- Podcasters & Interviewers: To clean up their voice tracks, remove background noise and get clearer, more professional audio.
- Video Content Creators: Those who want dialogue to be audible over background sounds for better video clarity.
- Streamers & Live Broadcasters: To reduce mic feedback, crowd noise, or other disturbances in live feeds.
- Educators & Lecturers: To make recorded lectures more intelligible for students, especially with noisy recording environments.
- Journalists / Field Reporters: For capturing spoken word cleanly in uncontrolled environments.
- Musicians / Remixers: When they need vocal stems (isolated vocals) or want to remove interference from tracks.
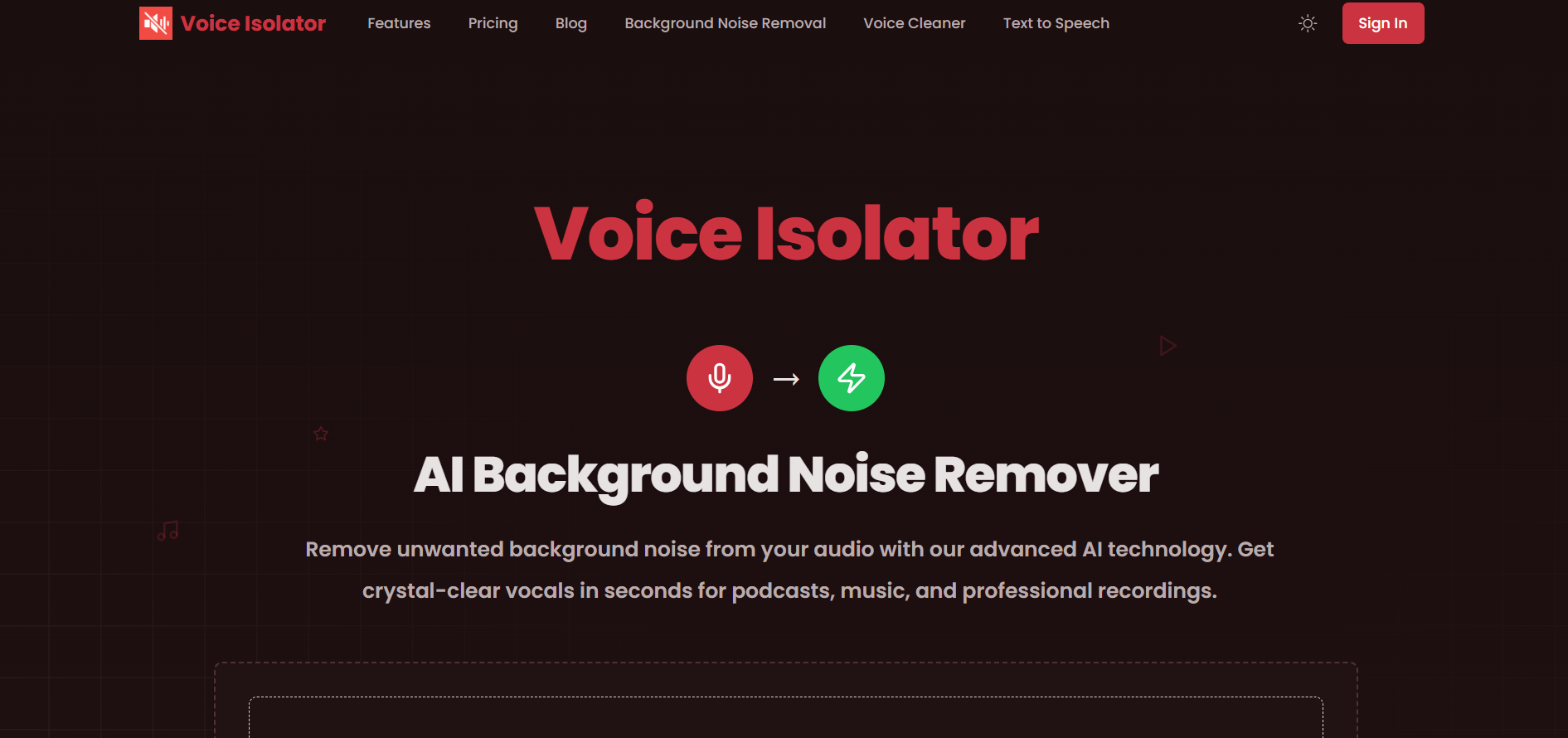
How to Use It?
