- Content Creators & Influencers: Instantly generate unique videos for social media, YouTube, and marketing.
- Agencies & Designers: Batch-generate visuals for campaigns, explainers, or ads efficiently.
- Businesses & Marketers: Produce promotional content, product demos, and branded motion graphics.
- Educators & Trainers: Create engaging lesson videos and animated explainers.
- Artists & Storytellers: Experiment with style, animation, and cinematic effects powered by multiple AI models.
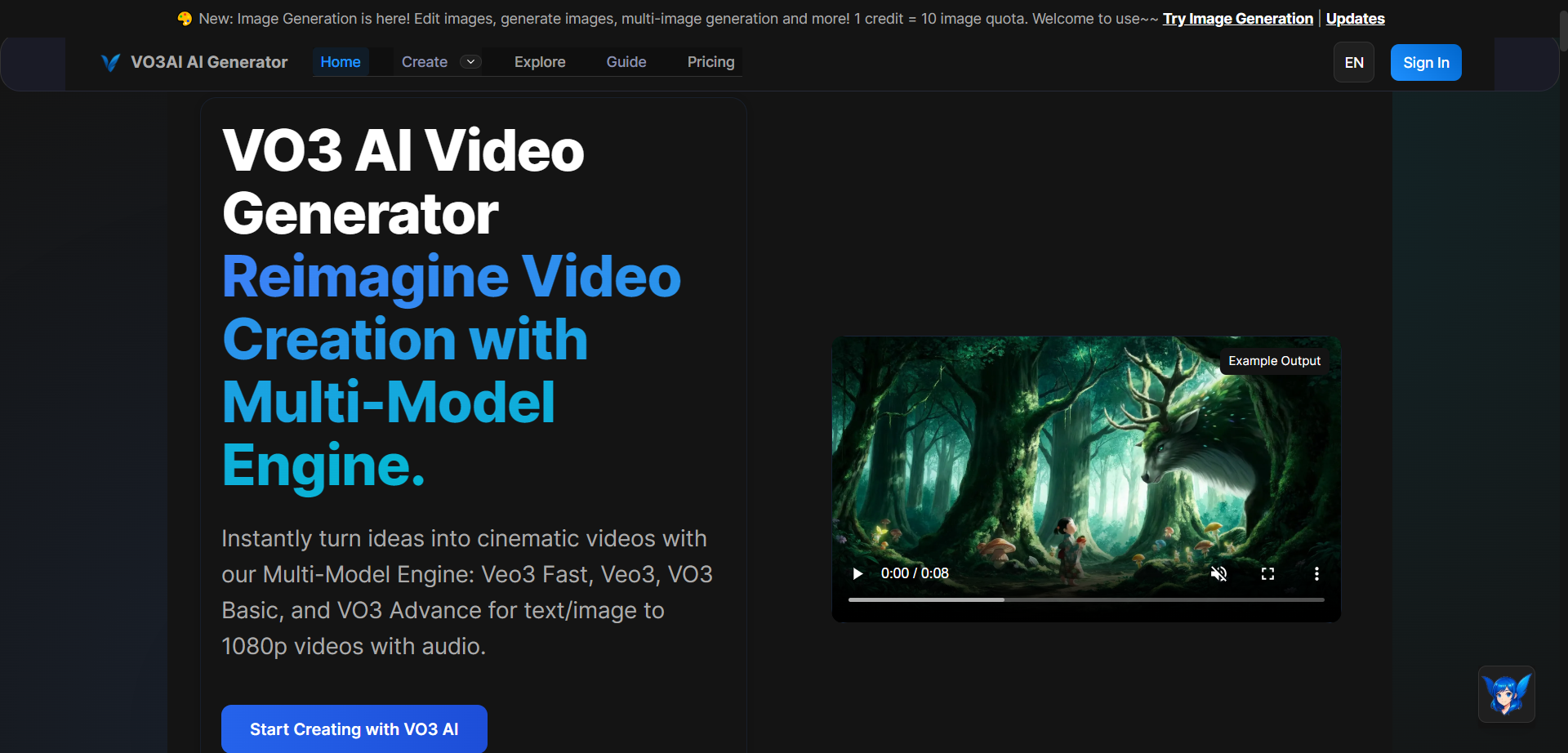
How to Use VO3 AI?
