
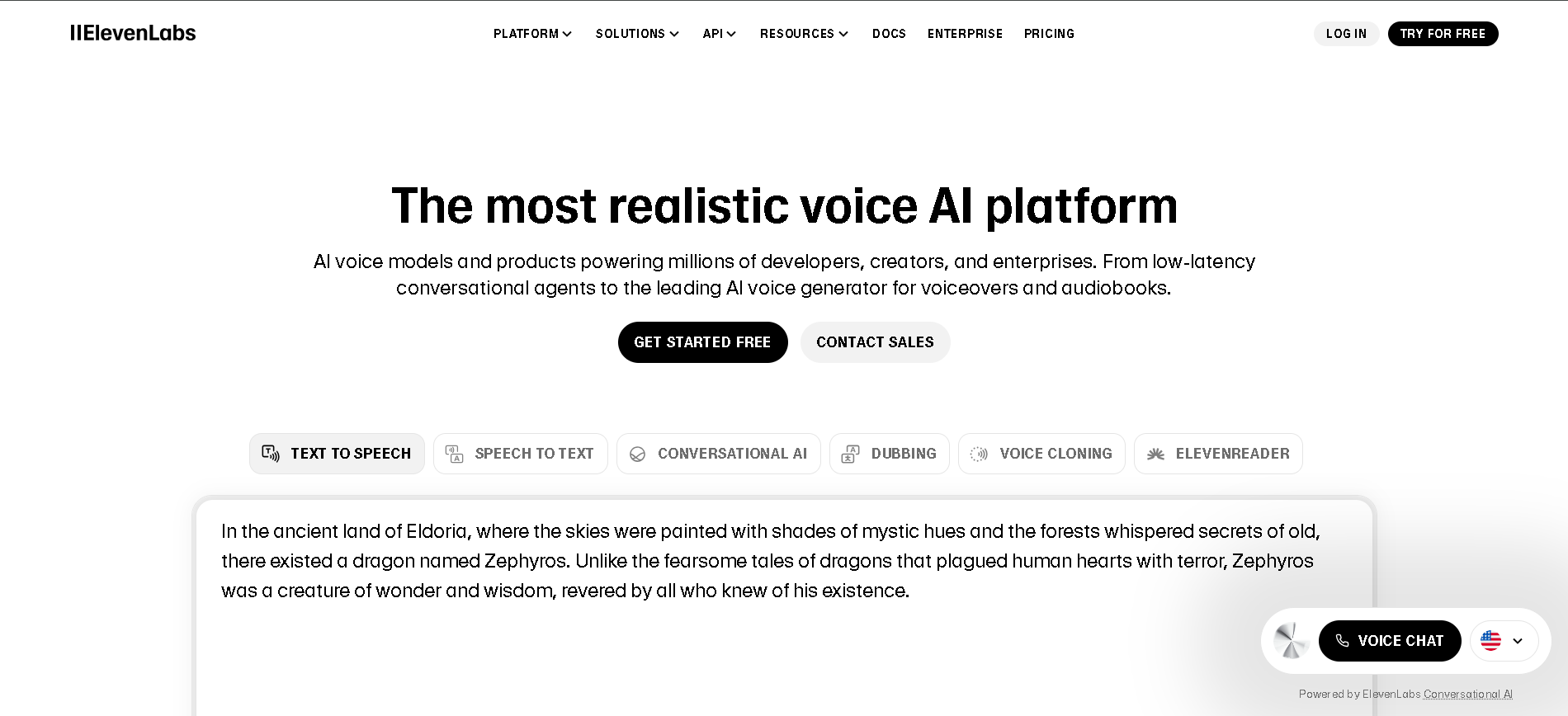
- Content Creators & YouTubers: Generate AI voiceovers for videos, podcasts, and animations.
- Businesses & Marketing Teams: Create engaging audio ads, automated customer support, and interactive content.
- Authors & Audiobook Narrators: Convert text into professional audiobooks with lifelike narration.
- Developers & AI Enthusiasts: Integrate TTS into applications, games, and virtual assistants via API.
- Accessibility & Education: Assist visually impaired users and provide interactive learning.
- Ultra-Realistic AI Voices: Voices sound human-like, with natural intonation and expressiveness.