- Upload or Record: Provide your audio or video file, or use browser-recording functions if available.
- Specify What To Keep / Remove: Choose whether to isolate vocals/speech or remove background noise, music, etc.
- Let AI Process: The system analyzes the file, separates components or filters noise.
- Preview & Adjust (if available): Check how clean the voice is; may allow adjustments like level of noise removal or intensity.
- Download Cleaned Audio: Once satisfied, export the processed speech or audio track.
- Real-Time / Fast Processing: You can get cleaned audio quite quickly without needing complex editing tools.
- High Quality Speech Isolation: The tool tends to preserve spoken word clarity even when background is messy.
- Minimal User Skill Required: Works with simple upload/record actions; no need for deep audio engineering knowledge.
- Versatility of Use Cases: Useful across podcasts, videos, interviews, live streaming, education, etc.
- No Software Installation Needed: Browser-based, often works directly from device with internet.
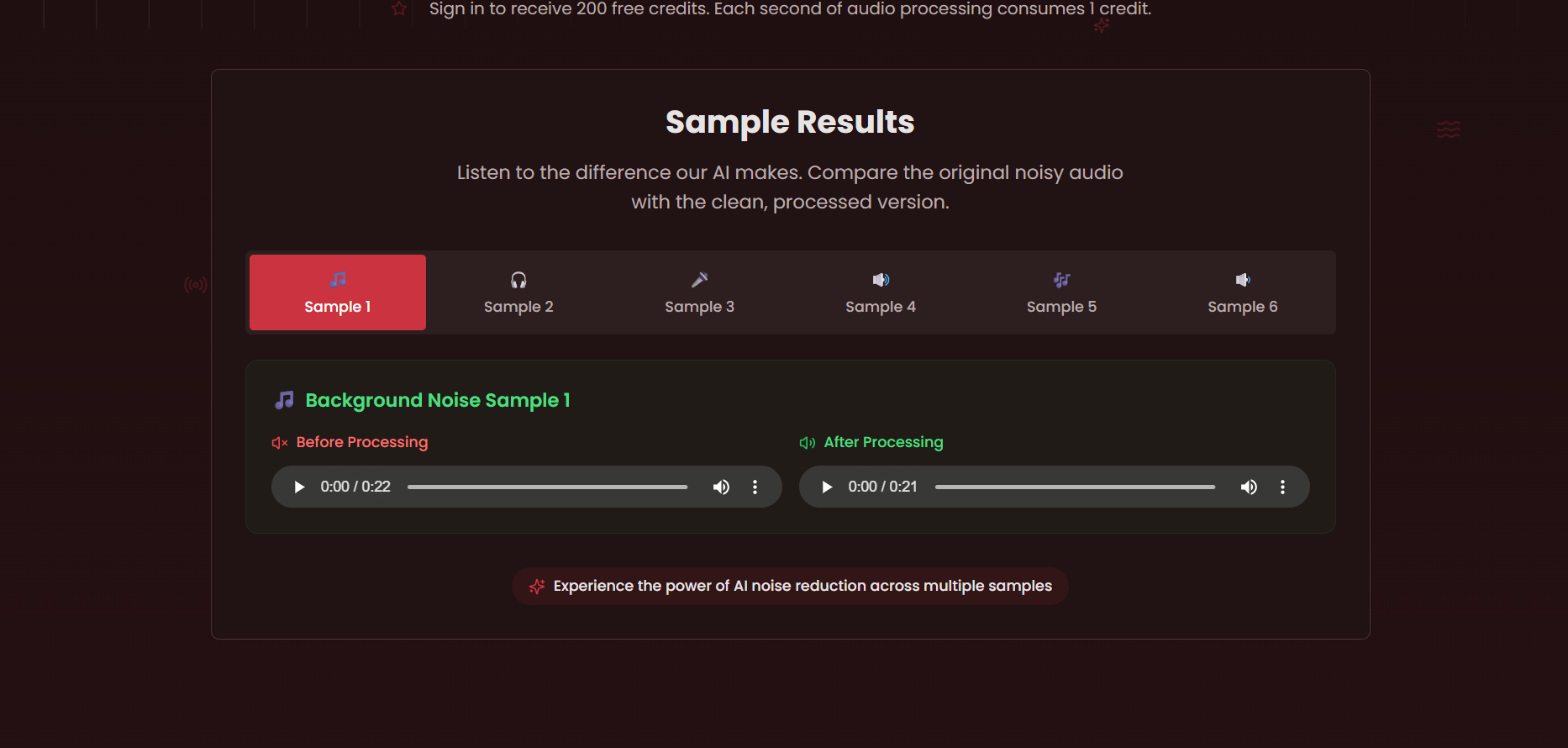
- Makes voice much clearer and more intelligible
- Removes or suppresses unwanted background noise effectively
- Easy to use for non-experts
- Saves time compared to manual cleanup in DAWs or editors
- Useful for many kinds of creators and professionals
- May not perfectly separate vocals in extremely noisy or overlapping audio
- Artifacts can remain if background and voice frequencies overlap heavily
- Quality depends on original file quality (mic, recording conditions)
- Limited control over fine-tuning if advanced features are restricted
Starter
$ 9.90
Advanced AI Voice Isolator
Priority support
Pro
$ 19.99
Advanced AI Voice Isolator
Priority support
One Time
$ 4.90
2000 credits
Valid for 1 months
Proud of the love you're getting? Show off your AI Toolbook reviews—then invite more fans to share the love and build your credibility.
Add an AI Toolbook badge to your site—an easy way to drive followers, showcase updates, and collect reviews. It's like a mini 24/7 billboard for your AI.
