- Developers: Those looking to integrate LLM APIs into their applications securely and efficiently.
- Startups: Companies aiming to leverage AI capabilities without the overhead of managing a backend.
- Enterprises: Businesses needing secure and controlled access to LLM APIs for their applications.
- AI Enthusiasts: Individuals interested in experimenting with LLM APIs in their projects.
- App Owners: Those who want to enhance their mobile or web applications with AI functionalities.
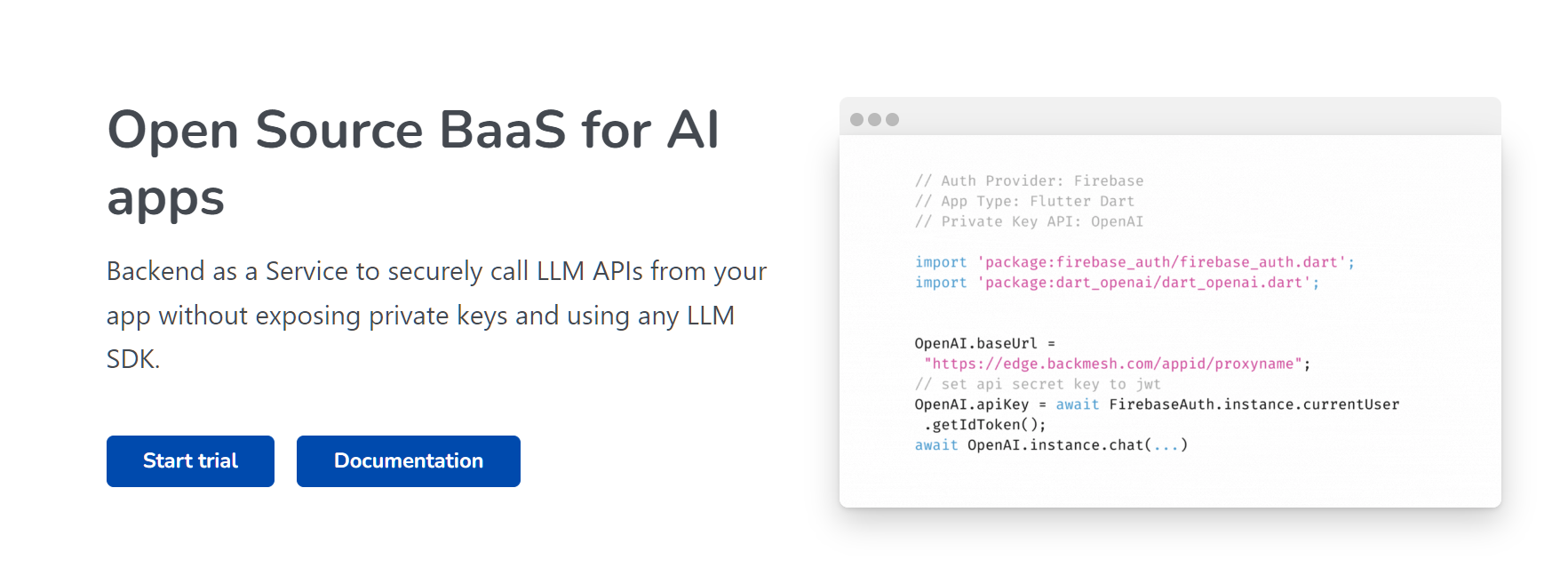
- Secure Access: Uses authenticated proxies to ensure only authorized users can access LLM APIs.
- Rate Limiting: Configurable per-user rate limits to prevent abuse and manage API usage efficiently.
- Detailed Analytics: Provides insights into usage patterns to help reduce costs and improve user satisfaction.
- No Backend Needed: Simplifies integration by eliminating the need for a backend to manage API calls.
- Security: Ensures secure access to LLM APIs with authenticated proxies.
- Efficiency: Simplifies integration by removing the need for a backend.
- Analytics: Provides valuable insights into API usage patterns.
- Rate Limiting: Helps manage and control API usage to prevent abuse.
- Dependency on Proxy: The effectiveness relies heavily on the proxy's performance and reliability.
- Limited Customization: May lack advanced customization options for specific user needs.
- Potential Latency: Adding a proxy layer could introduce latency in API responses.