- Multilingual Support: Generate speech in multiple languages and accents.
- AI Voice Cloning: Create custom voices that mimic real people with just a short audio sample.
- Scalable API for Developers: Seamlessly integrate AI-generated voices into apps, games, and software.
- Customizable Speech Styles: Adjust tone, pacing, and emotional expression to match different use cases.
- Human-Like Speech Quality – Voices sound more natural compared to traditional TTS tools.
- Voice Cloning Feature – Personalize AI voices by training it with real samples.
- Multiple Languages & Accents – Supports diverse global users.
- Fast & Scalable API – Ideal for integrating AI voiceovers into apps and products.
- Premium Features Require Subscription – Free version has limitations on voice generation.
- Ethical Concerns with Voice Cloning – Could be misused for deepfake audio.
- Limited Editing Tools – Lacks advanced post-processing features for fine-tuning speech.




Free
$ 0.00
Speech to Text
Conversational AI
Studio
Automated Dubbing
API access
10 minutes of high-quality Text to Speech
15 minutes of Conversational AI
Starter
$ 5.00
Commercial license
Instant Voice Cloning
20 projects in Studio
Dubbing Studio
30 minutes of high-quality Text to Speech
50 minutes of Conversational AI
Creator
$ 11.00
Professional Voice Cloning
Usage based billing for additional credits
Higher quality audio 192 kbps
100 minutes of high-quality Text to Speech
250 minutes of Conversational AI
Pro
$ 99.00
44.1kHz PCM audio output via API
500 minutes of high-quality Text to Speech
1,100 minutes of Conversational AI
Proud of the love you're getting? Show off your AI Toolbook reviews—then invite more fans to share the love and build your credibility.
Add an AI Toolbook badge to your site—an easy way to drive followers, showcase updates, and collect reviews. It's like a mini 24/7 billboard for your AI.
Reviews
Rating Distribution
Average score
Popular Mention
FAQs
Similar AI Tools
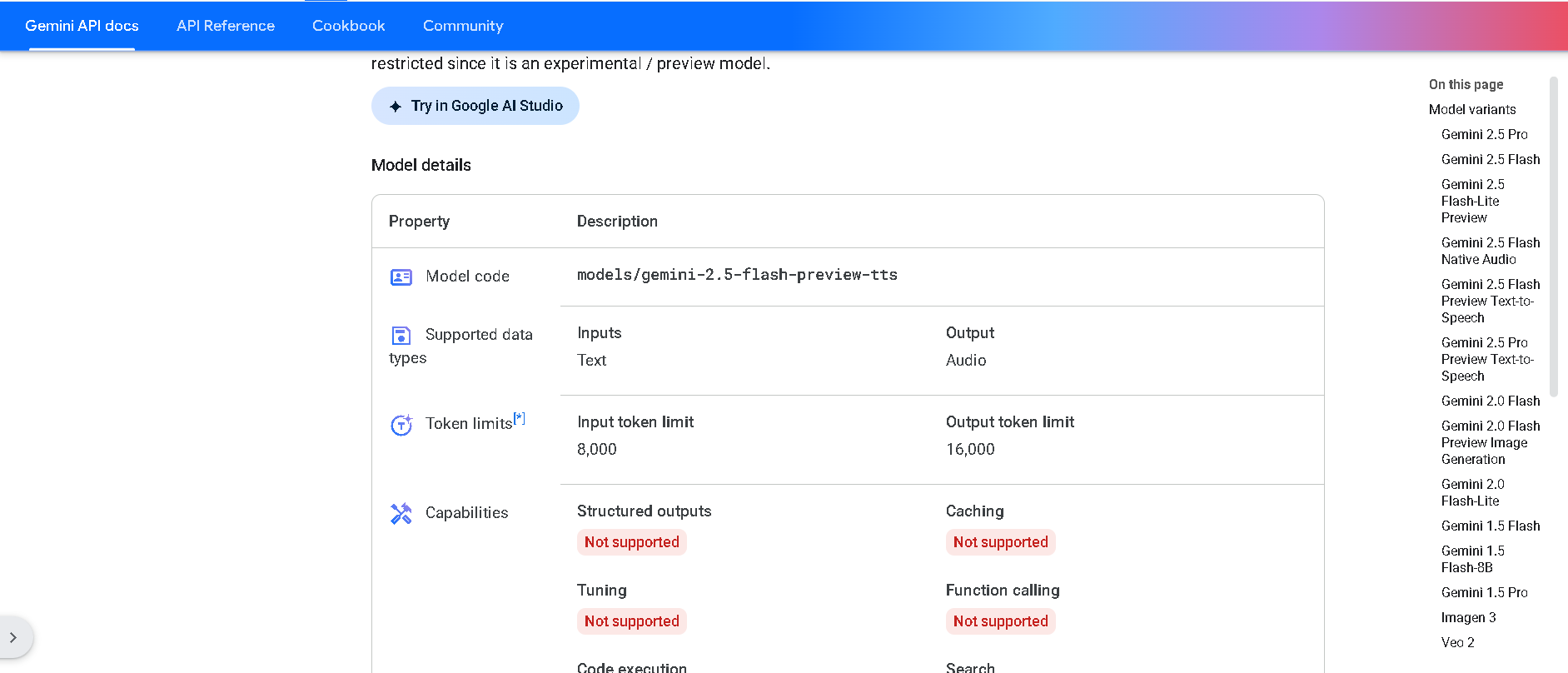
Gemini 2.5 Flash Preview TTS is Google DeepMind’s cutting-edge text-to-speech model that converts text into natural, expressive audio. It supports both single-speaker and multi-speaker output, allowing fine-grained control over style, emotion, pace, and tone. This preview variant is optimized for low latency and structured use cases like podcasts, audiobooks, and customer support workflows .
