
- Songwriters & Composers: Sketch full vocal performances directly from MIDI and lyrics—no studio required.
- Producers & Arrangers: Layer expressive voices with styles like chest, belt, breathy, and even rap—multilingual, too.
- Electronic Musicians & Demo Artists: Write, audition, and export vocal ideas without hiring singers.
- Audio Engineers & Project Creators: Customize vocal expression in profound detail—phoneme timing, dynamics, retakes.
- Multicultural Artists & Studios: Create realistic English, Japanese, Chinese, Cantonese, Korean, or Spanish singing—all in one tool.
How to Use Synthesizer V Studio 2?
- Download & Install: Available for Windows, macOS, and Linux—launch the app or hook it as a VST/AU plugin.
- Create Your Track: Enter MIDI notes and lyrics via built-in editor or import existing files.
- Select Your Voice: Tap into free starter voices like Mai 2, Liam, or Mo Xu—or use prior SynthV 1 voice banks.
- Customize Vocal Delivery: Tweak pitch, mouth movement, expression, pronunciation, emotion, and choose new vocal modes.
- Use AI Retakes & Speed Boosts: Generate alternate takes, refine phrasing, and render vocals up to three times faster offline.
- Scripting & Automation: Harness JavaScript or Lua to script retakes, pitch curves, timing shifts, or mixer tweaks.
- Export or Integrate: Render as audio or use as a plugin inside your DAW for direct vocal layering and manipulation.
- AI + Sample-Based Hybrid Engine: Get lifelike singing that blends nuance and realism through advanced synthesis.
- Speech-Level Expressivity Control: Everything—from intense vibrato to mouth movement—is tweakable to feel genuinely alive.
- Supercharged Performance: Offline rendering is lightning-fast—perfect for workflow flow and real-time creation.
- Multilingual Singing & Rap Support: Works fluently across languages and vocal styles—flexibility that matches global creativity.
- Deep Scriptability: JavaScript and Lua scripting let power users automate and modulate vocal output precisely and creatively.
- Studio-grade vocal realism without mic sessions or auditions.
- Flexible voice styling, languages, and expressive controls—serious creative depth.
- Efficiency gains that save time without sacrificing quality.
- Framework that spans from novice-friendly editing to pro scripting.
- Seamless integration into existing music workflows as a plugin.
- The learning curve can be steep—especially for complex vocal tweaks or scripting.
- Premium voices and pro scripting need paid Studio 2 Pro.
- Resource-heavy on older machines—fast rendering demands good hardware.
- Interface is powerful—but can feel dense without guided onboarding.

Synthesizer V Studio Pro
$89 One Time Purchase
- Standard Offline Rendering
- Retake Pitch / Timbre
- Timbre only
- Manual Mode / Pitch Deviation
- Tension, Breathiness, Voicing, Gender, Tone Shift
- Duration / Strength Sliders
- Windows / Linux / macOS
- Available both as a standalone and as VST3, AU, AAX, ARA
Synthesizer V Studio 2 Pro
$99 One Time Purchase
- Up to 300% Faster Offline Rendering
- Retake Pitch / Timbre / Timing
- Pitch / Timbre / Pronunciation
- Smart Pitch Controls
- + New Mouth Opening Parameter
- Dedicated Phoneme Timing Panel
- Windows / macOS
Proud of the love you're getting? Show off your AI Toolbook reviews—then invite more fans to share the love and build your credibility.
Add an AI Toolbook badge to your site—an easy way to drive followers, showcase updates, and collect reviews. It's like a mini 24/7 billboard for your AI.
Reviews
Rating Distribution
Average score
Popular Mention
FAQs
Similar AI Tools
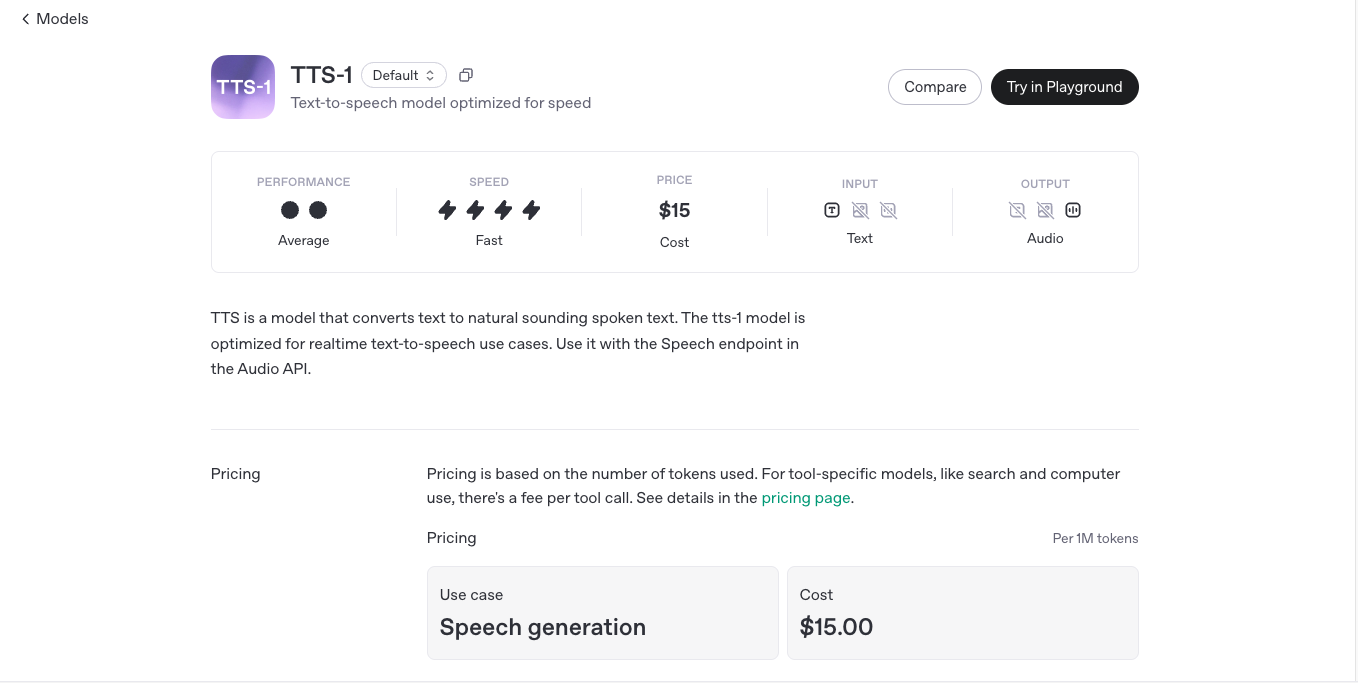
OpenAI TTS1
OpenAI's TTS-1 (Text-to-Speech) is a cutting-edge generative voice model that converts written text into natural-sounding speech with astonishing clarity, pacing, and emotional nuance. TTS-1 is designed to power real-time voice applications—like assistants, narrators, or conversational agents—with near-human vocal quality and minimal latency. Available through OpenAI’s API, this model makes it easy for developers to give their applications a voice that actually sounds human—not robotic. With multiple voices, languages, and low-latency streaming, TTS-1 redefines the synthetic voice experience.