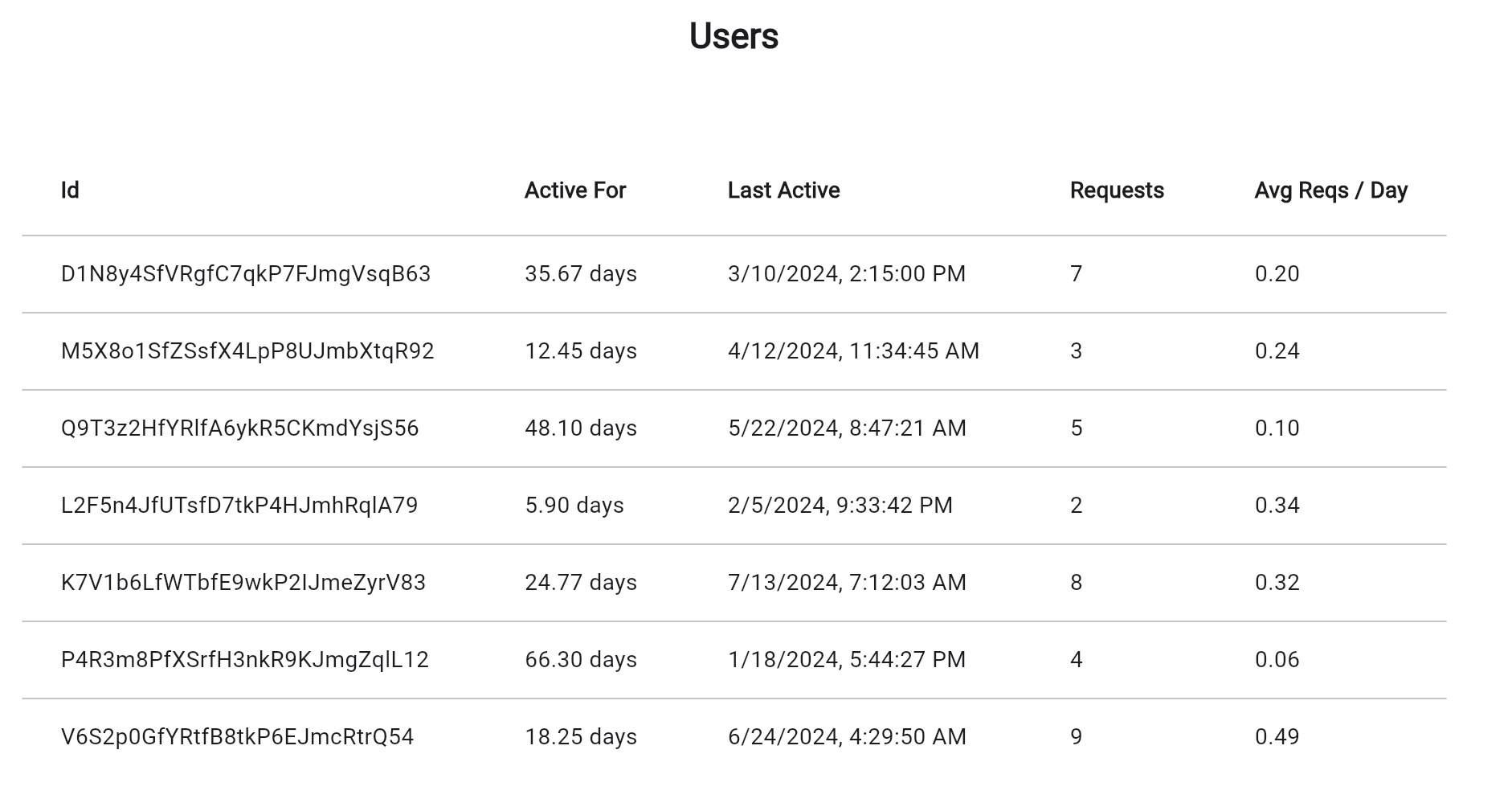
Starter
$ 10.00
Dedicated Discord channel
Configurable rate limits per user
Resource access control
Request Limits 500k included
Total Users Unlimited
MAUs 50k included
Pro
Custom
Dedicated Discord channel
Configurable rate limits per user
Request Limits 2M included, then $1 per 1M
Total Users Unlimited
MAUs 100k included, then $0.003
Enterprise
Cusotm
Dedicated Discord channel
Configurable rate limits per user
Resource access control
Request Limits Unlimited
Total Users Unlimited
MAUs Unlimited
Proud of the love you're getting? Show off your AI Toolbook reviews—then invite more fans to share the love and build your credibility.
Add an AI Toolbook badge to your site—an easy way to drive followers, showcase updates, and collect reviews. It's like a mini 24/7 billboard for your AI.
Reviews
Rating Distribution
Average score
Popular Mention
FAQs
Similar AI Tools

allganize
Allganize is a leading enterprise AI platform specializing in Large Language Model (LLM) solutions to enhance business efficiency and growth. It offers a comprehensive suite of AI-powered tools, including an LLM App Builder, Cognitive Search, and AI Answer Bot, designed to automate processes, improve data handling, and optimize customer support.
allganize
Allganize is a leading enterprise AI platform specializing in Large Language Model (LLM) solutions to enhance business efficiency and growth. It offers a comprehensive suite of AI-powered tools, including an LLM App Builder, Cognitive Search, and AI Answer Bot, designed to automate processes, improve data handling, and optimize customer support.
allganize
Allganize is a leading enterprise AI platform specializing in Large Language Model (LLM) solutions to enhance business efficiency and growth. It offers a comprehensive suite of AI-powered tools, including an LLM App Builder, Cognitive Search, and AI Answer Bot, designed to automate processes, improve data handling, and optimize customer support.

Meta Llama 3
Meta Llama 3 is Meta’s third-generation open-weight large language model family, released in April 2024 and enhanced in July 2024 with the 3.1 update. It spans three sizes—8B, 70B, and 405B parameters—each offering a 128K‑token context window. Llama 3 excels at reasoning, code generation, multilingual text, and instruction-following, and introduces multimodal vision (image understanding) capabilities in its 3.2 series. Robust safety mechanisms like Llama Guard 3, Code Shield, and CyberSec Eval 2 ensure responsible output.
Meta Llama 3
Meta Llama 3 is Meta’s third-generation open-weight large language model family, released in April 2024 and enhanced in July 2024 with the 3.1 update. It spans three sizes—8B, 70B, and 405B parameters—each offering a 128K‑token context window. Llama 3 excels at reasoning, code generation, multilingual text, and instruction-following, and introduces multimodal vision (image understanding) capabilities in its 3.2 series. Robust safety mechanisms like Llama Guard 3, Code Shield, and CyberSec Eval 2 ensure responsible output.
Meta Llama 3
Meta Llama 3 is Meta’s third-generation open-weight large language model family, released in April 2024 and enhanced in July 2024 with the 3.1 update. It spans three sizes—8B, 70B, and 405B parameters—each offering a 128K‑token context window. Llama 3 excels at reasoning, code generation, multilingual text, and instruction-following, and introduces multimodal vision (image understanding) capabilities in its 3.2 series. Robust safety mechanisms like Llama Guard 3, Code Shield, and CyberSec Eval 2 ensure responsible output.
