- Researchers and Developers: Utilize Astra for AI-driven projects, machine learning advancements, and application development.
- Businesses and Enterprises: Implement Astra in customer service, automation, and data analysis to streamline operations.
- Educators and Students: Use Astra for research, learning assistance, and to advance AI education.
- General Users: Benefit from AI-powered assistance in daily tasks, smart device interactions, and efficient information retrieval.
- Real-Time Multimodal AI: Processes text, speech, and visual data simultaneously and in real-time, allowing for highly intelligent and natural interactions.
- Context-Aware Assistance: Understands and retains context over time, enabling it to provide more accurate, relevant, and personalized responses.
- Instant and Interactive: Delivers rapid responses, making it highly efficient for real-time conversations and dynamic problem-solving.
- Seamless Device Integration: Works across multiple platforms and form factors, including mobile phones, smart glasses, and other AI-enabled wearable devices.
- AI-Powered Vision: Possesses the ability to recognize objects, understand environments, and interpret visual cues, enhancing user experiences through visual understanding.
- Fast and intelligent responses across different media.
- Contextual awareness improves AI interactions.
- Works seamlessly across multiple devices.
- Real-time vision and object recognition capabilities.
- Expands possibilities for AI-driven personal assistants.
- Still in development, so features may evolve.
- Potential privacy concerns with AI-driven data processing.
- Requires strong computational power for optimal performance.
Paid
Custom
Proud of the love you're getting? Show off your AI Toolbook reviews—then invite more fans to share the love and build your credibility.
Add an AI Toolbook badge to your site—an easy way to drive followers, showcase updates, and collect reviews. It's like a mini 24/7 billboard for your AI.
Reviews
Rating Distribution
Average score
Popular Mention
FAQs
Similar AI Tools
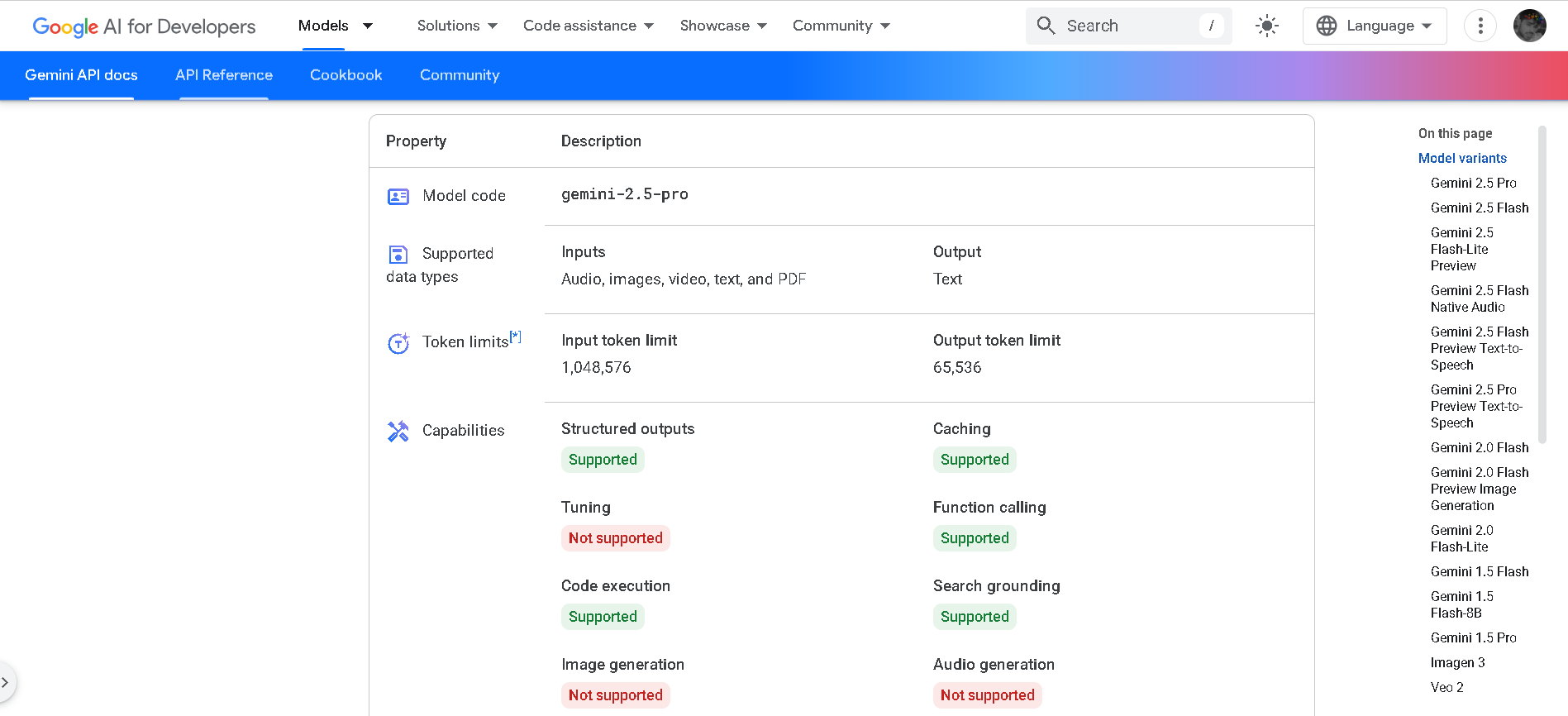

Gemini 2.5 Pro
Gemini 2.5 Pro is Google DeepMind’s advanced hybrid-reasoning AI model, designed to think deeply before responding. With support for multimodal inputs—text, images, audio, video, and code—it offers lightning-fast inference performance, up to 2 million tokens of context, and top-tier results in math, science, and coding benchmarks.
Gemini 2.5 Pro
Gemini 2.5 Pro is Google DeepMind’s advanced hybrid-reasoning AI model, designed to think deeply before responding. With support for multimodal inputs—text, images, audio, video, and code—it offers lightning-fast inference performance, up to 2 million tokens of context, and top-tier results in math, science, and coding benchmarks.
Gemini 2.5 Pro
Gemini 2.5 Pro is Google DeepMind’s advanced hybrid-reasoning AI model, designed to think deeply before responding. With support for multimodal inputs—text, images, audio, video, and code—it offers lightning-fast inference performance, up to 2 million tokens of context, and top-tier results in math, science, and coding benchmarks.
