
- Singers & Vocalists: Clone your voice, clean up your takes, or reimagine performances using AI tweaks.
- Music Producers & Remix Artists: Isolate stems, blend voices, add choir effects, or master tracks without conventional gear.
- Songwriters & Arrangers: Turn lyrics into singing, layer harmonies, and play with vocal textures for demos or releases.
- Audio Engineers & Creators: Smooth pitch, sculpt tone, and polish vocals using built-in mastering and effects.
- Indie Artists & DIY Filmmakers: Produce clean, catchy vocals and audio without needing a full studio stack.
How to Use Kits.AI?
- Log In via Browser: Access Kits Studio with Google, Discord, or other sign-on options.
- Upload or Record: Drag your vocal file in or record directly—visual waveform helps you stay on track.
- Choose Voice Model: Pick from royalty-free Kits voices or switch to your own cloned model in one click.
- Apply Effects: Use pitch correction, EQ, compression, reverb, delay, stereo widening, and more—live edits in studio.
- Swap Audio Seamlessly: Swap input tracks without losing your effects or voice-model selection.
- Manage Projects: Save, revisit, edit, or delete vocal projects—all organized neatly within the interface.
- Export or Upgrade: Download your creation and, if needed, upgrade to access higher-quality output or advanced tools.
- End-to-End Vocal Studio in a Browser: Record, edit, clone, effect, and export—all without downloads or plugins.
- Ethical Voice Models: Built on fairly licensed vocal data—so artists are compensated and rights are respected.
- Feature-Rich Workflow: Voice cloning, vocal remover, stem splitting, AI mastering, pitch tuning, and more—all in one place.
- Intuitive Studio UX: Sleek layout, project history, easy model swaps, effects panel—design that welcomes both pros and newbies.
- Browser-based ease—no installs, just creativity.
- Deep vocal feature set—covering creation, mixing, mastering, and cloning.
- Ethically sourced models mean creators can work with peace of mind.
- Visual project management keeps you organized and fast.
- Perfect for musicians on the move or those craving quick demos.
- Advanced features and high-quality export likely require a paid tier.
- New users might feel a bit overwhelmed by the tool-rich interface at first.
- Relies on internet connection—offline workflow isn’t supported.
- Mobile access may be limited compared to desktop experience.
FREE
$0
- 15 conversion minutes
- 0 voice slots
- 0 download minutes
- Voice designer/blender
- Kits generative vocals
STARTER
$8/M
- Unlimited conversions
- 2 voice slots
- 15 downloads minutes
- Instant voice cloning
- Advanced settings
- Choir tool
PRODUCER
$16/M
- Unlimited conversions
- 5 voice slots
- 60 download minutes
- Everything on Starter
- Singing voice synthesizer
- Professional voice clone
PROFESSIONAL
$40/M
- Unlimited conversions
- 12 voice slots
- Unlimited download minutes
- Everything on Producer
Proud of the love you're getting? Show off your AI Toolbook reviews—then invite more fans to share the love and build your credibility.
Add an AI Toolbook badge to your site—an easy way to drive followers, showcase updates, and collect reviews. It's like a mini 24/7 billboard for your AI.
Reviews
Rating Distribution
Average score
Popular Mention
FAQs
Similar AI Tools

Audimee
Audimee is a next-gen AI vocal platform that empowers creators to convert their vocals using royalty-free AI voices, train custom voice models, isolate and mix vocals, and produce harmonies—all with commercial-ready, copyright-free flexibility.
Audimee
Audimee is a next-gen AI vocal platform that empowers creators to convert their vocals using royalty-free AI voices, train custom voice models, isolate and mix vocals, and produce harmonies—all with commercial-ready, copyright-free flexibility.
Audimee
Audimee is a next-gen AI vocal platform that empowers creators to convert their vocals using royalty-free AI voices, train custom voice models, isolate and mix vocals, and produce harmonies—all with commercial-ready, copyright-free flexibility.


Vocaloid
VOCALOID is the iconic singing synthesizer engine crafted by Yamaha, empowering creators to instantly generate expressive, lifelike vocals straight from your lyrics and melody. With its latest iteration, VOCALOID6, it leverages AI-powered enhancements to deliver even more natural singing characteristics—like nuanced vibrato, rhythms, and harmonization—without requiring human vocalists. Use its multilingual voicebanks to combine Japanese, English, and Chinese lyrics in a single track, layer choir parts, or even replicate your own stylings with the VOCALO CHANGER. Whether you're sketching demo vocals or sculpting polished performances, VOCALOID puts world-class vocal production at your fingertips.
