- Remote Teams & Multinational Businesses: Hold meetings without language friction.
- Customer Support & Sales: Serve global customers naturally in any language.
- Educators & Trainers: Teach or present to diverse audiences with instant translation.
- International Friends & Families: Chat effortlessly across continents.
- Language Learners & Polyglots: Practice conversations in unfamiliar languages.
🛠️ How to Use AiLuvio?
- Sign Up or Get the App: Use the web interface or download for Android/iOS.
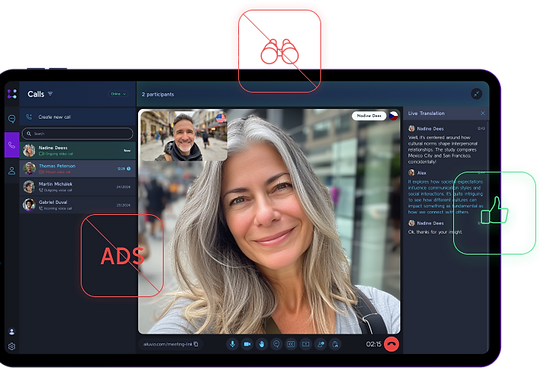
- Start a Call: Invite participants—each can speak in their language.
- Choose Languages: Set preferred spoken and translated languages for participants.
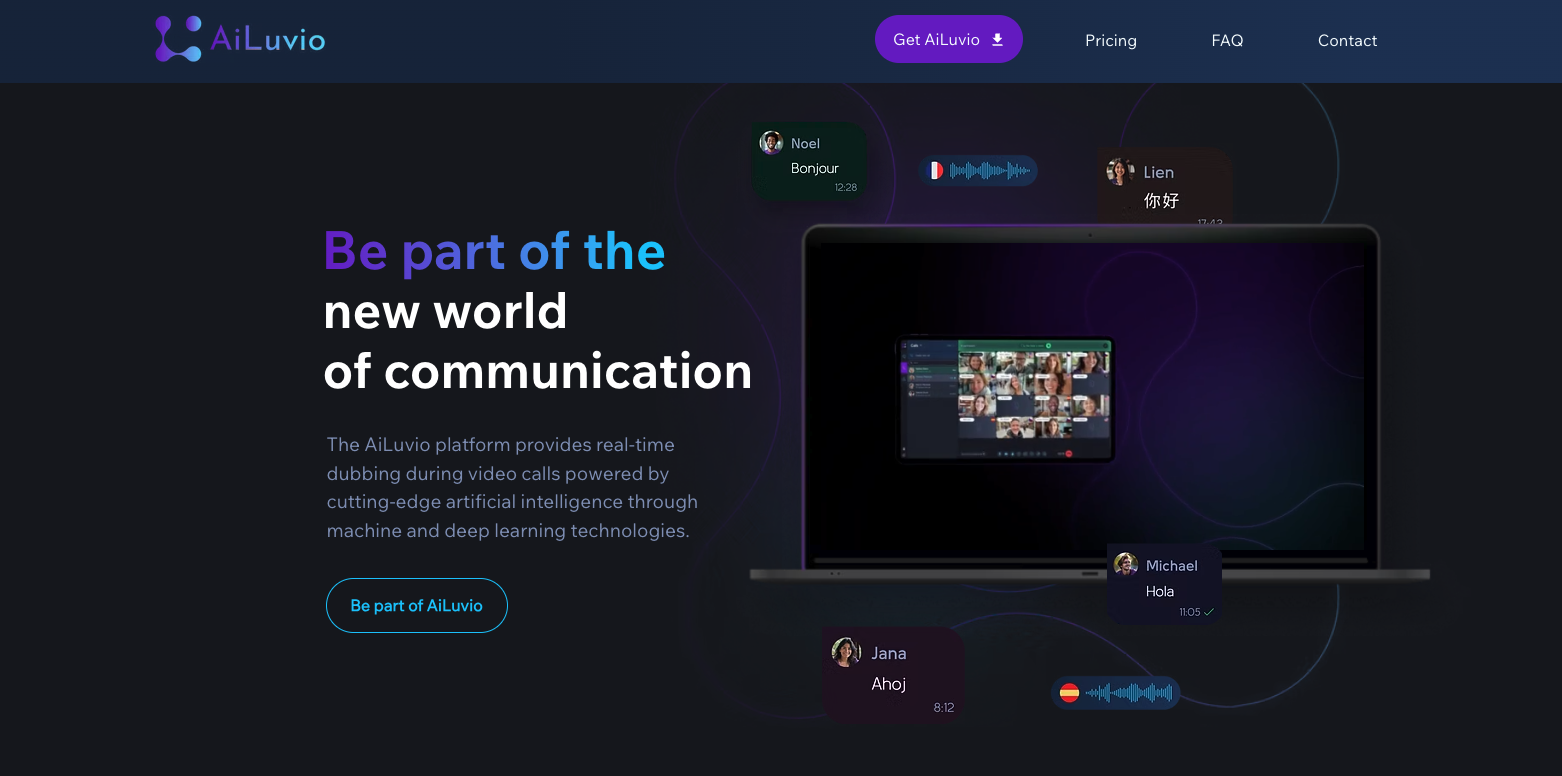
- Communicate Naturally: Speak, and AiLuvio dubs your voice in real time.