Gemini 2.5 Flash Preview TTS is Google DeepMind’s cutting-edge text-to-speech model that converts text into natural, expressive audio. It supports both single-speaker and multi-speaker output, allowing fine-grained control over style, emotion, pace, and tone. This preview variant is optimized for low latency and structured use cases like podcasts, audiobooks, and customer support workflows .
Gemini 2.5 Flash Preview TTS is Google DeepMind’s cutting-edge text-to-speech model that converts text into natural, expressive audio. It supports both single-speaker and multi-speaker output, allowing fine-grained control over style, emotion, pace, and tone. This preview variant is optimized for low latency and structured use cases like podcasts, audiobooks, and customer support workflows .
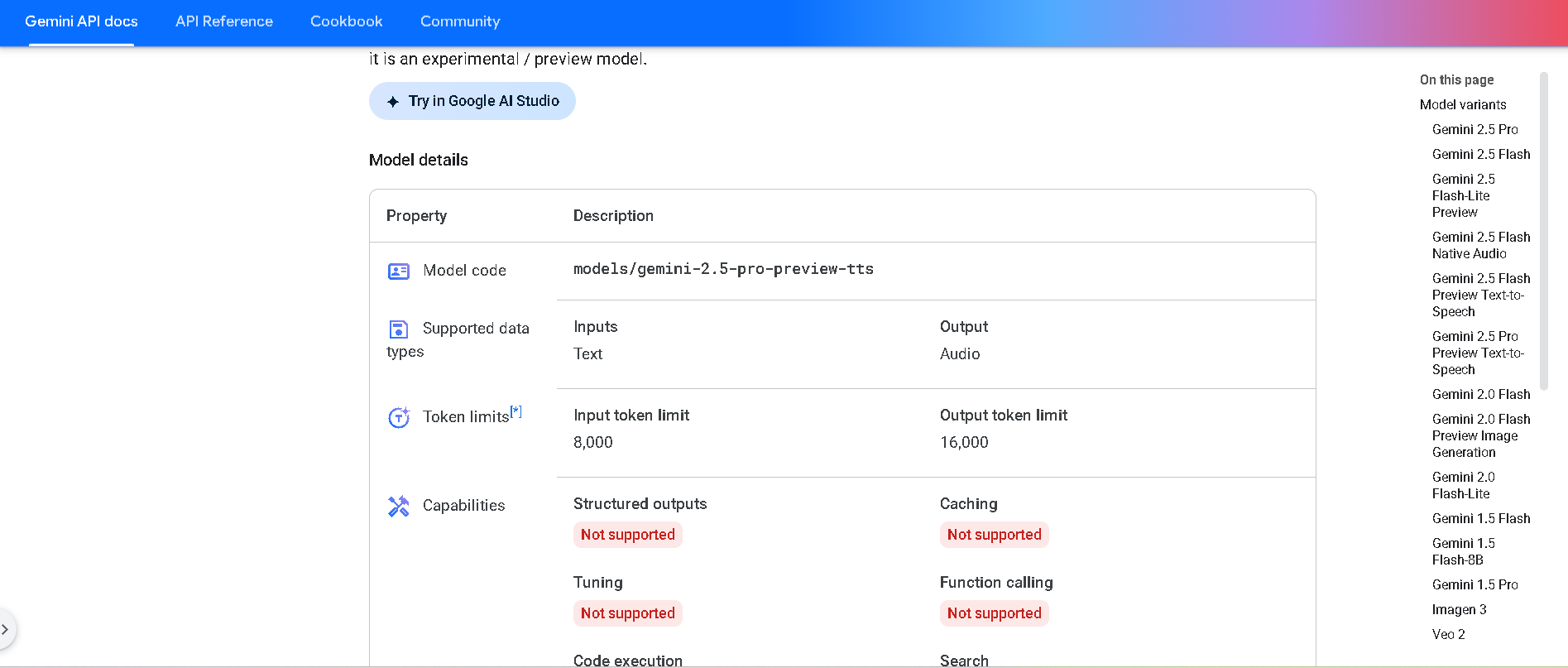
Gemini 2.5 Pro Preview TTS is Google DeepMind’s most powerful text-to-speech model in the Gemini 2.5 series, available in preview. It generates natural-sounding audio—from single-speaker readings to multi-speaker dialogue—while offering fine-grained control over voice style, emotion, pacing, and cadence. Designed for high-fidelity podcasts, audiobooks, and professional voice workflows.
Gemini 2.5 Pro Preview TTS is Google DeepMind’s most powerful text-to-speech model in the Gemini 2.5 series, available in preview. It generates natural-sounding audio—from single-speaker readings to multi-speaker dialogue—while offering fine-grained control over voice style, emotion, pacing, and cadence. Designed for high-fidelity podcasts, audiobooks, and professional voice workflows.
Gemini 2.5 Pro Preview TTS is Google DeepMind’s most powerful text-to-speech model in the Gemini 2.5 series, available in preview. It generates natural-sounding audio—from single-speaker readings to multi-speaker dialogue—while offering fine-grained control over voice style, emotion, pacing, and cadence. Designed for high-fidelity podcasts, audiobooks, and professional voice workflows.
Sesame AI