OpenAI TTS1
OpenAI's TTS-1 (Text-to-Speech) is a cutting-edge generative voice model that converts written text into natural-sounding speech with astonishing clarity, pacing, and emotional nuance. TTS-1 is designed to power real-time voice applications—like assistants, narrators, or conversational agents—with near-human vocal quality and minimal latency. Available through OpenAI’s API, this model makes it easy for developers to give their applications a voice that actually sounds human—not robotic. With multiple voices, languages, and low-latency streaming, TTS-1 redefines the synthetic voice experience.
OpenAI TTS1
OpenAI's TTS-1 (Text-to-Speech) is a cutting-edge generative voice model that converts written text into natural-sounding speech with astonishing clarity, pacing, and emotional nuance. TTS-1 is designed to power real-time voice applications—like assistants, narrators, or conversational agents—with near-human vocal quality and minimal latency. Available through OpenAI’s API, this model makes it easy for developers to give their applications a voice that actually sounds human—not robotic. With multiple voices, languages, and low-latency streaming, TTS-1 redefines the synthetic voice experience.
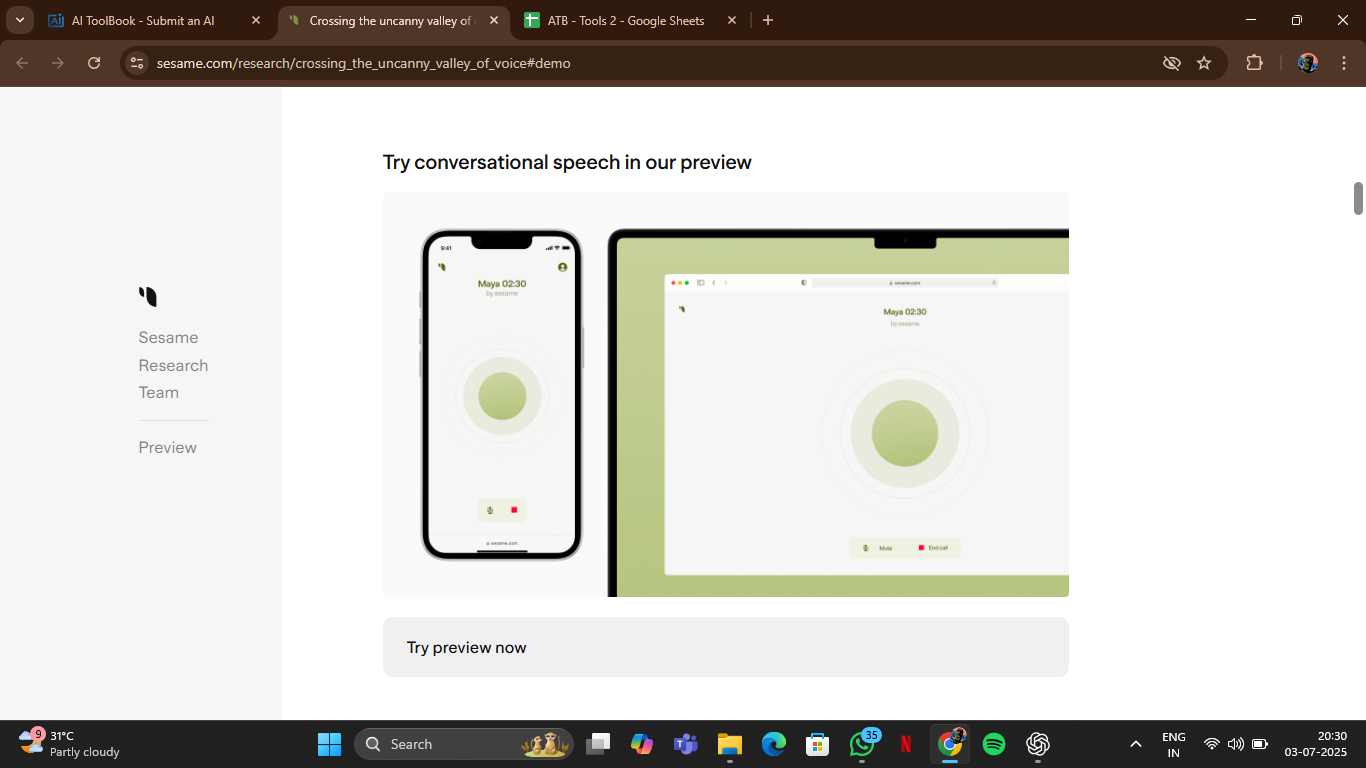
Sesame AI
Sesame Voice AI is a cutting-edge voice synthesis platform that specializes in generating highly realistic and emotionally expressive synthetic voices. Developed by Sesame Labs, this tool bridges the gap between robotic-sounding voice models and human-like speech by incorporating nuanced emotion, context-awareness, and personality into generated audio. Whether it's for games, virtual assistants, films, or branded audio experiences, Sesame aims to "cross the uncanny valley" of voice, producing voices that sound indistinguishably human. It leverages deep learning, large-scale neural networks, and novel techniques in voice conditioning to bring personality-rich, expressive voice capabilities to creators and developers—without needing a real voice actor every time.
Sesame AI
Sesame Voice AI is a cutting-edge voice synthesis platform that specializes in generating highly realistic and emotionally expressive synthetic voices. Developed by Sesame Labs, this tool bridges the gap between robotic-sounding voice models and human-like speech by incorporating nuanced emotion, context-awareness, and personality into generated audio. Whether it's for games, virtual assistants, films, or branded audio experiences, Sesame aims to "cross the uncanny valley" of voice, producing voices that sound indistinguishably human. It leverages deep learning, large-scale neural networks, and novel techniques in voice conditioning to bring personality-rich, expressive voice capabilities to creators and developers—without needing a real voice actor every time.
Sesame AI
Sesame Voice AI is a cutting-edge voice synthesis platform that specializes in generating highly realistic and emotionally expressive synthetic voices. Developed by Sesame Labs, this tool bridges the gap between robotic-sounding voice models and human-like speech by incorporating nuanced emotion, context-awareness, and personality into generated audio. Whether it's for games, virtual assistants, films, or branded audio experiences, Sesame aims to "cross the uncanny valley" of voice, producing voices that sound indistinguishably human. It leverages deep learning, large-scale neural networks, and novel techniques in voice conditioning to bring personality-rich, expressive voice capabilities to creators and developers—without needing a real voice actor every time.