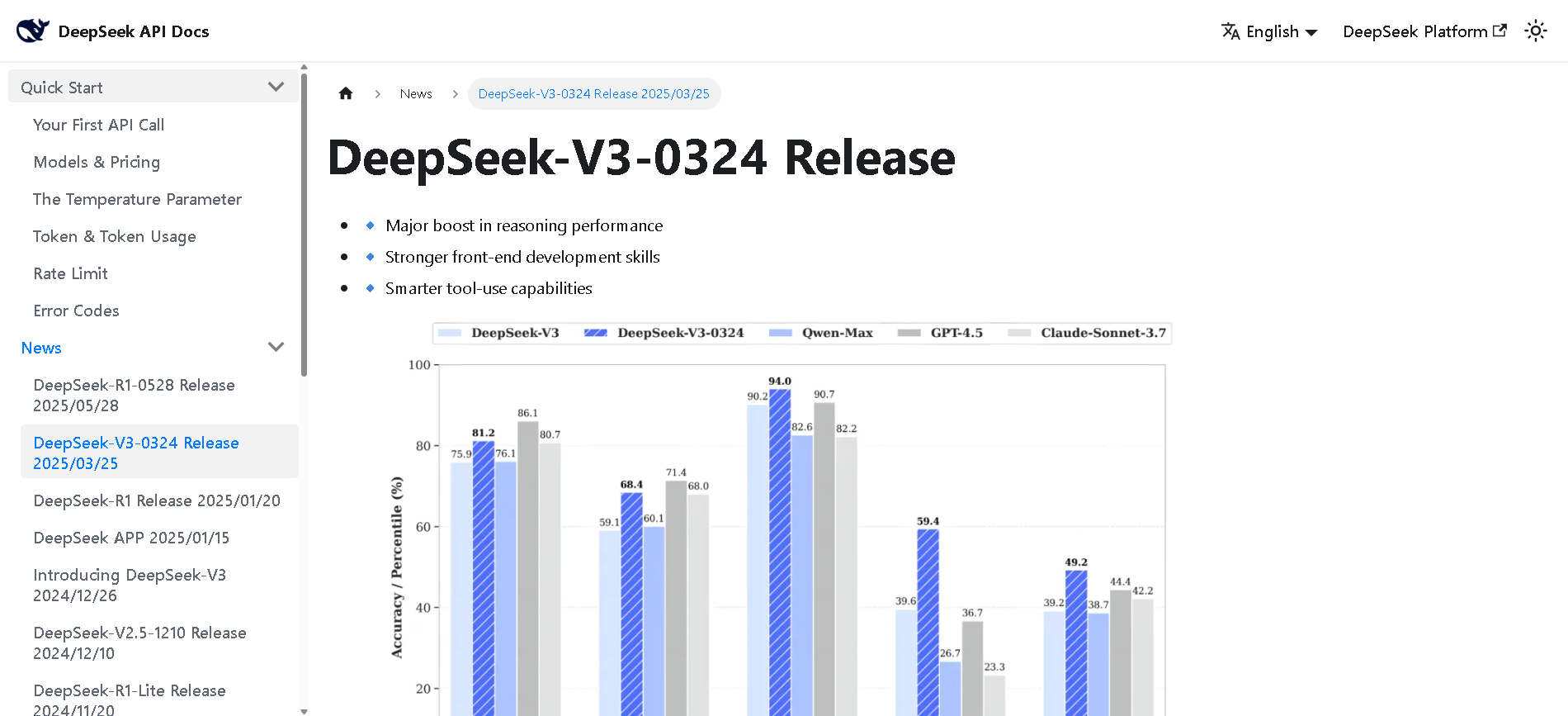
DeepSeek-V3-0324
DeepSeek V3 (0324) is the latest open-source Mixture-of-Experts (MoE) language model from DeepSeek, featuring 671B parameters (37B active per token). Released in March 2025 under the MIT license, it builds on DeepSeek V3 with major enhancements in reasoning, coding, front-end generation, and Chinese proficiency. It maintains cost-efficiency and function-calling support.
DeepSeek-V3-0324
DeepSeek V3 (0324) is the latest open-source Mixture-of-Experts (MoE) language model from DeepSeek, featuring 671B parameters (37B active per token). Released in March 2025 under the MIT license, it builds on DeepSeek V3 with major enhancements in reasoning, coding, front-end generation, and Chinese proficiency. It maintains cost-efficiency and function-calling support.
DeepSeek-V3-0324
DeepSeek V3 (0324) is the latest open-source Mixture-of-Experts (MoE) language model from DeepSeek, featuring 671B parameters (37B active per token). Released in March 2025 under the MIT license, it builds on DeepSeek V3 with major enhancements in reasoning, coding, front-end generation, and Chinese proficiency. It maintains cost-efficiency and function-calling support.
Codestral 25.01 is Mistral AI’s upgraded code-generation model, released January 13, 2025. Featuring a more efficient architecture and improved tokenizer, it delivers code completion and intelligence about 2× faster than its predecessor, with support for fill-in-the-middle (FIM), code correction, test generation, and proficiency in over 80 programming languages, all within a 256K-token context window.
Codestral 25.01 is Mistral AI’s upgraded code-generation model, released January 13, 2025. Featuring a more efficient architecture and improved tokenizer, it delivers code completion and intelligence about 2× faster than its predecessor, with support for fill-in-the-middle (FIM), code correction, test generation, and proficiency in over 80 programming languages, all within a 256K-token context window.