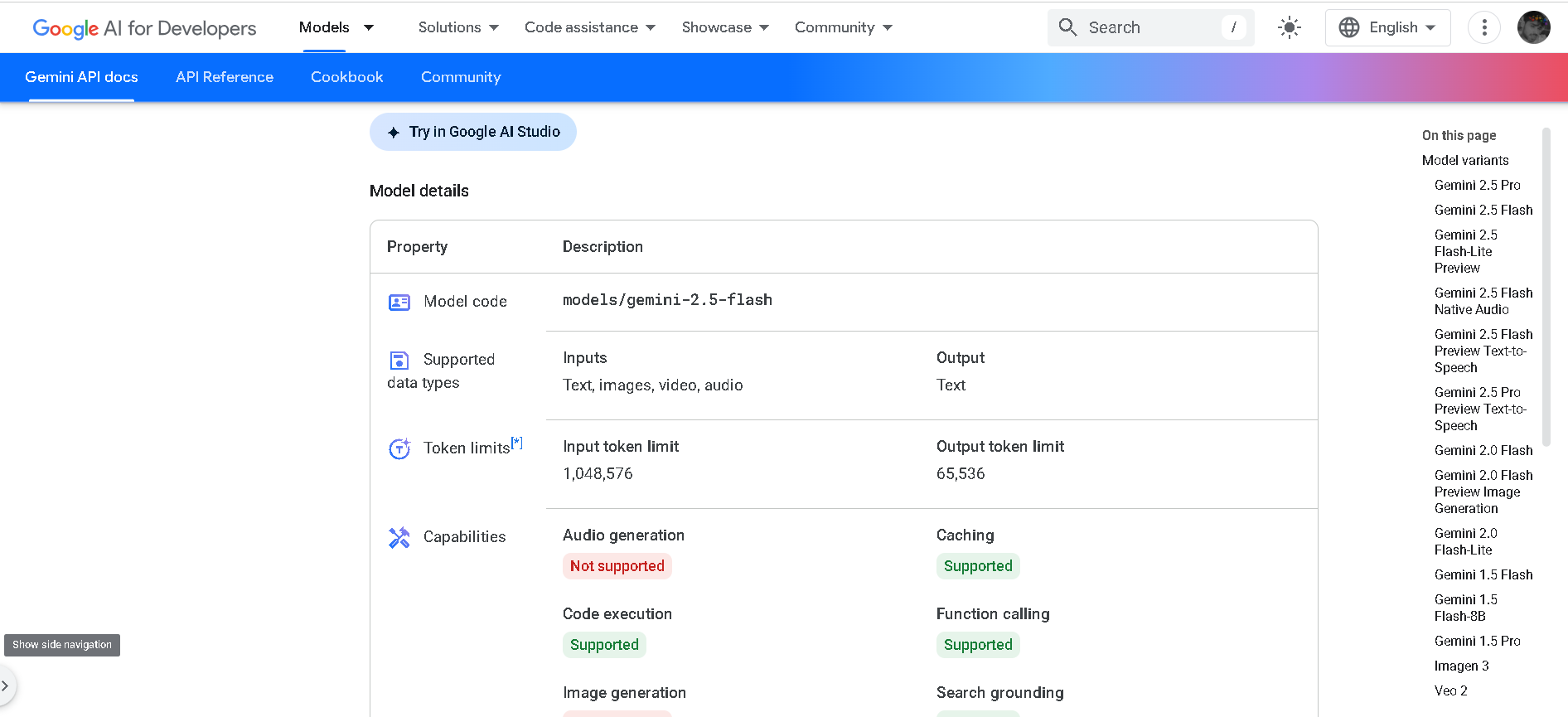

Gemini 2.5 Flash
Gemini 2.5 Flash is Google DeepMind’s cost-efficient, low-latency hybrid-reasoning model. Designed for large-scale, real-time tasks that require thinking—like classification, translation, conversational AI, and agent behaviors—it supports text, image, audio, and video input, and offers developer control over its reasoning depth. It balances high speed with strong multimodal intelligence.
Gemini 2.5 Flash
Gemini 2.5 Flash is Google DeepMind’s cost-efficient, low-latency hybrid-reasoning model. Designed for large-scale, real-time tasks that require thinking—like classification, translation, conversational AI, and agent behaviors—it supports text, image, audio, and video input, and offers developer control over its reasoning depth. It balances high speed with strong multimodal intelligence.
Gemini 2.5 Flash
Gemini 2.5 Flash is Google DeepMind’s cost-efficient, low-latency hybrid-reasoning model. Designed for large-scale, real-time tasks that require thinking—like classification, translation, conversational AI, and agent behaviors—it supports text, image, audio, and video input, and offers developer control over its reasoning depth. It balances high speed with strong multimodal intelligence.
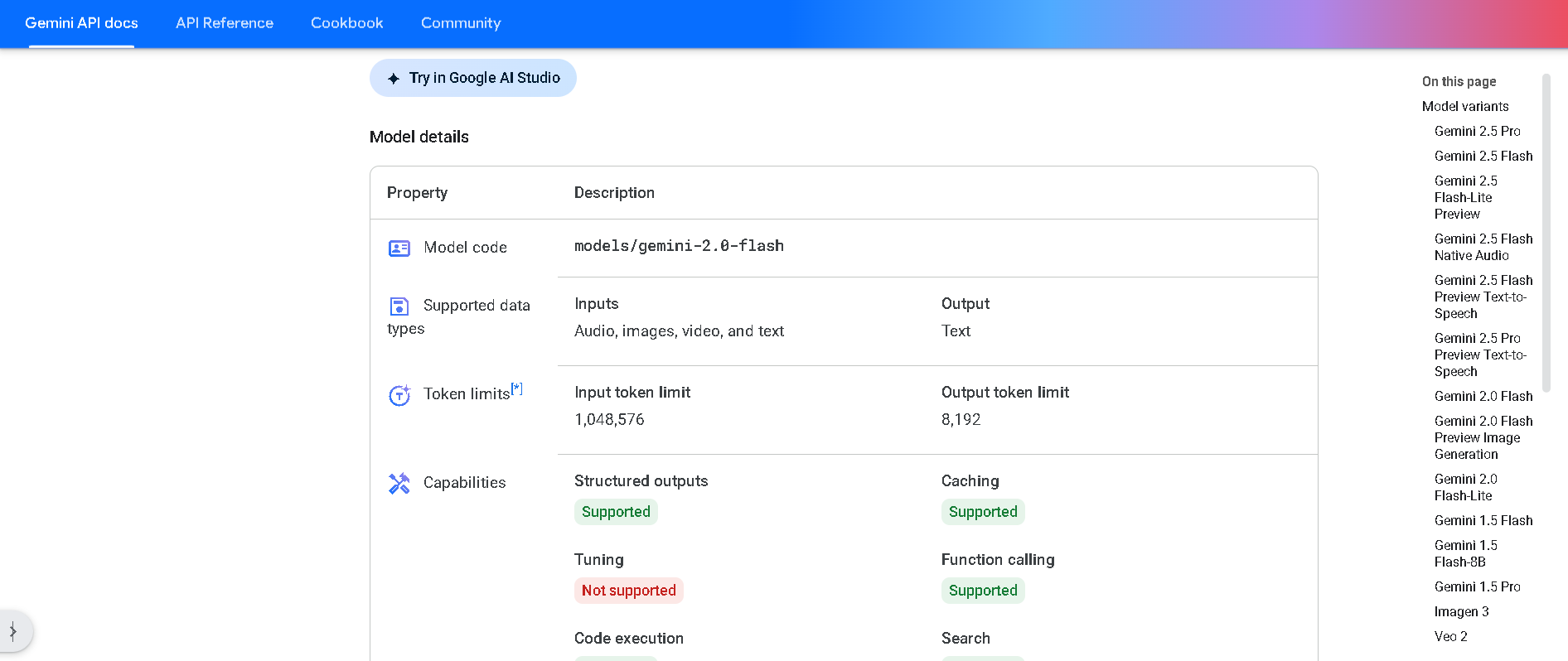

Gemini 2.0 Flash
Gemini 2.0 Flash is Google DeepMind’s next-gen workhorse model designed for real-time, multimodal reasoning. It delivers twice the speed of the previous Pro-tier model with support for text, image, video, and audio inputs. Flash also outputs native images and steerable text-to-speech audio, and can call tools such as search, code execution, and third-party functions—all within a massive 1 million token context window.