Reviews
Rating Distribution
Average score
Popular Mention
FAQs
Common audio/video formats such as MP3, WAV, MP4 are usually supported.
Usually yes, but you’ll need to check the licensing terms of the specific tool.
Usually just a few seconds to a minute depending on file size and background complexity.
No — this is aimed at non-technical users generally.
Not always — very loud or overlapping background noise may not be fully removed and some artifacts may persist.
Similar AI Tools
NotebookAI Podcast
AIdeaFlow Podcast is an AI-powered platform that automates the process of transforming text—like articles, PDFs, or scripts—into polished, human-like podcast audio. It leverages advanced Triton TTS models (including Gemini, WorldSpeak, and others) to produce natural-sounding voiceovers in over 31 languages using more than 120 unique voices. You can input content via text, file upload, or URL, and let the AI handle pacing, tone, and voice selection. With support for single speakers, interactive dialogues, and voice cloning, it suits a wide range of creators—from educators turning lecture notes into spoken content to marketers producing audio campaigns. AIdeaFlow features intelligent editing tools to remove errors, manage silence, and add music or effects.
NotebookAI Podcast
AIdeaFlow Podcast is an AI-powered platform that automates the process of transforming text—like articles, PDFs, or scripts—into polished, human-like podcast audio. It leverages advanced Triton TTS models (including Gemini, WorldSpeak, and others) to produce natural-sounding voiceovers in over 31 languages using more than 120 unique voices. You can input content via text, file upload, or URL, and let the AI handle pacing, tone, and voice selection. With support for single speakers, interactive dialogues, and voice cloning, it suits a wide range of creators—from educators turning lecture notes into spoken content to marketers producing audio campaigns. AIdeaFlow features intelligent editing tools to remove errors, manage silence, and add music or effects.