Codestral 25.01 is Mistral AI’s upgraded code-generation model, released January 13, 2025. Featuring a more efficient architecture and improved tokenizer, it delivers code completion and intelligence about 2× faster than its predecessor, with support for fill-in-the-middle (FIM), code correction, test generation, and proficiency in over 80 programming languages, all within a 256K-token context window.
UsageGuard
UsageGuard is an AI infrastructure platform designed to help businesses build, deploy, and monitor AI applications with confidence. It acts as a proxy service for Large Language Model (LLM) API calls, providing a unified endpoint that offers a suite of enterprise-grade features. Its core mission is to empower developers and enterprises with robust solutions for AI security, cost control, usage tracking, and comprehensive observability.
UsageGuard
UsageGuard is an AI infrastructure platform designed to help businesses build, deploy, and monitor AI applications with confidence. It acts as a proxy service for Large Language Model (LLM) API calls, providing a unified endpoint that offers a suite of enterprise-grade features. Its core mission is to empower developers and enterprises with robust solutions for AI security, cost control, usage tracking, and comprehensive observability.
UsageGuard
UsageGuard is an AI infrastructure platform designed to help businesses build, deploy, and monitor AI applications with confidence. It acts as a proxy service for Large Language Model (LLM) API calls, providing a unified endpoint that offers a suite of enterprise-grade features. Its core mission is to empower developers and enterprises with robust solutions for AI security, cost control, usage tracking, and comprehensive observability.
LLM Gateway
LLM Gateway is a unified API gateway designed to simplify working with large language models (LLMs) from multiple providers by offering a single, OpenAI-compatible endpoint. Whether using OpenAI, Anthropic, Google Vertex AI, or others, developers can route, monitor, and manage requests—all without altering existing code. Available as an open-source self-hosted option (MIT-licensed) or hosted service, it combines powerful features for analytics, cost optimization, and performance management—all under one roof.
LLM Gateway
LLM Gateway is a unified API gateway designed to simplify working with large language models (LLMs) from multiple providers by offering a single, OpenAI-compatible endpoint. Whether using OpenAI, Anthropic, Google Vertex AI, or others, developers can route, monitor, and manage requests—all without altering existing code. Available as an open-source self-hosted option (MIT-licensed) or hosted service, it combines powerful features for analytics, cost optimization, and performance management—all under one roof.
LLM Gateway
LLM Gateway is a unified API gateway designed to simplify working with large language models (LLMs) from multiple providers by offering a single, OpenAI-compatible endpoint. Whether using OpenAI, Anthropic, Google Vertex AI, or others, developers can route, monitor, and manage requests—all without altering existing code. Available as an open-source self-hosted option (MIT-licensed) or hosted service, it combines powerful features for analytics, cost optimization, and performance management—all under one roof.
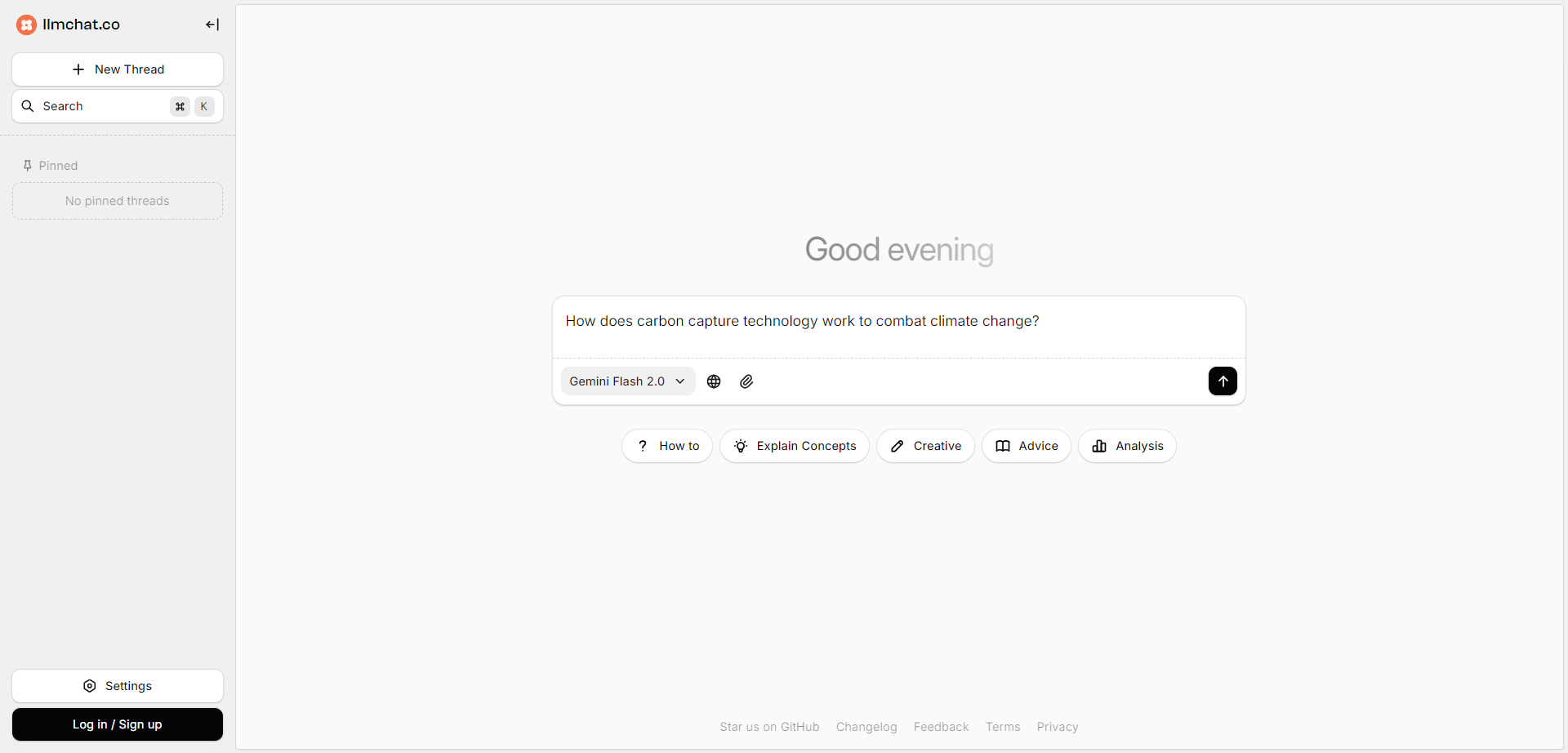

LLM Chat
LLMChat is a privacy-focused, open-source AI chatbot platform designed for advanced research, agentic workflows, and seamless interaction with multiple large language models (LLMs). It offers users a minimalistic and intuitive interface enabling deep exploration of complex topics with modes like Deep Research and Pro Search, which incorporates real-time web integration for current data. The platform emphasizes user privacy by storing all chat history locally in the browser, ensuring conversations never leave the device. LLMChat supports many popular LLM providers such as OpenAI, Anthropic, Google, and more, allowing users to customize AI assistants with personalized instructions and knowledge bases for a wide variety of applications ranging from research to content generation and coding assistance.
