) and export formats suitable for videos, podcasts, audiobooks and e-learning modules. The platform emphasises speed and scalability, claiming that a voiceover can be created in just minutes, compared to traditional voice-actor turnaround times. It is positioned for marketers, educators, content creators and agencies needing multi-language voice production with minimal friction.
AI Awaaz
Ai Awaaz is a text-to-speech (TTS) and voice-generation platform developed in India and marketed as India’s first emotion-based TTS AI engine. It enables users to convert text into natural-sounding voiceovers in 20+ Indian languages and 140+ voices, with selectable emotions (e.g., cheerful, sad, whispering) and export formats suitable for videos, podcasts, audiobooks and e-learning modules. The platform emphasises speed and scalability, claiming that a voiceover can be created in just minutes, compared to traditional voice-actor turnaround times. It is positioned for marketers, educators, content creators and agencies needing multi-language voice production with minimal friction.
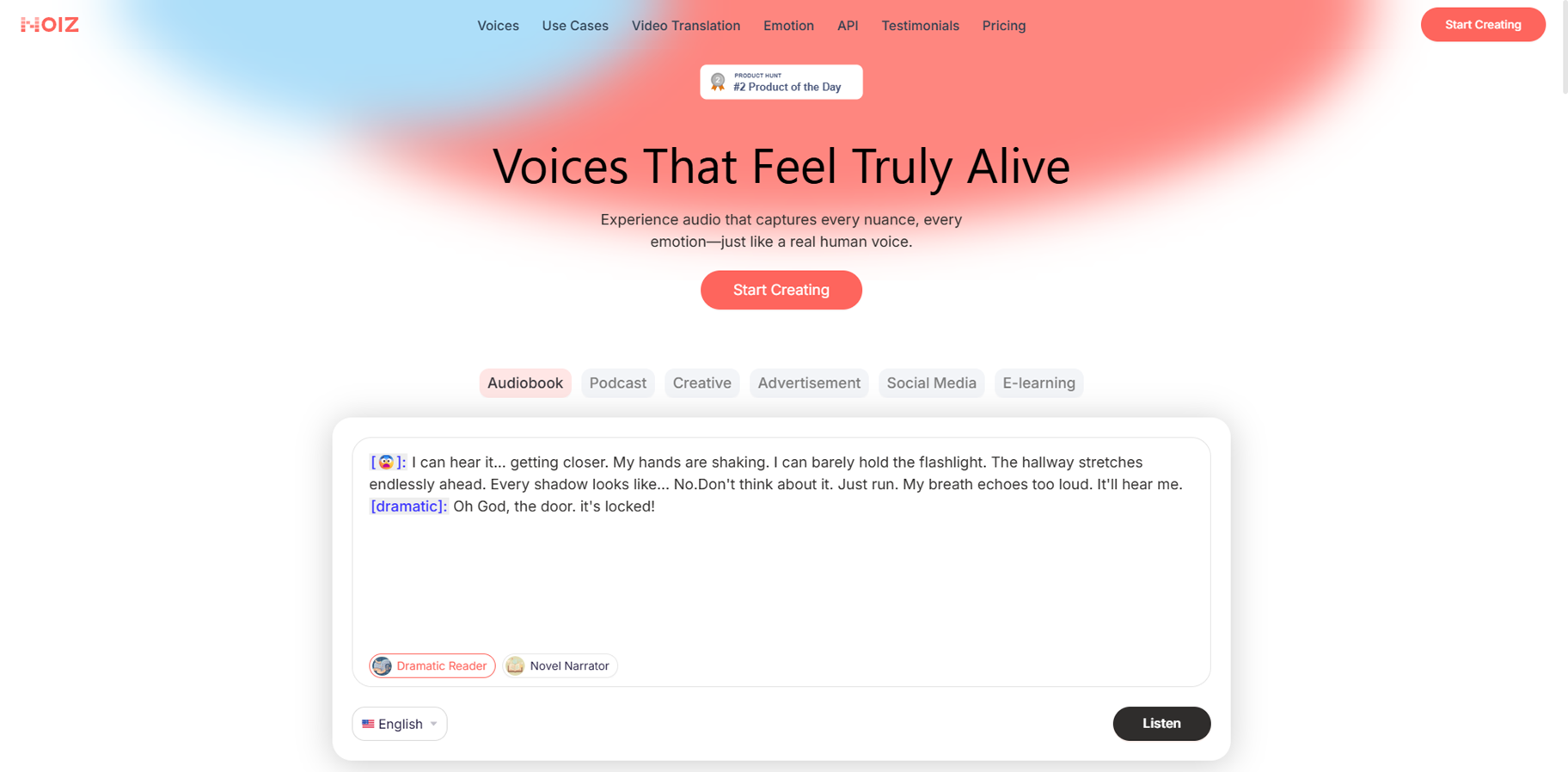

Noiz
Noiz is a leading AI platform for advanced speech synthesis and audio generation, specializing in highly expressive, lifelike voices with emotional control and customization. It offers text-to-speech , voice cloning, multilingual dubbing, AI singing voice generation, and developer APIs for seamless integration into apps. Users can create realistic vocals with nuance, vibrato, and dynamics from simple prompts, supporting video translation, audio editing, and music production. The tool excels in cost-efficiency, handling everything from podcast mastering to viral song covers, with features like noise removal, auto-leveling, and scene-based soundscapes. Ideal for creators seeking professional audio without studios.