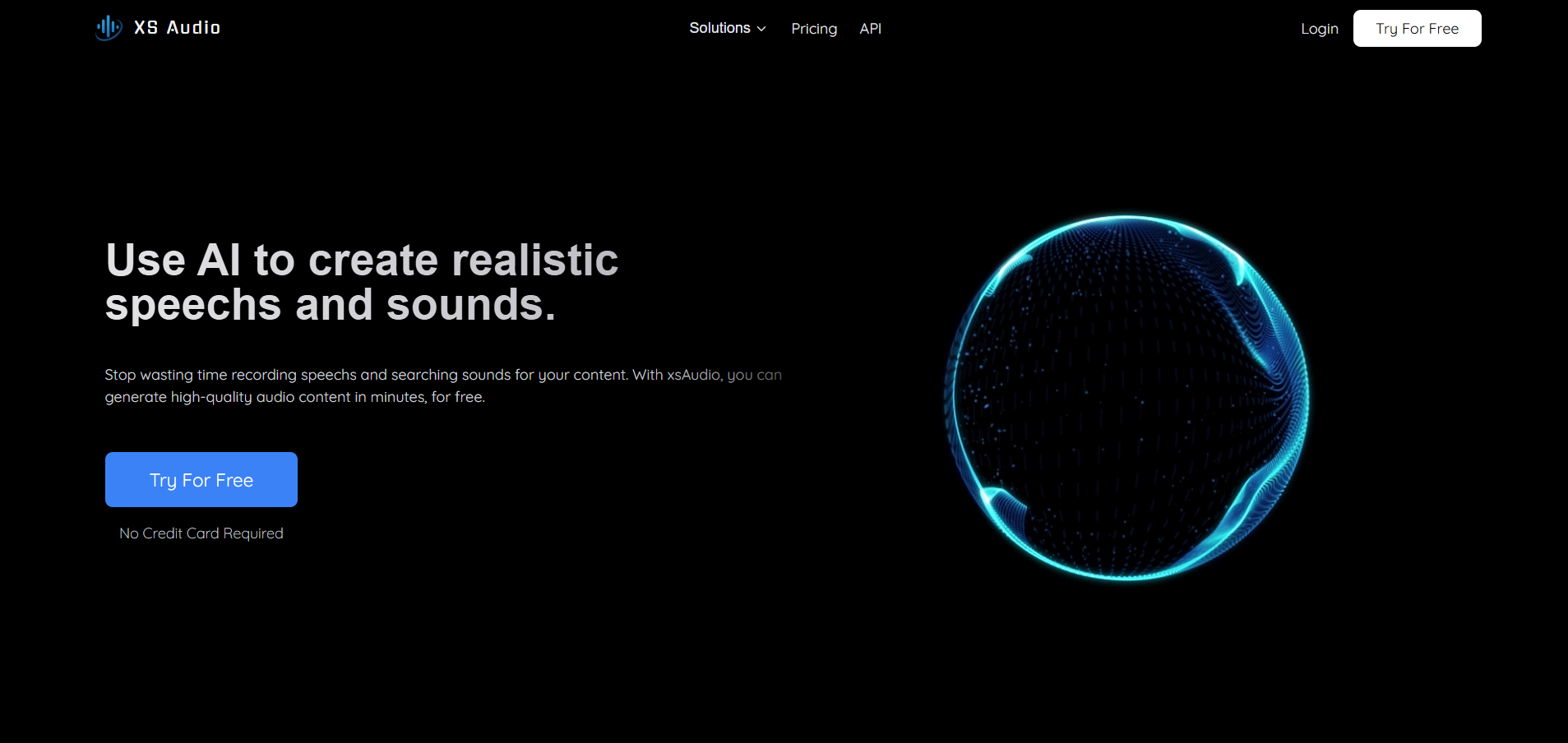

XSAudio
XSAudio is a powerful AI audio platform offering text-to-speech, voice cloning, and sound effect generation. With realistic voice libraries, custom cloning, and multilingual support, it’s perfect for creators, developers, and businesses needing high-quality audio fast. Use it for videos, podcasts, games, and more—with daily free credits and API access.
XSAudio
XSAudio is a powerful AI audio platform offering text-to-speech, voice cloning, and sound effect generation. With realistic voice libraries, custom cloning, and multilingual support, it’s perfect for creators, developers, and businesses needing high-quality audio fast. Use it for videos, podcasts, games, and more—with daily free credits and API access.
XSAudio
XSAudio is a powerful AI audio platform offering text-to-speech, voice cloning, and sound effect generation. With realistic voice libraries, custom cloning, and multilingual support, it’s perfect for creators, developers, and businesses needing high-quality audio fast. Use it for videos, podcasts, games, and more—with daily free credits and API access.
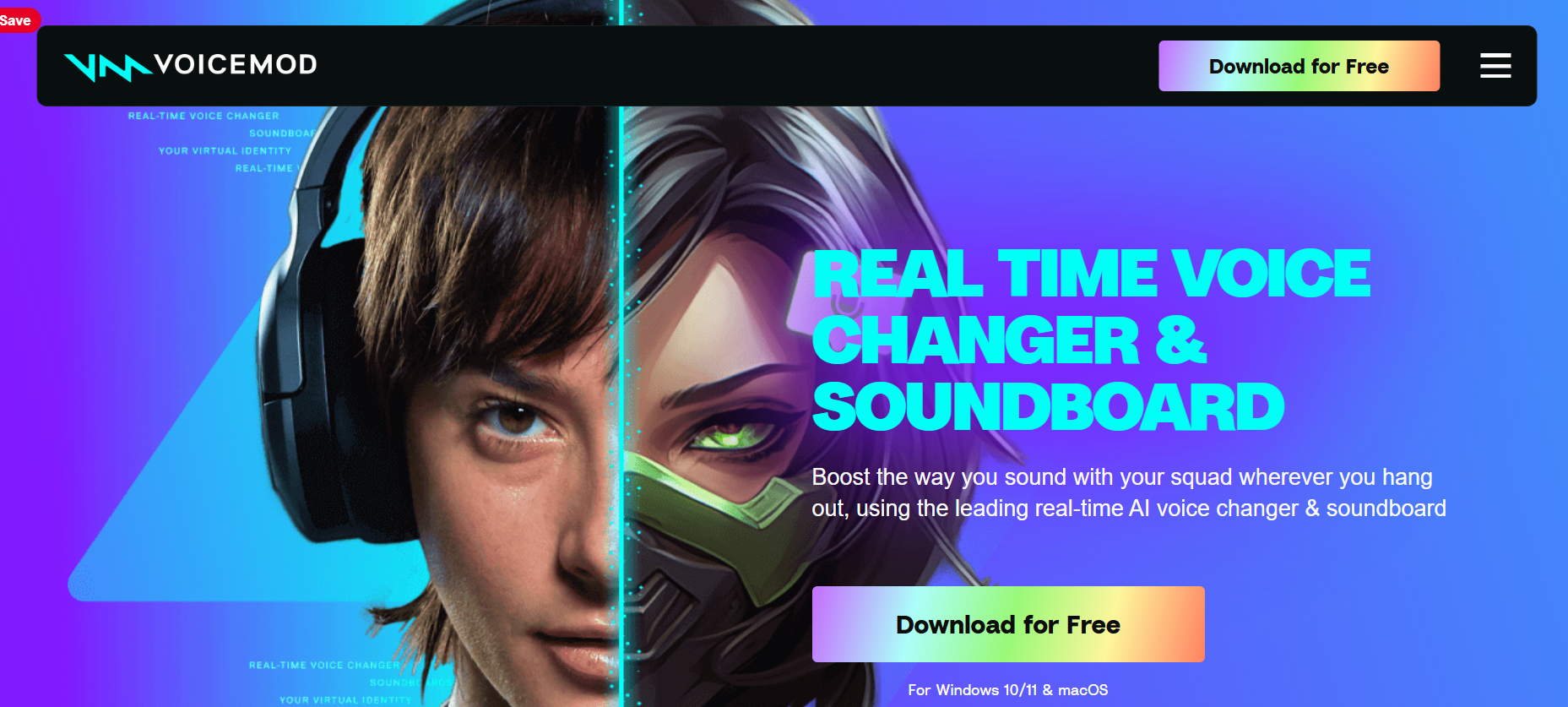

Voicemod
Voicemod is a dynamic real-time AI voice changer and soundboard app designed to supercharge your mic—from gaming streams to group chats. It elevates your voice with ultra-low latency, noise suppression, and performance-optimized voice effects that work across platforms like Discord, in-game voice chats, and streaming. With the powerful Voicelab 2.0 editor, you can drag, mix, and craft custom voice effects—from robotic textures to cinematic ambiance—tailored to your vibe. Drop sound memes, record instant replays, or remix trending audio right into your soundboard. Need to extend the fun to consoles? Pair your phone with Voicemod Key and carry the chaos there, too.
Voicemod
Voicemod is a dynamic real-time AI voice changer and soundboard app designed to supercharge your mic—from gaming streams to group chats. It elevates your voice with ultra-low latency, noise suppression, and performance-optimized voice effects that work across platforms like Discord, in-game voice chats, and streaming. With the powerful Voicelab 2.0 editor, you can drag, mix, and craft custom voice effects—from robotic textures to cinematic ambiance—tailored to your vibe. Drop sound memes, record instant replays, or remix trending audio right into your soundboard. Need to extend the fun to consoles? Pair your phone with Voicemod Key and carry the chaos there, too.