Vocaloid
VOCALOID is the iconic singing synthesizer engine crafted by Yamaha, empowering creators to instantly generate expressive, lifelike vocals straight from your lyrics and melody. With its latest iteration, VOCALOID6, it leverages AI-powered enhancements to deliver even more natural singing characteristics—like nuanced vibrato, rhythms, and harmonization—without requiring human vocalists. Use its multilingual voicebanks to combine Japanese, English, and Chinese lyrics in a single track, layer choir parts, or even replicate your own stylings with the VOCALO CHANGER. Whether you're sketching demo vocals or sculpting polished performances, VOCALOID puts world-class vocal production at your fingertips.
Vocaloid
VOCALOID is the iconic singing synthesizer engine crafted by Yamaha, empowering creators to instantly generate expressive, lifelike vocals straight from your lyrics and melody. With its latest iteration, VOCALOID6, it leverages AI-powered enhancements to deliver even more natural singing characteristics—like nuanced vibrato, rhythms, and harmonization—without requiring human vocalists. Use its multilingual voicebanks to combine Japanese, English, and Chinese lyrics in a single track, layer choir parts, or even replicate your own stylings with the VOCALO CHANGER. Whether you're sketching demo vocals or sculpting polished performances, VOCALOID puts world-class vocal production at your fingertips.
Voice Isolator
Voice Isolator is an AI-powered audio tool focused on cleaning up recordings by isolating speech/vocals and removing unwanted background noise or interference. It’s useful for podcasts, interviews, videos, or any situation with noisy audio. You can upload or directly record audio/video files, let the AI analyze and separate or enhance the speech component, then download the cleaned output. Quality tends to be high; the tool deals with things like ambient noise, reverb, chatter, or music in the background while trying to preserve clarity of the voice.
Voice Isolator
Voice Isolator is an AI-powered audio tool focused on cleaning up recordings by isolating speech/vocals and removing unwanted background noise or interference. It’s useful for podcasts, interviews, videos, or any situation with noisy audio. You can upload or directly record audio/video files, let the AI analyze and separate or enhance the speech component, then download the cleaned output. Quality tends to be high; the tool deals with things like ambient noise, reverb, chatter, or music in the background while trying to preserve clarity of the voice.
Voice Isolator
Voice Isolator is an AI-powered audio tool focused on cleaning up recordings by isolating speech/vocals and removing unwanted background noise or interference. It’s useful for podcasts, interviews, videos, or any situation with noisy audio. You can upload or directly record audio/video files, let the AI analyze and separate or enhance the speech component, then download the cleaned output. Quality tends to be high; the tool deals with things like ambient noise, reverb, chatter, or music in the background while trying to preserve clarity of the voice.

Wondera
Wondera is an AI music co-creator and visualizer platform that helps musicians and creators generate, edit, and publish original music and synced music videos from simple prompts or uploaded references. It blends an AI music generator, stem editor, voice conversion, and effect controls with a free music video generator that aligns visuals to rhythm and mood. Users can refine melodies, swap instruments, change genres, and craft artist personas, then publish or download tracks for use in videos, podcasts, and social media. With mobile apps and web tools, Wondera streamlines end‑to‑end music production, from idea to mastered audio and dynamic visuals.
Wondera
Wondera is an AI music co-creator and visualizer platform that helps musicians and creators generate, edit, and publish original music and synced music videos from simple prompts or uploaded references. It blends an AI music generator, stem editor, voice conversion, and effect controls with a free music video generator that aligns visuals to rhythm and mood. Users can refine melodies, swap instruments, change genres, and craft artist personas, then publish or download tracks for use in videos, podcasts, and social media. With mobile apps and web tools, Wondera streamlines end‑to‑end music production, from idea to mastered audio and dynamic visuals.
Wondera
Wondera is an AI music co-creator and visualizer platform that helps musicians and creators generate, edit, and publish original music and synced music videos from simple prompts or uploaded references. It blends an AI music generator, stem editor, voice conversion, and effect controls with a free music video generator that aligns visuals to rhythm and mood. Users can refine melodies, swap instruments, change genres, and craft artist personas, then publish or download tracks for use in videos, podcasts, and social media. With mobile apps and web tools, Wondera streamlines end‑to‑end music production, from idea to mastered audio and dynamic visuals.