LLM Chat
LLMChat is a privacy-focused, open-source AI chatbot platform designed for advanced research, agentic workflows, and seamless interaction with multiple large language models (LLMs). It offers users a minimalistic and intuitive interface enabling deep exploration of complex topics with modes like Deep Research and Pro Search, which incorporates real-time web integration for current data. The platform emphasizes user privacy by storing all chat history locally in the browser, ensuring conversations never leave the device. LLMChat supports many popular LLM providers such as OpenAI, Anthropic, Google, and more, allowing users to customize AI assistants with personalized instructions and knowledge bases for a wide variety of applications ranging from research to content generation and coding assistance.
LLM Chat
LLMChat is a privacy-focused, open-source AI chatbot platform designed for advanced research, agentic workflows, and seamless interaction with multiple large language models (LLMs). It offers users a minimalistic and intuitive interface enabling deep exploration of complex topics with modes like Deep Research and Pro Search, which incorporates real-time web integration for current data. The platform emphasizes user privacy by storing all chat history locally in the browser, ensuring conversations never leave the device. LLMChat supports many popular LLM providers such as OpenAI, Anthropic, Google, and more, allowing users to customize AI assistants with personalized instructions and knowledge bases for a wide variety of applications ranging from research to content generation and coding assistance.
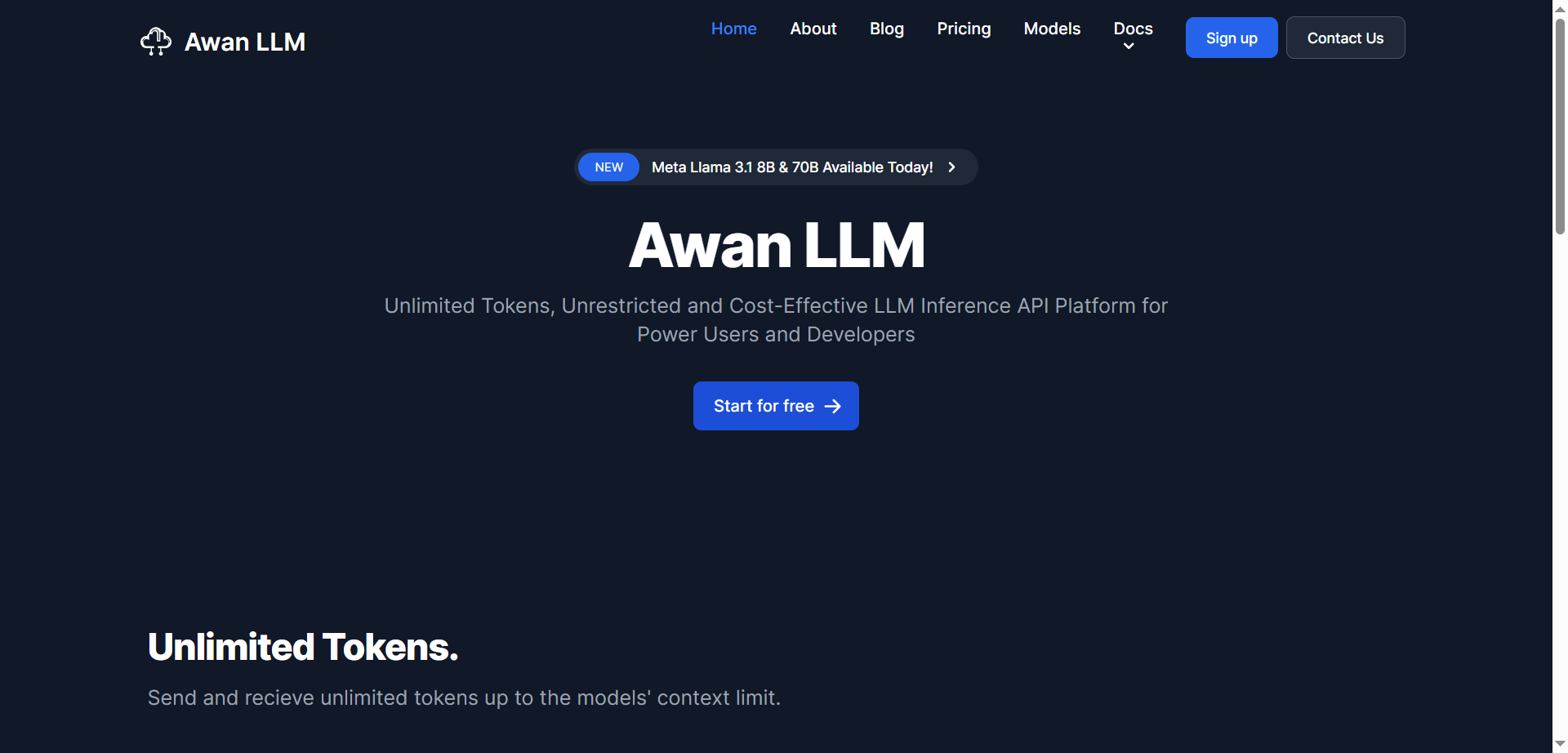

Awan LLM
Awan LLM is a cost-effective, unlimited token large language model inference API platform designed for power users and developers. Unlike traditional API providers that charge per token, Awan LLM offers a monthly subscription model that enables users to send and receive unlimited tokens up to the model's context limit. It supports unrestricted use of LLM models without censorship or constraints. The platform is built on privately owned data centers and GPUs, allowing it to offer efficient and scalable AI services. Awan LLM supports numerous use cases including AI assistants, AI agents, roleplaying, data processing, code completion, and building AI-powered applications without worrying about token limits or costs.