Sesame Voice AI is a cutting-edge voice synthesis platform that specializes in generating highly realistic and emotionally expressive synthetic voices. Developed by Sesame Labs, this tool bridges the gap between robotic-sounding voice models and human-like speech by incorporating nuanced emotion, context-awareness, and personality into generated audio. Whether it's for games, virtual assistants, films, or branded audio experiences, Sesame aims to "cross the uncanny valley" of voice, producing voices that sound indistinguishably human. It leverages deep learning, large-scale neural networks, and novel techniques in voice conditioning to bring personality-rich, expressive voice capabilities to creators and developers—without needing a real voice actor every time.
Sesame AI
Sesame Voice AI is a cutting-edge voice synthesis platform that specializes in generating highly realistic and emotionally expressive synthetic voices. Developed by Sesame Labs, this tool bridges the gap between robotic-sounding voice models and human-like speech by incorporating nuanced emotion, context-awareness, and personality into generated audio. Whether it's for games, virtual assistants, films, or branded audio experiences, Sesame aims to "cross the uncanny valley" of voice, producing voices that sound indistinguishably human. It leverages deep learning, large-scale neural networks, and novel techniques in voice conditioning to bring personality-rich, expressive voice capabilities to creators and developers—without needing a real voice actor every time.
Sesame AI
Sesame Voice AI is a cutting-edge voice synthesis platform that specializes in generating highly realistic and emotionally expressive synthetic voices. Developed by Sesame Labs, this tool bridges the gap between robotic-sounding voice models and human-like speech by incorporating nuanced emotion, context-awareness, and personality into generated audio. Whether it's for games, virtual assistants, films, or branded audio experiences, Sesame aims to "cross the uncanny valley" of voice, producing voices that sound indistinguishably human. It leverages deep learning, large-scale neural networks, and novel techniques in voice conditioning to bring personality-rich, expressive voice capabilities to creators and developers—without needing a real voice actor every time.