- Live Chat & Transcripts: Chat messages auto-translate; calls are transcribed.
- Advanced Voice Features (Coming Soon): Voice cloning, lip-sync, meeting summaries, and predictive translation
- 30+ Languages Support: Includes English, Czech, Chinese, Portuguese, and more.
- Real-Time Voice Dubbing: Instantly voices translations so participants hear in their own language.
- Ad-Free & Privacy-Centric: No tracking, no ads, all communication encrypted via SSL.
- Freemium Model: Generous free plan plus paid tiers offering longer sessions and advanced features.
- Business Ready: Designed for corporate meetings with upcoming support for lip-sync, voice cloning, and summary tools.
- Breaks Language Barriers: Empowers fluent conversation across languages in real time.
- All-in-One Communication: Voice, chat translation, group calls, transcription, and record—all integrated.
- Strong Privacy: SSL encryption and a no-ads, no-tracking policy.
- Transparent Pricing: Free tier plus clear monthly plans—no hidden charges.
- Early-Stage Promise: Small team (founded 2023), but backed by real user approvals and continuous iteration.
- Beta-Level Coverage: Voice cloning and lip sync still in development—may be imperfect on launch.
- Mobile & Web Only: No desktop app—requires browser or mobile access.
- Internet Required: Performance relies on stable, low-latency connections.
- Latency Risk: Real-time dubbing may lag on weaker networks.
- New Player: Still building trust and user base compared to mature competitors.
Free
$ 0.00
AI-powered premium voices
Unlimited communication without translation
Encrypted communication
Group calls and chats
AI-powered automatic translation of chat messages
Call transcription
Basic
$4.99/month
AI-powered premium voices
Unlimited communication without translation
Encrypted communication
Group calls and chats
AI-powered automatic translation of chat messages
Call transcription
One time
$12/month
AI-powered premium voices
Unlimited communication without translation
Encrypted communication
Group calls and chats
AI-powered automatic translation of chat messages
Call transcription
Proud of the love you're getting? Show off your AI Toolbook reviews—then invite more fans to share the love and build your credibility.
Add an AI Toolbook badge to your site—an easy way to drive followers, showcase updates, and collect reviews. It's like a mini 24/7 billboard for your AI.
Reviews
Rating Distribution
Average score
Popular Mention
FAQs
Similar AI Tools

VoiceClone-AI
VoiceClone AI is a cutting-edge voice synthesis platform powered by advanced AI that recreates a speaker’s voice from just 30–60 seconds of sample audio. By capturing tone, accent, inflection, and emotion, it enables users to generate realistic voice content without the need for re-recording. VoiceClone supports multi-language output and provides fine-grained control over emotional cues, pacing, and expressiveness—delivering high-quality MP3/WAV files and seamless API integration.
VoiceClone-AI
VoiceClone AI is a cutting-edge voice synthesis platform powered by advanced AI that recreates a speaker’s voice from just 30–60 seconds of sample audio. By capturing tone, accent, inflection, and emotion, it enables users to generate realistic voice content without the need for re-recording. VoiceClone supports multi-language output and provides fine-grained control over emotional cues, pacing, and expressiveness—delivering high-quality MP3/WAV files and seamless API integration.