Voicemod
Voicemod is a dynamic real-time AI voice changer and soundboard app designed to supercharge your mic—from gaming streams to group chats. It elevates your voice with ultra-low latency, noise suppression, and performance-optimized voice effects that work across platforms like Discord, in-game voice chats, and streaming. With the powerful Voicelab 2.0 editor, you can drag, mix, and craft custom voice effects—from robotic textures to cinematic ambiance—tailored to your vibe. Drop sound memes, record instant replays, or remix trending audio right into your soundboard. Need to extend the fun to consoles? Pair your phone with Voicemod Key and carry the chaos there, too.


VoiSpark
VoiSpark is an advanced AI-driven voice generation platform designed to transform text into natural, expressive speech and to create unique vocal identities using industry-leading AI models like ElevenLabs, Cartesia, and OpenAI. The platform offers tools for text-to-speech conversion, voice generation with emotion and pitch control, voice changing to mimic celebrities or cartoons, and voice cloning with just one minute of audio. VoiSpark supports over 500 human-like voices across 30+ languages, making it ideal for content creators, marketers, and businesses seeking studio-quality voice solutions.
VoiSpark
VoiSpark is an advanced AI-driven voice generation platform designed to transform text into natural, expressive speech and to create unique vocal identities using industry-leading AI models like ElevenLabs, Cartesia, and OpenAI. The platform offers tools for text-to-speech conversion, voice generation with emotion and pitch control, voice changing to mimic celebrities or cartoons, and voice cloning with just one minute of audio. VoiSpark supports over 500 human-like voices across 30+ languages, making it ideal for content creators, marketers, and businesses seeking studio-quality voice solutions.
VoiSpark
VoiSpark is an advanced AI-driven voice generation platform designed to transform text into natural, expressive speech and to create unique vocal identities using industry-leading AI models like ElevenLabs, Cartesia, and OpenAI. The platform offers tools for text-to-speech conversion, voice generation with emotion and pitch control, voice changing to mimic celebrities or cartoons, and voice cloning with just one minute of audio. VoiSpark supports over 500 human-like voices across 30+ languages, making it ideal for content creators, marketers, and businesses seeking studio-quality voice solutions.