- Enter Text or Upload Image: Start video creation by describing a scene or uploading an image.
- Select Model & Customize: Use VO3 Bot to optimize prompts, pick style, and choose best-fit video model.
- Generate & Download: Batch-create or split scenes for efficient production, then download or share the result.
- Leverage Workflow Tools: Use batch, continuation, and prompt optimization for complex projects.
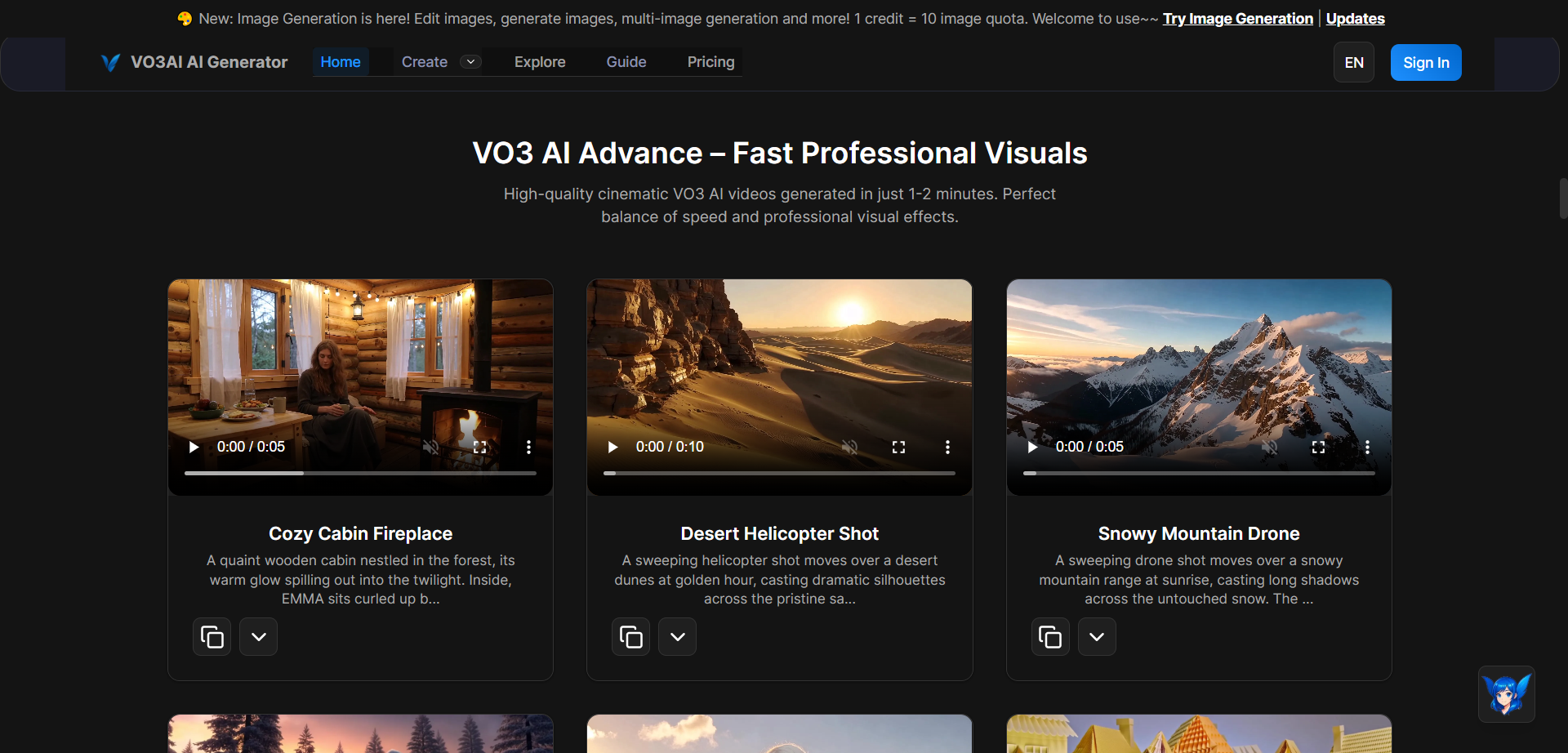
- Multi-Model AI Engine: Access multiple models (Veo3 Fast, Veo3, VO3 Basic, Advance, Premium) for style and speed.