NotebookAI Podcast
AIdeaFlow Podcast is an AI-powered platform that automates the process of transforming text—like articles, PDFs, or scripts—into polished, human-like podcast audio. It leverages advanced Triton TTS models (including Gemini, WorldSpeak, and others) to produce natural-sounding voiceovers in over 31 languages using more than 120 unique voices. You can input content via text, file upload, or URL, and let the AI handle pacing, tone, and voice selection. With support for single speakers, interactive dialogues, and voice cloning, it suits a wide range of creators—from educators turning lecture notes into spoken content to marketers producing audio campaigns. AIdeaFlow features intelligent editing tools to remove errors, manage silence, and add music or effects.
Utell AI
Utell AI is an advanced AI-powered accent conversion platform that helps individuals and businesses improve communication by refining non-native English accents in real-time. It provides a seamless experience for enhancing clarity, preserving natural voice characteristics, and facilitating smooth interactions across meetings, calls, gaming, and online streaming.
Utell AI
Utell AI is an advanced AI-powered accent conversion platform that helps individuals and businesses improve communication by refining non-native English accents in real-time. It provides a seamless experience for enhancing clarity, preserving natural voice characteristics, and facilitating smooth interactions across meetings, calls, gaming, and online streaming.
Utell AI
Utell AI is an advanced AI-powered accent conversion platform that helps individuals and businesses improve communication by refining non-native English accents in real-time. It provides a seamless experience for enhancing clarity, preserving natural voice characteristics, and facilitating smooth interactions across meetings, calls, gaming, and online streaming.
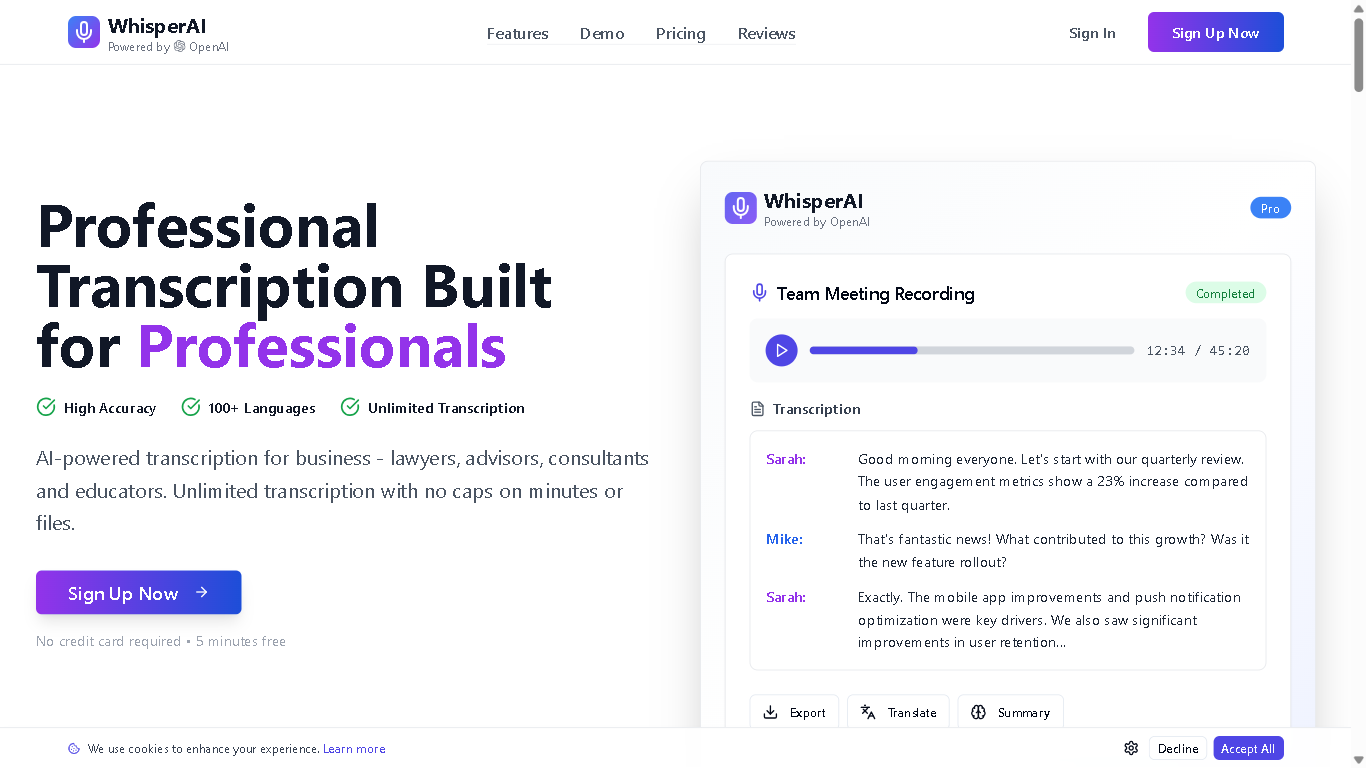
Whisprai.ai is an AI-powered transcription and summarization tool designed to help businesses and individuals quickly and accurately transcribe audio and video files, and generate concise summaries of their content. It offers features for improving workflow efficiency and enhancing productivity through AI-driven automation.