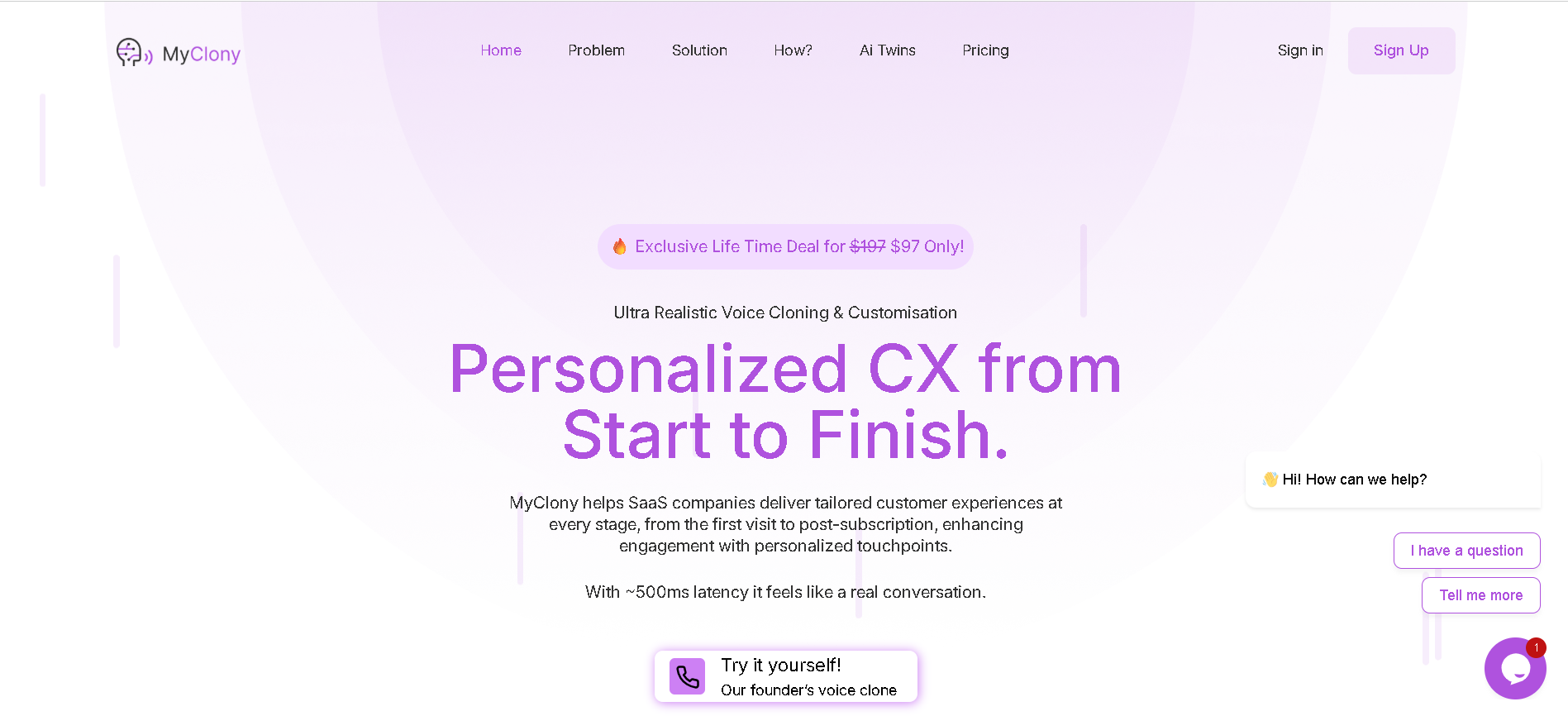
MyClony
Myclony is an AI-powered interactive voice cloning platform designed to enhance customer experience for SaaS companies. It creates personalized "Voice Twins" that provide real-time, human-like assistance, helping businesses to automate customer support and sales processes while fostering deeper emotional connections and trust.
MyClony
Myclony is an AI-powered interactive voice cloning platform designed to enhance customer experience for SaaS companies. It creates personalized "Voice Twins" that provide real-time, human-like assistance, helping businesses to automate customer support and sales processes while fostering deeper emotional connections and trust.
MyClony
Myclony is an AI-powered interactive voice cloning platform designed to enhance customer experience for SaaS companies. It creates personalized "Voice Twins" that provide real-time, human-like assistance, helping businesses to automate customer support and sales processes while fostering deeper emotional connections and trust.
PERSO.ai
Perso.ai is an AI-powered video localization platform that enables creators, educators, and businesses to produce high-quality, multilingual videos effortlessly. It offers features like voice cloning, lip-sync dubbing, and real-time script editing, making global content creation accessible to everyone.
PERSO.ai
Perso.ai is an AI-powered video localization platform that enables creators, educators, and businesses to produce high-quality, multilingual videos effortlessly. It offers features like voice cloning, lip-sync dubbing, and real-time script editing, making global content creation accessible to everyone.
PERSO.ai
Perso.ai is an AI-powered video localization platform that enables creators, educators, and businesses to produce high-quality, multilingual videos effortlessly. It offers features like voice cloning, lip-sync dubbing, and real-time script editing, making global content creation accessible to everyone.
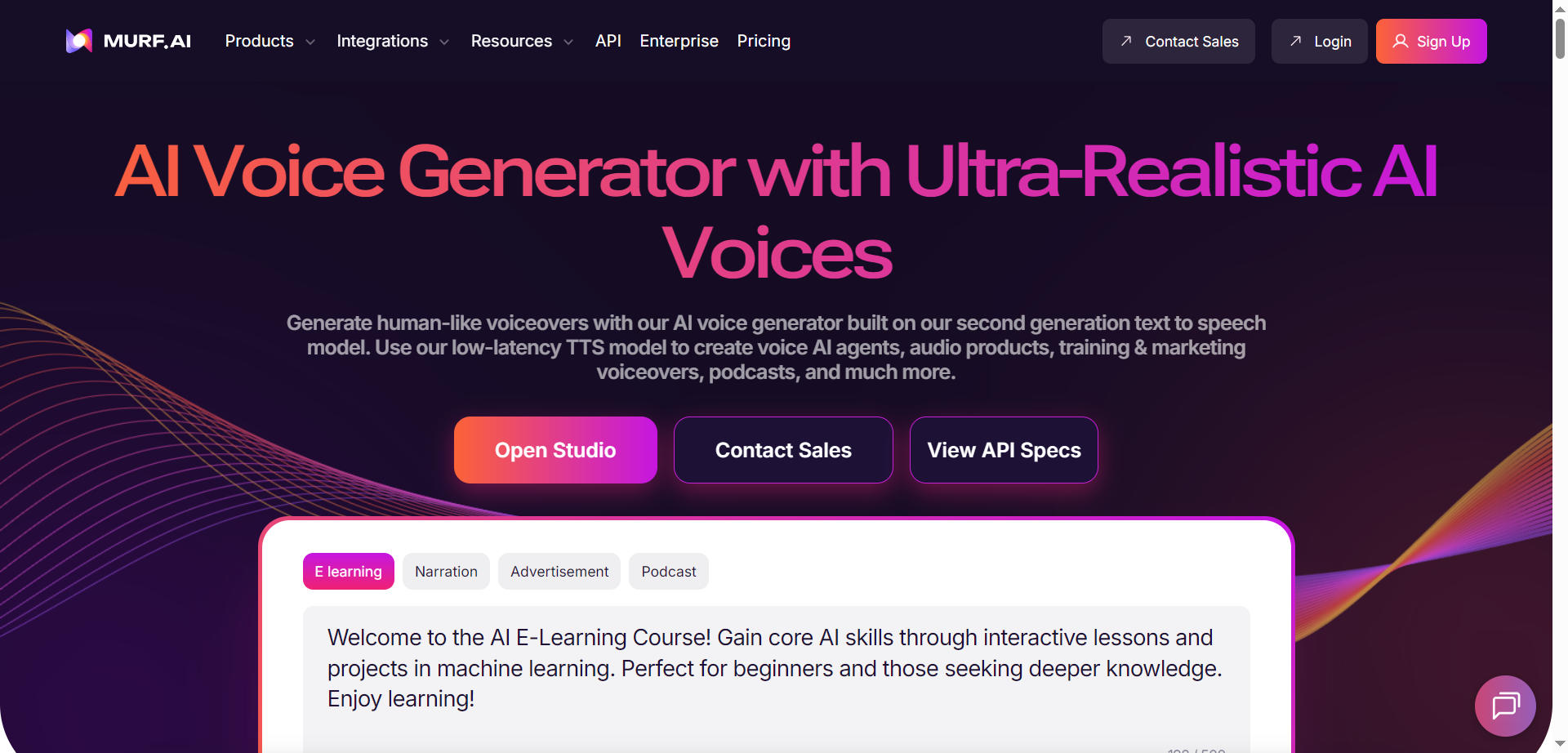

Murf.ai
Murf.ai is an AI voice generator and text-to-speech platform that delivers ultra-realistic voiceovers for creators, teams, and developers. It offers 200+ multilingual voices, 10+ speaking styles, and fine-grained controls over pitch, speed, tone, prosody, and pronunciation. A low-latency TTS model powers conversational agents with sub-200 ms response, while APIs enable voice cloning, voice changing, streaming TTS, and translation/dubbing in 30+ languages. A studio workspace supports scripting, timing, and rapid iteration for ads, training, audiobooks, podcasts, and product audio. Pronunciation libraries, team workspaces, and tool integrations help standardize brand voice at scale without complex audio engineering.