Voiceslab
Voiceslab is an AI voice cloning and synthesis platform that enables users to create digital replicas of their voice from a short audio sample. By uploading or recording about 10–60 seconds of speech, the system analyzes tone, speech patterns, and style to generate a custom voice model. After that, users can input text to produce natural-sounding speech in their cloned voice across multiple languages. The tool is suited for content creators, marketers, podcasters, and businesses wanting to scale voice content without repeated recording.
Voiceslab
Voiceslab is an AI voice cloning and synthesis platform that enables users to create digital replicas of their voice from a short audio sample. By uploading or recording about 10–60 seconds of speech, the system analyzes tone, speech patterns, and style to generate a custom voice model. After that, users can input text to produce natural-sounding speech in their cloned voice across multiple languages. The tool is suited for content creators, marketers, podcasters, and businesses wanting to scale voice content without repeated recording.
Voiceslab
Voiceslab is an AI voice cloning and synthesis platform that enables users to create digital replicas of their voice from a short audio sample. By uploading or recording about 10–60 seconds of speech, the system analyzes tone, speech patterns, and style to generate a custom voice model. After that, users can input text to produce natural-sounding speech in their cloned voice across multiple languages. The tool is suited for content creators, marketers, podcasters, and businesses wanting to scale voice content without repeated recording.
Lovo
LOVO AI is a voiceover and video creation platform that combines an advanced text-to-speech engine with an online editor to produce natural, production-ready audio and visuals. With 500+ voices across 100+ languages, it enables rapid creation of voiceovers for marketing, e-learning, podcasts, social content, and more. Its Genny workspace adds scriptwriting, voice cloning, auto-subtitles, and AI image generation to streamline end-to-end production. Directable Pro V2 voices allow nuanced control of tone and delivery using natural language directions. Teams can collaborate in the cloud, export quickly, and even integrate via API to bring LOVO’s voices into apps and workflows. A free tier and trial options help projects start fast without setup friction.
Lovo
LOVO AI is a voiceover and video creation platform that combines an advanced text-to-speech engine with an online editor to produce natural, production-ready audio and visuals. With 500+ voices across 100+ languages, it enables rapid creation of voiceovers for marketing, e-learning, podcasts, social content, and more. Its Genny workspace adds scriptwriting, voice cloning, auto-subtitles, and AI image generation to streamline end-to-end production. Directable Pro V2 voices allow nuanced control of tone and delivery using natural language directions. Teams can collaborate in the cloud, export quickly, and even integrate via API to bring LOVO’s voices into apps and workflows. A free tier and trial options help projects start fast without setup friction.
Lovo
LOVO AI is a voiceover and video creation platform that combines an advanced text-to-speech engine with an online editor to produce natural, production-ready audio and visuals. With 500+ voices across 100+ languages, it enables rapid creation of voiceovers for marketing, e-learning, podcasts, social content, and more. Its Genny workspace adds scriptwriting, voice cloning, auto-subtitles, and AI image generation to streamline end-to-end production. Directable Pro V2 voices allow nuanced control of tone and delivery using natural language directions. Teams can collaborate in the cloud, export quickly, and even integrate via API to bring LOVO’s voices into apps and workflows. A free tier and trial options help projects start fast without setup friction.

Murf.ai
Murf.ai is an AI voice generator and text-to-speech platform that delivers ultra-realistic voiceovers for creators, teams, and developers. It offers 200+ multilingual voices, 10+ speaking styles, and fine-grained controls over pitch, speed, tone, prosody, and pronunciation. A low-latency TTS model powers conversational agents with sub-200 ms response, while APIs enable voice cloning, voice changing, streaming TTS, and translation/dubbing in 30+ languages. A studio workspace supports scripting, timing, and rapid iteration for ads, training, audiobooks, podcasts, and product audio. Pronunciation libraries, team workspaces, and tool integrations help standardize brand voice at scale without complex audio engineering.
Murf.ai
Murf.ai is an AI voice generator and text-to-speech platform that delivers ultra-realistic voiceovers for creators, teams, and developers. It offers 200+ multilingual voices, 10+ speaking styles, and fine-grained controls over pitch, speed, tone, prosody, and pronunciation. A low-latency TTS model powers conversational agents with sub-200 ms response, while APIs enable voice cloning, voice changing, streaming TTS, and translation/dubbing in 30+ languages. A studio workspace supports scripting, timing, and rapid iteration for ads, training, audiobooks, podcasts, and product audio. Pronunciation libraries, team workspaces, and tool integrations help standardize brand voice at scale without complex audio engineering.