Gemini 2.0 Flash
Gemini 2.0 Flash is Google DeepMind’s next-gen workhorse model designed for real-time, multimodal reasoning. It delivers twice the speed of the previous Pro-tier model with support for text, image, video, and audio inputs. Flash also outputs native images and steerable text-to-speech audio, and can call tools such as search, code execution, and third-party functions—all within a massive 1 million token context window.
Gemini 2.0 Flash
Gemini 2.0 Flash is Google DeepMind’s next-gen workhorse model designed for real-time, multimodal reasoning. It delivers twice the speed of the previous Pro-tier model with support for text, image, video, and audio inputs. Flash also outputs native images and steerable text-to-speech audio, and can call tools such as search, code execution, and third-party functions—all within a massive 1 million token context window.
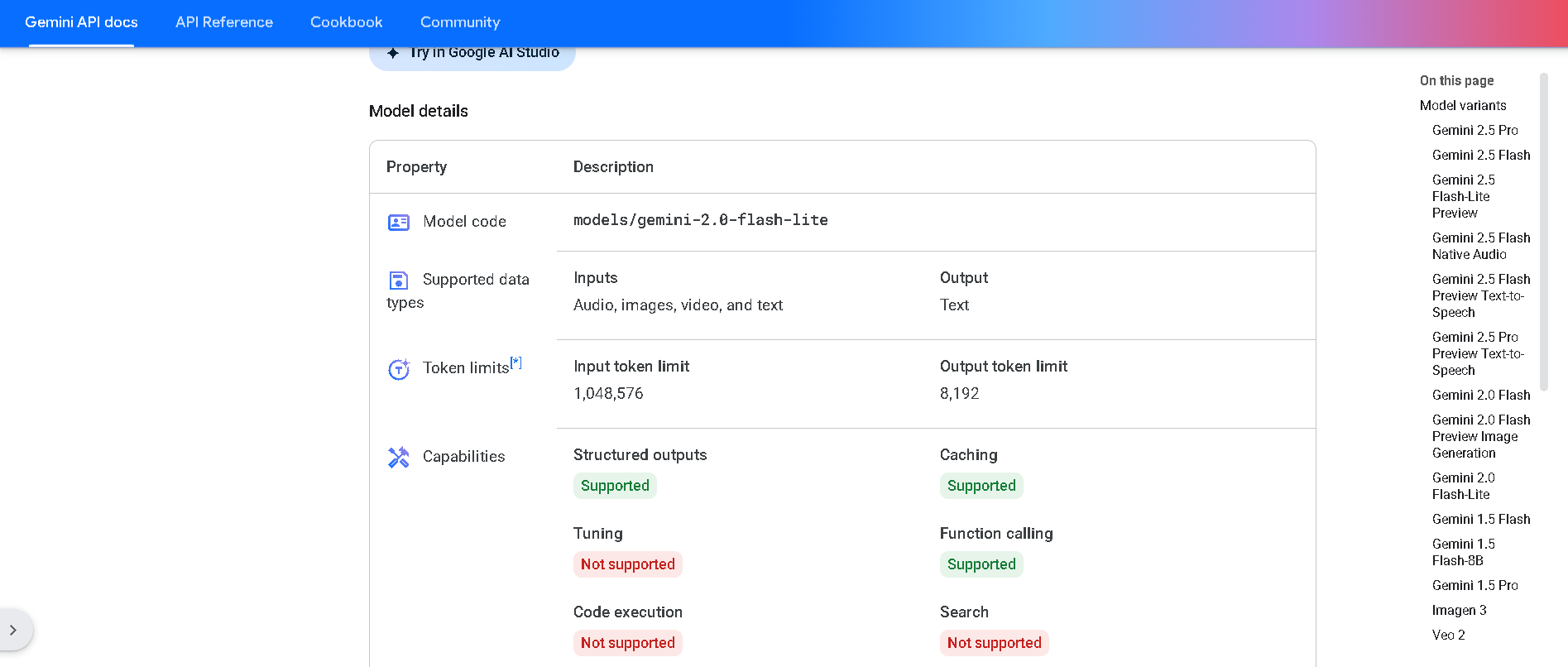
Gemini 2.0 Flash‑Lite is Google DeepMind’s most cost-efficient, low-latency variant of the Gemini 2.0 Flash model, now publicly available in preview. It delivers fast, multimodal reasoning across text, image, audio, and video inputs, supports native tool use, and processes up to a 1 million token context window—all while keeping latency and cost exceptionally low .
Gemini 2.0 Flash‑Lite is Google DeepMind’s most cost-efficient, low-latency variant of the Gemini 2.0 Flash model, now publicly available in preview. It delivers fast, multimodal reasoning across text, image, audio, and video inputs, supports native tool use, and processes up to a 1 million token context window—all while keeping latency and cost exceptionally low .
Gemini 2.0 Flash‑Lite is Google DeepMind’s most cost-efficient, low-latency variant of the Gemini 2.0 Flash model, now publicly available in preview. It delivers fast, multimodal reasoning across text, image, audio, and video inputs, supports native tool use, and processes up to a 1 million token context window—all while keeping latency and cost exceptionally low .