Awan LLM
Awan LLM is a cost-effective, unlimited token large language model inference API platform designed for power users and developers. Unlike traditional API providers that charge per token, Awan LLM offers a monthly subscription model that enables users to send and receive unlimited tokens up to the model's context limit. It supports unrestricted use of LLM models without censorship or constraints. The platform is built on privately owned data centers and GPUs, allowing it to offer efficient and scalable AI services. Awan LLM supports numerous use cases including AI assistants, AI agents, roleplaying, data processing, code completion, and building AI-powered applications without worrying about token limits or costs.
Awan LLM
Awan LLM is a cost-effective, unlimited token large language model inference API platform designed for power users and developers. Unlike traditional API providers that charge per token, Awan LLM offers a monthly subscription model that enables users to send and receive unlimited tokens up to the model's context limit. It supports unrestricted use of LLM models without censorship or constraints. The platform is built on privately owned data centers and GPUs, allowing it to offer efficient and scalable AI services. Awan LLM supports numerous use cases including AI assistants, AI agents, roleplaying, data processing, code completion, and building AI-powered applications without worrying about token limits or costs.
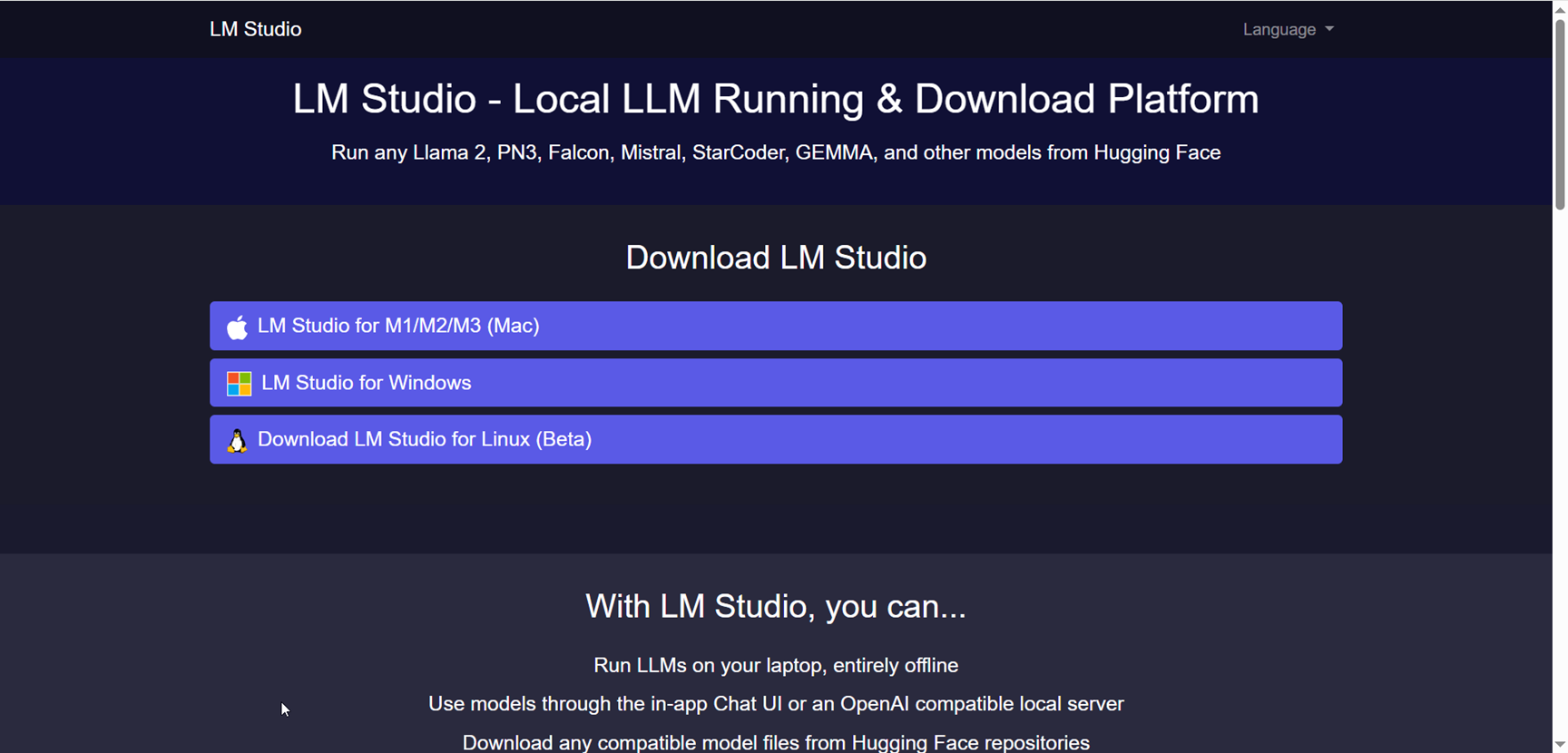
LM Studio
LM Studio is a local large language model (LLM) platform that enables users to run and download powerful AI language models like LLaMa, MPT, and Gemma directly on their own computers. This platform supports Mac, Windows, and Linux operating systems, providing flexibility to users across different devices. LM Studio focuses on privacy and control by allowing users to work with AI models locally without relying on cloud-based services, ensuring data stays on the user’s device. It offers an easy-to-install interface with step-by-step guidance for setup, facilitating access to advanced AI capabilities for developers, researchers, and AI enthusiasts without requiring an internet connection.