Murf.ai
Murf.ai is an AI voice generator and text-to-speech platform that delivers ultra-realistic voiceovers for creators, teams, and developers. It offers 200+ multilingual voices, 10+ speaking styles, and fine-grained controls over pitch, speed, tone, prosody, and pronunciation. A low-latency TTS model powers conversational agents with sub-200 ms response, while APIs enable voice cloning, voice changing, streaming TTS, and translation/dubbing in 30+ languages. A studio workspace supports scripting, timing, and rapid iteration for ads, training, audiobooks, podcasts, and product audio. Pronunciation libraries, team workspaces, and tool integrations help standardize brand voice at scale without complex audio engineering.
PlayAI
Play.ht is an AI voice generator and text-to-speech platform for creating humanlike voiceovers in minutes. It offers a large, growing library of natural voices across 30+ languages and accents, with controls for pitch, pace, emphasis, pauses, and SSML. Dialog-enabled generation supports multi-speaker, multi-turn conversations in a single file, ideal for podcasts and character-driven audio. Teams can define and reuse pronunciations for brand terms, preview segments, and fine-tune emotion and speaking styles. Voice cloning and custom voice creation enable consistent brand sound, while ultra-low-latency streaming suits live apps. Use cases span videos, audiobooks, training, assistants, games, IVR, and localization.
PlayAI
Play.ht is an AI voice generator and text-to-speech platform for creating humanlike voiceovers in minutes. It offers a large, growing library of natural voices across 30+ languages and accents, with controls for pitch, pace, emphasis, pauses, and SSML. Dialog-enabled generation supports multi-speaker, multi-turn conversations in a single file, ideal for podcasts and character-driven audio. Teams can define and reuse pronunciations for brand terms, preview segments, and fine-tune emotion and speaking styles. Voice cloning and custom voice creation enable consistent brand sound, while ultra-low-latency streaming suits live apps. Use cases span videos, audiobooks, training, assistants, games, IVR, and localization.
PlayAI
Play.ht is an AI voice generator and text-to-speech platform for creating humanlike voiceovers in minutes. It offers a large, growing library of natural voices across 30+ languages and accents, with controls for pitch, pace, emphasis, pauses, and SSML. Dialog-enabled generation supports multi-speaker, multi-turn conversations in a single file, ideal for podcasts and character-driven audio. Teams can define and reuse pronunciations for brand terms, preview segments, and fine-tune emotion and speaking styles. Voice cloning and custom voice creation enable consistent brand sound, while ultra-low-latency streaming suits live apps. Use cases span videos, audiobooks, training, assistants, games, IVR, and localization.
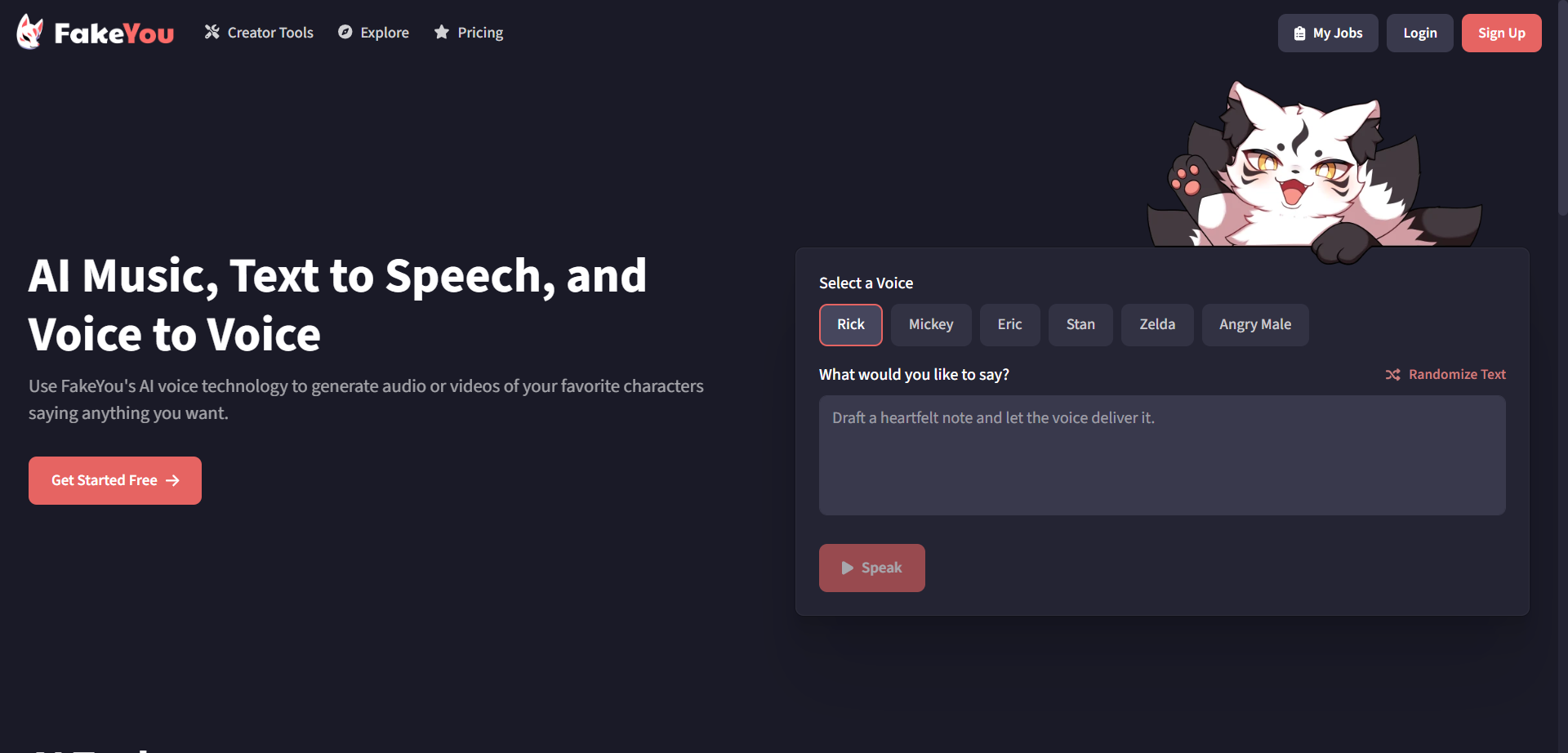
FakeYou