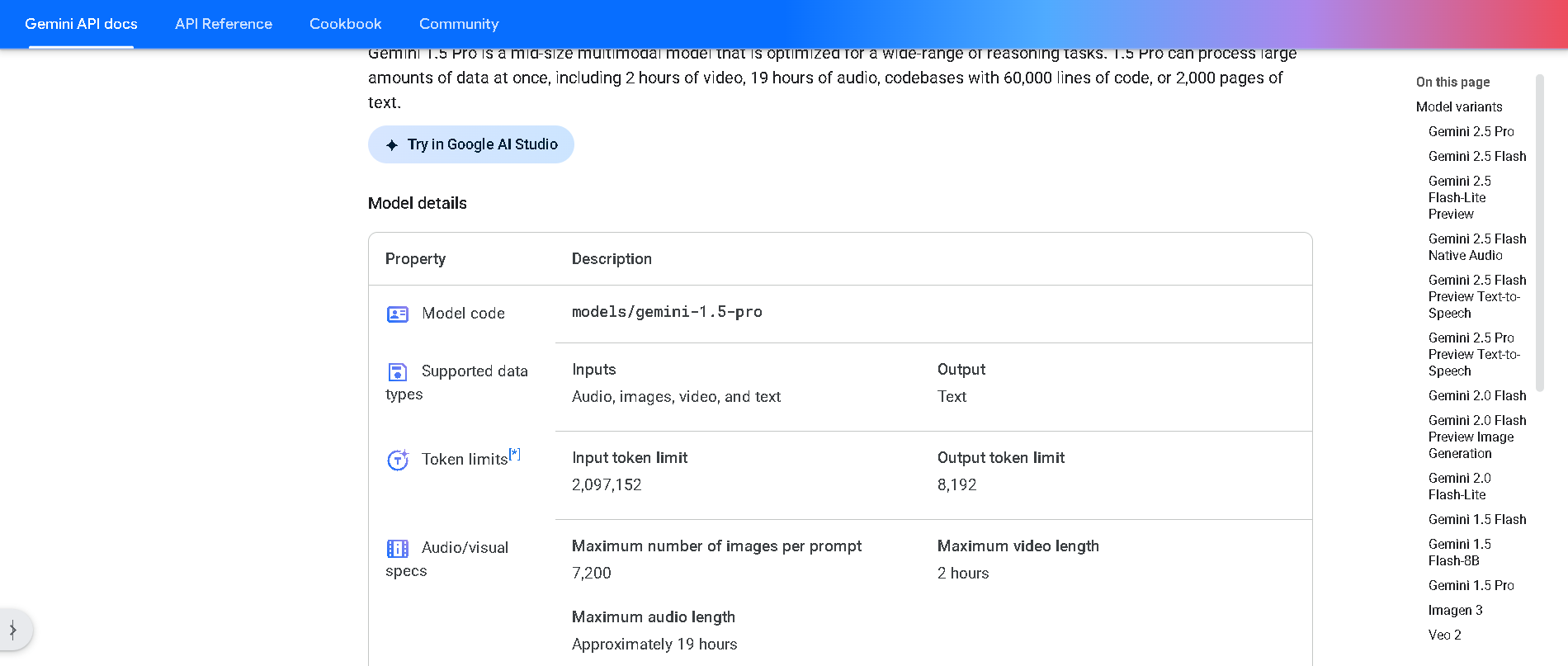

Gemini 1.5 Pro
Gemini 1.5 Pro is Google DeepMind’s mid-size multimodal model, using a mixture-of-experts (MoE) architecture to deliver high performance with lower compute. It supports text, images, audio, video, and code, and features an experimental context window up to 1 million tokens—the longest among widely available models. It excels in long-document reasoning, multimodal understanding, and in-context learning.
Gemini 1.5 Pro
Gemini 1.5 Pro is Google DeepMind’s mid-size multimodal model, using a mixture-of-experts (MoE) architecture to deliver high performance with lower compute. It supports text, images, audio, video, and code, and features an experimental context window up to 1 million tokens—the longest among widely available models. It excels in long-document reasoning, multimodal understanding, and in-context learning.
Gemini 1.5 Pro
Gemini 1.5 Pro is Google DeepMind’s mid-size multimodal model, using a mixture-of-experts (MoE) architecture to deliver high performance with lower compute. It supports text, images, audio, video, and code, and features an experimental context window up to 1 million tokens—the longest among widely available models. It excels in long-document reasoning, multimodal understanding, and in-context learning.

Reka
Reka is an AI research and product company specializing in multimodal AI systems. Founded by former DeepMind and Meta FAIR scientists, Reka develops advanced AI models and applications that integrate text, images, audio, and video inputs. The company focuses on creating efficient, scalable, and deployable AI solutions for enterprises and developers.
Reka
Reka is an AI research and product company specializing in multimodal AI systems. Founded by former DeepMind and Meta FAIR scientists, Reka develops advanced AI models and applications that integrate text, images, audio, and video inputs. The company focuses on creating efficient, scalable, and deployable AI solutions for enterprises and developers.
Reka
Reka is an AI research and product company specializing in multimodal AI systems. Founded by former DeepMind and Meta FAIR scientists, Reka develops advanced AI models and applications that integrate text, images, audio, and video inputs. The company focuses on creating efficient, scalable, and deployable AI solutions for enterprises and developers.
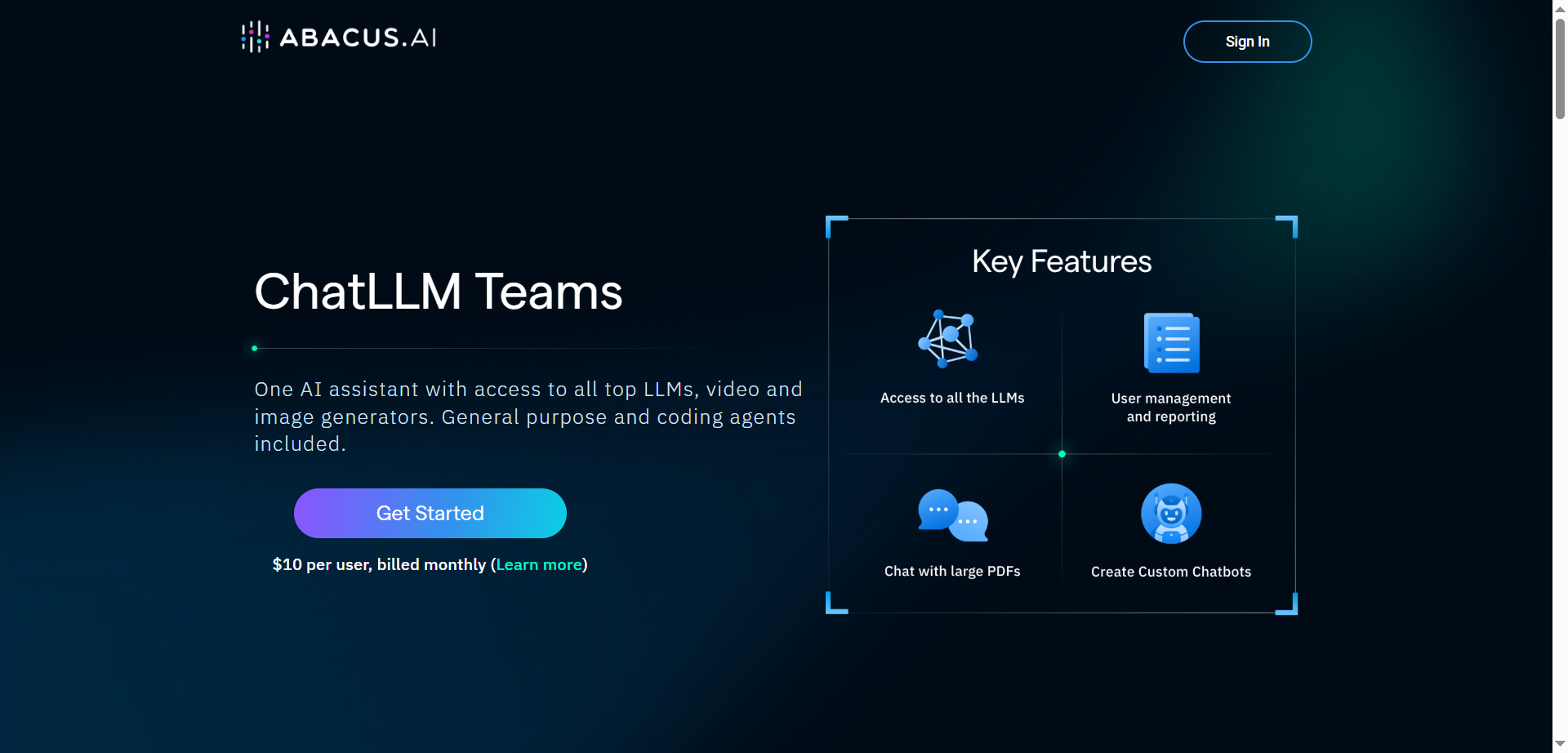

Abacus.AI
ChatLLM Teams by Abacus.AI is an all‑in‑one AI assistant that unifies access to top LLMs, image and video generators, and powerful agentic tools in a single workspace. It includes DeepAgent for complex, multi‑step tasks, code execution with an editor, document/chat with files, web search, TTS, and slide/doc generation. Users can build custom chatbots, set up AI workflows, generate images and videos from multiple models, and organize work with projects across desktop and mobile apps. The platform is OpenAI‑style in usability but adds operator features for running tasks on a computer, plus DeepAgent Desktop and AppLLM for building and hosting small apps.