LM Studio
LM Studio is a local large language model (LLM) platform that enables users to run and download powerful AI language models like LLaMa, MPT, and Gemma directly on their own computers. This platform supports Mac, Windows, and Linux operating systems, providing flexibility to users across different devices. LM Studio focuses on privacy and control by allowing users to work with AI models locally without relying on cloud-based services, ensuring data stays on the user’s device. It offers an easy-to-install interface with step-by-step guidance for setup, facilitating access to advanced AI capabilities for developers, researchers, and AI enthusiasts without requiring an internet connection.
LM Studio
LM Studio is a local large language model (LLM) platform that enables users to run and download powerful AI language models like LLaMa, MPT, and Gemma directly on their own computers. This platform supports Mac, Windows, and Linux operating systems, providing flexibility to users across different devices. LM Studio focuses on privacy and control by allowing users to work with AI models locally without relying on cloud-based services, ensuring data stays on the user’s device. It offers an easy-to-install interface with step-by-step guidance for setup, facilitating access to advanced AI capabilities for developers, researchers, and AI enthusiasts without requiring an internet connection.


Mem0
Mem0.ai is a universal, self-improving memory layer for LLM applications that gives AI agents persistent recall across conversations. It intelligently compresses chat history into optimized representations, cutting token usage by up to 80% while preserving essential context for personalized experiences. Used by 50k+ developers and companies like Sunflower Sober and OpenNote, Mem0 enables infinite recall in healthcare, education, sales, and more, reducing costs and boosting response quality by 26% over native solutions. With one-line installation, framework compatibility, and enterprise-grade security including SOC 2 and HIPAA compliance, it deploys anywhere from Kubernetes to air-gapped servers for production-ready personalization.
Mem0
Mem0.ai is a universal, self-improving memory layer for LLM applications that gives AI agents persistent recall across conversations. It intelligently compresses chat history into optimized representations, cutting token usage by up to 80% while preserving essential context for personalized experiences. Used by 50k+ developers and companies like Sunflower Sober and OpenNote, Mem0 enables infinite recall in healthcare, education, sales, and more, reducing costs and boosting response quality by 26% over native solutions. With one-line installation, framework compatibility, and enterprise-grade security including SOC 2 and HIPAA compliance, it deploys anywhere from Kubernetes to air-gapped servers for production-ready personalization.
Mem0
Mem0.ai is a universal, self-improving memory layer for LLM applications that gives AI agents persistent recall across conversations. It intelligently compresses chat history into optimized representations, cutting token usage by up to 80% while preserving essential context for personalized experiences. Used by 50k+ developers and companies like Sunflower Sober and OpenNote, Mem0 enables infinite recall in healthcare, education, sales, and more, reducing costs and boosting response quality by 26% over native solutions. With one-line installation, framework compatibility, and enterprise-grade security including SOC 2 and HIPAA compliance, it deploys anywhere from Kubernetes to air-gapped servers for production-ready personalization.
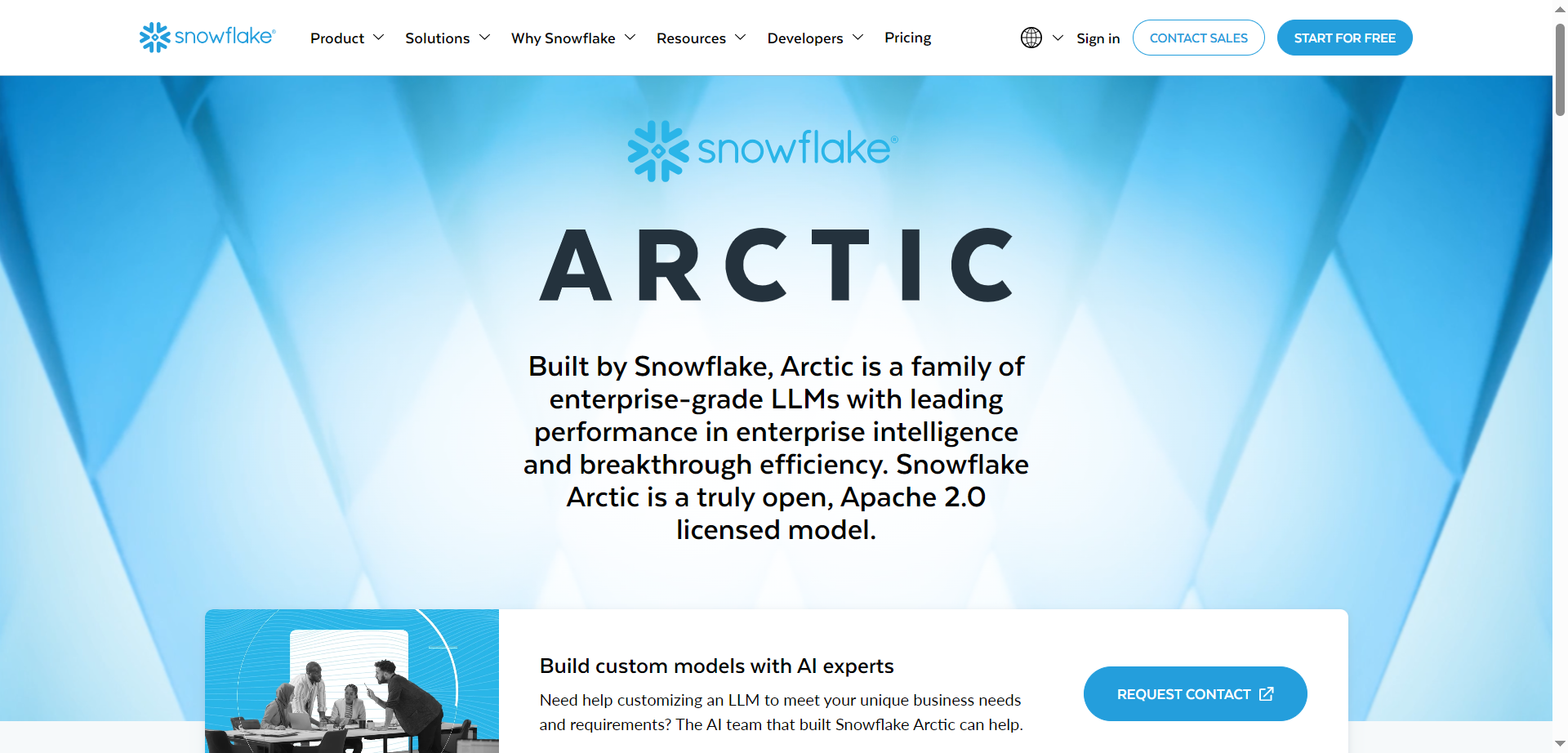
Snowflake - Arctic
Snowflake's Arctic is a family of open-source large language models optimized for enterprise workloads, featuring a unique dense-MoE hybrid architecture that delivers top-tier performance in SQL generation, code tasks, and instruction following at a fraction of comparable model development costs. Released under Apache 2.0 license with fully ungated access to weights, code, open data recipes, and research insights, it excels in complex business scenarios while remaining capable across general tasks. Enterprises can fine-tune or deploy using popular frameworks like LoRA, TRT-LLM, and vLLM, with detailed training and inference cookbooks available. The models lead benchmarks for enterprise intelligence, balancing expert efficiency for fast inference and broad applicability without restrictive gates or proprietary limits.