VoiceClone-AI
VoiceClone AI is a cutting-edge voice synthesis platform powered by advanced AI that recreates a speaker’s voice from just 30–60 seconds of sample audio. By capturing tone, accent, inflection, and emotion, it enables users to generate realistic voice content without the need for re-recording. VoiceClone supports multi-language output and provides fine-grained control over emotional cues, pacing, and expressiveness—delivering high-quality MP3/WAV files and seamless API integration.

Parrot Talk
Parrot Talk, often referred to as Parrot AI, is an AI-powered voice cloner, generator, and video creation tool. It allows users to clone their own voices from a simple recording, as well as generate realistic audio and videos using a vast library of 100+ celebrity-style AI voices. The platform enables users to create engaging content by converting text to speech, generating AI music from YouTube URLs, and creating short videos with lip-syncing and facial expressions. It's primarily designed for creating funny, entertaining, and creative audio and video clips.
Parrot Talk
Parrot Talk, often referred to as Parrot AI, is an AI-powered voice cloner, generator, and video creation tool. It allows users to clone their own voices from a simple recording, as well as generate realistic audio and videos using a vast library of 100+ celebrity-style AI voices. The platform enables users to create engaging content by converting text to speech, generating AI music from YouTube URLs, and creating short videos with lip-syncing and facial expressions. It's primarily designed for creating funny, entertaining, and creative audio and video clips.
Parrot Talk
Parrot Talk, often referred to as Parrot AI, is an AI-powered voice cloner, generator, and video creation tool. It allows users to clone their own voices from a simple recording, as well as generate realistic audio and videos using a vast library of 100+ celebrity-style AI voices. The platform enables users to create engaging content by converting text to speech, generating AI music from YouTube URLs, and creating short videos with lip-syncing and facial expressions. It's primarily designed for creating funny, entertaining, and creative audio and video clips.
All Voice Lab
All Voice Lab is an advanced AI-powered audio platform that enables creators, developers, and businesses to produce expressive and realistic audio with ease. It offers Text-to-Speech (TTS), high-fidelity voice cloning, and voice-changing tools—all powered by their proprietary MaskGCT model—which excels at capturing emotional tone, rhythm, and natural speech nuances. The platform supports six major languages and prioritizes security with encryption, strict access controls, and misuse monitoring. Whether you're producing audiobooks, dubbing videos, localizing content, or creating immersive audio experiences, All Voice Lab delivers fast, scalable, and expressive voice solutions.
All Voice Lab
All Voice Lab is an advanced AI-powered audio platform that enables creators, developers, and businesses to produce expressive and realistic audio with ease. It offers Text-to-Speech (TTS), high-fidelity voice cloning, and voice-changing tools—all powered by their proprietary MaskGCT model—which excels at capturing emotional tone, rhythm, and natural speech nuances. The platform supports six major languages and prioritizes security with encryption, strict access controls, and misuse monitoring. Whether you're producing audiobooks, dubbing videos, localizing content, or creating immersive audio experiences, All Voice Lab delivers fast, scalable, and expressive voice solutions.
All Voice Lab
All Voice Lab is an advanced AI-powered audio platform that enables creators, developers, and businesses to produce expressive and realistic audio with ease. It offers Text-to-Speech (TTS), high-fidelity voice cloning, and voice-changing tools—all powered by their proprietary MaskGCT model—which excels at capturing emotional tone, rhythm, and natural speech nuances. The platform supports six major languages and prioritizes security with encryption, strict access controls, and misuse monitoring. Whether you're producing audiobooks, dubbing videos, localizing content, or creating immersive audio experiences, All Voice Lab delivers fast, scalable, and expressive voice solutions.

Murf.ai
Murf.ai is an AI voice generator and text-to-speech platform that delivers ultra-realistic voiceovers for creators, teams, and developers. It offers 200+ multilingual voices, 10+ speaking styles, and fine-grained controls over pitch, speed, tone, prosody, and pronunciation. A low-latency TTS model powers conversational agents with sub-200 ms response, while APIs enable voice cloning, voice changing, streaming TTS, and translation/dubbing in 30+ languages. A studio workspace supports scripting, timing, and rapid iteration for ads, training, audiobooks, podcasts, and product audio. Pronunciation libraries, team workspaces, and tool integrations help standardize brand voice at scale without complex audio engineering.