Murf.ai
Murf.ai is an AI voice generator and text-to-speech platform that delivers ultra-realistic voiceovers for creators, teams, and developers. It offers 200+ multilingual voices, 10+ speaking styles, and fine-grained controls over pitch, speed, tone, prosody, and pronunciation. A low-latency TTS model powers conversational agents with sub-200 ms response, while APIs enable voice cloning, voice changing, streaming TTS, and translation/dubbing in 30+ languages. A studio workspace supports scripting, timing, and rapid iteration for ads, training, audiobooks, podcasts, and product audio. Pronunciation libraries, team workspaces, and tool integrations help standardize brand voice at scale without complex audio engineering.
Murf.ai
Murf.ai is an AI voice generator and text-to-speech platform that delivers ultra-realistic voiceovers for creators, teams, and developers. It offers 200+ multilingual voices, 10+ speaking styles, and fine-grained controls over pitch, speed, tone, prosody, and pronunciation. A low-latency TTS model powers conversational agents with sub-200 ms response, while APIs enable voice cloning, voice changing, streaming TTS, and translation/dubbing in 30+ languages. A studio workspace supports scripting, timing, and rapid iteration for ads, training, audiobooks, podcasts, and product audio. Pronunciation libraries, team workspaces, and tool integrations help standardize brand voice at scale without complex audio engineering.

Resemble.AI
Resemble AI is an enterprise-focused Voice AI platform built on trust, offering realistic voice generation, voice cloning, and multi-modal deepfake detection across audio, image, and video. It provides real-time text-to-speech and speech-to-speech backed by advanced models like Chatterbox, plus watermarking for provenance and intelligence features for language, dialect, and anomaly detection. Teams can create branded, controllable voices, edit audio by typing, and deploy voice agents with developer-ready tooling. The platform also enables on-premises or private deployment for stricter compliance. With integrated security awareness training and automated monitoring, Resemble helps organizations scale voice experiences while defending against synthetic media risks.
Resemble.AI
Resemble AI is an enterprise-focused Voice AI platform built on trust, offering realistic voice generation, voice cloning, and multi-modal deepfake detection across audio, image, and video. It provides real-time text-to-speech and speech-to-speech backed by advanced models like Chatterbox, plus watermarking for provenance and intelligence features for language, dialect, and anomaly detection. Teams can create branded, controllable voices, edit audio by typing, and deploy voice agents with developer-ready tooling. The platform also enables on-premises or private deployment for stricter compliance. With integrated security awareness training and automated monitoring, Resemble helps organizations scale voice experiences while defending against synthetic media risks.
Resemble.AI
Resemble AI is an enterprise-focused Voice AI platform built on trust, offering realistic voice generation, voice cloning, and multi-modal deepfake detection across audio, image, and video. It provides real-time text-to-speech and speech-to-speech backed by advanced models like Chatterbox, plus watermarking for provenance and intelligence features for language, dialect, and anomaly detection. Teams can create branded, controllable voices, edit audio by typing, and deploy voice agents with developer-ready tooling. The platform also enables on-premises or private deployment for stricter compliance. With integrated security awareness training and automated monitoring, Resemble helps organizations scale voice experiences while defending against synthetic media risks.
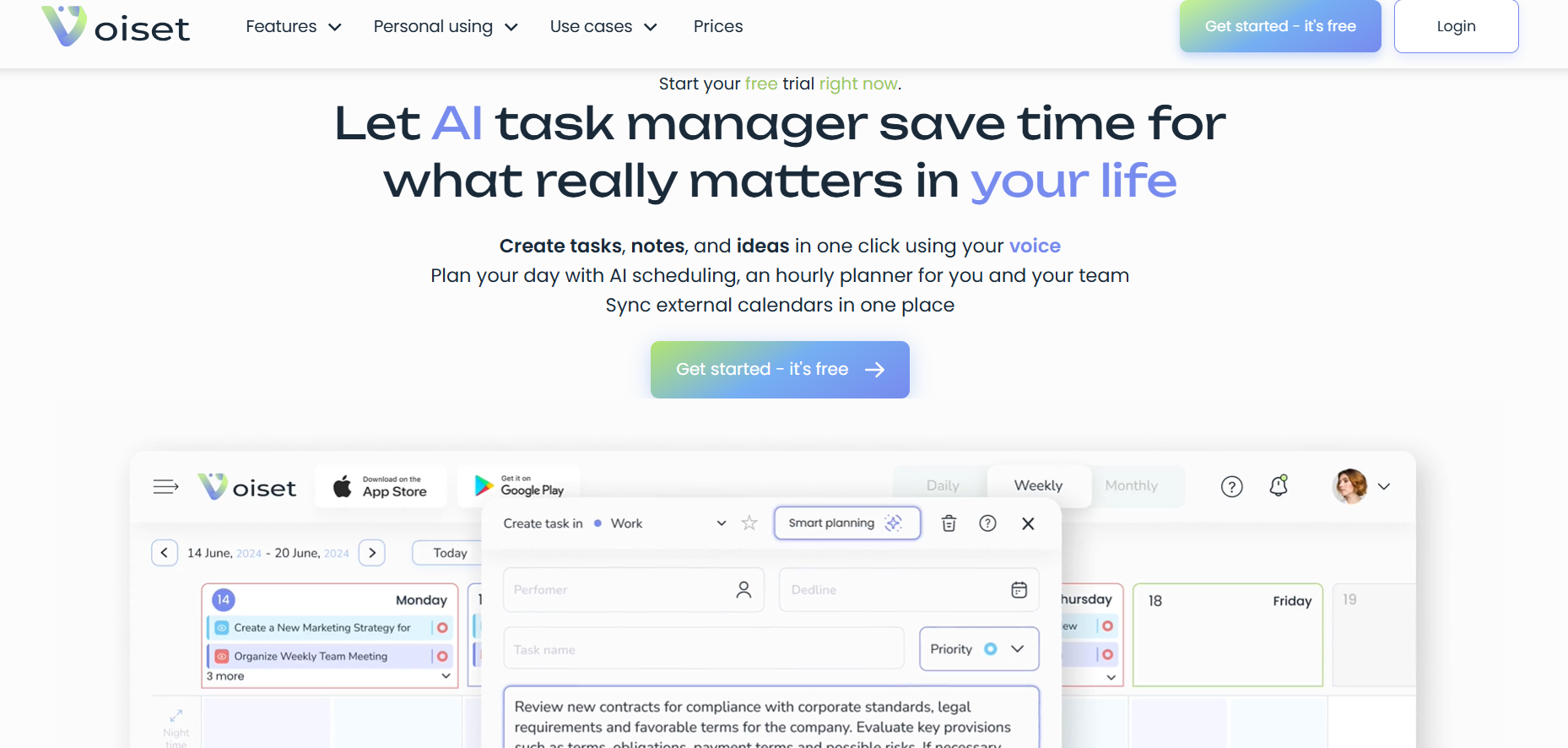
Voiset
Voiset is an AI-driven voice automation and conversational intelligence platform designed to enhance business communication, sales, and customer service. It allows teams to build intelligent voice agents that handle inbound and outbound calls, transcribe conversations, and provide real-time analytics. With advanced natural language processing, Voiset enables companies to automate communication tasks, reduce call handling time, and maintain personalized customer interactions. It integrates seamlessly with CRM tools and supports multiple languages, making it ideal for global teams and enterprises looking to scale voice operations.