Abacus.AI
ChatLLM Teams by Abacus.AI is an all‑in‑one AI assistant that unifies access to top LLMs, image and video generators, and powerful agentic tools in a single workspace. It includes DeepAgent for complex, multi‑step tasks, code execution with an editor, document/chat with files, web search, TTS, and slide/doc generation. Users can build custom chatbots, set up AI workflows, generate images and videos from multiple models, and organize work with projects across desktop and mobile apps. The platform is OpenAI‑style in usability but adds operator features for running tasks on a computer, plus DeepAgent Desktop and AppLLM for building and hosting small apps.
Abacus.AI
ChatLLM Teams by Abacus.AI is an all‑in‑one AI assistant that unifies access to top LLMs, image and video generators, and powerful agentic tools in a single workspace. It includes DeepAgent for complex, multi‑step tasks, code execution with an editor, document/chat with files, web search, TTS, and slide/doc generation. Users can build custom chatbots, set up AI workflows, generate images and videos from multiple models, and organize work with projects across desktop and mobile apps. The platform is OpenAI‑style in usability but adds operator features for running tasks on a computer, plus DeepAgent Desktop and AppLLM for building and hosting small apps.

Typing Mind
TypingMind is a powerful frontend for large language models, giving users a clean, customizable interface to interact with AI more efficiently. It enhances the user experience by offering advanced features such as conversation organization, prompt management, model switching, and private local usage options. TypingMind provides a more flexible and user-friendly environment than standard AI chat interfaces, allowing users to optimize workflows, manage sessions, and personalize interactions. It is built for individuals and teams who want full control over how they use LLMs without relying on default chat UIs.
Typing Mind
TypingMind is a powerful frontend for large language models, giving users a clean, customizable interface to interact with AI more efficiently. It enhances the user experience by offering advanced features such as conversation organization, prompt management, model switching, and private local usage options. TypingMind provides a more flexible and user-friendly environment than standard AI chat interfaces, allowing users to optimize workflows, manage sessions, and personalize interactions. It is built for individuals and teams who want full control over how they use LLMs without relying on default chat UIs.
Typing Mind
TypingMind is a powerful frontend for large language models, giving users a clean, customizable interface to interact with AI more efficiently. It enhances the user experience by offering advanced features such as conversation organization, prompt management, model switching, and private local usage options. TypingMind provides a more flexible and user-friendly environment than standard AI chat interfaces, allowing users to optimize workflows, manage sessions, and personalize interactions. It is built for individuals and teams who want full control over how they use LLMs without relying on default chat UIs.
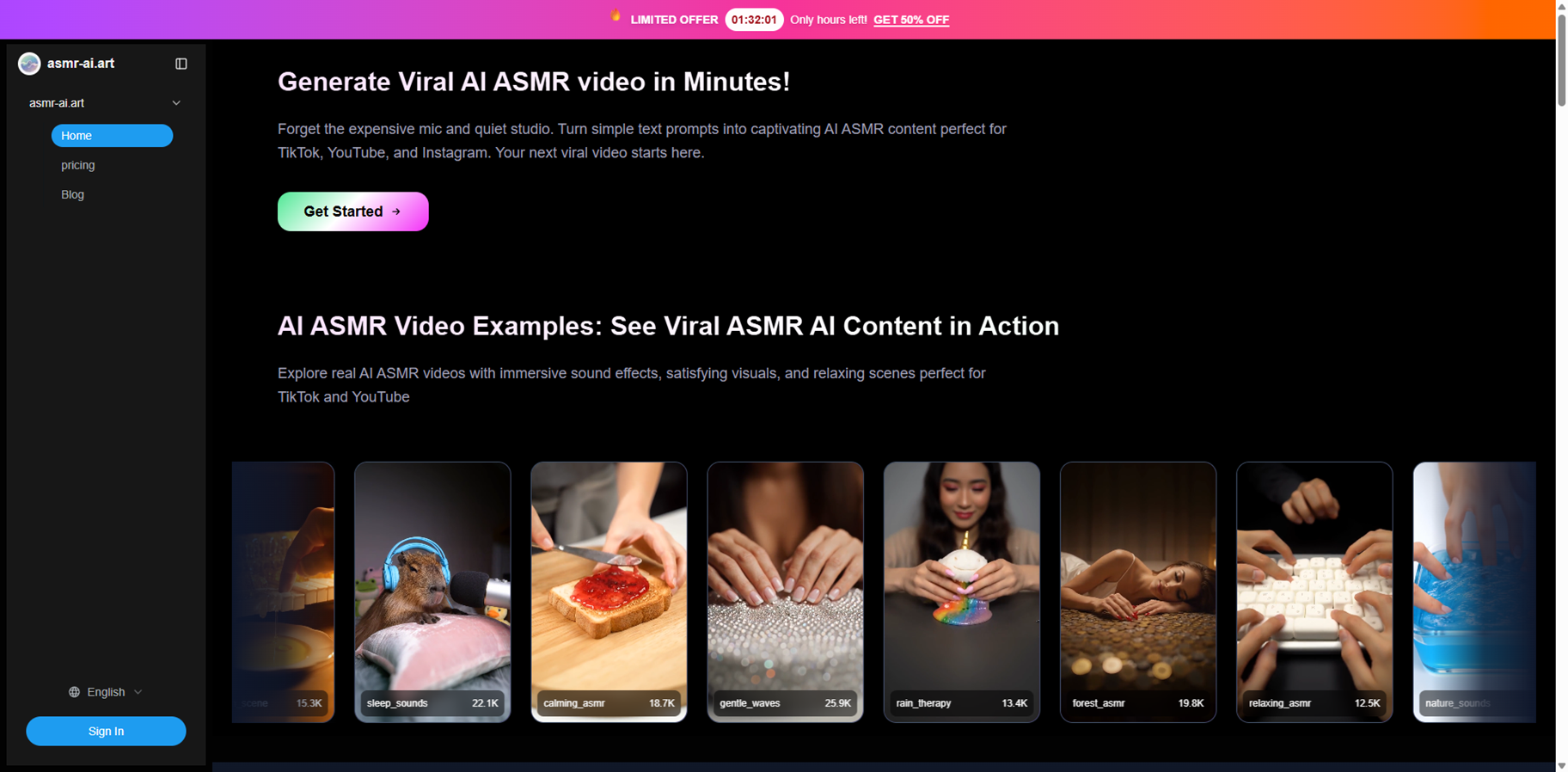
ASMR-AI.art
ASMR-AI.art is an AI-powered ASMR video generator that lets you create relaxing, satisfying clips with synchronized sound and visuals in just a few minutes, without mics or a studio. Powered by Google Veo 3.1, it turns text prompts or reference images into cinematic AI videos with native ASMR audio, tapping, whispers, ambient sounds, perfectly matched to on-screen actions. You can control aspect ratio, quality mode, and even extend clips beyond 8 seconds for longer content. The platform is built for TikTok, Instagram Reels, YouTube, sleep apps, and wellness brands, with permanent downloads and commercial usage rights included.