FakeYou is a community-driven AI voice platform that converts text into speech using a large catalog of celebrity, character, and creator-trained voices. It emphasizes ease of use for quick meme audio, voiceovers, and creative projects, while also supporting longer scripts with stable generation. Users select from many fan-made and studio-quality voice models, then fine-tune outputs with controls like pace and emphasis for better delivery. The platform focuses on fun, experimentation, and shareability, letting creators generate clips for videos, streams, and social posts. With a lively community and frequent new voices, FakeYou makes voice cloning and character TTS accessible for everyday content creation.
FakeYou
FakeYou is a community-driven AI voice platform that converts text into speech using a large catalog of celebrity, character, and creator-trained voices. It emphasizes ease of use for quick meme audio, voiceovers, and creative projects, while also supporting longer scripts with stable generation. Users select from many fan-made and studio-quality voice models, then fine-tune outputs with controls like pace and emphasis for better delivery. The platform focuses on fun, experimentation, and shareability, letting creators generate clips for videos, streams, and social posts. With a lively community and frequent new voices, FakeYou makes voice cloning and character TTS accessible for everyday content creation.
FakeYou
FakeYou is a community-driven AI voice platform that converts text into speech using a large catalog of celebrity, character, and creator-trained voices. It emphasizes ease of use for quick meme audio, voiceovers, and creative projects, while also supporting longer scripts with stable generation. Users select from many fan-made and studio-quality voice models, then fine-tune outputs with controls like pace and emphasis for better delivery. The platform focuses on fun, experimentation, and shareability, letting creators generate clips for videos, streams, and social posts. With a lively community and frequent new voices, FakeYou makes voice cloning and character TTS accessible for everyday content creation.

AI ASMR
AI ASMR is a generative AI tool that converts short text prompts into relaxing audiovisual experiences—ASMR (Autonomous Sensory Meridian Response) videos with gentle sounds, immersive visuals, and ambient scenes. Users can specify scenarios like “knife slicing pineapple with close-up camera and crisp sound effects” and the tool produces a video with macro visuals, layered audio, and a calm atmosphere. The platform is aimed at creators of relaxation, study, or sensory content—offering quick production of ASMR-style videos without needing a studio, microphone setup, or manual editing. Users select triggers (whispers, taps, nature ambience), visual style, aspect ratio, and quality mode (fast or high definition), then generate a downloadable video ready for YouTube, TikTok, or streaming.