- 1080p Video & Audio Generation: High-definition output suitable for professional and commercial use.
- Workflow Automation Tools: Batch generation, scene management, and 24/7 AI Bot for support and optimization.
- Diverse Style Options: Supports realistic, anime, sci-fi, fantasy, and even origami-inspired animation.
- Professional Sharing & SEO: Create shareable videos with privacy controls and SEO-optimized pages.
- Wide range of creative options and styles.
- Fast production with batch and workflow automation tools.
- Mobile-optimized for smooth access.
- Commercial rights included in subscriptions and credit packs.
- Credit-based system means usage limits for heavy users.
- Most advanced models and features require paid subscription.
- Video length limited to short (5-10 second) clips by default.
- Customization and advanced controls may need some technical familiarity.




Basic
$ 19.90
720p & 1080p video resolution
Standard processing
Commercial usage rights
Public & private videos
VO3 Basic: 1 credit (720p 1080p)
VO3 Advance: 4 credits (1080p)
Google Veo3 Fast: 5 credits (768p + Audio)
Basic support
Global availability
Auto-renews monthly
Studio
$ 199.00
VO3 Al Basic & Advance
Google Veo3 and VEO3 Fast Al Support
5-10 second videos
720p & 1080p video resolution
Lip sync support
Text Video & Image→ Video with sound effects
Fastest processing
Commercial usage rights
Public & private videos
Priority support
Global availability
Auto-renews monthly
Pro
$ 49.90
VO3 Al Basic & Advance
Google Veo 3 and VEO3 Fast Support
5-10 second videos
720p & 1080p video resolution
Lip sync support
Text Video with sound effects
Commercial usage rights
Public & private videos
Fastest processing
Priority support
Global availability
Auto-renews monthly
Proud of the love you're getting? Show off your AI Toolbook reviews—then invite more fans to share the love and build your credibility.
Add an AI Toolbook badge to your site—an easy way to drive followers, showcase updates, and collect reviews. It's like a mini 24/7 billboard for your AI.
Reviews
Rating Distribution
Average score
Popular Mention
FAQs
Similar AI Tools

Veo 2
Veo 2 is Google DeepMind’s advanced text-to-video generator that creates high-quality, cinematic video clips from text or image prompts. It offers realistic human motion, physics consistency, cinematic camera controls, 720p-4K resolution, extended clip length, and an invisible SynthID watermark to identify AI-generated content .
Veo 2
Veo 2 is Google DeepMind’s advanced text-to-video generator that creates high-quality, cinematic video clips from text or image prompts. It offers realistic human motion, physics consistency, cinematic camera controls, 720p-4K resolution, extended clip length, and an invisible SynthID watermark to identify AI-generated content .
Veo 2
Veo 2 is Google DeepMind’s advanced text-to-video generator that creates high-quality, cinematic video clips from text or image prompts. It offers realistic human motion, physics consistency, cinematic camera controls, 720p-4K resolution, extended clip length, and an invisible SynthID watermark to identify AI-generated content .
Vidu AI
Vidu AI is a powerful, web-based AI video creation platform that transforms text prompts, static images, or multiple visual references into high-quality, cinematic videos within seconds. It supports text-to-video, image-to-video, and reference-to-video modes—offering creative flexibility for stylized, realistic, and anime-style content
Vidu AI
Vidu AI is a powerful, web-based AI video creation platform that transforms text prompts, static images, or multiple visual references into high-quality, cinematic videos within seconds. It supports text-to-video, image-to-video, and reference-to-video modes—offering creative flexibility for stylized, realistic, and anime-style content
Vidu AI
Vidu AI is a powerful, web-based AI video creation platform that transforms text prompts, static images, or multiple visual references into high-quality, cinematic videos within seconds. It supports text-to-video, image-to-video, and reference-to-video modes—offering creative flexibility for stylized, realistic, and anime-style content
Image-to-Video Maker is an all-in-one AI video generation platform that lets you convert text prompts, photos, or video clips into vivid, high-quality videos in seconds. Using a suite of leading AI models—including Google Veo 3, ByteDance Seedance, Kuaishou Kling, and Alibaba Wan—this platform powers cinematic effects, smooth transitions, AI talking avatars, upscaling, lip-syncing, and trending visual styles, all accessible to creators at any skill level.