ASMR-AI.art
ASMR-AI.art is an AI-powered ASMR video generator that lets you create relaxing, satisfying clips with synchronized sound and visuals in just a few minutes, without mics or a studio. Powered by Google Veo 3.1, it turns text prompts or reference images into cinematic AI videos with native ASMR audio, tapping, whispers, ambient sounds, perfectly matched to on-screen actions. You can control aspect ratio, quality mode, and even extend clips beyond 8 seconds for longer content. The platform is built for TikTok, Instagram Reels, YouTube, sleep apps, and wellness brands, with permanent downloads and commercial usage rights included.
ASMR-AI.art
ASMR-AI.art is an AI-powered ASMR video generator that lets you create relaxing, satisfying clips with synchronized sound and visuals in just a few minutes, without mics or a studio. Powered by Google Veo 3.1, it turns text prompts or reference images into cinematic AI videos with native ASMR audio, tapping, whispers, ambient sounds, perfectly matched to on-screen actions. You can control aspect ratio, quality mode, and even extend clips beyond 8 seconds for longer content. The platform is built for TikTok, Instagram Reels, YouTube, sleep apps, and wellness brands, with permanent downloads and commercial usage rights included.
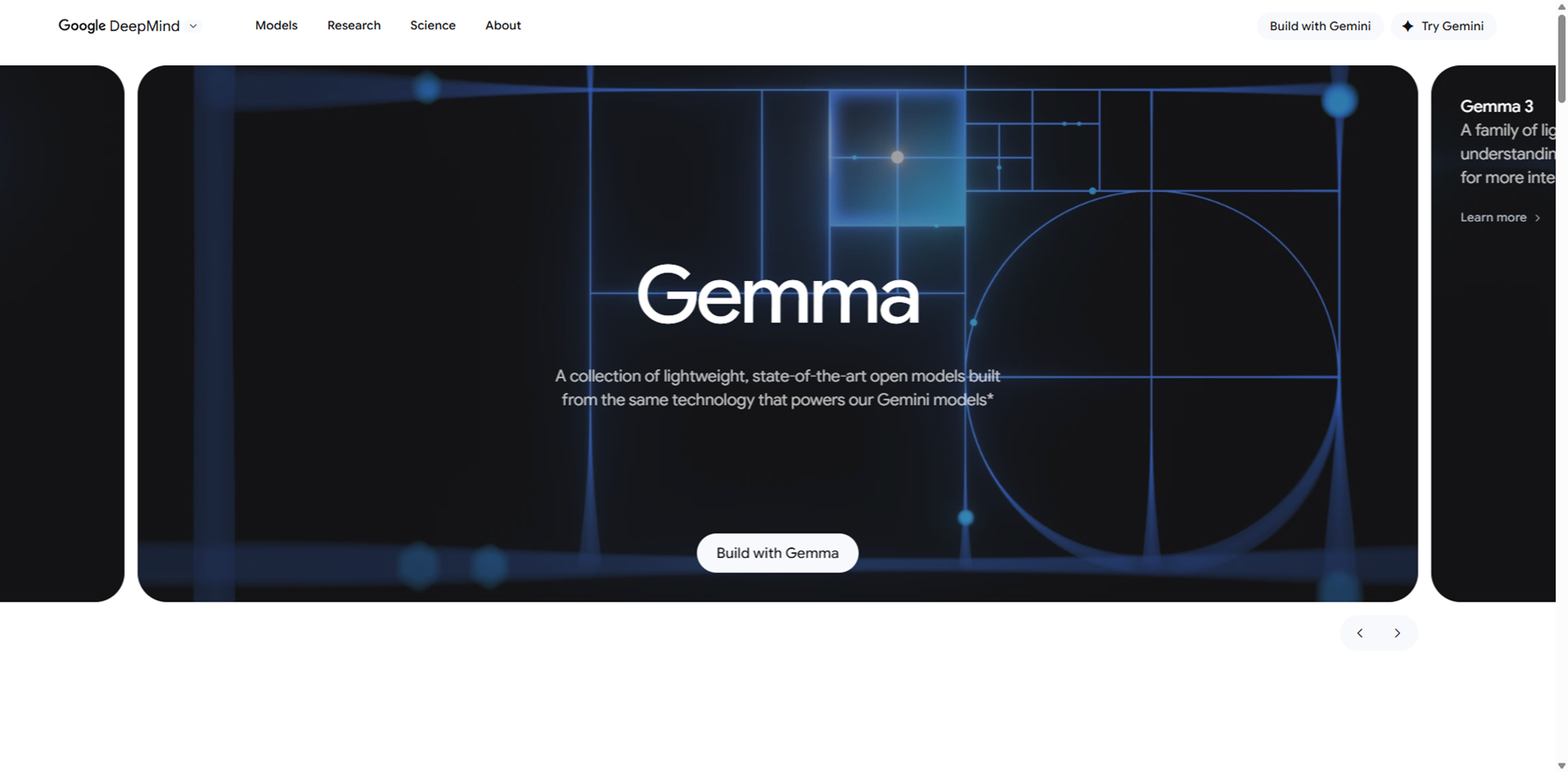

Gemma
Gemma is a family of lightweight, state-of-the-art open models from Google DeepMind, built using the same research and technology that powers the Gemini models. Available in sizes from 270M to 27B parameters, they support multimodal understanding with text, image, video, and audio inputs while generating text outputs, alongside strong multilingual capabilities across over 140 languages. Specialized variants like CodeGemma for coding, PaliGemma for vision-language tasks, ShieldGemma for safety classification, MedGemma for medical imaging and text, and mobile-optimized Gemma 3n enable developers to create efficient AI apps that run on devices from phones to servers. These models excel in tasks like summarization, question answering, reasoning, code generation, and translation, with tools for fine-tuning and deployment.