Whisprai.ai is an AI-powered transcription and summarization tool designed to help businesses and individuals quickly and accurately transcribe audio and video files, and generate concise summaries of their content. It offers features for improving workflow efficiency and enhancing productivity through AI-driven automation.
Whisprai.ai is an AI-powered transcription and summarization tool designed to help businesses and individuals quickly and accurately transcribe audio and video files, and generate concise summaries of their content. It offers features for improving workflow efficiency and enhancing productivity through AI-driven automation.
PERSO.ai
Perso.ai is an AI-powered video localization platform that enables creators, educators, and businesses to produce high-quality, multilingual videos effortlessly. It offers features like voice cloning, lip-sync dubbing, and real-time script editing, making global content creation accessible to everyone.
PERSO.ai
Perso.ai is an AI-powered video localization platform that enables creators, educators, and businesses to produce high-quality, multilingual videos effortlessly. It offers features like voice cloning, lip-sync dubbing, and real-time script editing, making global content creation accessible to everyone.
PERSO.ai
Perso.ai is an AI-powered video localization platform that enables creators, educators, and businesses to produce high-quality, multilingual videos effortlessly. It offers features like voice cloning, lip-sync dubbing, and real-time script editing, making global content creation accessible to everyone.
Voiceslab
Voiceslab is an AI voice cloning and synthesis platform that enables users to create digital replicas of their voice from a short audio sample. By uploading or recording about 10–60 seconds of speech, the system analyzes tone, speech patterns, and style to generate a custom voice model. After that, users can input text to produce natural-sounding speech in their cloned voice across multiple languages. The tool is suited for content creators, marketers, podcasters, and businesses wanting to scale voice content without repeated recording.
Voiceslab
Voiceslab is an AI voice cloning and synthesis platform that enables users to create digital replicas of their voice from a short audio sample. By uploading or recording about 10–60 seconds of speech, the system analyzes tone, speech patterns, and style to generate a custom voice model. After that, users can input text to produce natural-sounding speech in their cloned voice across multiple languages. The tool is suited for content creators, marketers, podcasters, and businesses wanting to scale voice content without repeated recording.
Voiceslab
Voiceslab is an AI voice cloning and synthesis platform that enables users to create digital replicas of their voice from a short audio sample. By uploading or recording about 10–60 seconds of speech, the system analyzes tone, speech patterns, and style to generate a custom voice model. After that, users can input text to produce natural-sounding speech in their cloned voice across multiple languages. The tool is suited for content creators, marketers, podcasters, and businesses wanting to scale voice content without repeated recording.
Lovo
LOVO AI is a voiceover and video creation platform that combines an advanced text-to-speech engine with an online editor to produce natural, production-ready audio and visuals. With 500+ voices across 100+ languages, it enables rapid creation of voiceovers for marketing, e-learning, podcasts, social content, and more. Its Genny workspace adds scriptwriting, voice cloning, auto-subtitles, and AI image generation to streamline end-to-end production. Directable Pro V2 voices allow nuanced control of tone and delivery using natural language directions. Teams can collaborate in the cloud, export quickly, and even integrate via API to bring LOVO’s voices into apps and workflows. A free tier and trial options help projects start fast without setup friction.