Murf.ai
Murf.ai is an AI voice generator and text-to-speech platform that delivers ultra-realistic voiceovers for creators, teams, and developers. It offers 200+ multilingual voices, 10+ speaking styles, and fine-grained controls over pitch, speed, tone, prosody, and pronunciation. A low-latency TTS model powers conversational agents with sub-200 ms response, while APIs enable voice cloning, voice changing, streaming TTS, and translation/dubbing in 30+ languages. A studio workspace supports scripting, timing, and rapid iteration for ads, training, audiobooks, podcasts, and product audio. Pronunciation libraries, team workspaces, and tool integrations help standardize brand voice at scale without complex audio engineering.
Murf.ai
Murf.ai is an AI voice generator and text-to-speech platform that delivers ultra-realistic voiceovers for creators, teams, and developers. It offers 200+ multilingual voices, 10+ speaking styles, and fine-grained controls over pitch, speed, tone, prosody, and pronunciation. A low-latency TTS model powers conversational agents with sub-200 ms response, while APIs enable voice cloning, voice changing, streaming TTS, and translation/dubbing in 30+ languages. A studio workspace supports scripting, timing, and rapid iteration for ads, training, audiobooks, podcasts, and product audio. Pronunciation libraries, team workspaces, and tool integrations help standardize brand voice at scale without complex audio engineering.
PlayAI
Play.ht is an AI voice generator and text-to-speech platform for creating humanlike voiceovers in minutes. It offers a large, growing library of natural voices across 30+ languages and accents, with controls for pitch, pace, emphasis, pauses, and SSML. Dialog-enabled generation supports multi-speaker, multi-turn conversations in a single file, ideal for podcasts and character-driven audio. Teams can define and reuse pronunciations for brand terms, preview segments, and fine-tune emotion and speaking styles. Voice cloning and custom voice creation enable consistent brand sound, while ultra-low-latency streaming suits live apps. Use cases span videos, audiobooks, training, assistants, games, IVR, and localization.
PlayAI
Play.ht is an AI voice generator and text-to-speech platform for creating humanlike voiceovers in minutes. It offers a large, growing library of natural voices across 30+ languages and accents, with controls for pitch, pace, emphasis, pauses, and SSML. Dialog-enabled generation supports multi-speaker, multi-turn conversations in a single file, ideal for podcasts and character-driven audio. Teams can define and reuse pronunciations for brand terms, preview segments, and fine-tune emotion and speaking styles. Voice cloning and custom voice creation enable consistent brand sound, while ultra-low-latency streaming suits live apps. Use cases span videos, audiobooks, training, assistants, games, IVR, and localization.
PlayAI
Play.ht is an AI voice generator and text-to-speech platform for creating humanlike voiceovers in minutes. It offers a large, growing library of natural voices across 30+ languages and accents, with controls for pitch, pace, emphasis, pauses, and SSML. Dialog-enabled generation supports multi-speaker, multi-turn conversations in a single file, ideal for podcasts and character-driven audio. Teams can define and reuse pronunciations for brand terms, preview segments, and fine-tune emotion and speaking styles. Voice cloning and custom voice creation enable consistent brand sound, while ultra-low-latency streaming suits live apps. Use cases span videos, audiobooks, training, assistants, games, IVR, and localization.

Resemble.AI
Resemble AI is an enterprise-focused Voice AI platform built on trust, offering realistic voice generation, voice cloning, and multi-modal deepfake detection across audio, image, and video. It provides real-time text-to-speech and speech-to-speech backed by advanced models like Chatterbox, plus watermarking for provenance and intelligence features for language, dialect, and anomaly detection. Teams can create branded, controllable voices, edit audio by typing, and deploy voice agents with developer-ready tooling. The platform also enables on-premises or private deployment for stricter compliance. With integrated security awareness training and automated monitoring, Resemble helps organizations scale voice experiences while defending against synthetic media risks.