Gemma
Gemma is a family of lightweight, state-of-the-art open models from Google DeepMind, built using the same research and technology that powers the Gemini models. Available in sizes from 270M to 27B parameters, they support multimodal understanding with text, image, video, and audio inputs while generating text outputs, alongside strong multilingual capabilities across over 140 languages. Specialized variants like CodeGemma for coding, PaliGemma for vision-language tasks, ShieldGemma for safety classification, MedGemma for medical imaging and text, and mobile-optimized Gemma 3n enable developers to create efficient AI apps that run on devices from phones to servers. These models excel in tasks like summarization, question answering, reasoning, code generation, and translation, with tools for fine-tuning and deployment.
Gemma
Gemma is a family of lightweight, state-of-the-art open models from Google DeepMind, built using the same research and technology that powers the Gemini models. Available in sizes from 270M to 27B parameters, they support multimodal understanding with text, image, video, and audio inputs while generating text outputs, alongside strong multilingual capabilities across over 140 languages. Specialized variants like CodeGemma for coding, PaliGemma for vision-language tasks, ShieldGemma for safety classification, MedGemma for medical imaging and text, and mobile-optimized Gemma 3n enable developers to create efficient AI apps that run on devices from phones to servers. These models excel in tasks like summarization, question answering, reasoning, code generation, and translation, with tools for fine-tuning and deployment.
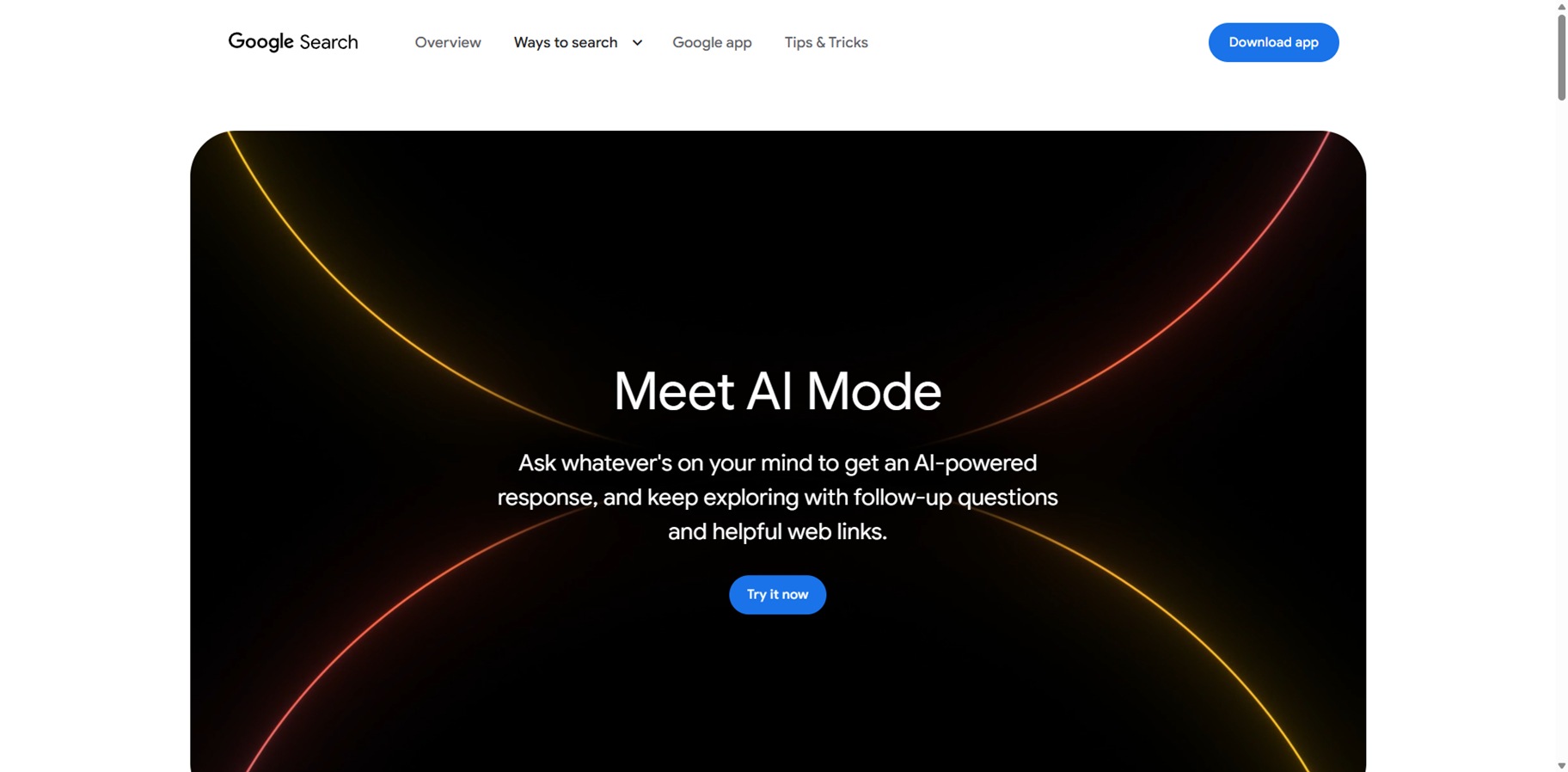

Google AI Mode
Google AI Mode is Google's most advanced generative AI search experience, powered by the Gemini model, designed to handle complex queries with deeper reasoning and multimodal inputs like text, voice, images, or photos. It breaks down your question into subtopics, fans out multiple searches across the web simultaneously, and synthesizes comprehensive, cited responses with links to high-quality sources for further exploration. Unlike traditional search results, it offers conversational follow-ups, personalized context from past interactions, and tools like Deep Search for thorough reports, making research intuitive and efficient for everything from product comparisons to in-depth topic dives. Available via google.com/ai, the Search bar, or the Google app, it's rolling out widely including in India.
Google AI Mode
Google AI Mode is Google's most advanced generative AI search experience, powered by the Gemini model, designed to handle complex queries with deeper reasoning and multimodal inputs like text, voice, images, or photos. It breaks down your question into subtopics, fans out multiple searches across the web simultaneously, and synthesizes comprehensive, cited responses with links to high-quality sources for further exploration. Unlike traditional search results, it offers conversational follow-ups, personalized context from past interactions, and tools like Deep Search for thorough reports, making research intuitive and efficient for everything from product comparisons to in-depth topic dives. Available via google.com/ai, the Search bar, or the Google app, it's rolling out widely including in India.