Lovo
LOVO AI is a voiceover and video creation platform that combines an advanced text-to-speech engine with an online editor to produce natural, production-ready audio and visuals. With 500+ voices across 100+ languages, it enables rapid creation of voiceovers for marketing, e-learning, podcasts, social content, and more. Its Genny workspace adds scriptwriting, voice cloning, auto-subtitles, and AI image generation to streamline end-to-end production. Directable Pro V2 voices allow nuanced control of tone and delivery using natural language directions. Teams can collaborate in the cloud, export quickly, and even integrate via API to bring LOVO’s voices into apps and workflows. A free tier and trial options help projects start fast without setup friction.
Lovo
LOVO AI is a voiceover and video creation platform that combines an advanced text-to-speech engine with an online editor to produce natural, production-ready audio and visuals. With 500+ voices across 100+ languages, it enables rapid creation of voiceovers for marketing, e-learning, podcasts, social content, and more. Its Genny workspace adds scriptwriting, voice cloning, auto-subtitles, and AI image generation to streamline end-to-end production. Directable Pro V2 voices allow nuanced control of tone and delivery using natural language directions. Teams can collaborate in the cloud, export quickly, and even integrate via API to bring LOVO’s voices into apps and workflows. A free tier and trial options help projects start fast without setup friction.


Adobe Podcast
Adobe Podcast is an online audio creation platform that streamlines recording, editing, and publishing for podcasts and voice content. It offers browser-based recording with remote guest capture, AI-powered enhancement to clean noisy audio, and transcript-level editing that lets users edit by text instead of waveforms. Features like automatic leveling, noise reduction, and echo removal produce broadcast-ready sound with minimal effort. Built-in collaboration helps teams review, comment, and finalize episodes quickly. Publishing workflows are simplified with exports tailored for major platforms. The result is a faster path from raw conversation to polished, professional audio without complex setup.
Adobe Podcast
Adobe Podcast is an online audio creation platform that streamlines recording, editing, and publishing for podcasts and voice content. It offers browser-based recording with remote guest capture, AI-powered enhancement to clean noisy audio, and transcript-level editing that lets users edit by text instead of waveforms. Features like automatic leveling, noise reduction, and echo removal produce broadcast-ready sound with minimal effort. Built-in collaboration helps teams review, comment, and finalize episodes quickly. Publishing workflows are simplified with exports tailored for major platforms. The result is a faster path from raw conversation to polished, professional audio without complex setup.
Adobe Podcast
Adobe Podcast is an online audio creation platform that streamlines recording, editing, and publishing for podcasts and voice content. It offers browser-based recording with remote guest capture, AI-powered enhancement to clean noisy audio, and transcript-level editing that lets users edit by text instead of waveforms. Features like automatic leveling, noise reduction, and echo removal produce broadcast-ready sound with minimal effort. Built-in collaboration helps teams review, comment, and finalize episodes quickly. Publishing workflows are simplified with exports tailored for major platforms. The result is a faster path from raw conversation to polished, professional audio without complex setup.

Murf.ai
Murf.ai is an AI voice generator and text-to-speech platform that delivers ultra-realistic voiceovers for creators, teams, and developers. It offers 200+ multilingual voices, 10+ speaking styles, and fine-grained controls over pitch, speed, tone, prosody, and pronunciation. A low-latency TTS model powers conversational agents with sub-200 ms response, while APIs enable voice cloning, voice changing, streaming TTS, and translation/dubbing in 30+ languages. A studio workspace supports scripting, timing, and rapid iteration for ads, training, audiobooks, podcasts, and product audio. Pronunciation libraries, team workspaces, and tool integrations help standardize brand voice at scale without complex audio engineering.
Murf.ai
Murf.ai is an AI voice generator and text-to-speech platform that delivers ultra-realistic voiceovers for creators, teams, and developers. It offers 200+ multilingual voices, 10+ speaking styles, and fine-grained controls over pitch, speed, tone, prosody, and pronunciation. A low-latency TTS model powers conversational agents with sub-200 ms response, while APIs enable voice cloning, voice changing, streaming TTS, and translation/dubbing in 30+ languages. A studio workspace supports scripting, timing, and rapid iteration for ads, training, audiobooks, podcasts, and product audio. Pronunciation libraries, team workspaces, and tool integrations help standardize brand voice at scale without complex audio engineering.