Noiz
Noiz is a leading AI platform for advanced speech synthesis and audio generation, specializing in highly expressive, lifelike voices with emotional control and customization. It offers text-to-speech , voice cloning, multilingual dubbing, AI singing voice generation, and developer APIs for seamless integration into apps. Users can create realistic vocals with nuance, vibrato, and dynamics from simple prompts, supporting video translation, audio editing, and music production. The tool excels in cost-efficiency, handling everything from podcast mastering to viral song covers, with features like noise removal, auto-leveling, and scene-based soundscapes. Ideal for creators seeking professional audio without studios.
Noiz
Noiz is a leading AI platform for advanced speech synthesis and audio generation, specializing in highly expressive, lifelike voices with emotional control and customization. It offers text-to-speech , voice cloning, multilingual dubbing, AI singing voice generation, and developer APIs for seamless integration into apps. Users can create realistic vocals with nuance, vibrato, and dynamics from simple prompts, supporting video translation, audio editing, and music production. The tool excels in cost-efficiency, handling everything from podcast mastering to viral song covers, with features like noise removal, auto-leveling, and scene-based soundscapes. Ideal for creators seeking professional audio without studios.
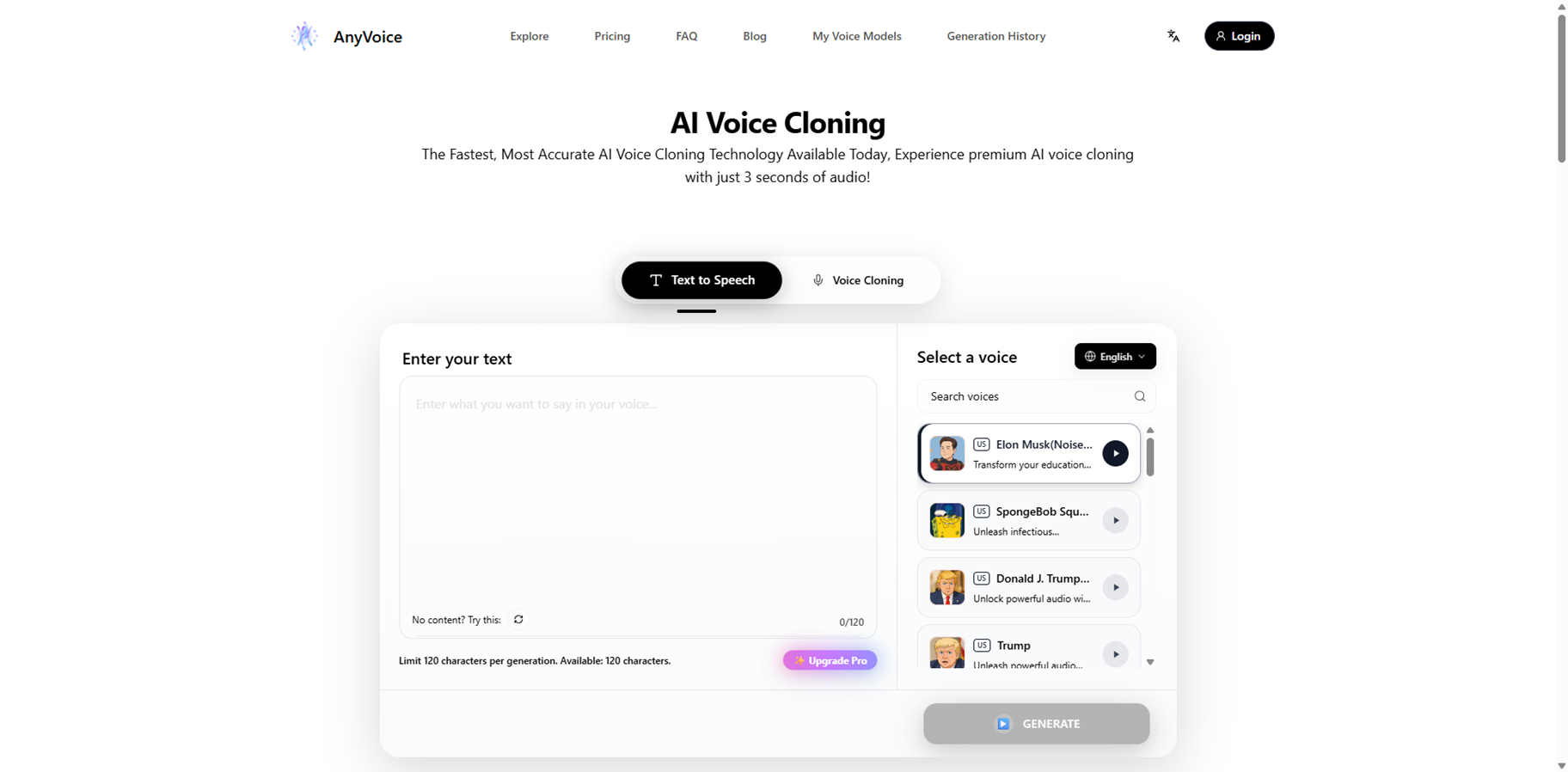

AnyVoice
AnyVoice brings the world's fastest AI voice cloning, turning just 3 seconds of audio into hyper-realistic speech that nails every nuance and emotion. Pick from English, Chinese Mandarin, Japanese, or Korean, enter your text, select the cloned voice, and get instant lifelike output—no long recordings or tech skills needed. Perfect for quick voiceovers, prototyping, or dynamic content, it delivers indistinguishable-from-human results securely with user privacy front and center. Free tier offers 900 seconds monthly and 5 clones; Pro unlocks unlimited everything and commercial rights. Streamlined interface makes pro-level cloning accessible to anyone, speeding up creation like never before.