Image-to-Video Maker is an all-in-one AI video generation platform that lets you convert text prompts, photos, or video clips into vivid, high-quality videos in seconds. Using a suite of leading AI models—including Google Veo 3, ByteDance Seedance, Kuaishou Kling, and Alibaba Wan—this platform powers cinematic effects, smooth transitions, AI talking avatars, upscaling, lip-syncing, and trending visual styles, all accessible to creators at any skill level.
Image-to-Video Maker is an all-in-one AI video generation platform that lets you convert text prompts, photos, or video clips into vivid, high-quality videos in seconds. Using a suite of leading AI models—including Google Veo 3, ByteDance Seedance, Kuaishou Kling, and Alibaba Wan—this platform powers cinematic effects, smooth transitions, AI talking avatars, upscaling, lip-syncing, and trending visual styles, all accessible to creators at any skill level.

iMyFone Novi AI
iMyFone AI Video Generator is a versatile online platform that leverages advanced artificial intelligence to create professional-quality videos from simple text prompts or images. Designed to make video production accessible to everyone, its intuitive interface allows users to generate engaging, customized videos packed with dynamic scenes, transitions, voiceovers, and background music without any prior editing skills. Suitable for marketing, social media, education, or personal storytelling, iMyFone’s AI-powered engine automates creative workflow, delivering polished, ready-to-share videos quickly and efficiently.
iMyFone Novi AI
iMyFone AI Video Generator is a versatile online platform that leverages advanced artificial intelligence to create professional-quality videos from simple text prompts or images. Designed to make video production accessible to everyone, its intuitive interface allows users to generate engaging, customized videos packed with dynamic scenes, transitions, voiceovers, and background music without any prior editing skills. Suitable for marketing, social media, education, or personal storytelling, iMyFone’s AI-powered engine automates creative workflow, delivering polished, ready-to-share videos quickly and efficiently.
iMyFone Novi AI
iMyFone AI Video Generator is a versatile online platform that leverages advanced artificial intelligence to create professional-quality videos from simple text prompts or images. Designed to make video production accessible to everyone, its intuitive interface allows users to generate engaging, customized videos packed with dynamic scenes, transitions, voiceovers, and background music without any prior editing skills. Suitable for marketing, social media, education, or personal storytelling, iMyFone’s AI-powered engine automates creative workflow, delivering polished, ready-to-share videos quickly and efficiently.
Viddo AI
Viddo AI is a robust all-in-one creative platform powered by next-generation generative models that allows anyone to produce videos, images, and music without editing experience. Integrating popular AI engines like Veo 3, Runway, PixVerse, Midjourney, Seedance, and Suno, Viddo AI supports a wide range of creative workflows—including Image-to-Video, Text-to-Video, Video-to-Video, Text-to-Image, and Image-to-Image generation—all from a single intuitive interface. The platform’s advanced options enable users to customize outputs, select the optimal AI model, and generate professional-quality content in minutes, with fast rendering and user-friendly tools tailored for both beginners and expert creators.
Viddo AI
Viddo AI is a robust all-in-one creative platform powered by next-generation generative models that allows anyone to produce videos, images, and music without editing experience. Integrating popular AI engines like Veo 3, Runway, PixVerse, Midjourney, Seedance, and Suno, Viddo AI supports a wide range of creative workflows—including Image-to-Video, Text-to-Video, Video-to-Video, Text-to-Image, and Image-to-Image generation—all from a single intuitive interface. The platform’s advanced options enable users to customize outputs, select the optimal AI model, and generate professional-quality content in minutes, with fast rendering and user-friendly tools tailored for both beginners and expert creators.
Viddo AI
Viddo AI is a robust all-in-one creative platform powered by next-generation generative models that allows anyone to produce videos, images, and music without editing experience. Integrating popular AI engines like Veo 3, Runway, PixVerse, Midjourney, Seedance, and Suno, Viddo AI supports a wide range of creative workflows—including Image-to-Video, Text-to-Video, Video-to-Video, Text-to-Image, and Image-to-Image generation—all from a single intuitive interface. The platform’s advanced options enable users to customize outputs, select the optimal AI model, and generate professional-quality content in minutes, with fast rendering and user-friendly tools tailored for both beginners and expert creators.