NotebookAI Podcast
AIdeaFlow Podcast is an AI-powered platform that automates the process of transforming text—like articles, PDFs, or scripts—into polished, human-like podcast audio. It leverages advanced Triton TTS models (including Gemini, WorldSpeak, and others) to produce natural-sounding voiceovers in over 31 languages using more than 120 unique voices. You can input content via text, file upload, or URL, and let the AI handle pacing, tone, and voice selection. With support for single speakers, interactive dialogues, and voice cloning, it suits a wide range of creators—from educators turning lecture notes into spoken content to marketers producing audio campaigns. AIdeaFlow features intelligent editing tools to remove errors, manage silence, and add music or effects.
NotebookAI Podcast
AIdeaFlow Podcast is an AI-powered platform that automates the process of transforming text—like articles, PDFs, or scripts—into polished, human-like podcast audio. It leverages advanced Triton TTS models (including Gemini, WorldSpeak, and others) to produce natural-sounding voiceovers in over 31 languages using more than 120 unique voices. You can input content via text, file upload, or URL, and let the AI handle pacing, tone, and voice selection. With support for single speakers, interactive dialogues, and voice cloning, it suits a wide range of creators—from educators turning lecture notes into spoken content to marketers producing audio campaigns. AIdeaFlow features intelligent editing tools to remove errors, manage silence, and add music or effects.
NotebookAI Podcast
AIdeaFlow Podcast is an AI-powered platform that automates the process of transforming text—like articles, PDFs, or scripts—into polished, human-like podcast audio. It leverages advanced Triton TTS models (including Gemini, WorldSpeak, and others) to produce natural-sounding voiceovers in over 31 languages using more than 120 unique voices. You can input content via text, file upload, or URL, and let the AI handle pacing, tone, and voice selection. With support for single speakers, interactive dialogues, and voice cloning, it suits a wide range of creators—from educators turning lecture notes into spoken content to marketers producing audio campaigns. AIdeaFlow features intelligent editing tools to remove errors, manage silence, and add music or effects.
Veo3 AI Video
UseVoe is an AI-powered voice cloning and speech synthesis platform that enables users to create realistic voiceovers using customized synthetic voices. Designed for content creators, marketers, educators, and developers, UseVoe offers a fast and efficient way to generate human-like speech from text without needing professional voice actors or recording studios. The platform supports multiple languages and voice styles, allowing users to select or train voices that match their brand or project tone. Its intuitive interface allows easy input of text scripts, adjustment of speech parameters such as speed and pitch, and immediate generation of audio outputs. Additionally, UseVoe provides API access for seamless integration into applications, games, or multimedia projects. It is useful for producing podcasts, audiobooks, instructional content, advertisements, and more.
Veo3 AI Video
UseVoe is an AI-powered voice cloning and speech synthesis platform that enables users to create realistic voiceovers using customized synthetic voices. Designed for content creators, marketers, educators, and developers, UseVoe offers a fast and efficient way to generate human-like speech from text without needing professional voice actors or recording studios. The platform supports multiple languages and voice styles, allowing users to select or train voices that match their brand or project tone. Its intuitive interface allows easy input of text scripts, adjustment of speech parameters such as speed and pitch, and immediate generation of audio outputs. Additionally, UseVoe provides API access for seamless integration into applications, games, or multimedia projects. It is useful for producing podcasts, audiobooks, instructional content, advertisements, and more.
Veo3 AI Video
UseVoe is an AI-powered voice cloning and speech synthesis platform that enables users to create realistic voiceovers using customized synthetic voices. Designed for content creators, marketers, educators, and developers, UseVoe offers a fast and efficient way to generate human-like speech from text without needing professional voice actors or recording studios. The platform supports multiple languages and voice styles, allowing users to select or train voices that match their brand or project tone. Its intuitive interface allows easy input of text scripts, adjustment of speech parameters such as speed and pitch, and immediate generation of audio outputs. Additionally, UseVoe provides API access for seamless integration into applications, games, or multimedia projects. It is useful for producing podcasts, audiobooks, instructional content, advertisements, and more.