Google AI Mode
Google AI Mode is Google's most advanced generative AI search experience, powered by the Gemini model, designed to handle complex queries with deeper reasoning and multimodal inputs like text, voice, images, or photos. It breaks down your question into subtopics, fans out multiple searches across the web simultaneously, and synthesizes comprehensive, cited responses with links to high-quality sources for further exploration. Unlike traditional search results, it offers conversational follow-ups, personalized context from past interactions, and tools like Deep Search for thorough reports, making research intuitive and efficient for everything from product comparisons to in-depth topic dives. Available via google.com/ai, the Search bar, or the Google app, it's rolling out widely including in India.
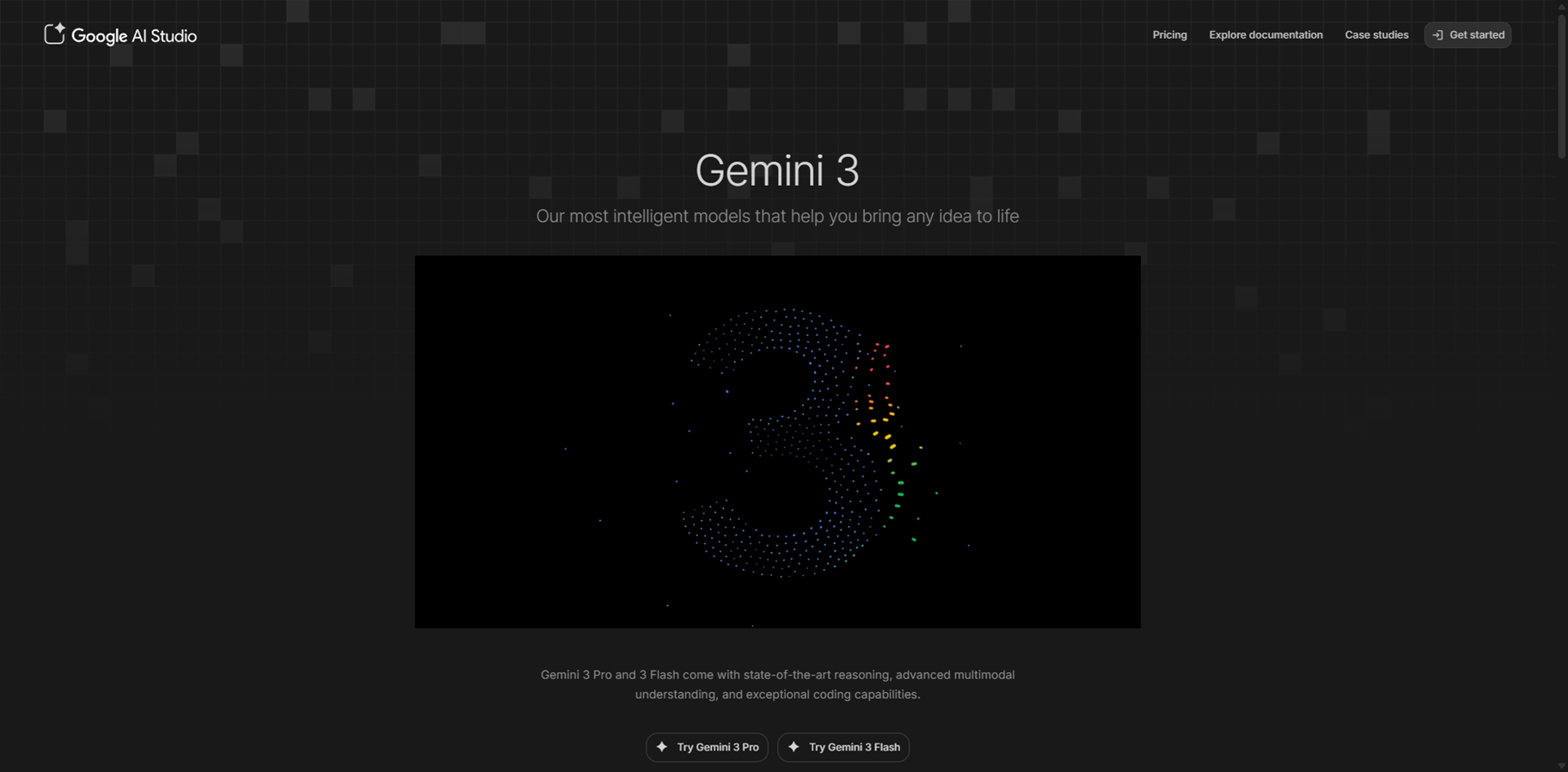

Gemini 3
Gemini 3 is Google's most advanced AI model family, including Gemini 3 Pro and Gemini 3 Flash, excelling in state-of-the-art reasoning, multimodal understanding across text, images, video, audio, and code, with exceptional agentic capabilities for handling complex, multi-step tasks autonomously. Accessible directly in Google AI Studio for developers to experiment, tune prompts, and build apps, it shines in vibe coding, generating interactive experiences from ideas, superior tool use like Google Search integration, and conversational editing for images. With a massive 1M token context window, Deep Think mode for ultra-complex problem-solving, and features like structured outputs and function calling, it powers everything from personal assistants to sophisticated workflows, outperforming predecessors on benchmarks like GPQA and ARC-AGI.
Gemini 3
Gemini 3 is Google's most advanced AI model family, including Gemini 3 Pro and Gemini 3 Flash, excelling in state-of-the-art reasoning, multimodal understanding across text, images, video, audio, and code, with exceptional agentic capabilities for handling complex, multi-step tasks autonomously. Accessible directly in Google AI Studio for developers to experiment, tune prompts, and build apps, it shines in vibe coding, generating interactive experiences from ideas, superior tool use like Google Search integration, and conversational editing for images. With a massive 1M token context window, Deep Think mode for ultra-complex problem-solving, and features like structured outputs and function calling, it powers everything from personal assistants to sophisticated workflows, outperforming predecessors on benchmarks like GPQA and ARC-AGI.
Gemini 3
Gemini 3 is Google's most advanced AI model family, including Gemini 3 Pro and Gemini 3 Flash, excelling in state-of-the-art reasoning, multimodal understanding across text, images, video, audio, and code, with exceptional agentic capabilities for handling complex, multi-step tasks autonomously. Accessible directly in Google AI Studio for developers to experiment, tune prompts, and build apps, it shines in vibe coding, generating interactive experiences from ideas, superior tool use like Google Search integration, and conversational editing for images. With a massive 1M token context window, Deep Think mode for ultra-complex problem-solving, and features like structured outputs and function calling, it powers everything from personal assistants to sophisticated workflows, outperforming predecessors on benchmarks like GPQA and ARC-AGI.
Editorial Note
This page was researched and written by the ATB Editorial Team. Our team researches each AI tool by reviewing its official website, testing features, exploring real use cases, and considering user feedback. Every page is fact-checked and regularly updated to ensure the information stays accurate, neutral, and useful for our readers.
If you have any suggestions or questions, email us at hello@aitoolbook.ai