Image to Video
Image to Video AI is an advanced online platform that converts static images into dynamic, high-quality videos using cutting-edge artificial intelligence technology. It allows users to upload photos and transform them into engaging videos with smooth motion, animations, and customizable effects, supporting video resolutions up to 4K. The platform caters to a wide range of users including content creators, marketers, and hobbyists by providing easy-to-use tools that automate video creation, offering features like batch processing, adjustable video length, and various animation styles—all without requiring any video editing skills.
Image to Video
Image to Video AI is an advanced online platform that converts static images into dynamic, high-quality videos using cutting-edge artificial intelligence technology. It allows users to upload photos and transform them into engaging videos with smooth motion, animations, and customizable effects, supporting video resolutions up to 4K. The platform caters to a wide range of users including content creators, marketers, and hobbyists by providing easy-to-use tools that automate video creation, offering features like batch processing, adjustable video length, and various animation styles—all without requiring any video editing skills.
Image to Video
Image to Video AI is an advanced online platform that converts static images into dynamic, high-quality videos using cutting-edge artificial intelligence technology. It allows users to upload photos and transform them into engaging videos with smooth motion, animations, and customizable effects, supporting video resolutions up to 4K. The platform caters to a wide range of users including content creators, marketers, and hobbyists by providing easy-to-use tools that automate video creation, offering features like batch processing, adjustable video length, and various animation styles—all without requiring any video editing skills.
WAN AI is an AI-powered creative visual generation platform built to help filmmakers, designers, content creators, and storytellers produce high-quality images and cinematic videos with minimal effort. The platform specializes in turning text prompts, reference images, and style guides into polished visuals that maintain coherence, artistic direction, and scene-level consistency. Designed for speed and accessibility, WAN AI provides creators with an intuitive interface that supports rapid ideation, concept art development, storyboarding, product visualization, and high-fidelity image generation. By combining multi-model generation, style controls, character consistency tools, and iterative refinement workflows, the platform helps users turn abstract ideas into production-ready visual assets. WAN AI allows users to fine-tune outputs through adjustable parameters such as lighting, perspective, realism, and artistic tone.
WAN AI is an AI-powered creative visual generation platform built to help filmmakers, designers, content creators, and storytellers produce high-quality images and cinematic videos with minimal effort. The platform specializes in turning text prompts, reference images, and style guides into polished visuals that maintain coherence, artistic direction, and scene-level consistency. Designed for speed and accessibility, WAN AI provides creators with an intuitive interface that supports rapid ideation, concept art development, storyboarding, product visualization, and high-fidelity image generation. By combining multi-model generation, style controls, character consistency tools, and iterative refinement workflows, the platform helps users turn abstract ideas into production-ready visual assets. WAN AI allows users to fine-tune outputs through adjustable parameters such as lighting, perspective, realism, and artistic tone.
WAN AI is an AI-powered creative visual generation platform built to help filmmakers, designers, content creators, and storytellers produce high-quality images and cinematic videos with minimal effort. The platform specializes in turning text prompts, reference images, and style guides into polished visuals that maintain coherence, artistic direction, and scene-level consistency. Designed for speed and accessibility, WAN AI provides creators with an intuitive interface that supports rapid ideation, concept art development, storyboarding, product visualization, and high-fidelity image generation. By combining multi-model generation, style controls, character consistency tools, and iterative refinement workflows, the platform helps users turn abstract ideas into production-ready visual assets. WAN AI allows users to fine-tune outputs through adjustable parameters such as lighting, perspective, realism, and artistic tone.
Waver AI
Waver AI is a next-generation, foundation-model-powered video and image generation platform built for creators, teams, and studios that need cinematic, temporally coherent visuals without the traditional production pipeline. At its core, Waver 1.0 consolidates text-to-video (T2V), image-to-video (I2V), and text-to-image (T2I) capabilities into a single, extensible model that emphasizes motion fidelity, temporal consistency, and predictable framing at 1080p resolution. The platform targets practical production needs—short-form cinematic clips (2–10 seconds), storyboard animatics, product reveals, social campaign videos, and rapid concept exploration—by converting concise prompts or reference imagery into polished motion content. Waver distinguishes itself by optimizing for real-world motion (sports, human actions, complex camera moves) through rectified flow transformer architectures and benchmarked performance.