AI Voice Generator – Voice Cloning is a cutting-edge platform that leverages Higgs Audio's advanced neural networks to create realistic voice replicas from just a short audio sample. This tool allows users to clone voices with minimal reference audio, offering professional-grade results in under 100 milliseconds. Ideal for content creators, voice actors, and developers, it provides an open-source framework for customizable voice models.
AI Voice Generator – Voice Cloning is a cutting-edge platform that leverages Higgs Audio's advanced neural networks to create realistic voice replicas from just a short audio sample. This tool allows users to clone voices with minimal reference audio, offering professional-grade results in under 100 milliseconds. Ideal for content creators, voice actors, and developers, it provides an open-source framework for customizable voice models.
AI Voice Generator – Voice Cloning is a cutting-edge platform that leverages Higgs Audio's advanced neural networks to create realistic voice replicas from just a short audio sample. This tool allows users to clone voices with minimal reference audio, offering professional-grade results in under 100 milliseconds. Ideal for content creators, voice actors, and developers, it provides an open-source framework for customizable voice models.

Murf.ai
Murf.ai is an AI voice generator and text-to-speech platform that delivers ultra-realistic voiceovers for creators, teams, and developers. It offers 200+ multilingual voices, 10+ speaking styles, and fine-grained controls over pitch, speed, tone, prosody, and pronunciation. A low-latency TTS model powers conversational agents with sub-200 ms response, while APIs enable voice cloning, voice changing, streaming TTS, and translation/dubbing in 30+ languages. A studio workspace supports scripting, timing, and rapid iteration for ads, training, audiobooks, podcasts, and product audio. Pronunciation libraries, team workspaces, and tool integrations help standardize brand voice at scale without complex audio engineering.
Murf.ai
Murf.ai is an AI voice generator and text-to-speech platform that delivers ultra-realistic voiceovers for creators, teams, and developers. It offers 200+ multilingual voices, 10+ speaking styles, and fine-grained controls over pitch, speed, tone, prosody, and pronunciation. A low-latency TTS model powers conversational agents with sub-200 ms response, while APIs enable voice cloning, voice changing, streaming TTS, and translation/dubbing in 30+ languages. A studio workspace supports scripting, timing, and rapid iteration for ads, training, audiobooks, podcasts, and product audio. Pronunciation libraries, team workspaces, and tool integrations help standardize brand voice at scale without complex audio engineering.
Murf.ai
Murf.ai is an AI voice generator and text-to-speech platform that delivers ultra-realistic voiceovers for creators, teams, and developers. It offers 200+ multilingual voices, 10+ speaking styles, and fine-grained controls over pitch, speed, tone, prosody, and pronunciation. A low-latency TTS model powers conversational agents with sub-200 ms response, while APIs enable voice cloning, voice changing, streaming TTS, and translation/dubbing in 30+ languages. A studio workspace supports scripting, timing, and rapid iteration for ads, training, audiobooks, podcasts, and product audio. Pronunciation libraries, team workspaces, and tool integrations help standardize brand voice at scale without complex audio engineering.

Resemble.AI
Resemble AI is an enterprise-focused Voice AI platform built on trust, offering realistic voice generation, voice cloning, and multi-modal deepfake detection across audio, image, and video. It provides real-time text-to-speech and speech-to-speech backed by advanced models like Chatterbox, plus watermarking for provenance and intelligence features for language, dialect, and anomaly detection. Teams can create branded, controllable voices, edit audio by typing, and deploy voice agents with developer-ready tooling. The platform also enables on-premises or private deployment for stricter compliance. With integrated security awareness training and automated monitoring, Resemble helps organizations scale voice experiences while defending against synthetic media risks.
Resemble.AI
Resemble AI is an enterprise-focused Voice AI platform built on trust, offering realistic voice generation, voice cloning, and multi-modal deepfake detection across audio, image, and video. It provides real-time text-to-speech and speech-to-speech backed by advanced models like Chatterbox, plus watermarking for provenance and intelligence features for language, dialect, and anomaly detection. Teams can create branded, controllable voices, edit audio by typing, and deploy voice agents with developer-ready tooling. The platform also enables on-premises or private deployment for stricter compliance. With integrated security awareness training and automated monitoring, Resemble helps organizations scale voice experiences while defending against synthetic media risks.