Murf.ai
Murf.ai is an AI voice generator and text-to-speech platform that delivers ultra-realistic voiceovers for creators, teams, and developers. It offers 200+ multilingual voices, 10+ speaking styles, and fine-grained controls over pitch, speed, tone, prosody, and pronunciation. A low-latency TTS model powers conversational agents with sub-200 ms response, while APIs enable voice cloning, voice changing, streaming TTS, and translation/dubbing in 30+ languages. A studio workspace supports scripting, timing, and rapid iteration for ads, training, audiobooks, podcasts, and product audio. Pronunciation libraries, team workspaces, and tool integrations help standardize brand voice at scale without complex audio engineering.
PlayAI
Play.ht is an AI voice generator and text-to-speech platform for creating humanlike voiceovers in minutes. It offers a large, growing library of natural voices across 30+ languages and accents, with controls for pitch, pace, emphasis, pauses, and SSML. Dialog-enabled generation supports multi-speaker, multi-turn conversations in a single file, ideal for podcasts and character-driven audio. Teams can define and reuse pronunciations for brand terms, preview segments, and fine-tune emotion and speaking styles. Voice cloning and custom voice creation enable consistent brand sound, while ultra-low-latency streaming suits live apps. Use cases span videos, audiobooks, training, assistants, games, IVR, and localization.
PlayAI
Play.ht is an AI voice generator and text-to-speech platform for creating humanlike voiceovers in minutes. It offers a large, growing library of natural voices across 30+ languages and accents, with controls for pitch, pace, emphasis, pauses, and SSML. Dialog-enabled generation supports multi-speaker, multi-turn conversations in a single file, ideal for podcasts and character-driven audio. Teams can define and reuse pronunciations for brand terms, preview segments, and fine-tune emotion and speaking styles. Voice cloning and custom voice creation enable consistent brand sound, while ultra-low-latency streaming suits live apps. Use cases span videos, audiobooks, training, assistants, games, IVR, and localization.
PlayAI
Play.ht is an AI voice generator and text-to-speech platform for creating humanlike voiceovers in minutes. It offers a large, growing library of natural voices across 30+ languages and accents, with controls for pitch, pace, emphasis, pauses, and SSML. Dialog-enabled generation supports multi-speaker, multi-turn conversations in a single file, ideal for podcasts and character-driven audio. Teams can define and reuse pronunciations for brand terms, preview segments, and fine-tune emotion and speaking styles. Voice cloning and custom voice creation enable consistent brand sound, while ultra-low-latency streaming suits live apps. Use cases span videos, audiobooks, training, assistants, games, IVR, and localization.
FakeYou
FakeYou is a community-driven AI voice platform that converts text into speech using a large catalog of celebrity, character, and creator-trained voices. It emphasizes ease of use for quick meme audio, voiceovers, and creative projects, while also supporting longer scripts with stable generation. Users select from many fan-made and studio-quality voice models, then fine-tune outputs with controls like pace and emphasis for better delivery. The platform focuses on fun, experimentation, and shareability, letting creators generate clips for videos, streams, and social posts. With a lively community and frequent new voices, FakeYou makes voice cloning and character TTS accessible for everyday content creation.
FakeYou
FakeYou is a community-driven AI voice platform that converts text into speech using a large catalog of celebrity, character, and creator-trained voices. It emphasizes ease of use for quick meme audio, voiceovers, and creative projects, while also supporting longer scripts with stable generation. Users select from many fan-made and studio-quality voice models, then fine-tune outputs with controls like pace and emphasis for better delivery. The platform focuses on fun, experimentation, and shareability, letting creators generate clips for videos, streams, and social posts. With a lively community and frequent new voices, FakeYou makes voice cloning and character TTS accessible for everyday content creation.