AI ASMR
AI ASMR is a generative AI tool that converts short text prompts into relaxing audiovisual experiences—ASMR (Autonomous Sensory Meridian Response) videos with gentle sounds, immersive visuals, and ambient scenes. Users can specify scenarios like “knife slicing pineapple with close-up camera and crisp sound effects” and the tool produces a video with macro visuals, layered audio, and a calm atmosphere. The platform is aimed at creators of relaxation, study, or sensory content—offering quick production of ASMR-style videos without needing a studio, microphone setup, or manual editing. Users select triggers (whispers, taps, nature ambience), visual style, aspect ratio, and quality mode (fast or high definition), then generate a downloadable video ready for YouTube, TikTok, or streaming.
AI ASMR
AI ASMR is a generative AI tool that converts short text prompts into relaxing audiovisual experiences—ASMR (Autonomous Sensory Meridian Response) videos with gentle sounds, immersive visuals, and ambient scenes. Users can specify scenarios like “knife slicing pineapple with close-up camera and crisp sound effects” and the tool produces a video with macro visuals, layered audio, and a calm atmosphere. The platform is aimed at creators of relaxation, study, or sensory content—offering quick production of ASMR-style videos without needing a studio, microphone setup, or manual editing. Users select triggers (whispers, taps, nature ambience), visual style, aspect ratio, and quality mode (fast or high definition), then generate a downloadable video ready for YouTube, TikTok, or streaming.
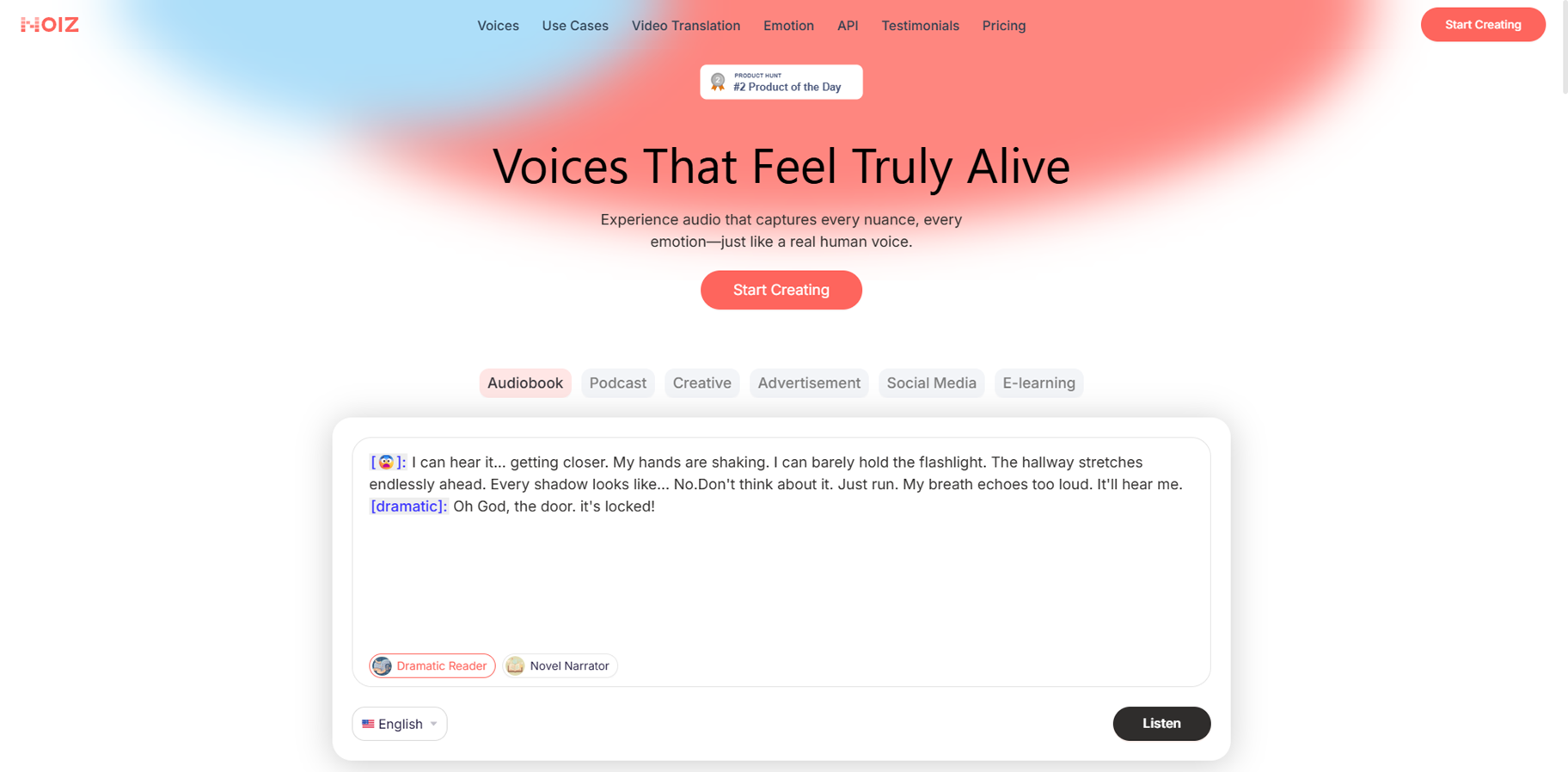

Noiz
Noiz is a leading AI platform for advanced speech synthesis and audio generation, specializing in highly expressive, lifelike voices with emotional control and customization. It offers text-to-speech , voice cloning, multilingual dubbing, AI singing voice generation, and developer APIs for seamless integration into apps. Users can create realistic vocals with nuance, vibrato, and dynamics from simple prompts, supporting video translation, audio editing, and music production. The tool excels in cost-efficiency, handling everything from podcast mastering to viral song covers, with features like noise removal, auto-leveling, and scene-based soundscapes. Ideal for creators seeking professional audio without studios.