Resemble.AI
Resemble AI is an enterprise-focused Voice AI platform built on trust, offering realistic voice generation, voice cloning, and multi-modal deepfake detection across audio, image, and video. It provides real-time text-to-speech and speech-to-speech backed by advanced models like Chatterbox, plus watermarking for provenance and intelligence features for language, dialect, and anomaly detection. Teams can create branded, controllable voices, edit audio by typing, and deploy voice agents with developer-ready tooling. The platform also enables on-premises or private deployment for stricter compliance. With integrated security awareness training and automated monitoring, Resemble helps organizations scale voice experiences while defending against synthetic media risks.

InfiniteTalk AI
InfiniteTalk is an AI-powered conversational media platform that generates natural, expressive dialogues and multi-voice audio scenes directly from text. Designed for creators, educators, marketers, and product teams, it enables users to script conversations between multiple characters, control emotions, pacing, tone, and style, and instantly produce high-quality audio without recording equipment or voice actors. InfiniteTalk specializes in dynamic, lifelike spoken interactions, allowing users to model realistic conversations for storytelling, training, entertainment, support simulations, and interactive content. The platform functions as a flexible dialogue engine where written scripts transform into fully voiced audio experiences. Users can assign different AI voices to characters, refine emotional delivery, modify timing, and generate entire conversational flows that feel coherent and human.
InfiniteTalk AI
InfiniteTalk is an AI-powered conversational media platform that generates natural, expressive dialogues and multi-voice audio scenes directly from text. Designed for creators, educators, marketers, and product teams, it enables users to script conversations between multiple characters, control emotions, pacing, tone, and style, and instantly produce high-quality audio without recording equipment or voice actors. InfiniteTalk specializes in dynamic, lifelike spoken interactions, allowing users to model realistic conversations for storytelling, training, entertainment, support simulations, and interactive content. The platform functions as a flexible dialogue engine where written scripts transform into fully voiced audio experiences. Users can assign different AI voices to characters, refine emotional delivery, modify timing, and generate entire conversational flows that feel coherent and human.
InfiniteTalk AI
InfiniteTalk is an AI-powered conversational media platform that generates natural, expressive dialogues and multi-voice audio scenes directly from text. Designed for creators, educators, marketers, and product teams, it enables users to script conversations between multiple characters, control emotions, pacing, tone, and style, and instantly produce high-quality audio without recording equipment or voice actors. InfiniteTalk specializes in dynamic, lifelike spoken interactions, allowing users to model realistic conversations for storytelling, training, entertainment, support simulations, and interactive content. The platform functions as a flexible dialogue engine where written scripts transform into fully voiced audio experiences. Users can assign different AI voices to characters, refine emotional delivery, modify timing, and generate entire conversational flows that feel coherent and human.

CoeFont
Coefont Cloud is an AI voice-generation platform that enables users to create natural, expressive, and customizable synthetic voices for narration, dialogue, and media production. It specializes in delivering high-quality text-to-speech output with strong emotional dynamics, allowing creators to apply tone, style, pitch, and pacing adjustments to match different use cases. Coefont Cloud also offers a unique personalized voice-creation feature, enabling users to generate their own AI voice by recording a short audio sample. The platform supports large-scale production workflows by offering batch generation, multilingual support, and real-time previewing.
CoeFont
Coefont Cloud is an AI voice-generation platform that enables users to create natural, expressive, and customizable synthetic voices for narration, dialogue, and media production. It specializes in delivering high-quality text-to-speech output with strong emotional dynamics, allowing creators to apply tone, style, pitch, and pacing adjustments to match different use cases. Coefont Cloud also offers a unique personalized voice-creation feature, enabling users to generate their own AI voice by recording a short audio sample. The platform supports large-scale production workflows by offering batch generation, multilingual support, and real-time previewing.
CoeFont
Coefont Cloud is an AI voice-generation platform that enables users to create natural, expressive, and customizable synthetic voices for narration, dialogue, and media production. It specializes in delivering high-quality text-to-speech output with strong emotional dynamics, allowing creators to apply tone, style, pitch, and pacing adjustments to match different use cases. Coefont Cloud also offers a unique personalized voice-creation feature, enabling users to generate their own AI voice by recording a short audio sample. The platform supports large-scale production workflows by offering batch generation, multilingual support, and real-time previewing.