Resemble.AI
Resemble AI is an enterprise-focused Voice AI platform built on trust, offering realistic voice generation, voice cloning, and multi-modal deepfake detection across audio, image, and video. It provides real-time text-to-speech and speech-to-speech backed by advanced models like Chatterbox, plus watermarking for provenance and intelligence features for language, dialect, and anomaly detection. Teams can create branded, controllable voices, edit audio by typing, and deploy voice agents with developer-ready tooling. The platform also enables on-premises or private deployment for stricter compliance. With integrated security awareness training and automated monitoring, Resemble helps organizations scale voice experiences while defending against synthetic media risks.
Resemble.AI
Resemble AI is an enterprise-focused Voice AI platform built on trust, offering realistic voice generation, voice cloning, and multi-modal deepfake detection across audio, image, and video. It provides real-time text-to-speech and speech-to-speech backed by advanced models like Chatterbox, plus watermarking for provenance and intelligence features for language, dialect, and anomaly detection. Teams can create branded, controllable voices, edit audio by typing, and deploy voice agents with developer-ready tooling. The platform also enables on-premises or private deployment for stricter compliance. With integrated security awareness training and automated monitoring, Resemble helps organizations scale voice experiences while defending against synthetic media risks.
FakeYou
FakeYou is a community-driven AI voice platform that converts text into speech using a large catalog of celebrity, character, and creator-trained voices. It emphasizes ease of use for quick meme audio, voiceovers, and creative projects, while also supporting longer scripts with stable generation. Users select from many fan-made and studio-quality voice models, then fine-tune outputs with controls like pace and emphasis for better delivery. The platform focuses on fun, experimentation, and shareability, letting creators generate clips for videos, streams, and social posts. With a lively community and frequent new voices, FakeYou makes voice cloning and character TTS accessible for everyday content creation.
FakeYou
FakeYou is a community-driven AI voice platform that converts text into speech using a large catalog of celebrity, character, and creator-trained voices. It emphasizes ease of use for quick meme audio, voiceovers, and creative projects, while also supporting longer scripts with stable generation. Users select from many fan-made and studio-quality voice models, then fine-tune outputs with controls like pace and emphasis for better delivery. The platform focuses on fun, experimentation, and shareability, letting creators generate clips for videos, streams, and social posts. With a lively community and frequent new voices, FakeYou makes voice cloning and character TTS accessible for everyday content creation.
FakeYou
FakeYou is a community-driven AI voice platform that converts text into speech using a large catalog of celebrity, character, and creator-trained voices. It emphasizes ease of use for quick meme audio, voiceovers, and creative projects, while also supporting longer scripts with stable generation. Users select from many fan-made and studio-quality voice models, then fine-tune outputs with controls like pace and emphasis for better delivery. The platform focuses on fun, experimentation, and shareability, letting creators generate clips for videos, streams, and social posts. With a lively community and frequent new voices, FakeYou makes voice cloning and character TTS accessible for everyday content creation.


Top Medi AI
TopMediai is an all-in-one AI platform built to supercharge content creation across voice, music, and media. It offers advanced tools for text-to-speech, voice cloning, song generation, music covers, and more—allowing creators to generate realistic voiceovers, custom music tracks, and full audio productions in minutes. With thousands of AI voices, support for hundreds of languages and accents, and smart music-generation from prompts, lyrics or images, you get a creative engine built for speed and scale. Whether you're crafting podcasts, videos, games, songs or dubbing, TopMediai packs studio-grade power into a browser-based workflow. The platform also offers API access so developers and creative teams can integrate voice and music generation into their apps and systems.
Top Medi AI
TopMediai is an all-in-one AI platform built to supercharge content creation across voice, music, and media. It offers advanced tools for text-to-speech, voice cloning, song generation, music covers, and more—allowing creators to generate realistic voiceovers, custom music tracks, and full audio productions in minutes. With thousands of AI voices, support for hundreds of languages and accents, and smart music-generation from prompts, lyrics or images, you get a creative engine built for speed and scale. Whether you're crafting podcasts, videos, games, songs or dubbing, TopMediai packs studio-grade power into a browser-based workflow. The platform also offers API access so developers and creative teams can integrate voice and music generation into their apps and systems.