Waver AI
Waver AI is a next-generation, foundation-model-powered video and image generation platform built for creators, teams, and studios that need cinematic, temporally coherent visuals without the traditional production pipeline. At its core, Waver 1.0 consolidates text-to-video (T2V), image-to-video (I2V), and text-to-image (T2I) capabilities into a single, extensible model that emphasizes motion fidelity, temporal consistency, and predictable framing at 1080p resolution. The platform targets practical production needs—short-form cinematic clips (2–10 seconds), storyboard animatics, product reveals, social campaign videos, and rapid concept exploration—by converting concise prompts or reference imagery into polished motion content. Waver distinguishes itself by optimizing for real-world motion (sports, human actions, complex camera moves) through rectified flow transformer architectures and benchmarked performance.
Waver AI
Waver AI is a next-generation, foundation-model-powered video and image generation platform built for creators, teams, and studios that need cinematic, temporally coherent visuals without the traditional production pipeline. At its core, Waver 1.0 consolidates text-to-video (T2V), image-to-video (I2V), and text-to-image (T2I) capabilities into a single, extensible model that emphasizes motion fidelity, temporal consistency, and predictable framing at 1080p resolution. The platform targets practical production needs—short-form cinematic clips (2–10 seconds), storyboard animatics, product reveals, social campaign videos, and rapid concept exploration—by converting concise prompts or reference imagery into polished motion content. Waver distinguishes itself by optimizing for real-world motion (sports, human actions, complex camera moves) through rectified flow transformer architectures and benchmarked performance.
Wan 2.6
WAN26 is an AI‑powered video generation platform that converts text prompts and uploaded images into visually coherent, cinematic short‑form videos. Built on advanced multimodal generation models, WAN26 focuses on creating smooth, detail‑rich motion sequences while preserving subject consistency, camera logic, and scene structure. It is designed for creators, marketers, educators, and studios seeking rapid, high‑quality video output without traditional production tools. The platform supports multi‑shot storytelling, smooth transitions, flexible aspect ratios, and customizable styles, enabling users to transform ideas into dynamic video sequences within minutes. With its ability to interpret complex prompts and maintain stylistic fidelity, WAN26 streamlines video ideation, prototyping, and content drafting for both personal and professional use.
Wan 2.6
WAN26 is an AI‑powered video generation platform that converts text prompts and uploaded images into visually coherent, cinematic short‑form videos. Built on advanced multimodal generation models, WAN26 focuses on creating smooth, detail‑rich motion sequences while preserving subject consistency, camera logic, and scene structure. It is designed for creators, marketers, educators, and studios seeking rapid, high‑quality video output without traditional production tools. The platform supports multi‑shot storytelling, smooth transitions, flexible aspect ratios, and customizable styles, enabling users to transform ideas into dynamic video sequences within minutes. With its ability to interpret complex prompts and maintain stylistic fidelity, WAN26 streamlines video ideation, prototyping, and content drafting for both personal and professional use.
Wan 2.6
WAN26 is an AI‑powered video generation platform that converts text prompts and uploaded images into visually coherent, cinematic short‑form videos. Built on advanced multimodal generation models, WAN26 focuses on creating smooth, detail‑rich motion sequences while preserving subject consistency, camera logic, and scene structure. It is designed for creators, marketers, educators, and studios seeking rapid, high‑quality video output without traditional production tools. The platform supports multi‑shot storytelling, smooth transitions, flexible aspect ratios, and customizable styles, enabling users to transform ideas into dynamic video sequences within minutes. With its ability to interpret complex prompts and maintain stylistic fidelity, WAN26 streamlines video ideation, prototyping, and content drafting for both personal and professional use.
Sota Video
SotaVideo AI is a text-to-video generation platform that creates smooth, coherent, and cinematic videos from simple descriptions. Designed for creators and businesses needing high-quality motion content, SotaVideo transforms text prompts into dynamic scenes with realistic movement, lighting, and camera transitions. Its engine focuses on visual coherence, ensuring characters, environments, and objects stay stable across frames. Users can create short videos for marketing, storytelling, concept visualization, education, and product showcases without traditional filming tools.
Sota Video
SotaVideo AI is a text-to-video generation platform that creates smooth, coherent, and cinematic videos from simple descriptions. Designed for creators and businesses needing high-quality motion content, SotaVideo transforms text prompts into dynamic scenes with realistic movement, lighting, and camera transitions. Its engine focuses on visual coherence, ensuring characters, environments, and objects stay stable across frames. Users can create short videos for marketing, storytelling, concept visualization, education, and product showcases without traditional filming tools.