Voice.ai
Voice.ai is an AI voice platform that delivers realistic voice agents, studio-quality text-to-speech, rapid voice cloning, and a free real-time voice changer all in one system. Businesses can deploy human-like AI phone agents for 24/7 inbound and outbound calls, lead qualification, appointment booking, and customer conversations that integrate seamlessly with CRM tools like Salesforce and HubSpot. It generates lifelike TTS audio in 15+ languages with accent localization, clones voices from just 10 seconds of sample audio, and offers a free voice changer for gamers and streamers to switch voices live. With enterprise compliance including GDPR, SOC 2, and HIPAA plus cloud or on-premise deployment options.
Voice.ai
Voice.ai is an AI voice platform that delivers realistic voice agents, studio-quality text-to-speech, rapid voice cloning, and a free real-time voice changer all in one system. Businesses can deploy human-like AI phone agents for 24/7 inbound and outbound calls, lead qualification, appointment booking, and customer conversations that integrate seamlessly with CRM tools like Salesforce and HubSpot. It generates lifelike TTS audio in 15+ languages with accent localization, clones voices from just 10 seconds of sample audio, and offers a free voice changer for gamers and streamers to switch voices live. With enterprise compliance including GDPR, SOC 2, and HIPAA plus cloud or on-premise deployment options.
Voice.ai
Voice.ai is an AI voice platform that delivers realistic voice agents, studio-quality text-to-speech, rapid voice cloning, and a free real-time voice changer all in one system. Businesses can deploy human-like AI phone agents for 24/7 inbound and outbound calls, lead qualification, appointment booking, and customer conversations that integrate seamlessly with CRM tools like Salesforce and HubSpot. It generates lifelike TTS audio in 15+ languages with accent localization, clones voices from just 10 seconds of sample audio, and offers a free voice changer for gamers and streamers to switch voices live. With enterprise compliance including GDPR, SOC 2, and HIPAA plus cloud or on-premise deployment options.

Noiz
Noiz is a leading AI platform for advanced speech synthesis and audio generation, specializing in highly expressive, lifelike voices with emotional control and customization. It offers text-to-speech , voice cloning, multilingual dubbing, AI singing voice generation, and developer APIs for seamless integration into apps. Users can create realistic vocals with nuance, vibrato, and dynamics from simple prompts, supporting video translation, audio editing, and music production. The tool excels in cost-efficiency, handling everything from podcast mastering to viral song covers, with features like noise removal, auto-leveling, and scene-based soundscapes. Ideal for creators seeking professional audio without studios.
Noiz
Noiz is a leading AI platform for advanced speech synthesis and audio generation, specializing in highly expressive, lifelike voices with emotional control and customization. It offers text-to-speech , voice cloning, multilingual dubbing, AI singing voice generation, and developer APIs for seamless integration into apps. Users can create realistic vocals with nuance, vibrato, and dynamics from simple prompts, supporting video translation, audio editing, and music production. The tool excels in cost-efficiency, handling everything from podcast mastering to viral song covers, with features like noise removal, auto-leveling, and scene-based soundscapes. Ideal for creators seeking professional audio without studios.
Noiz
Noiz is a leading AI platform for advanced speech synthesis and audio generation, specializing in highly expressive, lifelike voices with emotional control and customization. It offers text-to-speech , voice cloning, multilingual dubbing, AI singing voice generation, and developer APIs for seamless integration into apps. Users can create realistic vocals with nuance, vibrato, and dynamics from simple prompts, supporting video translation, audio editing, and music production. The tool excels in cost-efficiency, handling everything from podcast mastering to viral song covers, with features like noise removal, auto-leveling, and scene-based soundscapes. Ideal for creators seeking professional audio without studios.
Editorial Note
This page was researched and written by the ATB Editorial Team. Our team researches each AI tool by reviewing its official website, testing features, exploring real use cases, and considering user feedback. Every page is fact-checked and regularly updated to ensure the information stays accurate, neutral, and useful for our readers.
If you have any suggestions or questions, email us at hello@aitoolbook.ai