Noiz
Noiz is a leading AI platform for advanced speech synthesis and audio generation, specializing in highly expressive, lifelike voices with emotional control and customization. It offers text-to-speech , voice cloning, multilingual dubbing, AI singing voice generation, and developer APIs for seamless integration into apps. Users can create realistic vocals with nuance, vibrato, and dynamics from simple prompts, supporting video translation, audio editing, and music production. The tool excels in cost-efficiency, handling everything from podcast mastering to viral song covers, with features like noise removal, auto-leveling, and scene-based soundscapes. Ideal for creators seeking professional audio without studios.
Noiz
Noiz is a leading AI platform for advanced speech synthesis and audio generation, specializing in highly expressive, lifelike voices with emotional control and customization. It offers text-to-speech , voice cloning, multilingual dubbing, AI singing voice generation, and developer APIs for seamless integration into apps. Users can create realistic vocals with nuance, vibrato, and dynamics from simple prompts, supporting video translation, audio editing, and music production. The tool excels in cost-efficiency, handling everything from podcast mastering to viral song covers, with features like noise removal, auto-leveling, and scene-based soundscapes. Ideal for creators seeking professional audio without studios.
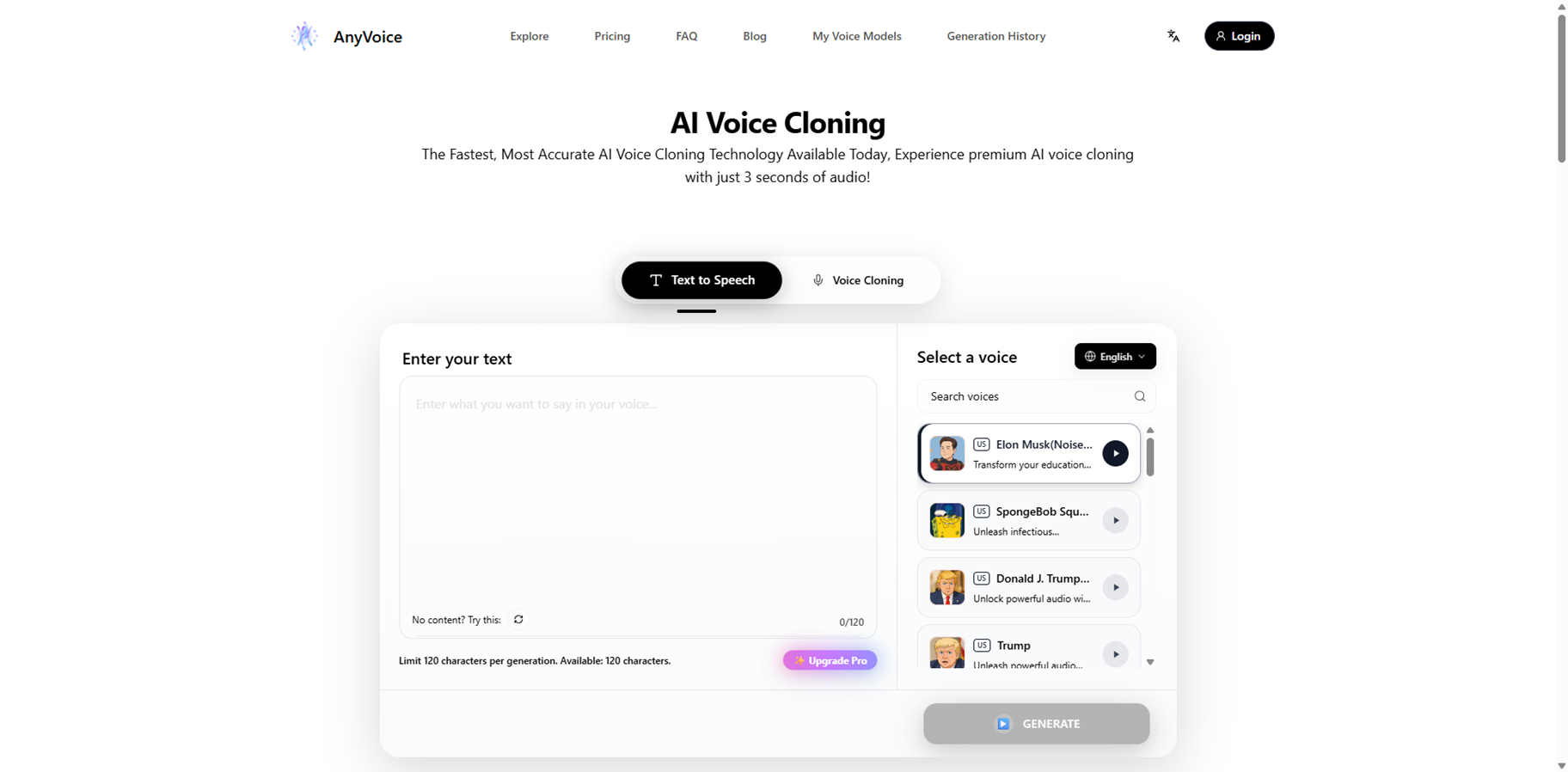

AnyVoice
AnyVoice brings the world's fastest AI voice cloning, turning just 3 seconds of audio into hyper-realistic speech that nails every nuance and emotion. Pick from English, Chinese Mandarin, Japanese, or Korean, enter your text, select the cloned voice, and get instant lifelike output—no long recordings or tech skills needed. Perfect for quick voiceovers, prototyping, or dynamic content, it delivers indistinguishable-from-human results securely with user privacy front and center. Free tier offers 900 seconds monthly and 5 clones; Pro unlocks unlimited everything and commercial rights. Streamlined interface makes pro-level cloning accessible to anyone, speeding up creation like never before.