Voiset
Voiset is an AI-driven voice automation and conversational intelligence platform designed to enhance business communication, sales, and customer service. It allows teams to build intelligent voice agents that handle inbound and outbound calls, transcribe conversations, and provide real-time analytics. With advanced natural language processing, Voiset enables companies to automate communication tasks, reduce call handling time, and maintain personalized customer interactions. It integrates seamlessly with CRM tools and supports multiple languages, making it ideal for global teams and enterprises looking to scale voice operations.
Voiset
Voiset is an AI-driven voice automation and conversational intelligence platform designed to enhance business communication, sales, and customer service. It allows teams to build intelligent voice agents that handle inbound and outbound calls, transcribe conversations, and provide real-time analytics. With advanced natural language processing, Voiset enables companies to automate communication tasks, reduce call handling time, and maintain personalized customer interactions. It integrates seamlessly with CRM tools and supports multiple languages, making it ideal for global teams and enterprises looking to scale voice operations.
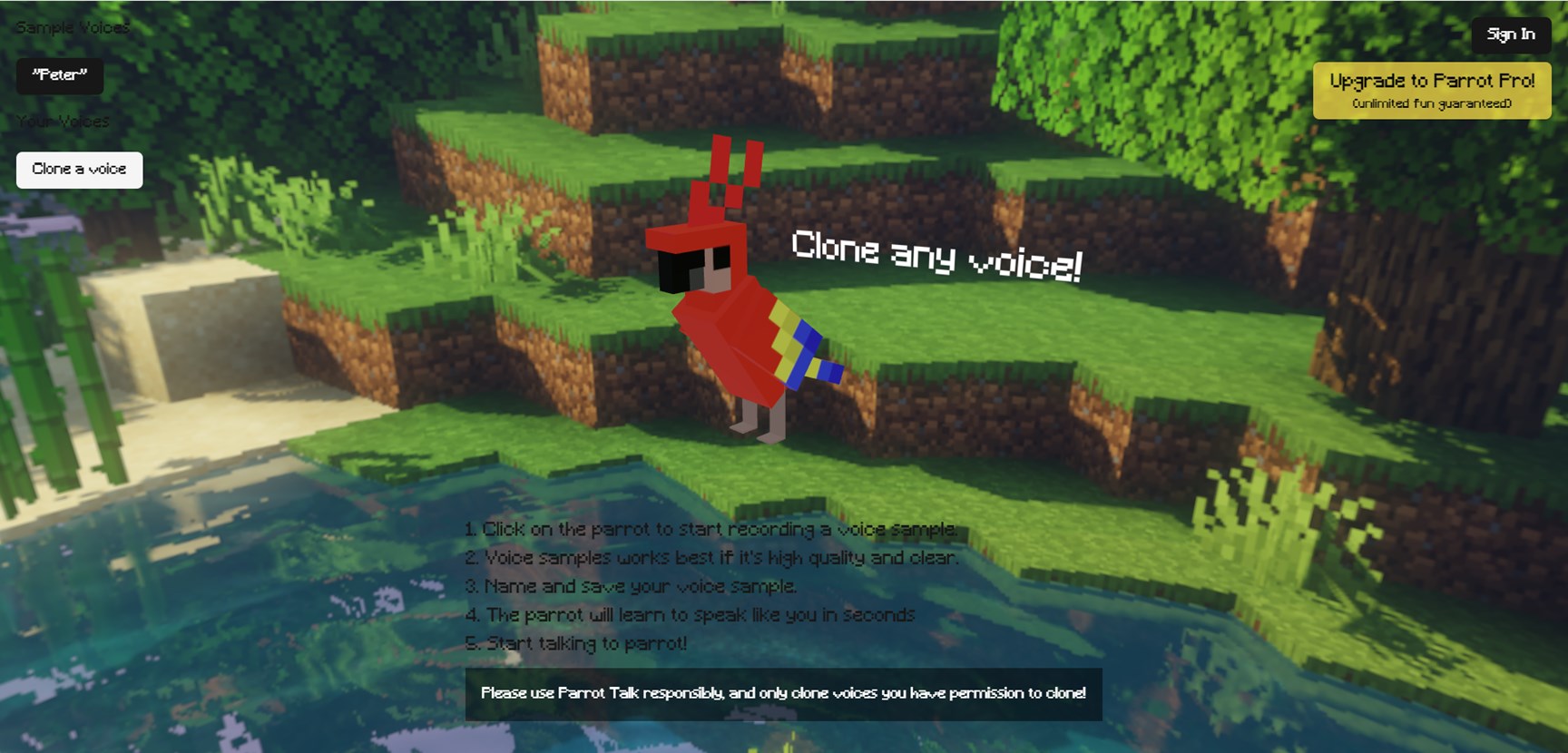

Parrot Talk
Parrottalk.ai is a cutting-edge voice cloning platform that lets users replicate any voice using just a single short audio recording. Upload a 10-second sample, and the AI generates realistic speech clones for podcasts, videos, audiobooks, or creative projects. It delivers high-fidelity results with natural intonation, accents, and timbre, making it ideal for content creators needing custom voices without expensive studios. The tool emphasizes ease-of-use with a simple web interface, quick processing times, and options for fine-tuning clones. Privacy-focused and accessible to beginners or pros, Parrottalk.ai transforms voiceovers, enabling personalized audio content at scale.