FakeYou
FakeYou is a community-driven AI voice platform that converts text into speech using a large catalog of celebrity, character, and creator-trained voices. It emphasizes ease of use for quick meme audio, voiceovers, and creative projects, while also supporting longer scripts with stable generation. Users select from many fan-made and studio-quality voice models, then fine-tune outputs with controls like pace and emphasis for better delivery. The platform focuses on fun, experimentation, and shareability, letting creators generate clips for videos, streams, and social posts. With a lively community and frequent new voices, FakeYou makes voice cloning and character TTS accessible for everyday content creation.
Infinite Talk AI
InfiniteTalkAI is an AI-driven voice interaction and conversational media platform designed to generate natural‑sounding dialogues, voiceovers, character interactions, and scripted conversational content from simple text prompts. Built for creators, educators, marketers, and developers, it enables users to produce fully voiced conversations between multiple AI characters, complete with tone control, personality variation, pacing adjustments, and emotional expression. InfiniteTalkAI focuses on realism and fluidity, offering high-quality speech synthesis that maintains clarity and context across long exchanges. Its engine supports storytelling, podcasting, training simulations, customer experience prototyping, and creative content workflows, reducing the need for manual recording or voice talent. The platform operates as a flexible multi-speaker system, allowing users to assign voices to characters, craft dialogue scenes, and generate continuous conversational flows.
Infinite Talk AI
InfiniteTalkAI is an AI-driven voice interaction and conversational media platform designed to generate natural‑sounding dialogues, voiceovers, character interactions, and scripted conversational content from simple text prompts. Built for creators, educators, marketers, and developers, it enables users to produce fully voiced conversations between multiple AI characters, complete with tone control, personality variation, pacing adjustments, and emotional expression. InfiniteTalkAI focuses on realism and fluidity, offering high-quality speech synthesis that maintains clarity and context across long exchanges. Its engine supports storytelling, podcasting, training simulations, customer experience prototyping, and creative content workflows, reducing the need for manual recording or voice talent. The platform operates as a flexible multi-speaker system, allowing users to assign voices to characters, craft dialogue scenes, and generate continuous conversational flows.
Infinite Talk AI
InfiniteTalkAI is an AI-driven voice interaction and conversational media platform designed to generate natural‑sounding dialogues, voiceovers, character interactions, and scripted conversational content from simple text prompts. Built for creators, educators, marketers, and developers, it enables users to produce fully voiced conversations between multiple AI characters, complete with tone control, personality variation, pacing adjustments, and emotional expression. InfiniteTalkAI focuses on realism and fluidity, offering high-quality speech synthesis that maintains clarity and context across long exchanges. Its engine supports storytelling, podcasting, training simulations, customer experience prototyping, and creative content workflows, reducing the need for manual recording or voice talent. The platform operates as a flexible multi-speaker system, allowing users to assign voices to characters, craft dialogue scenes, and generate continuous conversational flows.

DeVoice
Devoice is an AI-powered audio tool that lets users convert audio and video files into accurate, editable text transcripts instantly using advanced speech recognition technology. It also includes useful audio enhancement features like background noise removal and AI-generated voice tools to help creators and professionals work with sound more efficiently.
DeVoice
Devoice is an AI-powered audio tool that lets users convert audio and video files into accurate, editable text transcripts instantly using advanced speech recognition technology. It also includes useful audio enhancement features like background noise removal and AI-generated voice tools to help creators and professionals work with sound more efficiently.
DeVoice
Devoice is an AI-powered audio tool that lets users convert audio and video files into accurate, editable text transcripts instantly using advanced speech recognition technology. It also includes useful audio enhancement features like background noise removal and AI-generated voice tools to help creators and professionals work with sound more efficiently.
Editorial Note
This page was researched and written by the ATB Editorial Team. Our team researches each AI tool by reviewing its official website, testing features, exploring real use cases, and considering user feedback. Every page is fact-checked and regularly updated to ensure the information stays accurate, neutral, and useful for our readers.
If you have any suggestions or questions, email us at hello@aitoolbook.ai