AnyVoice
AnyVoice brings the world's fastest AI voice cloning, turning just 3 seconds of audio into hyper-realistic speech that nails every nuance and emotion. Pick from English, Chinese Mandarin, Japanese, or Korean, enter your text, select the cloned voice, and get instant lifelike output—no long recordings or tech skills needed. Perfect for quick voiceovers, prototyping, or dynamic content, it delivers indistinguishable-from-human results securely with user privacy front and center. Free tier offers 900 seconds monthly and 5 clones; Pro unlocks unlimited everything and commercial rights. Streamlined interface makes pro-level cloning accessible to anyone, speeding up creation like never before.
AnyVoice
AnyVoice brings the world's fastest AI voice cloning, turning just 3 seconds of audio into hyper-realistic speech that nails every nuance and emotion. Pick from English, Chinese Mandarin, Japanese, or Korean, enter your text, select the cloned voice, and get instant lifelike output—no long recordings or tech skills needed. Perfect for quick voiceovers, prototyping, or dynamic content, it delivers indistinguishable-from-human results securely with user privacy front and center. Free tier offers 900 seconds monthly and 5 clones; Pro unlocks unlimited everything and commercial rights. Streamlined interface makes pro-level cloning accessible to anyone, speeding up creation like never before.
Editorial Note
This page was researched and written by the ATB Editorial Team. Our team researches each AI tool by reviewing its official website, testing features, exploring real use cases, and considering user feedback. Every page is fact-checked and regularly updated to ensure the information stays accurate, neutral, and useful for our readers.
If you have any suggestions or questions, email us at hello@aitoolbook.ai