Parrot Talk
Parrottalk.ai is a cutting-edge voice cloning platform that lets users replicate any voice using just a single short audio recording. Upload a 10-second sample, and the AI generates realistic speech clones for podcasts, videos, audiobooks, or creative projects. It delivers high-fidelity results with natural intonation, accents, and timbre, making it ideal for content creators needing custom voices without expensive studios. The tool emphasizes ease-of-use with a simple web interface, quick processing times, and options for fine-tuning clones. Privacy-focused and accessible to beginners or pros, Parrottalk.ai transforms voiceovers, enabling personalized audio content at scale.
Parrot Talk
Parrottalk.ai is a cutting-edge voice cloning platform that lets users replicate any voice using just a single short audio recording. Upload a 10-second sample, and the AI generates realistic speech clones for podcasts, videos, audiobooks, or creative projects. It delivers high-fidelity results with natural intonation, accents, and timbre, making it ideal for content creators needing custom voices without expensive studios. The tool emphasizes ease-of-use with a simple web interface, quick processing times, and options for fine-tuning clones. Privacy-focused and accessible to beginners or pros, Parrottalk.ai transforms voiceovers, enabling personalized audio content at scale.
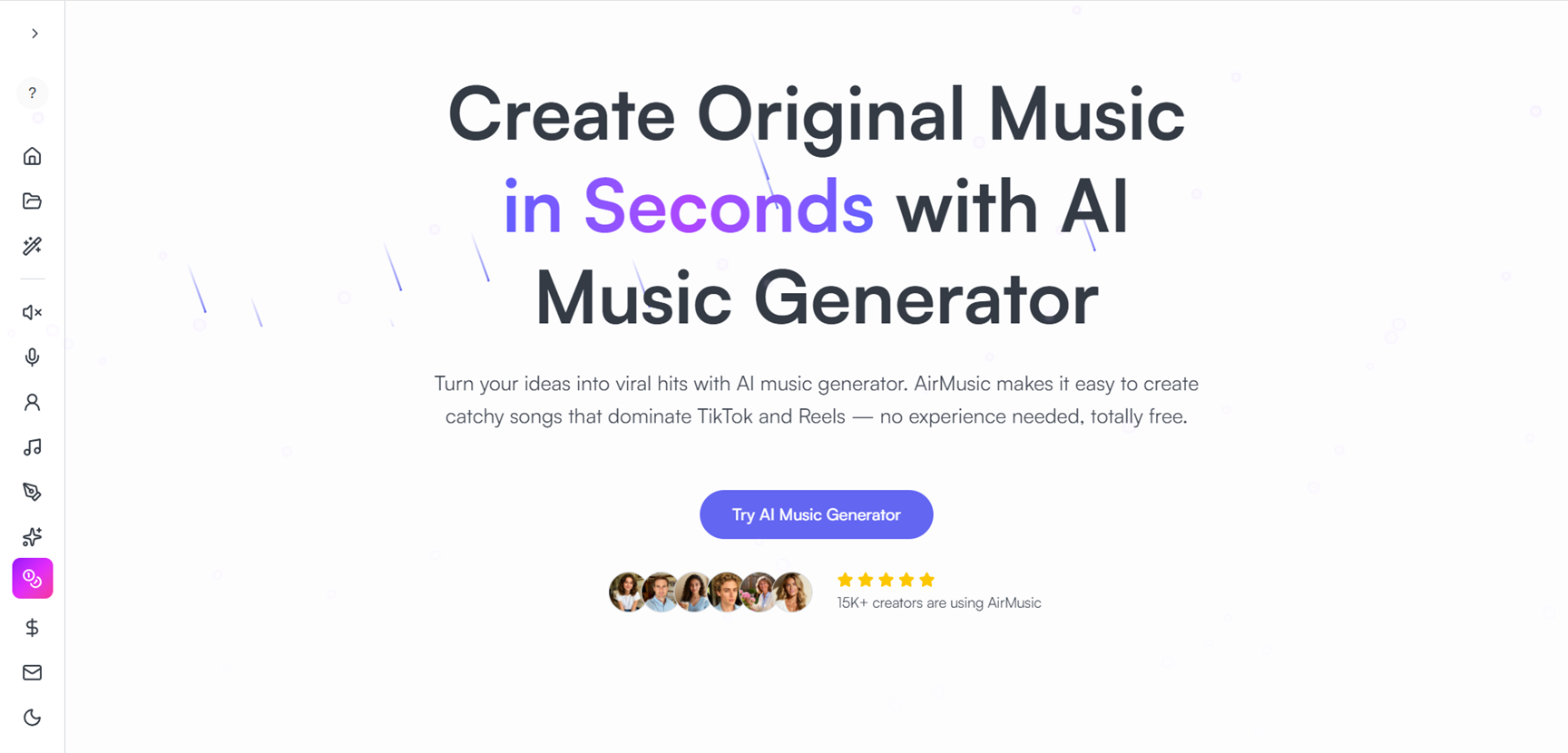

AirMusic
AirMusic is a comprehensive AI music generation platform that empowers creators to produce original, royalty-free tracks, covers, instrumentals, and remixes quickly and easily using advanced AI tools. With features like music extension, AI voice covers, vocal generation from lyrics, stem separation, voice cloning, and vocal removal, it supports full music production workflows from idea to final export in MP3 or WAV formats. Over 15K creators use it for TikTok, Reels, podcasts, and commercial projects, ensuring high-quality, customizable output without copyright concerns.
AirMusic
AirMusic is a comprehensive AI music generation platform that empowers creators to produce original, royalty-free tracks, covers, instrumentals, and remixes quickly and easily using advanced AI tools. With features like music extension, AI voice covers, vocal generation from lyrics, stem separation, voice cloning, and vocal removal, it supports full music production workflows from idea to final export in MP3 or WAV formats. Over 15K creators use it for TikTok, Reels, podcasts, and commercial projects, ensuring high-quality, customizable output without copyright concerns.
AirMusic
AirMusic is a comprehensive AI music generation platform that empowers creators to produce original, royalty-free tracks, covers, instrumentals, and remixes quickly and easily using advanced AI tools. With features like music extension, AI voice covers, vocal generation from lyrics, stem separation, voice cloning, and vocal removal, it supports full music production workflows from idea to final export in MP3 or WAV formats. Over 15K creators use it for TikTok, Reels, podcasts, and commercial projects, ensuring high-quality, customizable output without copyright concerns.
Editorial Note
This page was researched and written by the ATB Editorial Team. Our team researches each AI tool by reviewing its official website, testing features, exploring real use cases, and considering user feedback. Every page is fact-checked and regularly updated to ensure the information stays accurate, neutral, and useful for our readers.
If you have any suggestions or questions, email us at hello@aitoolbook.ai