Top Medi AI
TopMediai is an all-in-one AI platform built to supercharge content creation across voice, music, and media. It offers advanced tools for text-to-speech, voice cloning, song generation, music covers, and more—allowing creators to generate realistic voiceovers, custom music tracks, and full audio productions in minutes. With thousands of AI voices, support for hundreds of languages and accents, and smart music-generation from prompts, lyrics or images, you get a creative engine built for speed and scale. Whether you're crafting podcasts, videos, games, songs or dubbing, TopMediai packs studio-grade power into a browser-based workflow. The platform also offers API access so developers and creative teams can integrate voice and music generation into their apps and systems.
AI Awaaz
Ai Awaaz is a text-to-speech (TTS) and voice-generation platform developed in India and marketed as India’s first emotion-based TTS AI engine. It enables users to convert text into natural-sounding voiceovers in 20+ Indian languages and 140+ voices, with selectable emotions (e.g., cheerful, sad, whispering) and export formats suitable for videos, podcasts, audiobooks and e-learning modules. The platform emphasises speed and scalability, claiming that a voiceover can be created in just minutes, compared to traditional voice-actor turnaround times. It is positioned for marketers, educators, content creators and agencies needing multi-language voice production with minimal friction.
AI Awaaz
Ai Awaaz is a text-to-speech (TTS) and voice-generation platform developed in India and marketed as India’s first emotion-based TTS AI engine. It enables users to convert text into natural-sounding voiceovers in 20+ Indian languages and 140+ voices, with selectable emotions (e.g., cheerful, sad, whispering) and export formats suitable for videos, podcasts, audiobooks and e-learning modules. The platform emphasises speed and scalability, claiming that a voiceover can be created in just minutes, compared to traditional voice-actor turnaround times. It is positioned for marketers, educators, content creators and agencies needing multi-language voice production with minimal friction.
AI Awaaz
Ai Awaaz is a text-to-speech (TTS) and voice-generation platform developed in India and marketed as India’s first emotion-based TTS AI engine. It enables users to convert text into natural-sounding voiceovers in 20+ Indian languages and 140+ voices, with selectable emotions (e.g., cheerful, sad, whispering) and export formats suitable for videos, podcasts, audiobooks and e-learning modules. The platform emphasises speed and scalability, claiming that a voiceover can be created in just minutes, compared to traditional voice-actor turnaround times. It is positioned for marketers, educators, content creators and agencies needing multi-language voice production with minimal friction.
Infinite Talk AI
InfiniteTalk AI is a real-time voice AI platform designed to generate natural, expressive, human-like speech for conversations, character performances, dubbing, and instant voice replacement across creative and professional workflows. Unlike traditional text‑to‑speech tools, InfiniteTalk AI focuses on true conversational dynamics intonation, pacing, emotion, interruptions, reactions, and personality-driven delivery. Users can choose from a large library of AI voices or create custom voices that maintain identity, tone consistency, emotional variation, and accent accuracy. Built for streamers, filmmakers, game developers, virtual creators, and businesses, InfiniteTalk AI enables fully interactive AI voice agents, real-time dialogue, multilingual dubbing, and rapid voiceover generation for any context.
Infinite Talk AI
InfiniteTalk AI is a real-time voice AI platform designed to generate natural, expressive, human-like speech for conversations, character performances, dubbing, and instant voice replacement across creative and professional workflows. Unlike traditional text‑to‑speech tools, InfiniteTalk AI focuses on true conversational dynamics intonation, pacing, emotion, interruptions, reactions, and personality-driven delivery. Users can choose from a large library of AI voices or create custom voices that maintain identity, tone consistency, emotional variation, and accent accuracy. Built for streamers, filmmakers, game developers, virtual creators, and businesses, InfiniteTalk AI enables fully interactive AI voice agents, real-time dialogue, multilingual dubbing, and rapid voiceover generation for any context.
Infinite Talk AI
InfiniteTalk AI is a real-time voice AI platform designed to generate natural, expressive, human-like speech for conversations, character performances, dubbing, and instant voice replacement across creative and professional workflows. Unlike traditional text‑to‑speech tools, InfiniteTalk AI focuses on true conversational dynamics intonation, pacing, emotion, interruptions, reactions, and personality-driven delivery. Users can choose from a large library of AI voices or create custom voices that maintain identity, tone consistency, emotional variation, and accent accuracy. Built for streamers, filmmakers, game developers, virtual creators, and businesses, InfiniteTalk AI enables fully interactive AI voice agents, real-time dialogue, multilingual dubbing, and rapid voiceover generation for any context.