Snowflake - Arctic
Snowflake's Arctic is a family of open-source large language models optimized for enterprise workloads, featuring a unique dense-MoE hybrid architecture that delivers top-tier performance in SQL generation, code tasks, and instruction following at a fraction of comparable model development costs. Released under Apache 2.0 license with fully ungated access to weights, code, open data recipes, and research insights, it excels in complex business scenarios while remaining capable across general tasks. Enterprises can fine-tune or deploy using popular frameworks like LoRA, TRT-LLM, and vLLM, with detailed training and inference cookbooks available. The models lead benchmarks for enterprise intelligence, balancing expert efficiency for fast inference and broad applicability without restrictive gates or proprietary limits.
Snowflake - Arctic
Snowflake's Arctic is a family of open-source large language models optimized for enterprise workloads, featuring a unique dense-MoE hybrid architecture that delivers top-tier performance in SQL generation, code tasks, and instruction following at a fraction of comparable model development costs. Released under Apache 2.0 license with fully ungated access to weights, code, open data recipes, and research insights, it excels in complex business scenarios while remaining capable across general tasks. Enterprises can fine-tune or deploy using popular frameworks like LoRA, TRT-LLM, and vLLM, with detailed training and inference cookbooks available. The models lead benchmarks for enterprise intelligence, balancing expert efficiency for fast inference and broad applicability without restrictive gates or proprietary limits.

Typing Mind
TypingMind is a powerful frontend for large language models, giving users a clean, customizable interface to interact with AI more efficiently. It enhances the user experience by offering advanced features such as conversation organization, prompt management, model switching, and private local usage options. TypingMind provides a more flexible and user-friendly environment than standard AI chat interfaces, allowing users to optimize workflows, manage sessions, and personalize interactions. It is built for individuals and teams who want full control over how they use LLMs without relying on default chat UIs.
Typing Mind
TypingMind is a powerful frontend for large language models, giving users a clean, customizable interface to interact with AI more efficiently. It enhances the user experience by offering advanced features such as conversation organization, prompt management, model switching, and private local usage options. TypingMind provides a more flexible and user-friendly environment than standard AI chat interfaces, allowing users to optimize workflows, manage sessions, and personalize interactions. It is built for individuals and teams who want full control over how they use LLMs without relying on default chat UIs.
Typing Mind
TypingMind is a powerful frontend for large language models, giving users a clean, customizable interface to interact with AI more efficiently. It enhances the user experience by offering advanced features such as conversation organization, prompt management, model switching, and private local usage options. TypingMind provides a more flexible and user-friendly environment than standard AI chat interfaces, allowing users to optimize workflows, manage sessions, and personalize interactions. It is built for individuals and teams who want full control over how they use LLMs without relying on default chat UIs.
Editorial Note
This page was researched and written by the ATB Editorial Team. Our team researches each AI tool by reviewing its official website, testing features, exploring real use cases, and considering user feedback. Every page is fact-checked and regularly updated to ensure the information stays accurate, neutral, and useful for our readers.
If you have any suggestions or questions, email us at hello@aitoolbook.ai