AnyVoice
AnyVoice brings the world's fastest AI voice cloning, turning just 3 seconds of audio into hyper-realistic speech that nails every nuance and emotion. Pick from English, Chinese Mandarin, Japanese, or Korean, enter your text, select the cloned voice, and get instant lifelike output—no long recordings or tech skills needed. Perfect for quick voiceovers, prototyping, or dynamic content, it delivers indistinguishable-from-human results securely with user privacy front and center. Free tier offers 900 seconds monthly and 5 clones; Pro unlocks unlimited everything and commercial rights. Streamlined interface makes pro-level cloning accessible to anyone, speeding up creation like never before.
AnyVoice
AnyVoice brings the world's fastest AI voice cloning, turning just 3 seconds of audio into hyper-realistic speech that nails every nuance and emotion. Pick from English, Chinese Mandarin, Japanese, or Korean, enter your text, select the cloned voice, and get instant lifelike output—no long recordings or tech skills needed. Perfect for quick voiceovers, prototyping, or dynamic content, it delivers indistinguishable-from-human results securely with user privacy front and center. Free tier offers 900 seconds monthly and 5 clones; Pro unlocks unlimited everything and commercial rights. Streamlined interface makes pro-level cloning accessible to anyone, speeding up creation like never before.
Editorial Note
This page was researched and written by the ATB Editorial Team. Our team researches each AI tool by reviewing its official website, testing features, exploring real use cases, and considering user feedback. Every page is fact-checked and regularly updated to ensure the information stays accurate, neutral, and useful for our readers.
If you have any suggestions or questions, email us at hello@aitoolbook.ai