Noiz
Noiz is a leading AI platform for advanced speech synthesis and audio generation, specializing in highly expressive, lifelike voices with emotional control and customization. It offers text-to-speech , voice cloning, multilingual dubbing, AI singing voice generation, and developer APIs for seamless integration into apps. Users can create realistic vocals with nuance, vibrato, and dynamics from simple prompts, supporting video translation, audio editing, and music production. The tool excels in cost-efficiency, handling everything from podcast mastering to viral song covers, with features like noise removal, auto-leveling, and scene-based soundscapes. Ideal for creators seeking professional audio without studios.
Noiz
Noiz is a leading AI platform for advanced speech synthesis and audio generation, specializing in highly expressive, lifelike voices with emotional control and customization. It offers text-to-speech , voice cloning, multilingual dubbing, AI singing voice generation, and developer APIs for seamless integration into apps. Users can create realistic vocals with nuance, vibrato, and dynamics from simple prompts, supporting video translation, audio editing, and music production. The tool excels in cost-efficiency, handling everything from podcast mastering to viral song covers, with features like noise removal, auto-leveling, and scene-based soundscapes. Ideal for creators seeking professional audio without studios.
Noiz
Noiz is a leading AI platform for advanced speech synthesis and audio generation, specializing in highly expressive, lifelike voices with emotional control and customization. It offers text-to-speech , voice cloning, multilingual dubbing, AI singing voice generation, and developer APIs for seamless integration into apps. Users can create realistic vocals with nuance, vibrato, and dynamics from simple prompts, supporting video translation, audio editing, and music production. The tool excels in cost-efficiency, handling everything from podcast mastering to viral song covers, with features like noise removal, auto-leveling, and scene-based soundscapes. Ideal for creators seeking professional audio without studios.
Medio.Cool
Medio.Cool is an essential AI editing suite for businesses tackling video localization and global marketing without downloads or complex setups. It shines with one-click watermark removal from platforms like TikTok, YouTube, and Instagram, plus seamless translation of product details, videos, and subtitles into foreign languages. Generate polished narration videos from product links, clone voices for authentic dubbing, and download HD originals effortlessly—all online in your browser. With features like contextual subtitle polishing, multi-character voice cloning, and e-commerce import support, it empowers sellers to go global fast, mining new markets while keeping content natural and engaging. Perfect for turning local clips into international traffic magnets.
Medio.Cool
Medio.Cool is an essential AI editing suite for businesses tackling video localization and global marketing without downloads or complex setups. It shines with one-click watermark removal from platforms like TikTok, YouTube, and Instagram, plus seamless translation of product details, videos, and subtitles into foreign languages. Generate polished narration videos from product links, clone voices for authentic dubbing, and download HD originals effortlessly—all online in your browser. With features like contextual subtitle polishing, multi-character voice cloning, and e-commerce import support, it empowers sellers to go global fast, mining new markets while keeping content natural and engaging. Perfect for turning local clips into international traffic magnets.
Medio.Cool
Medio.Cool is an essential AI editing suite for businesses tackling video localization and global marketing without downloads or complex setups. It shines with one-click watermark removal from platforms like TikTok, YouTube, and Instagram, plus seamless translation of product details, videos, and subtitles into foreign languages. Generate polished narration videos from product links, clone voices for authentic dubbing, and download HD originals effortlessly—all online in your browser. With features like contextual subtitle polishing, multi-character voice cloning, and e-commerce import support, it empowers sellers to go global fast, mining new markets while keeping content natural and engaging. Perfect for turning local clips into international traffic magnets.
Editorial Note
This page was researched and written by the ATB Editorial Team. Our team researches each AI tool by reviewing its official website, testing features, exploring real use cases, and considering user feedback. Every page is fact-checked and regularly updated to ensure the information stays accurate, neutral, and useful for our readers.
If you have any suggestions or questions, email us at hello@aitoolbook.ai