Sota Video
SotaVideo AI is a text-to-video generation platform that creates smooth, coherent, and cinematic videos from simple descriptions. Designed for creators and businesses needing high-quality motion content, SotaVideo transforms text prompts into dynamic scenes with realistic movement, lighting, and camera transitions. Its engine focuses on visual coherence, ensuring characters, environments, and objects stay stable across frames. Users can create short videos for marketing, storytelling, concept visualization, education, and product showcases without traditional filming tools.

Vidduo
Vidduo is a super AI agent that turns photos into stunning avatar talk videos in minutes for TikTok, Instagram, YouTube, or other platforms, driving instant traffic to websites, apps, or businesses. It features revolutionary AI photo to video technology with industry-leading capabilities, supporting 12 models for smart automatic selection balancing quality, speed, and cost. Create multi-shot narrative videos maintaining subject consistency, visual style, and atmosphere across transitions, with 1080p high-resolution output featuring smooth motion and cinematic aesthetics.
Vidduo
Vidduo is a super AI agent that turns photos into stunning avatar talk videos in minutes for TikTok, Instagram, YouTube, or other platforms, driving instant traffic to websites, apps, or businesses. It features revolutionary AI photo to video technology with industry-leading capabilities, supporting 12 models for smart automatic selection balancing quality, speed, and cost. Create multi-shot narrative videos maintaining subject consistency, visual style, and atmosphere across transitions, with 1080p high-resolution output featuring smooth motion and cinematic aesthetics.
Vidduo
Vidduo is a super AI agent that turns photos into stunning avatar talk videos in minutes for TikTok, Instagram, YouTube, or other platforms, driving instant traffic to websites, apps, or businesses. It features revolutionary AI photo to video technology with industry-leading capabilities, supporting 12 models for smart automatic selection balancing quality, speed, and cost. Create multi-shot narrative videos maintaining subject consistency, visual style, and atmosphere across transitions, with 1080p high-resolution output featuring smooth motion and cinematic aesthetics.
S2V.ai
S2V.ai is a professional AI video generator platform that transforms text prompts or images into hyperrealistic, cinematic videos complete with native audio, powered by top models like Sora 2, Veo 3, and more. Creators input descriptions of scenes, styles, and actions, and the tool generates high-quality clips suitable for social media, marketing, films, or e-commerce, with features like multi-scene storyboarding and image-to-video animation. It offers concurrent generations, private processing, and commercial rights, making advanced video production accessible without expensive equipment or teams. Ideal for content creators, filmmakers, and businesses seeking fast, pro-level results with full control over motion, lighting, and sound.
S2V.ai
S2V.ai is a professional AI video generator platform that transforms text prompts or images into hyperrealistic, cinematic videos complete with native audio, powered by top models like Sora 2, Veo 3, and more. Creators input descriptions of scenes, styles, and actions, and the tool generates high-quality clips suitable for social media, marketing, films, or e-commerce, with features like multi-scene storyboarding and image-to-video animation. It offers concurrent generations, private processing, and commercial rights, making advanced video production accessible without expensive equipment or teams. Ideal for content creators, filmmakers, and businesses seeking fast, pro-level results with full control over motion, lighting, and sound.
S2V.ai
S2V.ai is a professional AI video generator platform that transforms text prompts or images into hyperrealistic, cinematic videos complete with native audio, powered by top models like Sora 2, Veo 3, and more. Creators input descriptions of scenes, styles, and actions, and the tool generates high-quality clips suitable for social media, marketing, films, or e-commerce, with features like multi-scene storyboarding and image-to-video animation. It offers concurrent generations, private processing, and commercial rights, making advanced video production accessible without expensive equipment or teams. Ideal for content creators, filmmakers, and businesses seeking fast, pro-level results with full control over motion, lighting, and sound.
Editorial Note
This page was researched and written by the ATB Editorial Team. Our team researches each AI tool by reviewing its official website, testing features, exploring real use cases, and considering user feedback. Every page is fact-checked and regularly updated to ensure the information stays accurate, neutral, and useful for our readers.
If you have any suggestions or questions, email us at hello@aitoolbook.ai